本文主要是介绍百度新闻资讯挖掘案例实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
百度新闻是广大网友获取资讯常用平台,同时也是金融人了解当今时下舆情数据及对投资行业分析的主要获取源。本文章将以爬取股票恒生电子(600570)新闻为例,带来关于利用python中requests库对百度新闻的数据爬取。
一、获取百度新闻网页源码
本次使用的浏览器为edge浏览器,首先浏览器搜索百度新闻,进入百度新闻首页,搜索“恒生电子”,进入新闻界面如图: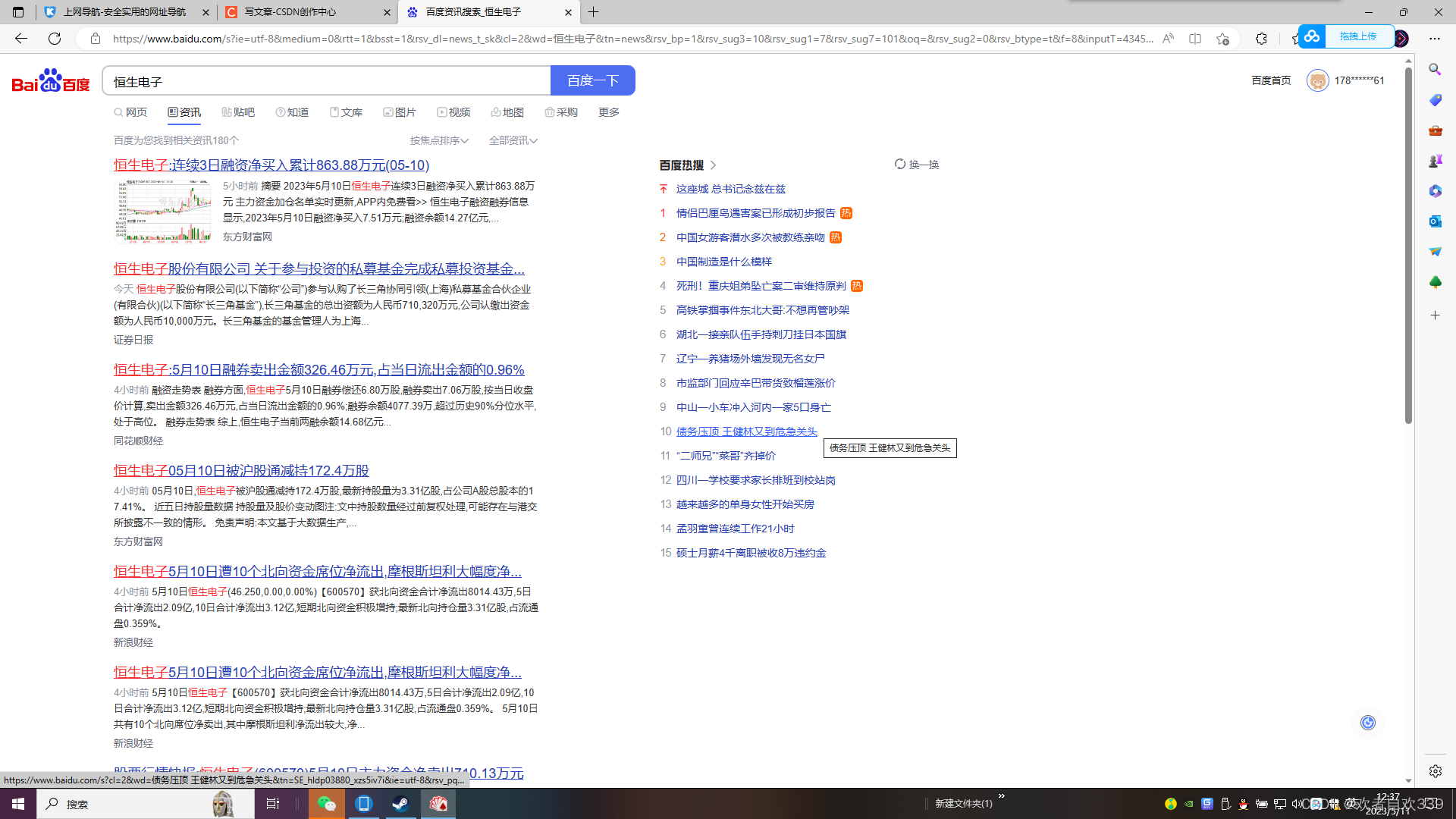
F12打开网页开发者工具利用元素指针可以看到相关新闻板块源码,此时我们记住新闻标题、来源、时间及链接网址的标签,方便我们后面编写正则表达式以获取源码相关文本。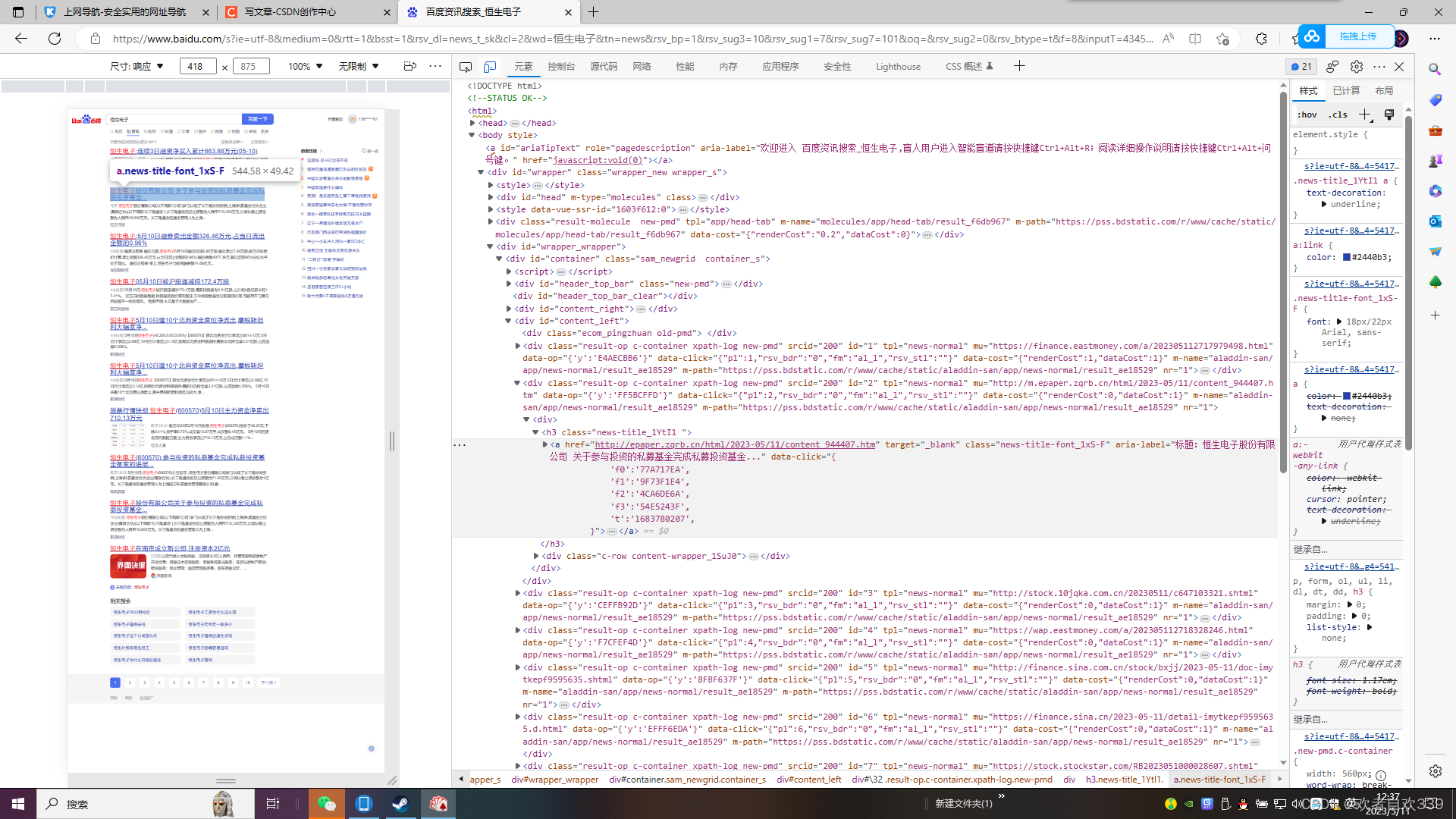
之后,我们进入脚本的编码。首先是导入requests包、re包以及设置requests.get()中的headers参数,以模拟浏览器的访问请求,关于User-Agent的获取方法,平台相关文章有相应解答,在此不做科普。
import requests
import re
