本文主要是介绍毕业设计-基于机器视觉的眼底视网膜血管语义分割-U-net,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
课题背景和意义
实现技术思路
一、图像预处理(Image preprocessing)
二、U-net网络模型(U-net network model)
三、实验结果与分析(Experimental results and analysis)
四、总结(Conclusion)
实现效果图样例
最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于机器视觉的眼底视网膜血管语义分割-U-net
课题背景和意义
眼底血管与人体健康息息相关,同时也作为医生诊断各 类眼科疾病以及心脑血管疾病的重要依据。眼底视网膜血管 结构特征变化与高血压、动脉硬化等心脑血管疾病有着密切 的联系,医生借助计算机图像处理技术,可以自动获取到眼 底图像中的血管形态。眼底图像血管提取的传统方法有匹配 滤波方法、阈值分割方法、形态学处理方法等。这些方法不 需要训练模型,但是血管分割的精度不够高。基于机器学习 的方法利用人工标记的血管图像来训练模型,以实现血管的 提取,Staal利用KNN(K-Nearest Neighbor)分类器来区分血 管的半径、亮度和边缘强度等特征信息。潘林等[2]为了克服光 照不均、对比度低以及病灶干扰等问题,提出了Gabor小波和 SVM(Support Vector Machines)分类器相结合的方法,利用多 种尺度的Gabor滤波特征和绿色通道灰度信息组成特征向量进 行降维,然后用SVM分类来区分血管。 近年来,卷积神经网络在图像处理领域取得了突破性。
实现技术思路
一、图像预处理(Image preprocessing)
为了下游分割任务更顺利地进行,我们先对图像进行 预处理。文献[3]单通道能够更加清晰地体现眼背景差异。 因此,在实验中将3通道图像按比例转换为灰度图像。原始 图像中血管与背景的对比度较弱,血管边界模糊,眼底图像 对比度较低,不易于人眼分辨。
使用OpenCv库中cv2.createCLAHE(clipLimit, titleGridSize)来实现这一功能。clipLimit是限制对比度阈值, 默认为40,直方图中像素值出现次数大于该阈值,多余的次 数会被重新分配;titleGridSize表示图像进行像素均衡化的网 格大小。经过上述操作后,可弱化眼底图像中的背景,提升 图像中血管区域的灰度,可以更清楚地显示血管结构。效果图如图所示。
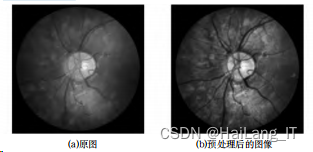
二、U-net网络模型(U-net network model)
网络结构
U-net网络结构呈U字形,由卷积和池化单元构成。左 半边为编码器即如传统的分类网络是下采样阶段,右半边为 解码器是上采样阶段,中间的箭头为跳跃连接,将浅层的特 征与深层的特征进行拼接。因为浅层提取到图像的一些简单特征,比如边界、颜色等。
深层经过的卷积操作多抓取到图 像的一些高级抽象特征。跳跃连接将编码器中获得特征信息 引入到对应的解码器中,为上采样提供了更多低层次的空间 与信息。这些低级的信息通常为轮廓和位置等,为后期图像 分割提供多尺度多层次的信息,由此可以得到更精细的分割 效果。U-net的网络结构如图所示。
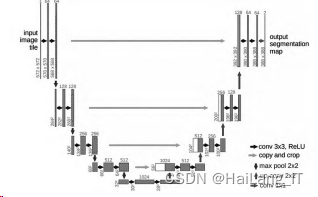
U-net为Encoder-Decoder结构。在编码器部分,采用五 个卷积模块进行特征提取。每个模块中的卷积层后都紧随批 归一化层,其作用是调整网络中的数据分布,防止出现数据 的“协变量漂移问题”,防止过度拟合。每个模块中的卷积 层中卷积核的个数分别为32、64、128、256、512。
池化层用 于对特征进行降维,在保持通道不变的情况下,将尺寸缩小 为输入特征的一半。经过编码器后,得到输入图像的高级特 征向量,将特征向量传入到解码器中。编码器部分采用ReLU 函数。
U-net改进
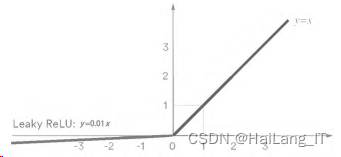
U-net中使用的激活函数为ReLU函数,ReLU函数定义 为y=max(0,x),对于所有正值,ReLU是线性的,对于所有负 值,经过ReLU计算后是0。由于没有复杂的数学运算,收敛 更快,模型可以花费更少的时间训练。Leaky ReLU函数图像如图所示。
模型优化器选择
