本文主要是介绍产品分析 | 数据资产目录竞品分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、分析背景和目的
分析市场上主流的包含数据资产目录的产品,重新整理一篇竞品分析以供参考和学习。
二、版本信息

三、名词解释

四、需求背景
1. 产品现状
- 建设了数据资产目录,但是偏技术向,比较难用,细节流程上欠考虑。
- 元数据的采集不够灵活。
- 元数据管理难用,数据的审批欠考虑。
2. 用户调研
1)业务人员:有个数据分析需求,他们想要的是快速的查找相关数据,确定该数据就是自己要使用的。

B 端产品经理如何快速成长?
产品与业务架构主要是将整个业务工作流进行分层,梳理,然后抽象出一个个需求,将业务需求与产品合情合理的映射起来,最终使业务数据在产品中流动,执行,记录,使用。
查看详情 >
2)数据开发
- 想快速知道数据影响链路,评估修改的影响范围;数据错误,快速根据数据链路进行排查。
- 想了解哪些数据查看次数最多,哪些数据根本无人问津,哪些是重复建设的数据,指导数据开发对模型的调整。
3)领导:查看数据目录,了解数仓里有哪些数据,有多少数据,数仓建设的怎么样。
3. 竞品选择和分析
网易EasyData:https://study.sf.163.com/documents/read/EasyDataBook/easydmap.md
华为DataArt Studio:https://support.huaweicloud.com/usermanual-dataartsstudio/dataartsstudio_01_0804.html
阿里DataWorks:https://help.aliyun.com/zh/dataworks/user-guide/overview-10?spm=a2c4g.11186623.0.0.62b276162FMOXv
不同厂商的数据资产目录展示的数据实体都不一样,除了基础的表,字段外,其他可根据实际需求情况确定。
数据资产目录产品定位偏向:
- 产品卖点主要是,元数据可以通过其他系统直接采集。华为和阿里的数据资产目录产品定位主要是偏向这种形式,也是因为售卖配套的数据开发工具,数据资产目录是一个附属的产品。
- 产品定位更偏企业内部使用,主要靠手动维护以及自动采集部分元数据。网易的EasyData中的数据资产目录产品定位更偏向这个,在元数据使用和治理上做的更好。
对于我们来说,没有其他更多的系统做支撑。所以主要是对网易的EasyData进行产品分析和参考,且EasyData的功能和流程更符合业务使用逻辑。
五、需求说明
1. 业务架构图