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36","Accept-Encoding": "gzip, deflate, br","Accept-Language": "zh-CN,zh;q=0.9"} # 用户代理设置
做完,这些设置后,我们开始尝试获取网页源码数据。先浏览器中复制下网页网址,定义好url,利用requests中get()方法获取并打印文本,在这里特别提示一下,百度现在有时有ssl证书认证的问题,这就会导致请求发过去一直没有响应,卡住了(获取不到源代码),解决方法,把https换成http。代码如下:
url='http://www.baidu.com/s?rtt=1&bsst=1&cl=undefined&tn=news&rsv_dl=ns_pc&word=%E4%B8%AD%E6%B2%B9%E8%B5%84%E6%9C%AC'
# 百度现在有时有ssl证书认证的问题,这就会导致请求发过去一直没有响应,卡住了(获取不到源代码),解决方法,把https换成httpres=requests.get(url,headers=headers).text
print(res)运行结果如图所示,可以看到我们已经获取到真正的网页源码了。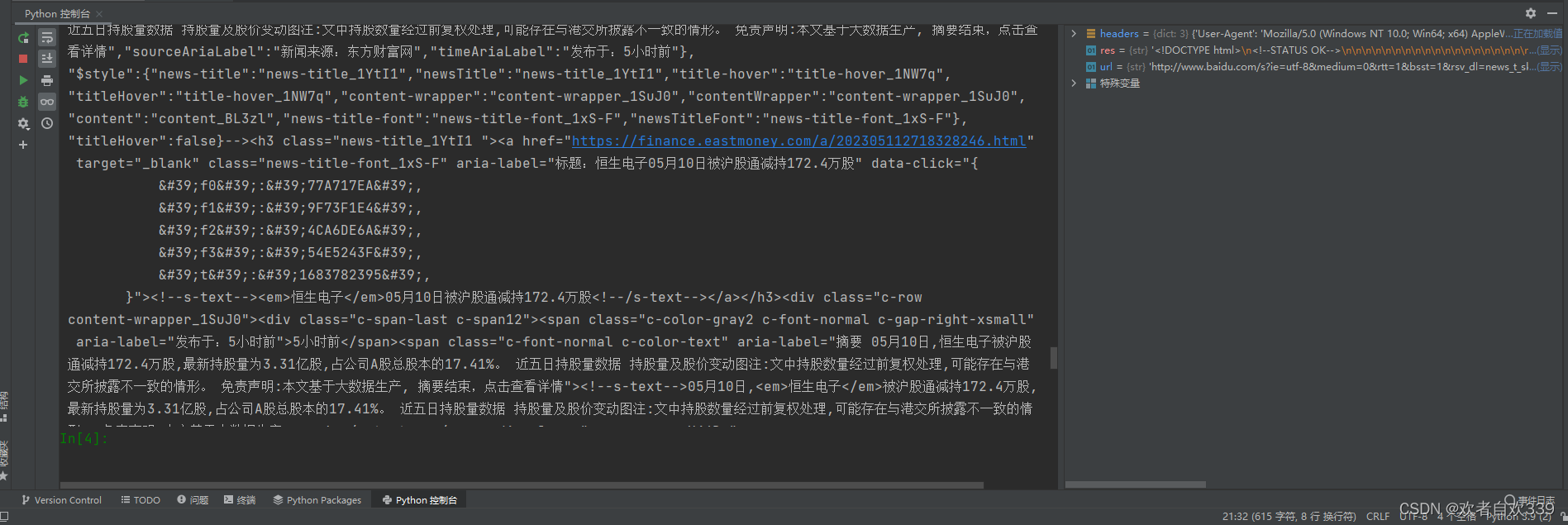
二、编写正则表达式分析并提取新闻信息
1、提取新闻来源及时间
通过观察网页源码文本,会发现每条新闻的来源和分布时间都夹存在<span class="c-color-gray"和<span class="c-color-gray2 c-font-normal c-gap-right-xsmall"后面的参数里面,因此可以利用这一个规律编写正则表达式提取信息并处理自动换行打印出来,代码如下:
p_source='<span class="c-color-gray" aria-label="(.*?)"'
p_info='<span class="c-color-gray2 c-font-normal c-gap-right-xsmall" aria-label="(.*?)"'
info=re.findall(p_info,res,re.S)
source=re.findall(p_source,res,re.S)
print(info)
print(source)2、新闻标题和链接网址
同样的道理来获取标题和网址,代码如下:
p_title='h3 class="news-title_1YtI1 ">.*?>(.*?)</a>'
p_href='<h3 class="news-title_1YtI1 ">.*?<a href="(.*?)"'
