本文主要是介绍企业出海数据合规:GDPR中的个人数据与非个人数据之区分,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
GDPR仅适用于个人数据,这意味着非个人数据不在其适用范围内。因此,个人数据的定义是一个至关重要的因素,因为它决定了处理数据的实体是否要遵守该法规对数据控制者规定的各种义务。尽管如此,什么是个人数据仍然是当前数据保护制度中引起争议的主要焦点问题之一。
GDPR Recital 26条采取了一种二元分法,区分个人数据和非个人数据,并只将前者纳入其适用范围。但实际生活中,数据的划分并不是静态地存在于两者之间的,对于个人数据在何种情况下通过一系列操作成为匿名数据仍存在争议。实际上,一些数据可能从一开始就是匿名数据(例如与自然人无关的气候传感器数据),但也存在某些数据,可能在某些时候是个人数据,但随后被成功地操作成与自然人无关的数据。这凸显了个人数据分类的动态性。
GDPR下的个人数据
当数据能够将个人与其他人“区分”或“可识别”时,该数据就属于个人数据。在Nowak一案中,欧洲法院认为“GDPR Recital 26条中对个人数据的表述使用‘any informantion’一词,意味着欧盟立法机构赋予这一概念以广泛范围,即并不局限于敏感信息或私人信息,而是包括所有种类的信息,不仅包括客观信息,也包括主观信息”。在Digital Rights Ireland案中,欧洲法院认定,元数据(如位置数据或IP地址)如果能间接识别数据主体的身份,也可以是个人数据,因为它可以“知道注册用户与之通信的人的身份和通信方式,并识别通信的时间以及通信发生的地点”。此外,GDPR第4(1)条强调个人数据必须与自然人有关,法人或死者的数据不在其管辖范围内。
个人数据与非个人数据的区别
在GDPR中,个人数据与非个人数据的区分标准之一为是否可识别。要确定一个自然人是否可识别,应考虑到所有合理的,有可能用来识别该自然人的手段,此外,这些手段是否可被使用也应当被考虑,例如,采用这些手段识别身份所需的成本和时间,当时的可用技术和技术发展情况等。
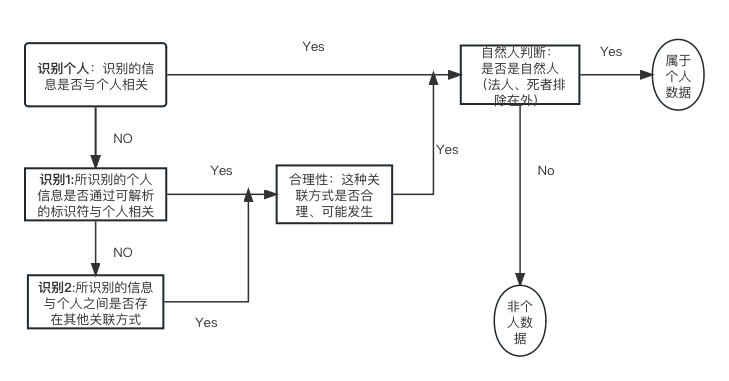
尽管GDPR Recital 26条似乎包含了区分个人数据和非个人数据的方法,但在实践中难以执行。GDPR Recital 26条提出了一种基于风险的方法来确定数据是否属于个人——在“合理可能”发生身份识别的情况下,就属于个人数据,否则就属于非个人数据。一些国家监管机构也承认判断数据是否属于个人应采相对主义的理解,强调相关标准是“识别或可能识别”数据主体。爱尔兰数据保护局(DPA)认为,“没有必要为了证明匿名技术的成功而证明数据主体不可能被识别。相反,如果可以证明,鉴于个案和当时技术情况,数据主体不太可能被识别,那么数据就可以被视为匿名数据”。
然而,A29WP在其2014年《关于匿名化和假名化的指南》中采用了不同的方法。一方面,工作组承认GDPR基于风险的测试方法;另一方面,工作组似乎在设计一种零风险测试——其指导方针宣布,“匿名化是处理个人数据的结果,目的是不可逆转地防止个人数据被滥用”。这意味着,A29WP认为在目前技术水平下,作为一种应用于个人数据的技术,匿名化的结果应与删除所达到的效果一样。
因此,与GDPR基于风险的测试方法相比,工作组似乎认为任何风险都是不能容忍的。Recital 26条认为匿名不可能是绝对的(例如技术会随着时间的推移而改变),而工作组则认为匿名应该是永久性的。这种矛盾也可以在其他国家当局发布的指南中找到。法国国家信息和自由委员会(CNIL)认为,匿名化就是“实际上无法识别”。它认为匿名化“力求不可逆转”,澄清了“不可能”是目标,但也承认在实践中难以实现。然而,法国最高行政法院则认为,只有在“不可能”直接或间接识别个人的情况下,数据才能被视为匿名,无论从数据控制者还是从第三者的角度来评价都是如此。
由此可见,这些不同的解释使法律无法确定在实践中应采用何种检验标准。
确定匿名化是否发生时应考虑哪些因素?