2. 业务流程图
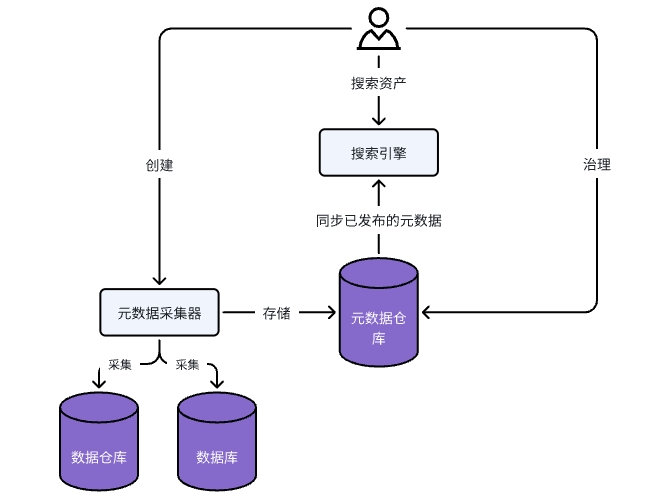
3. 产品信息架构

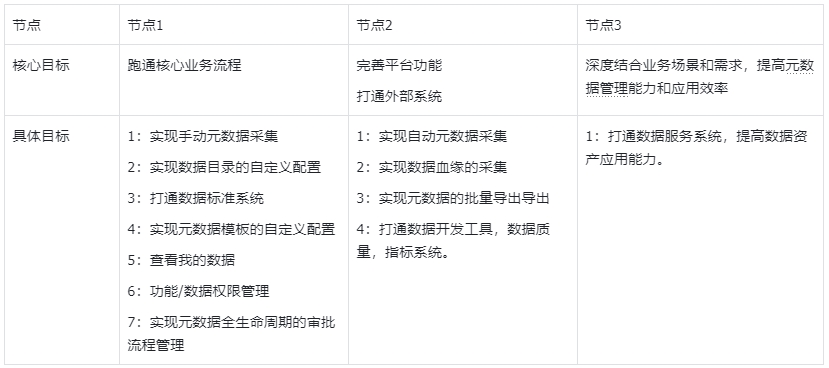
4. 产品路线图
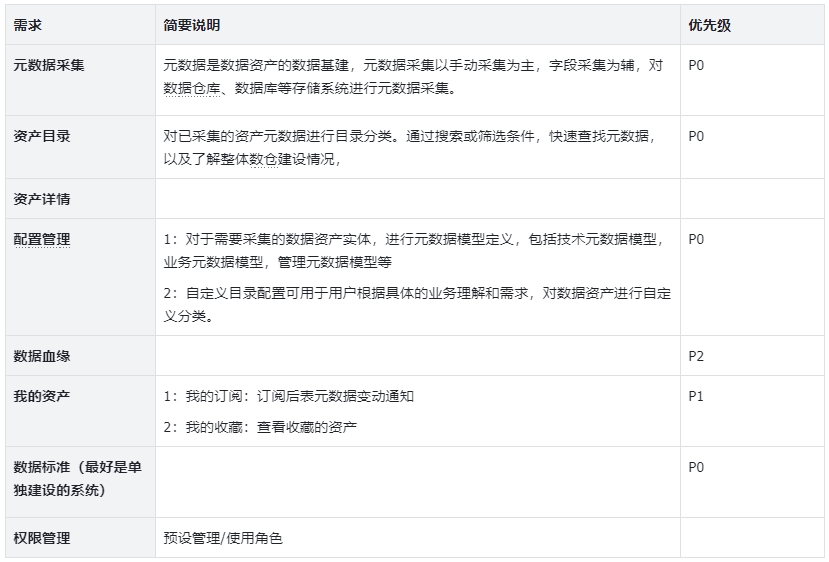
5. 需求清单
6. 用例图

六、功能详细说明
1. 配置管理
1)元数据模型配置
① 功能说明:对于需要采集的数据资产实体,进行元数据模型定义,包括技术元数据模型,业务元数据模型,管理元数据模型等等,根据实际需求和情况可写死,可做页面配置化。对于表来说,不同层级的表可以元数据有所差距,元数据模型可以只定义一套,属性可以定义为非必填。
② 功能结构