title=re.findall(p_title,res,re.S)
href=re.findall(p_href,res,re.S)
print(title)
print(href)最后代码输出结果内容打印如下: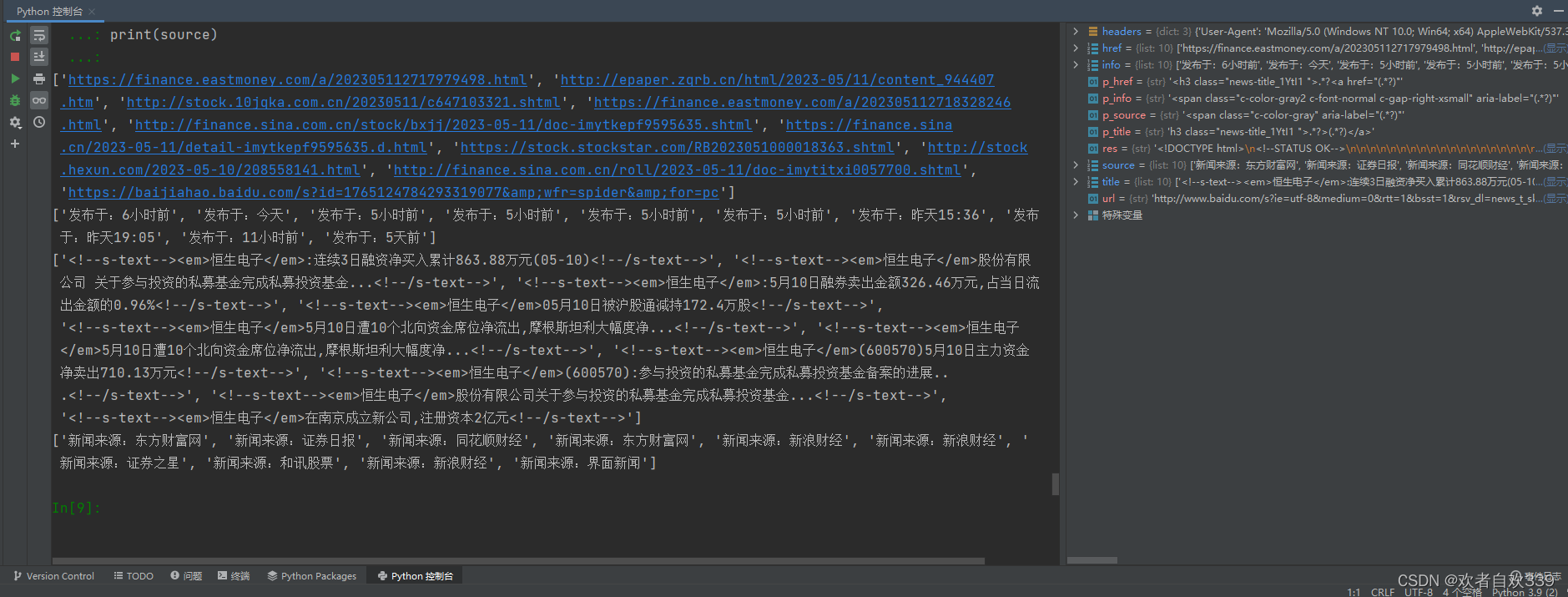
三、数据清洗并美化打印输出
从上图可以发现,抓取的新闻标题存在一些我们并不需要的文本,如<!--s-text--><em>和空格等一些HTML网页结构语句,这会影响到我们后面打印输出。所以我们需要对其进行数据清洗。首先是一些换行符和空格,我们利用python中的遍历方法遍历标题列表中的标题文本,用strip()函数对其清除。再利用sub()函数正则清理掉<!--s-text--><em>内容。此时我们还可以利用这个遍历方法顺便给爬取的数据进行整理和打印,代码如下:
for i in range(len(info)):title[i]=title[i].strip()title[i]=re.sub('<.*?>','',title[i])print(str(i+1)+'.'+title[i]+'('+source[i]+'_____'+info[i]+')')print(href[i])四、总结
以上就是关于百度新闻内容的爬取,由于百度网站的更新迭代,随时间推移,网页结构会发生改变,所以代码有时效性,但方法大同小异,注意结合实际情况修改脚本。其次,以上代码仅为教学示例,感兴趣的小伙伴也可以结合例子对其开拓,增加代码可玩性。以上完整代码如下:
import requests
import re
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36","Accept-Encoding": "gzip, deflate, br","Accept-Language": "zh-CN,zh;q=0.9"} # 用户代理设置
url='http://www.baidu.com/s?ie=utf-8&medium=0&rtt=1&bsst=1&rsv_dl=news_t_sk&cl=2&wd=%E6%81%92%E7%94%9F%E7%94%B5%E5%AD%90&tn=news&rsv_bp=1&rsv_sug3=10&rsv_sug1=7&rsv_sug7=101&oq=&rsv_sug2=0&rsv_btype=t&f=8&inputT=4345&rsv_sug4=5417'# 百度现在有时有ssl证书认证的问题,这就会导致请求发过去一直没有响应,卡住了(获取不到源代码),解决方法,把https换成http
res=requests.get(url,headers=headers).text
print(res)
p_href='<h3 class="news-title_1YtI1 ">.*?<a href="(.*?)"'
