本文主要是介绍【云原生系统故障自愈论文学习】—NENYA: Cascade Reinforcement Learning for Cost-Aware Failure Mitigation at Microsoft,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

发表在KDD2022
KDD是Knowledge Discovery and Data Mining的缩写,即知识发现和数据挖掘。是CCF (中国计算机学会)推荐的A类国际学术会议。
Abstract
大规模的分布式系统,如微软365的数据库系统,需要及时的缓解方案来解决故障,提高服务的可用性和可靠性。然而,缓解动作可能是昂贵的,它们可能导致性能下降,甚至是高昂的金钱支出。缓解动作可以以被动的方式管理,以控制检测到的故障,也可以以主动的方式减少潜在的故障。主动的缓解方法通常依赖于一个两阶段的策略:预测模型将首先识别具有高故障风险的实例(如数据库或磁盘),然后由工程师或自动bandit学习模型选择适当的缓解动作来应用。由于这两个阶段的信息不完全共享,某些重要的因素,如缓解成本和实例的状态,往往会在这两个阶段中的一个阶段被忽略。为了解决这些问题,我们提出了NENYA,这是一个大规模数据库系统的端到端缓解方案,由一个新颖的级联强化学习模型驱动。通过将数据库的状态作为输入,NENYA直接输出缓解动作,并根据对缓解成本和失败率的共同累积反馈进行优化。由于绝大多数数据库不需要采取缓解动作,NENYA利用一种新颖的级联决策结构,首先可靠地过滤掉这些数据库,然后集中精力为其余数据库选择适当的缓解动作。广泛的离线和在线实验表明,我们的方法在降低数据库的故障率和缓解成本方面都优于现有做法。NENYA已经被整合到微软365这个高效平台中,并取得了良好的效果。
1 INTRODUCTION
Largescale datacenters are motivated to implement sophisticated mitigation processes for addressing emerging failures。例如,当数据库发生故障时,将通知工程师进行调查并采取适当的缓解措施,包括激活被动数据库或更换与故障数据库相关的有问题的硬件。然而,不适当或不必要的缓解动作不仅会造成财务损失(例如,更换硬件的额外费用),而且还可能导致计划外的服务中断,对客户体验产生负面影响。因此,智能缓解系统不仅需要设计能够有效处理故障的缓解策略,还应该努力减少与缓解动作相关的成本。
现有的故障缓解工作大致可分为被动方法和主动方法(reactive and proactive approaches)。
- 被动方法:在观察到严重症状后才会采取缓解措施。虽然这种故障后缓解策略肯定会降低与不必要的缓解操作相关的成本,但在缓解操作生效之前,用户常常不得不忍受糟糕的服务体验
- 主动方法:这种新方法通常采用两阶段方法,首先使用预测模型预测每个实例的失效风险。然后可以为具有高失败风险的实例选择缓解动作。虽然缓解动作的选择通常留给工程师,但Narya探讨了自动Bandit学习模型的使用。然而,由于在预测和缓解阶段之间没有充分共享信息,关于缓解动作的反馈,特别是关于成本(
costs)的反馈,在预测风险时往往被忽视。在选择缓解动作时,也会忽略实例的详细状态。
为了解决现有方法中的问题,我们提出了NENYA,一个新的端到端、成本敏感的主动故障缓解方法,由一个新的级联强化学习框架提供支持,并将其应用于大规模数据库系统。NENYA的设计有两个主要特点。
- 端到端框架(
End-to-end Framework)。NENYA用一个端到端的强化学习框架将故障预测和缓解的决策过程结合起来。这种结构确保了对缓解动作的收益和成本的反馈可以有效地利用,以改善决策过程,确保低成本动作的优先性。NENYA将数据库的状态作为输入,并从以下类别中输出决策:NoOp—无缓解效果的决策、Op—可用的缓解动作集合。 - 级联决策结构(