2)自定义目录配置
① 功能说明:自定义目录配置可用于用户根据具体的业务理解和需求,对数据资产进行自定义分类。
② 功能结构

2. 元数据管理
实现灵活的元数据的采集。
1)元数据采集
功能说明:元数据采集以手动采集为主,自动采集为辅,对数据仓库、数据库等存储系统进行元数据采集。
2)采集元数据主要流程(自动/手动)
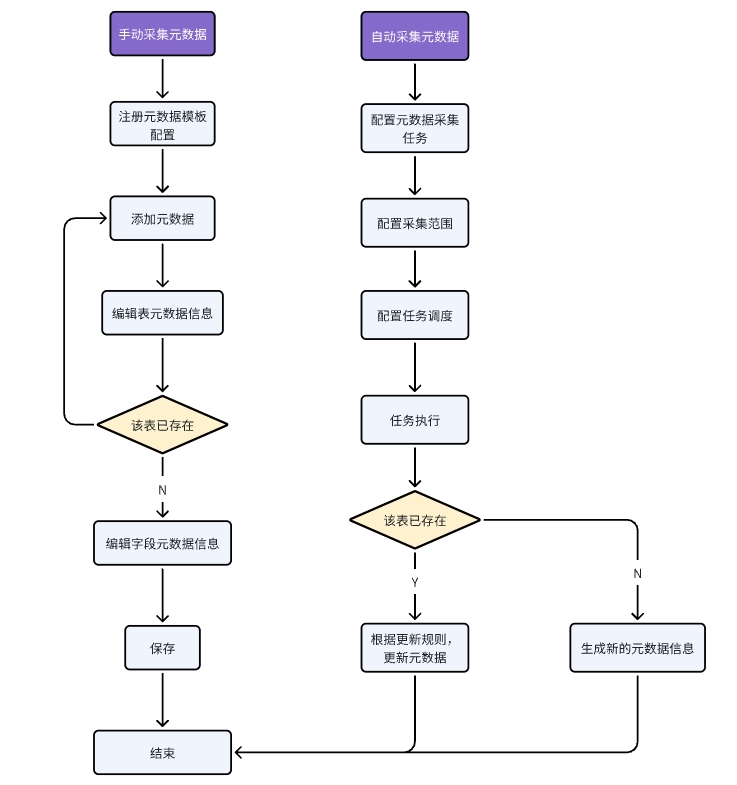
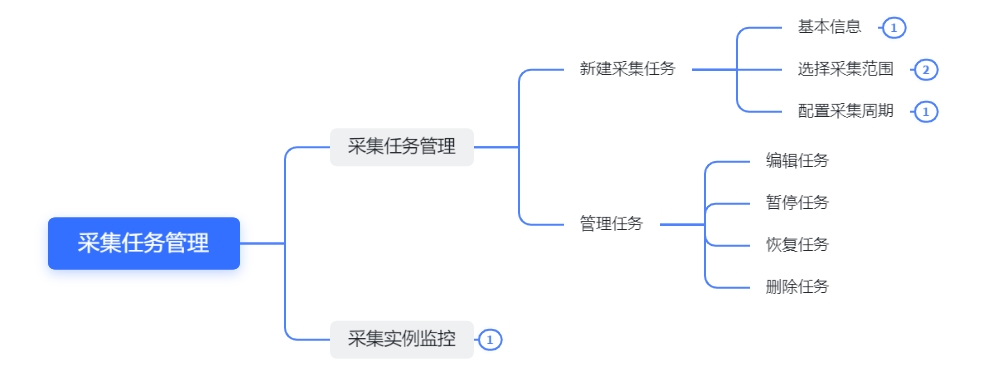
3)采集任务管理功能结构
当元数据采集任务未指定采集范围时,默认采集该数据连接下的所有数据表/文件。采集任务运行完成后,如果该数据连接下有新增数据表/文件,则需再次运行元数据采集任务,才能采集到新增数据表/文件的元数据。
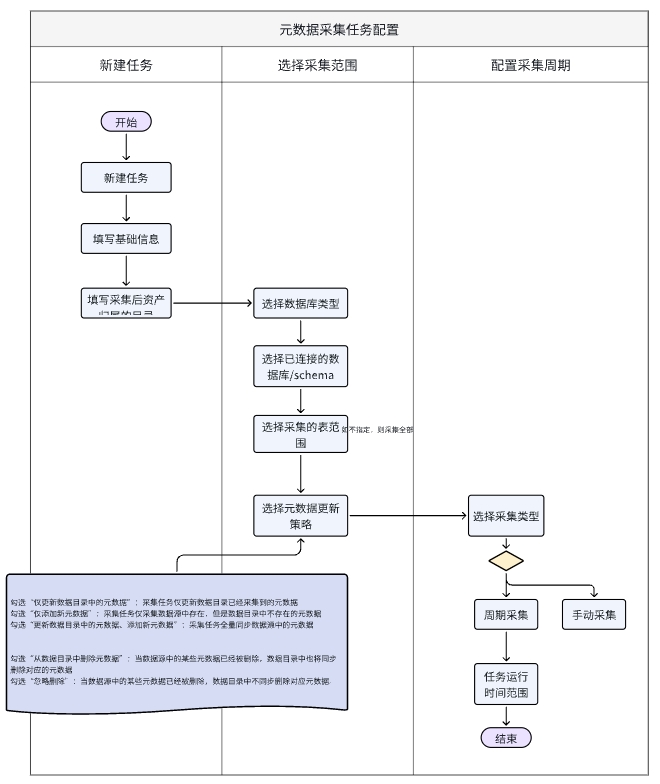
4)采集任务配置流程
网易EasyData元数据自动采集内容(图内信息肯定不全,可作参考):