算法模型需要选择合适的优化器进行参数的学习来使损 失函数不断减小。现有的U-net分割模型使用的是随机梯度下 降法(Stochastic Gradient Descent, SGD),梯度通过每一次 的迭代下降来更新网络中的参数。但是SGD的缺点是难以选 择合适的学习率,并且容易收敛到局部最优点。 为了解决上述问题,使用Adam优化器替代SGD 来进行模型参数权重的更新。如式所示:
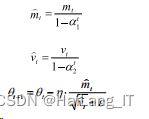
评价指标
语义分割通常使用平均交并比这个指标来评估语义分割 算法的性能。交并比(Intersection over Union, IoU)表示的 含义是模型对某一类别预测结果和真实值的交集与并集的比 值。IoU的计算公式如下:
![]()
式中,TP表示正确识别为正类的像素个数;FP表示错误识别为正类的像素个数;FN表示错误识别为负类的像素个数。然 后重复计算其他类别的IoU,再计算它们的平均数,计算公式 如下:
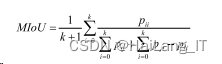
式中,k表示类别,k+1表示加上了背景类,i表示真实值,j表 示预测值, 表示将i预测为j,为假负(FN); 将j预测为i,为 假正(FP); 将i预测为i,为真正(TP)。因此可以等价于式。
![]()
三、实验结果与分析(Experimental results and analysis)
实验环境
眼底血管分割程序运行环境为Ubuntu 18.04,使用 Pytorch作为深度学习框架,VsCode作为程序编辑器;硬 件平台为AMD Ryzen 16核CPU,主频3.6 GHz,显卡是4 张 GeForce RTX 2080Ti,每张卡显存为12 GB。
数据集制作
眼底图像数据分别选取开源数据集CHASE和DRIVE数据 集进行实验,从两个数据集中分别选取100 对左右眼共计400 幅图像。然后统一将大图分割为256×256的小块,一是为了 增加数据量,二是通过裁减而不是采样的方式可以保留原图 的细节特征。最终获得1,600 幅图像。再按照8:2将上述图像 划分为训练集和测试集。
实验结果分析
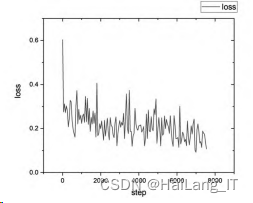
设置batch_size=4,初始学习率取0.001。同时为了防止过 拟合,本文采用L2正则化,将权重衰减稀疏设置为0.0001。 然后训练本文算法模型,训练过程中的损失函数变化情况如 图4所示。由图4显示的训练过程迭代次数损失曲线发现,训 练迭代3万次后,损失值基本围绕0.15进行上下波动,随着迭 代次数的增加,波动减小,损失值趋于稳定。
为了验证本文提出的算法在眼底血管分割上是否具有优 势,实验选取了与FCN及U-net算法进行对比。表1中给出了 本文算法与其他算法的分割效果对比。
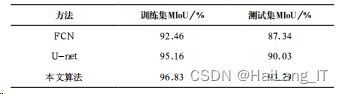
采用改进的U-net算法模型表现相对较 好,在原始U-net网络进行低级语义信息和高级语义信息融合 阶段,使用Leaky ReLU函数有效避免了神经元趋于“坏死” 的问题,改善了算法模型的稀疏性,从而在训练集和测试集 上MIoU值均有一定的提升,获取了更好的语义分割结果。另 外,从实验结果看,U-net算法分割的MIoU值远高于FCN算 法,可见U型网络[8]结构更适用于医疗图像的分割任务。
因为训练前将图像分割成许多块,所以在模型预测 完成后需要将预测结果进行合并,获取完整的推理图像, 然后与label进行比较。拼接后的分割结果如图所示,图(a)、图(b)、图(c)、图(d)依次是原图、预处理图、标 记图和预测图。

四、总结(Conclusion)
基于U-net图像分割算法,对于眼底图像中的血管 进行提取。首先,从两种开源的数据集中选取数据制作数据 集,其目的是丰富数据集的多样性,提高模型的泛化能力。 然后,针对U-net特征提取层中ReLU函数在模型训练时可能 存在的“神经元坏死”的情况,使用Leaky ReLU替代ReLU 函数,保留了特征中的负值信息,可以让模型学习到更多的 细节信息。
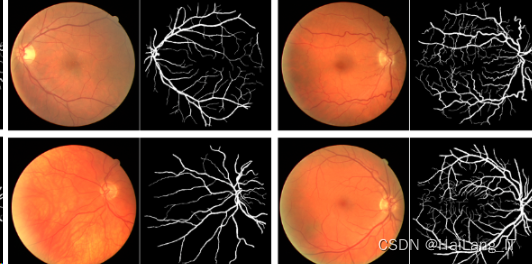
实现效果图样例
眼底视网膜血管语义分割:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
这篇关于毕业设计-基于机器视觉的眼底视网膜血管语义分割-U-net的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






