本文主要是介绍【Swin-Transformer学习】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Swin-Transformer学习笔记
参考链接:
https://blog.csdn.net/qq_37541097/article/details/121119988
【机器学习】详解 Swin Transformer (SwinT) 链接: link
B站视频 链接: link
1、Swin Transformer简介
Swin Transformer名字的前部分Swin来自于Shifted Windows,Shifted Windows(移动窗口)也是Swin Transformer的主要特点。Swin Transformer的作者的初衷是想让Vision Transformer像卷积神经网络一样,也能够分成几个block做层级式的特征提取,从而导致提出来的特征具有多尺度的概念。
标准的Transformer直接用到视觉领域有一些挑战,难度主要来自于尺度不一和图像的resolution较大两个方面。首先是关于尺度的问题,例如一张街景的图片,里面有很多车和行人,并且各种物体的大小不一,这种现象不存在于自然语言处理。再者是关于图像的resolution较大问题,如果以像素点为基本单位,序列的长度就变得高不可攀,为了解决序列长度这一问题,科研人员做了一系列的尝试工作,包括把后续的特征图作为Transformer的输入或者把图像打成多个patch以减少图片的resolution,也包括把图片划成一个一个的小窗口,然后再窗口里做自注意力计算等多种办法。针对以上两个方面的问题,Swin Transformer网络被提出,它的特征是通过移动窗口的方式学来的,移动窗口不仅带来了更大的效率,由于自注意力是在窗口内计算的,所以也大大降低了序列的长度,同时通过Shiting(移动)的操作可以使相邻的两个窗口之间进行交互,也因此上下层之间有了cross-window connection,从而变相达到了全局建模的能力。
层级式结构的好处在于不仅灵活的提供各种尺度的信息,同时还因为自注意力是在窗口内计算的,所以它的计算复杂度随着图片大小线性增长而不是平方级增长,这就使Swin Transformer能够在特别大的分辨率上进行预训练模型。
2、Swin Transformer模型原理
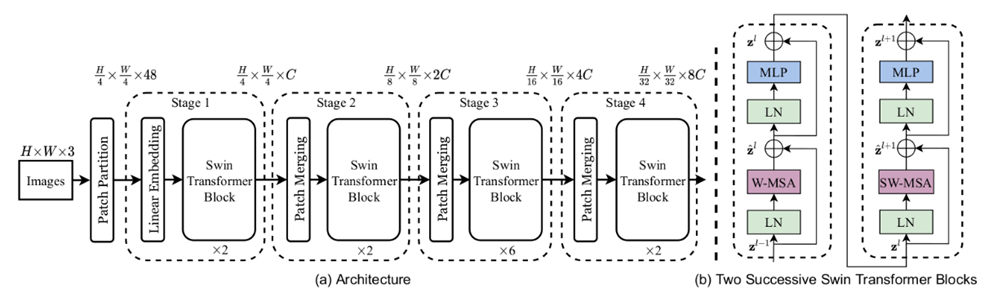
输入:是RGB图(维度H×W×3)。
Patch Partition:通过一个patch切分模块对输入图进行切分成一个没有重叠的patches。每个patch当作一个“token”,它的特征是原始RGB值的一个concatenation. 比如,patch是4×4,那么每个patch的特征的维度就是443 = 48。 其中,H * W * 3 = H/4 * W/4 * 48。
Stage 1: Linear Embeding + Swin Transformer Block
Linear Embeding层:人为设定维度。使得raw-valued feature 投射(project)到任意维度,图中用C表示。
Swin Transformer Block:保持tokens 的数目 = H/4 * W/4。
故,输出维度就是H/4 * W/4 * C。
Stage 2:patch merging + Swin Transformer Block
patch merging: 联结(concatenates)每组2 x 2的相邻的patches的特征,并且在4C维度的联结后的特征上应用用一个线性层。这降低了4倍的tokens数量,其中4 = 2×2,2是倍下采样的倍数。 concatenate之后,H/4 变成 H/8, W/4变成W/8,而 patch token 的维度则扩大 倍,即 4C。然后,对 4C 维的 patch 拼接特征使用了一个线性层,将输出维度降为 2C。接下来Swin Transformer Block用于特征转换(feature transformation),保持 H/8 * W/8。
重复 2 次与 Stage 2 相同过程,则分别指定为 Stage 3 和 Stage 4。输出分辨率 / patch token 数 则分别为H/16 * W/16和 H/32 * W/32。每个 Stage 都会改变张量的维度,从而形成一种层次化的表征。由此,该架构可方便地替换现有的各种视觉任务的主干网络。
3、Swin Transformer block
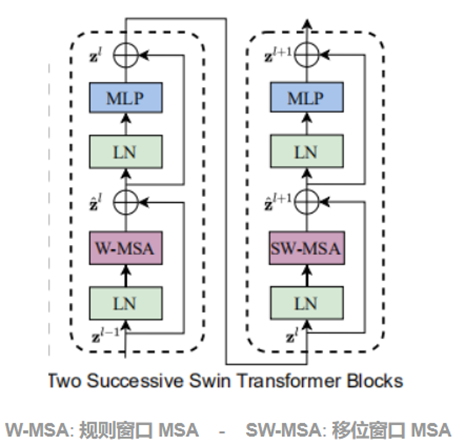
Swin Transformer 相比于 Transformer block (例如 ViT),将标准多头自注意力模块 (MSA) 替换为基于移位窗口的多头自注意力模块 (W-MSA / SW-MSA) 且保持其他部分不变。如上图所示,一个 Swin Transformer block 由一个 基于移位窗口的 MSA 模块 构成,且后接一个夹有 GeLU 非线性在中间的 2 层 MLP。LayerNorm (LN) 层被应用于每个 MSA 模块和每个 MLP 前,且一个 残差连接 被应用于每个模块后。
4、Patch Merging详解
前面有说,在每个Stage中首先要通过一个Patch Merging层进行下采样(Stage1除外)。如下图所示,假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。