p_info='<span class="c-color-gray2 c-font-normal c-gap-right-xsmall" aria-label="(.*?)"'
p_title='h3 class="news-title_1YtI1 ">.*?>(.*?)</a>'
p_source='<span class="c-color-gray" aria-label="(.*?)"'
href=re.findall(p_href,res,re.S)
info=re.findall(p_info,res,re.S)
title=re.findall(p_title,res,re.S)
source=re.findall(p_source,res,re.S)
print(href)
print(info)
print(title)
print(source)
for i in range(len(info)):title[i]=title[i].strip()title[i]=re.sub('<.*?>','',title[i])print(str(i+1)+'.'+title[i]+'('+source[i]+'_____'+info[i]+')')print(href[i])
代码结果如图: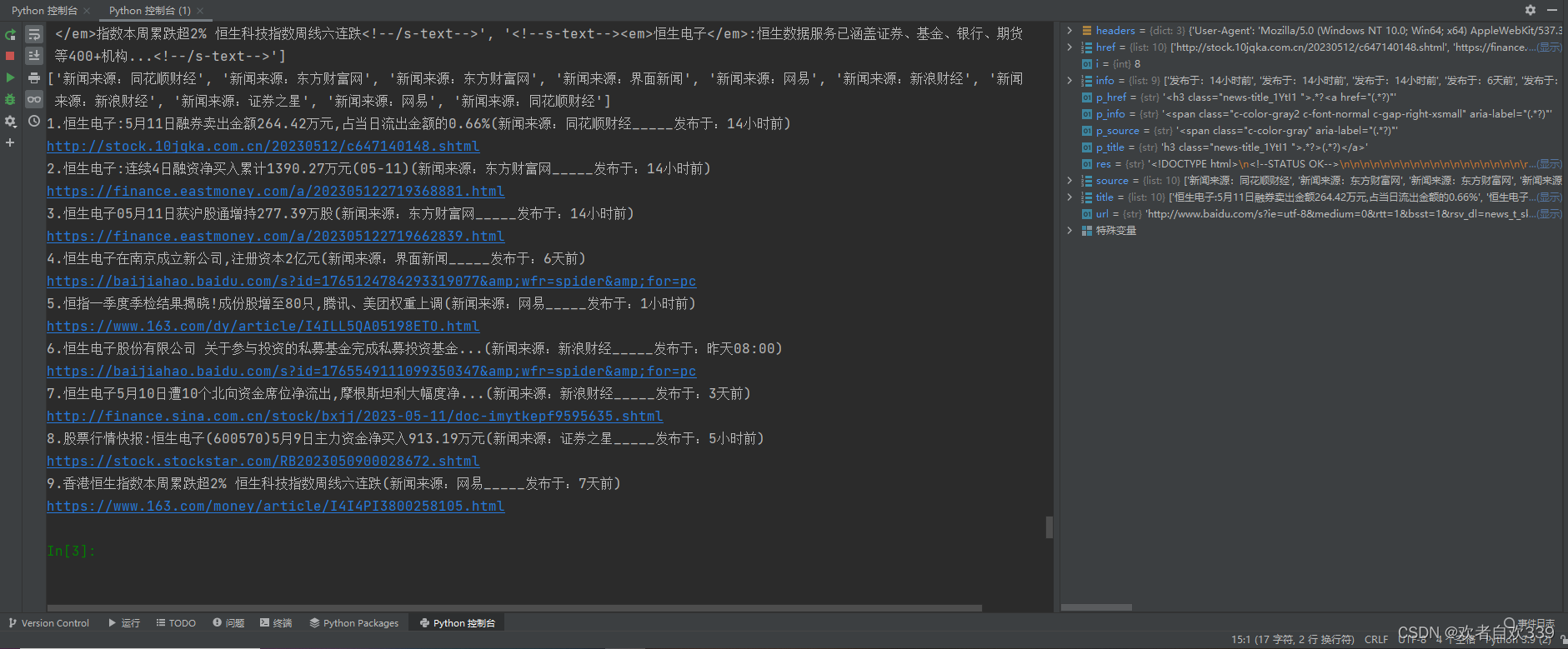
新人制作不易,您的点赞关注是唯一动力。
这篇关于百度新闻资讯挖掘案例实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





