本文主要是介绍结构方程模型(SEM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
结构方程模型(Structural Equation Modeling)是分析多变量间因果关系的利器,在众多学科领域具有巨大应用潜力。我们前期推出的《基于R语言结构方程模型》课程通过结构方程原理介绍、结构方程全局和局域估计、模型构建和调整、潜变量分析、复合变量分析及结构方程贝叶斯方法实现等一系列专题的介绍及大量案例讲解,由浅入深地系统介绍了结构方程模型的建立、拟合、评估、筛选和结果展示全过程,得到学员广泛认可。经过大家课后进一步交流和反馈,利用结构方程模型建模过程往往遇到很多‘特殊’情况:1)变量间为非直线关系;2)变量间存在交互作用;3)数据不满足正态分布;3)变量为非正态类型的数值变量,如0,1数据(符合二项分布)和计数数据(符合泊松分布)等等;4)外生或内生变量为分类变量,如男女、高中低、不同土地类型或森林类型等。在《基于R语言结构方程模型》课程中我们对变量非直线关系和非正态变量及数据分析做了初步介绍,但大家在遇到这些情况时仍然存在很大困惑。这些情况往往需要进行特殊处理,针对上述问题进行更深入的讲解,使大家在利用结构方程模型建模遇到上述情况时能够从容面对。
靳老师:180-3121-1455 微信
专题一、非线性、非正态、交互作用及分类变量分析
专题二、嵌套分层数据及数据分组分析
专题三、空间自相关数据分析技术
专题四、非递归(non-recursive)结构方程模型实践技术
专题五、系统发育数据纳入结构方程模型技术实践
专题六、时间重复测量数据分析
专题七、结构方程模型预测问题-直接预测实现途径
专题八、论文撰写、注意事项及常见问题实例解析
课程一:结构方程模型(SEM)高阶应用暨非线性、非正态、交互作用及分类变量分析
利用结构方程模型建模往往遇到很多‘特殊’情况:1)变量间为非直线关系;2)变量间存在交互作用;3)数据不满足正态分布;4)变量为非正态类型的数值变量,如0,1数据(符合二项分布)和计数数据(符合泊松分布)等等;5)外生或内生变量为分类变量,如男女、高中低、不同土地类型或森林类型等。在《基于R语言结构方程模型》课程中我们对变量非直线关系和非正态变量及数据分析做了介绍,但大家在遇到这些情况时仍然存在很大困惑。这些情况往往需要进行特殊处理,将针对上述问题进行更深入的讲解,使大家在利用结构方程模型建模遇到上述情况时能够从容面对。
一:非线性关系及交互作用分析
1、外生变量非线性关系处理
2、内生变量非线性关系处理
3、变量间存在交互作用关系分析
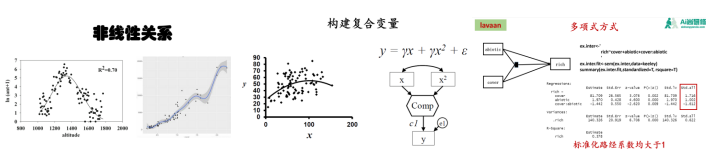
二:非正态数据/变量分析
1、数据/变量非正态问题
2、非正态数据分析
3、非正态变量变量分析