5、 W-MSA详解
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。如下图所示,左侧使用的是普通的Multi-head Self-Attention(MSA)模块,对于feature map中的每个像素(或称作token,patch)在Self-Attention计算过程中需要和所有的像素去计算。但在图右侧,在使用Windows Multi-head Self-Attention(W-MSA)模块时,首先将feature map按照MxM(例子中的M=2)大小划分成一个个Windows,然后单独对每个Windows内部进行Self-Attention。

两者的计算量具体差多少呢?原论文中有给出下面两个公式,这里忽略了Softmax的计算复杂度:
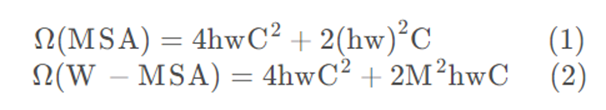
h代表feature map的高度
w代表feature map的宽度
C代表feature map的深度
M代表每个窗口(Windows)的大小
6、SW-MSA详解
前面有说,采用W-MSA模块时,只会在每个窗口内进行自注意力计算,所以窗口与窗口之间是无法进行信息传递的。为了解决这个问题,作者引入了Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,即进行偏移的W-MSA。如下图所示,左侧使用的是刚刚讲的W-MSA(假设是第L层),那么根据之前介绍的W-MSA和SW-MSA是成对使用的,那么第L+1层使用的就是SW-MSA(右侧图)。根据左右两幅图对比能够发现窗口(Windows)发生了偏移(可以理解成窗口从左上角分别向右侧和下方各偏移了⌊ M/ 2 ⌋个像素)。看下偏移后的窗口(右侧图),比如对于第一行第2列的2x4的窗口,它能够使第L层的第一排的两个窗口信息进行交流。再比如,第二行第二列的4x4的窗口,他能够使第L层的四个窗口信息进行交流,其他的同理。那么这就解决了不同窗口之间无法进行信息交流的问题。
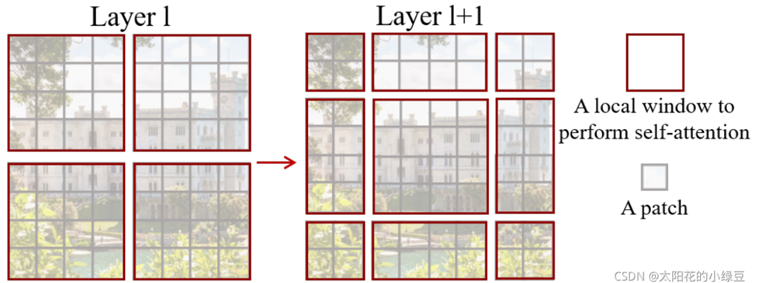
根据上图,可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后面又要对每个窗口内部进行MSA,这样做感觉又变麻烦了。为了解决这个麻烦,作者又提出而了Efficient batch computation for shifted configuration,一种更加高效的计算方法。下面是原论文给的示意图。