根据GDPR Recital 26条,评估数据是假名还是匿名的相关标准是可识别性。在确定是否可以识别个人时,应考虑“所有可能合理使用的手段”。这包括所有客观因素,如识别所需的成本和时间,并考虑处理时的可用技术和技术发展情况。此外,A29WP认为还应考虑三项标准来确定是否已进行了去身份化:(i)是否仍有可能将某个人单独列出;(ii)是否仍有可能将与某个人有关的记录联系起来;(iii)是否仍能推断出与某人有关的信息。如果这三个问题的答案都是否定的,数据可以被认为是匿名的。
如何确定相关的时间尺度?
相关的时间尺度是指在考虑技术发展及其对数据处理的影响时应该考虑的时间范围。在GDPR Recital 26条中,要求考虑的测试手段不仅仅是目前可用的手段,还包括未来可能发展的技术。然而,目前尚不清楚在这方面应该考虑哪个具体的时间范围。
Recital 26条并没有明确说明是否应该考虑正在进行的技术变化(例如已经在许多领域推出但尚未应用于特定的数据控制者或处理者的新技术),或者当前正在研究中的技术是否也应该予以考虑。A29WP提出了一些指导意见。他们建议在处理数据时同时考虑技术的现有水平以及在处理数据期间可能出现的新技术。
就数据的存续期而言,考虑数据的保留期限非常重要。例如,如果数据打算保留十年,数据控制者应该考虑到在第九年可能发生的身份识别的可能性。这意味着,即使数据最初可能不被视为个人数据,控制者也应该意识到该数据在后期成为个人数据的可能性,并做好准备。
原文阅读:用九智汇 | 企业出海数据合规:GDPR中的个人数据与非个人数据之区分
:
深度分析-《数据视角下的隐私合规》
深度分析-《数据视角下的隐私合规 II》
深度分析-《数据视角下的隐私合规 III》
深度分析-EDPB个人数据泄漏通知指南摘要及合规建议
深度分析:EDPB数据主体权利-访问权指南摘要及合规建议
EDPB关于通过视频设备处理个人数据的指南摘要及合规建议
App隐私合规评估实务和要点
TikTok被罚3.5亿欧元,你应该知道以下几点
没错!非洲肯尼亚刚刚发布了3项隐私处罚
技术分享-动态脱敏
智能网联时代汽车行业数据合规挑战
隐私工程实践路径系列:PIA篇(上)
落地实践-数据分类分级实践难点
数据分类分级-敏感图片识别
深度解读-《个人信息保护合规审计管理办法(征求意见稿)》
隐私工程实践路径系列:PIA篇(下)技术助力
智能网联汽车如何做好用户告知
用九智汇分享:《数字经济合规实务》
数据分类分级-结构化数据识别与分类的算法实践
数据分类分级-隐私管理与保护
“Autosec 安全之星” 用九智汇再获殊荣!
汽车智能网联时代如何解决用户隐私问题?
数据分类分级-敏感数据识别工程实践
用九智汇参编《隐私工程白皮书》正式发布,附下载链接
喜讯!用九智汇入选IAPP中国区服务供应商
这家母公司位于中国的企业因数据问题遭到CNIL处罚!
垦丁律师事务所麻策律师一行到访用九智汇交流合作
用九智汇通过ISO 27001、ISO 27701双重认证
我撒过最多的谎:已阅读并同意相关协议
用九智汇受邀参加WELEGAL与六和律师事务所线下沙龙活动:《数据如何合规出境》
用九智汇入选《数据安全保护义务履行参考案例集》
数字水印在知识产权保护中的应用?
最新!H&M因隐私问题遭到瑞典IMY处罚
第三方SDK合规浅析
关于个人信息权利与响应,你知道多少?
深度分析:EDPB跨境数据合规指南-BCRs认证
深度分析:EDPB关于GDPR下行政罚款计算的指南V2.1
GDPR开发者指南
智能网联汽车行业数据合规解决方案(上)
企业出海数据合规:选择加入和选择退出
企业出海数据合规:CCPA与CPRA的关系
企业出海合规:GDPR和CCPA差异知多少
EDPB-关于在联网车辆和移动相关应用中处理个人数据的第01/2020号指南2.0版(全文翻译)
智能网联汽车行业数据合规解决方案(下)
企业出海如何做好网站Cookie合规
企业出海数据合规:“躲不了”的GDPR域外管辖
新EDPB指南:不只是Cookie
这篇关于企业出海数据合规:GDPR中的个人数据与非个人数据之区分的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