三:分类变量分析
1、分类变量介绍
2、外生变量为分类变量分析
3、内生变量为分类变量分析

课程二:结构方程模型(SEM)高阶应用暨嵌套分层数据及数据分组分析
在科研工作中获取的数据往往具有嵌套/分层/多水平结构特点,这类数据结构违背了数据独立性假设,直接利用一般回归(或广义回归)和结构方程模型分析时得到的结果不可靠,需要进行修正。在回归分析中需要利用混合效应模型(嵌套模型或多水平模型)进行分析,修正数据不独立对结果的影响。本次课程首先将详细探讨利用结构方程模型分析嵌套/多水平/分层数据。另外,利用结构方程模型对数据进行分组分析在处理分层数据也是有效手段,分组分析的优点在于可以在统一的模型框架下将数据进行分组分析,对样本量较小的研究尤为有效,它还可以检验不同分组参数的差异的显著性,用以对比分析。因此,课程中同时包含了结构方程模型数据分组分析,我们通几个实例对数据分组分析进行深入介绍,使大家在遇到嵌套/分层/多水平数据结构时多一个选择。
一:嵌套/分层/多水平数据回归分析基本原理
1、嵌套/多水平/分层数据概述
2、混合效应模型分析嵌套/多水平/分层数据基本原理
3、贝叶斯方法分析嵌套/多水平/分层数据基本原理
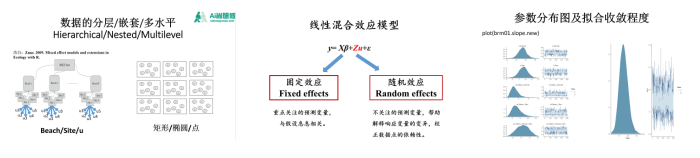
二:结构方程模型嵌套/分层/多水平数据分析
1、嵌套/多水平/分层数据结构结方程模型实现途径
2、均衡和不均衡嵌套/多水平/分层数据嵌套数据结方程模型实例
3、潜变量模型嵌套/多水平/分层数据分析

三:结构方程模型数据分组分析
1、数据分组与嵌套/分层/多水平及分类变量的区别与联系
2、结构方程模型数据分组分析
3、潜变量模型数据分组分析

课程三:结构方程模型(SEM)高阶应用暨空间自相关数据分析技术
采样样点通常包含空间信息,距离相近两个样点相似度要高于距离远样点间相似度,此即为空间自相关。空间自相关使样本违背了独立性假设。因而在建模过程中需要考虑空间自相关对结果的影响,排除空间自相关对模型造成的有偏结果。本课程将针空间数据表现出来的空间自相关特点,详细探讨结构方程模型全局估计法、局域估计法及贝叶斯法对空间自相关数据的处理方式和过程。
一:空间自相关数据回归模型分析
1、数据空间自相关概述
2、回归(混合效应)模型处理空间自相关数据
3、贝叶斯方法处理空间数据

二:空间自相关数据结构方程上:局域估计法
1、局域估计法纳入空间自相关的基本原理
2、局域估计法(piecewiseSEM和brms)对空间自相关数据的分析

三:空间自相关数据结构方程下:全局估计法
1、全局估计法(lavaan)对空间自相关数据分析基本原理
2、全局估计法对空间自相关分析实例讲解
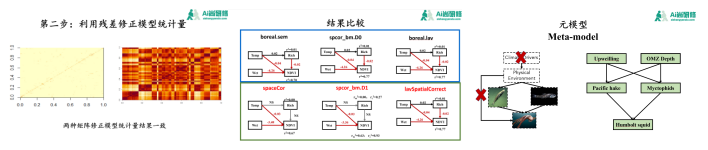
课程四:非递归(non-recursive)结构方程模型实践技术
结构方程模型(Structural Equation Modeling)是分析多变量间因果关系的利器,在众多学科领域具有巨大应用潜力。我们前期推出的《基于R语言结构方程模型》课程中所涉及内容均为递归模型。实际上在构建结构方程元模型过程中,通过文献调研后会发现2个变量存在交互作用(Reciproral Interaction),比如如A影响B,B反过来也影响A;也会出现3个变量间循环交互作用(Interaction Loop),比如A影响B,B影响C,C反过来影响A。这两种情况在结构方程模型中称为非递归(non-recursive)模型。本次课程将针对非递归结构方程型进行进一步讲解,我们将通过几个经典案例详解非递归结构方程模型建模过程。
1、递归模型与非递归模型区别 2、非递归模型分析注意事项及实现途径
3、非递归模型经典案例讲解 4、贝叶斯法(brms)实现非递归模型
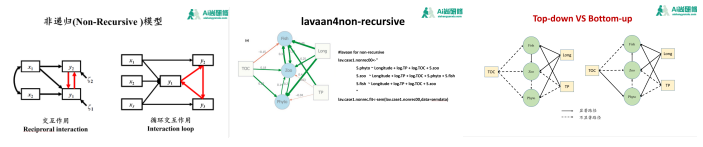
课程五:系统发育数据纳入结构方程模型技术实践
对于包含物种信息的数据而言,物种的亲缘关系远近会影响到物种的属性的表达,亲缘关系近的物种属性更相似,反之则更相异。系统发育树可定量物种亲缘关系的远近,此类数据同样具有不独立的问题,因此需要在结构方程建模时予以考虑。本课将向大家分享如何将系统发育信息纳入到结构方程模型,修正模型的有偏结果。
1、系统发育相关问题介绍
2、系统发育相关数据纳入结构方程模型实现途径
3、局域估计法(piecewiseSEM)实现系统发育相关数据纳入结构方程
4、贝叶斯方法(brms)实现系统发育相关数据纳入结构方程