感觉不太好描述。下图左侧是刚刚通过偏移窗口后得到的新窗口,右侧是为了方便大家理解,对每个窗口加上了一个标识。然后0对应的窗口标记为区域A,3和6对应的窗口标记为区域B,1和2对应的窗口标记为区域C。
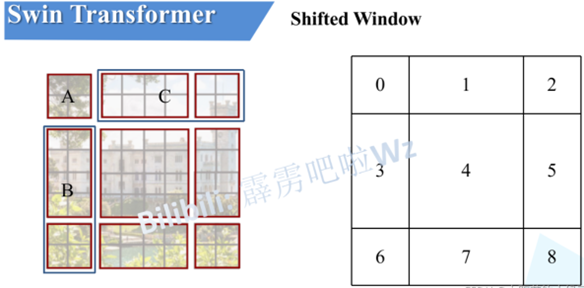
然后先将区域A和C移到最下方。

接着,再将区域A和B移至最右侧。
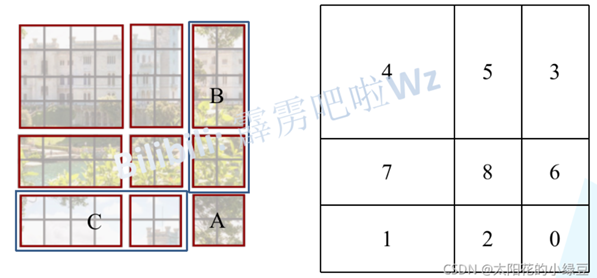
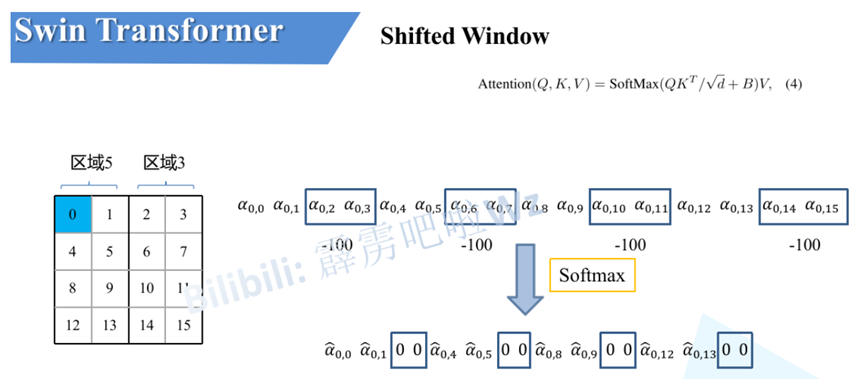
移动完后,4是一个单独的窗口;将5和3合并成一个窗口;7和1合并成一个窗口;8、6、2和0合并成一个窗口。这样又和原来一样是4个4x4的窗口了,所以能够保证计算量是一样的。这里肯定有人会想,把不同的区域合并在一起(比如5和3)进行MSA,这信息不就乱窜了吗?是的,为了防止这个问题,在实际计算中使用的是masked MSA即带蒙板mask的MSA,这样就能够通过设置蒙板来隔绝不同区域的信息了。关于mask如何使用,可以看下下面这幅图,下图是以上面的区域5和区域3为例。