Cascade Decision Structure)。由于大规模数据库系统的高可靠性,只有极小部分的数据库需要缓解动作。因此,一个好的缓解系统预计会对大多数数据库输出NoOp。为了确保NENYA的性能和可靠性,我们开发了一个新颖的级联强化学习框架,由一些NoOp层和Op层组成的级联结构。NoOp层的序列使NENYA能够以高置信度过滤掉绝大多数不需要采取缓解动作的数据库。至于那些确实需要采取缓解动作的数据库,最后的OP层将评估相关信息,从Op中选择最佳动作。
我们的工作贡献如下:
- 我们将大规模分布式系统中的故障缓解表述为一个强化学习问题。
- 我们提出了NENYA,一种用于大规模分布式系统的新的主动式故障缓解方法。据我们所知,NENYA是第一个考虑缓解成本的端到端故障缓解方法,以确定是否应该采取和采取哪些缓解动作。
- NENYA纳入了一个新颖的强化学习框架,即级联强化学习。NENYA中的级联决策结构确保代价高昂的缓解动作将只应用于适合大规模分布式系统的一小部分数据库。
- 广泛的离线和在线实验表明我们的方法性能优越。
2 BACKGROUND AND MOTIVATION
2.1 Failure Mitigation at Microsoft 365
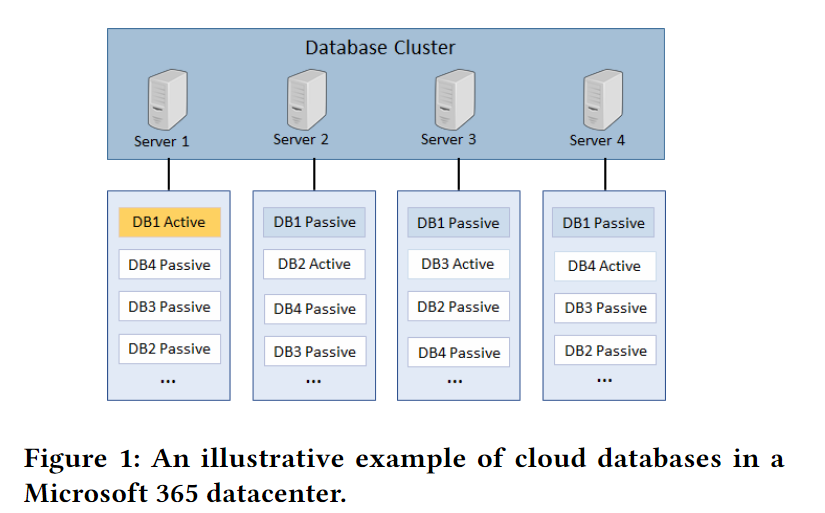
微软365依赖于大规模的云数据库来托管客户信息(例如Outlook邮箱),并为多个客户端提供稳定的数据访问。图1展示了M365数据中心分布式数据库的示例。每个数据库都有几个副本托管在不同的服务器上。在这些副本中,一个主动副本与客户端交互并提供服务,而其余被动副本作为备份与主动副本同步。当数据库的主动副本发生故障时,它将无法承载请求。因此,最优先考虑的是通过适当的缓解动作快速解决此故障,以确保服务的可用性。
例如,当在主动数据库上观察到显著的性能下降时,系统可以下令执行切换缓解操作。在此过程中,客户端可能会出现性能下降。在检测到服务器故障的罕见情况下,数据中心可能需要更换故障的物理服务器并在新服务器上重构所有托管数据库。
Narya,是目前大规模分布式系统中用于故障缓解的SOTA方法。作为一个两阶段的主动缓解方法,Narya利用一个故障预测模型来生成关于特定单元是否会失败的二分信号,然后将其传递给一个Bandit学习模型来生成自动缓解决策。
2.2 Motivation
我们在M365中缓解故障的经验表明了以下改进的方向:
- 状态感知(
State Awareness)。目前的两阶段主动缓解方法的缓解系统,只根据故障预测模块传递的二分信号来选择缓解动作。在实践中,关于每个数据库副本的当前和过去状态的遥测数据(例如,数据库读/写延迟、读错误、数据库负载)可以提供关于预测故障性质的有价值见解。例如,如果数据只表明在不久的将来会出现轻微的服务退化,用一个被动的数据库副本切换一个主动的数据库副本可能就足以解决这个问题。相反,如果遥测数据捕捉到高延迟或甚至完全失败,可能需要代价更高的动作来完全缓解这个问题。 - 成本感知(
Cost Awareness)。目前两阶段缓解的做法侧重于最小化失败率,而忽略了缓解动作的成本。当低成本和高成本的动作都能产生类似的结果时,两阶段缓解并不倾向于低成本的缓解动作。例如,由不健康的数据库拷贝引起的问题可以通过切换或替换不健康的数据库拷贝来缓解。然而,与简单的切换动作相比,替换副本会产生更多的时间和财务成本。
3 OUR PROPOSED APPROACH
3.1 Failure Mitigation in a Reinforcement Learning Framework
在介绍NENYA的详细框架之前,我们将首先把数据库系统中的故障缓解表述为一个强化学习问题。值得注意的是,虽然我们讨论的重点是数据库系统,但NENYA的框架和方法也可以应用于其他大规模分布式系统。