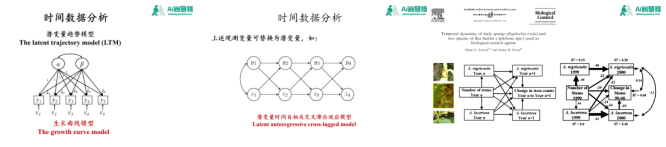
课程六:结构方程模型(SEM)时间/重复测量数据分析
很多研究需要进行多个时间点(如天/月/年)的连续观测,即重复观测数据或时间数据。在进行这类数据分析时,邻近观测时间样本间存在自相关问题需要进行校正。另外,研究目的本身可能是探讨研究对象的某一观测变量随观测时间的变化,即生长曲线模型(Growth Curve Model);也可能是研究系统中两个变量间存在交叉相互作用,比如A和B两个变量,A在时间T1对B的影响表现时间T2,B在时间T1对A的影响也同样表现在时间T2,此类模型称为交叉滞后模型(Autoregressive Cross-Lagged Model)。不论是生长曲线模型还是交叉滞后模型都会存在时间自相关的问题。将针对上述几个方面入手,详细探讨结构方程模型全局估计法、局域估计法及贝叶斯法对时间/重复观测数据的分析。
一:时间/重复测量数据回归模型分析
1、时间重复测量数据特点简介
2、回归模型处理时间/重复测量自相关数据
3、贝叶斯方法对时间/重复测量数据分析

二:时间/重复测量数据结构方程校正
1、局域估计法处理时间/重复测量数据基本原理
2、局域估计法(piecewiseSEM和brms)对时间自相关数据的分析

三:时间/重复测量数据的交叉滞后模型和生长曲线模型
1、时间/重复测量数据的交叉滞后模型(Autoregressive Cross-Lagged Model)
2、时间/重复测量数据的生长曲线模型(Growth Curve Model)
课程七:结构方程模型(SEM)预测问题
结构方程建立后如何进行预测很少有文献进行详细介绍,因此在结果展示时更多文献中仅仅展示模型中变量间的回归关系,即bivariate regression。而此回归关系的系数和结构方程中给出的路径系数并不一致。另外,还有结构方程软件包借用了线性回归的偏回归(partial regression)的理念来表征结构方程模型中变量间的“真”关系,遗憾的是此种方法得到的回归系数与结构方程得到的路径系数也不一致。那么如何根据结构方程模型系数表达变量间的关系?变量间的bivariate regression的含义是什么?我们将通过实例解开上述疑问,探讨如何利用结构方程进行预测。
1、结构方程模型进行预测问题概述
2、结构方程模型直接预测的实现途径
3、结构方程建模后变量间偏关系(partial relationship)的实现及表达

课程八:结构方程模型(SEM)论文发表注意事项
将通过实际案例分析分享结构方程模型建模过程、结果展示及论文撰写中主要注意事项和常见问题,避免论文被拒的杯具。

关注科研技术平台获取更多详情
这篇关于结构方程模型(SEM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