7、相对位置偏置
根据论文中提供的公式可知是在Q和K进行匹配并除以根号下d后加上了相对位置偏执B
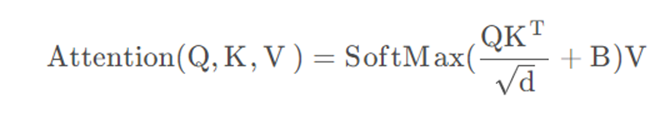
由于论文中并没有详解讲解这个相对位置偏执,所以我自己根据阅读源码做了简单的总结。如下图,假设输入的feature map高宽都为2,那么首先我们可以构建出每个像素的绝对位置(左下方的矩阵),对于每个像素的绝对位置是使用行号和列号表示的。比如蓝色的像素对应的是第0行第0列所以绝对位置索引是 (0,0),接下来再看看相对位置索引。首先看下蓝色的像素,在蓝色像素使用q与所有像素k进行匹配过程中,是以蓝色像素为参考点。然后用蓝色像素的绝对位置索引与其他位置索引进行相减,就得到其他位置相对蓝色像素的相对位置索引。例如黄色像素的绝对位置索引是 (0,1),则它相对蓝色像素的相对位置索引为( 0 , 0 ) − ( 0 , 1 ) = ( 0 , − 1 )。那么同理可以得到其他位置相对蓝色像素的相对位置索引矩阵。同样,也能得到相对黄色,红色以及绿色像素的相对位置索引矩阵。接下来将每个相对位置索引矩阵按行展平,并拼接在一起可以得到下面的4x4矩阵 。
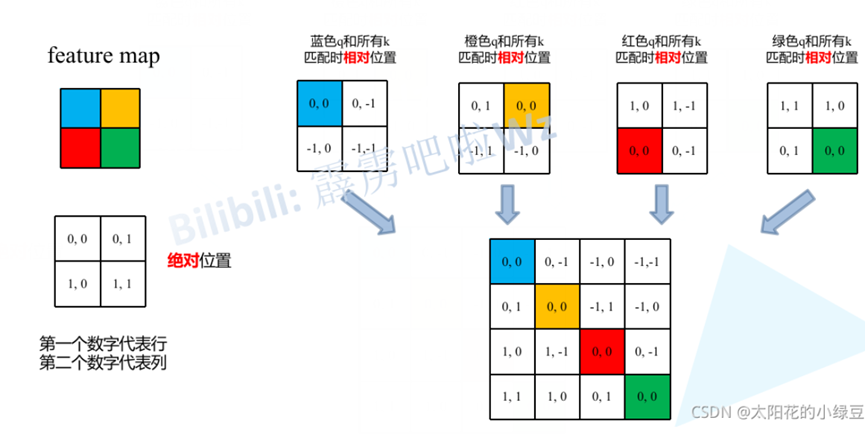
请注意,我这里描述的一直是相对位置索引,并不是相对位置偏执参数。因为后面我们会根据相对位置索引去取对应的参数。比如说黄色像素是在蓝色像素的右边,所以相对蓝色像素的相对位置索引为 (0, -1)。绿色像素是在红色像素的右边,所以相对红色像素的相对位置索引为 (0, -1)。可以发现这两者的相对位置索引都是 (0, -1),所以他们使用的相对位置偏执参数都是一样的。其实讲到这基本已经讲完了,但在源码中作者为了方便把二维索引给转成了一维索引。具体这么转的呢,首先在原始的相对位置索引上加上M-1(M为窗口的大小,在本示例中M=2),加上之后索引中就不会有负数了。
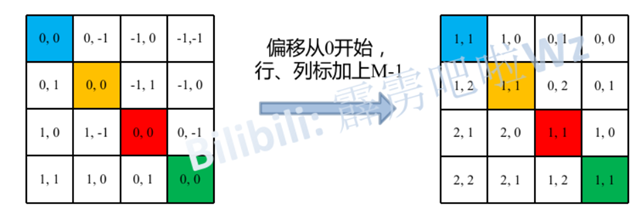
接着将所有的行标都乘上2M-1。

最后将行标和列标进行相加。这样即保证了相对位置关系,而且不会出现0 + ( − 1 ) = ( − 1 ) + 0的问题了。
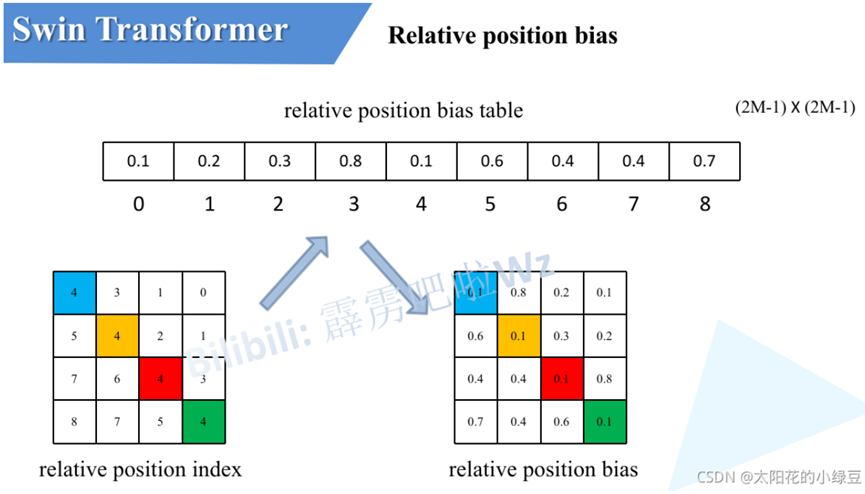
刚刚上面也说了,之前计算的是相对位置索引,并不是相对位置偏执参数。真正使用到的可训练参数B ^是保存在relative position bias table表里的,这个表的长度是等于( 2 M − 1 ) × ( 2 M − 1 )的。那么上述公式中的相对位置偏执参数B是根据上面的相对位置索引表根据查relative position bias table表得到的,如下图所示。
8、模型详细配置参数
下图是原论文中给出的关于不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large),其中:
win. sz. 7x7表示使用的窗口(Windows)的大小
dim表示feature map的channel深度(或者说token的向量长度)
head表示多头注意力模块中head的个数

这篇关于【Swin-Transformer学习】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