5)说明
- 手动添加元数据后,可配置采集任务。周期性或手动更新相关元数据(数据源类型、数据源、表物理名称都一致的视为同一数据资产)。
- 由上图可见,在没有对接数据开发工具的情况下,可自动采集的元数据信息基础且有限,大部分元数据还得靠手动维护。
- 选择自动采集的元数据时,须保证机器自动采集的内容准确性。
3. 元数据治理流程(以网易EasyData为例)
治理流程和组织架构密不可分,审批流程贯穿治理流程。对于组织架构不完整的企业,可直接略过草稿状态。有点过于麻烦了。

数据资产状态图:
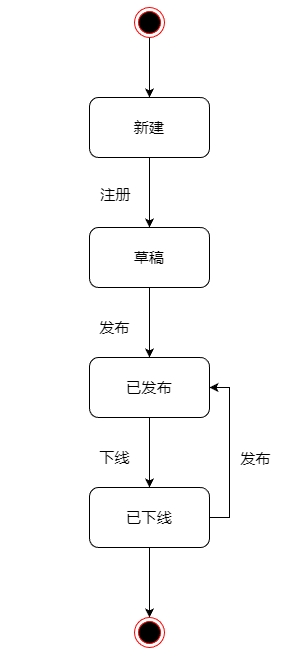
发布后才可以在资产目录中查询到,上线下线的版本均为同一版本,修改/治理后会生产新的版本,用来覆盖已发布/已下线版本
4. 数据目录
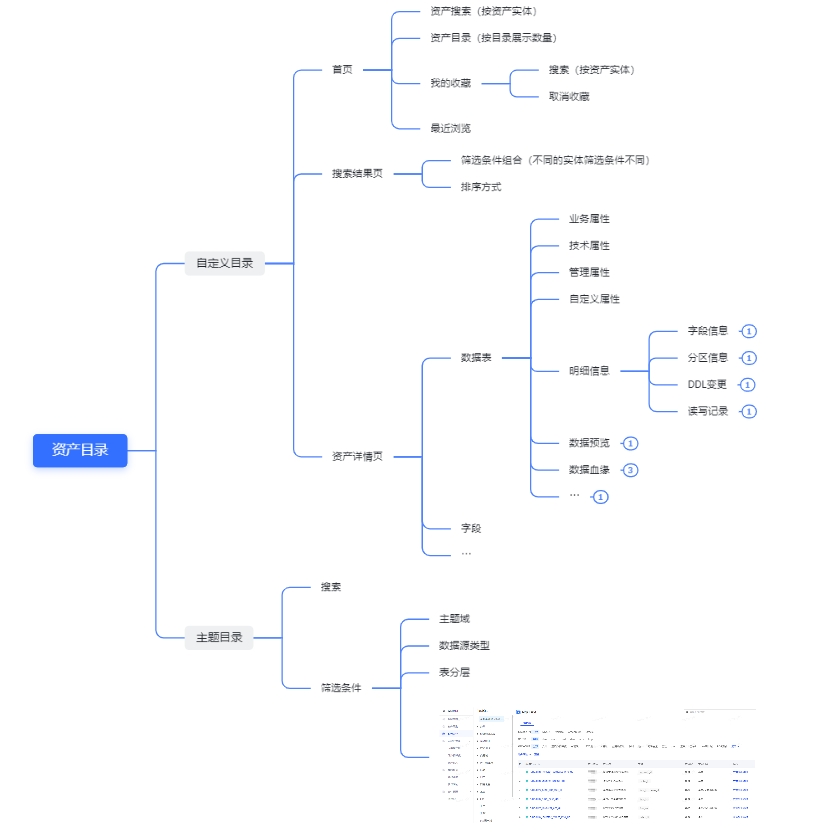
功能说明:元数据模型是数据目录的数据基建,数据目录围绕元数据基建,和业务场景做一系列的功能。
功能结构图:
5. 数据血缘
功能说明:对数据上下游链路图形化展示。
- 血缘视图种类:关系视图,列表视图。
- 血缘种类:表级血缘、字段级血缘(字段级血缘:EasyData字段血缘仅支持列表视图,且仅支持展示一张表,猜测是在实际业务中,字段血缘用图形化加载缓慢或会出现卡死,列表式可快速加载且使用不会卡顿)。
- 影响通知:变更影响通知到下游所有链路相关人员。
功能结构图:

6. 我的资产
1)我的订阅
订阅后,将会接收订阅资产元数据变动信息。

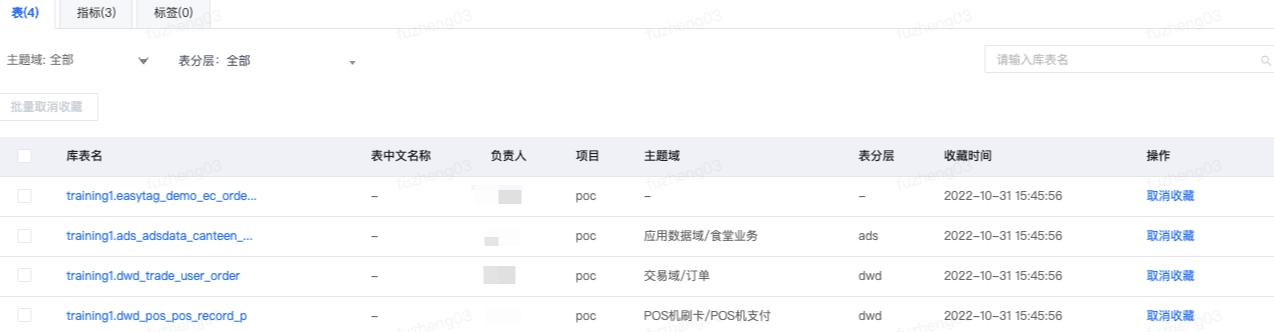
2)我的收藏
其他补充
- 数据标准一定要建设在数据资产目录前。
- 组织的建设,很大程度上决定数据资产维护的准确性和权威性。
作为一家专注于互联网领域的公司,我们的主要业务是进行互联网平台开发、定制开发,以及全网推广和平台包装。我们的专业团队拥有丰富的经验和强大的技术实力,可以满足各类企业和个人的需求。
在软件开发方面,我们秉持着用户至上的理念,致力于打造出既实用又易用的软件产品。我们有一套成熟的软件开发流程,从需求调研到设计、开发、测试、上线,每一环节都严格把控,以确保软件的品质。我们的服务覆盖了从移动应用、网站开发、微信小程序、企业级软件等各类项目。
在全网营销推广方面,我们运用最新的SEO技术与社交媒体营销策略,结合内容营销和大数据分析,为企业和个人提供全方位的网络推广解决方案。我们的目标是帮助企业和个人在互联网世界中获得更大的影响力和更高的知名度。
我们的成功案例丰富多样,包括零一空间、驯龙世界、趣吧、公仔乐园、花生日记、店流宝、玩转派对、比亚熊、星潮宇宙、湘旺世界、轻流、LDS魔法熊、龙珠有点潮、兽神记、云乐个游、鳄血素、乐趣生活、云巢国际、淘金之旅、趣盒、星际公民等主流平台。这些平台的成功运营,都离不开我们专业的软件开发和全网营销推广支持。
同时,我们也为多家企业和个人的提供了全套的互联网+方案,帮助他们实现了线上业务的快速增长。无论是电商平台还是社交平台,无论是在线教育还是在线娱乐,我们都有丰富的经验和成功的案例。
如果您有任何软件开发需求可以与我们联系
公众号(智创有术)
这篇关于产品分析 | 数据资产目录竞品分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