形式上,给定数据库(主动或被动)在不同时间 t = 0 , 1 , 2 , . . . t=0,1,2,... t=0,1,2,... 的状态 s t ∈ S s_t∈S st∈S(如服务器在线时间,读/写延迟,数据库事件)。 我们的目标是学习一个缓解策略 π ( a t ∣ s t ) \pi (a_t |s_t) π(at∣st) ,其中 a t a_t at 代表为避免主动数据库的故障而采取的主动动作(包括不需要时不采取动作)。具体描述如下:
-
Action
NENYA从Op和NoOp两个类别中考虑四种缓解动作。Op包括SwithchIn,将主动数据库副本换成被动数据库副本(𝑎 = 0),SwithchOut,将被动副本换成主动副本(𝑎 = 1),Replace,替换数据库副本(𝑎 = 2)。NoOp表示不采取缓解动作(𝑎 = 3)。请注意,由于数据库的一个且仅有一个副本必须保持主动,SwitchIn 和 SwitchOut应该同时进行。也就是说,每当SwitchIn应用于主动数据库副本时,必须同时对被动副本采取SwitchOut动作,反之亦然。
-
State
状态 s t = [ s t 0 , s t 1 ] s_t = [s^0_t , s^1_t ] st=[st0,st1] 由静态特征 s t 0 s^0_t st0 和动态特征 s t 1 s^1_t st1组成。静态特征 s t 0 ∈ R v s^0_t\in \mathcal{R}^v st0∈Rv 表示对应数据库副本的状态,如读/写延迟、错误指标、基础服务器开机时间等。动态特征 s t 1 s^1_t st1 用于表示数据库副本当前是主动还是被动。
-
Reward Function
考虑了两个奖励函数:
(1) r C ( s t , a t ) r^C(s_t , a_t) rC(st,at),表示缓解动作的成本,包括时间和财务成本(
financial cost);(2) r D ( s t , a t ) r^D(s_t,a_t) rD(st,at),表示与数据库故障有关的成本。
第一个奖励函数 r C r^C rC 是在领域专家的帮助下定义的。特别是,我们为 SwitchIn 和 SwitchOut 动作设置了 r C ( s t , 0 ) = − 1 r^C(s_t,0)=-1 rC(st,0)=−1 和 r C ( s t , 1 ) = − 1 r^C(s_t,1)=-1 rC(st,1)=−1,为替换动作设置了 r C ( s t , 2 ) = − 1 r^C(s_t,2)=-1 rC(st,2)=−1,为NoOp动作设置了 r C ( s t , 3 ) = − 100 r^C(s_t,3)=-100 rC(st,3)=−100。这种设置反映了这样一个事实:动作SwitchIn和SwitchOut通常只需要很短的时间,而且几乎没有财务成本,而替换动作则需要相对较长的时间,而且有一定的财务成本。至于代表数据库故障成本的奖励函数 r D r^D rD,构建了一个监督学习模型 f ( y t ∣ s t , a t ) f(y_t |s_t , a_t ) f(yt∣st,at),以学习每个数据库在每个时间步骤的故障概率 y t ∈ [ 0 , 1 ] y_t\in [0,1] yt∈[0,1], − y t -y_t −yt然后被用作内在奖励 r D r^D rD 。
-
State Transition
我们用 P ( s ’ ∣ s , a ) P(s^{’}|s, a) P(s’∣s,a) 来表示状态转换模型,该模型在给定先前状态 s t s^t st 和缓解动作 a a a 后,返回新的状态向量 s t + 1 s_{t+1} st+1。在标准RL方法的训练过程中,通常根据与真实世界环境的频繁交互来评估状态转换模型。在本文中,我们可以通过重放日志数据来获取近似的状态转换(如第4.1节所述)。
-
Policy
𝜋(𝑎|𝑠) 对应于故障缓解策略,该策略返回采取缓解动作的概率 a t ∈ { S w i t c h I n , S w i t c h O u t , R e p l a c e , N o O p } a_t ∈ \{SwitchIn,SwitchOut, Replace, NoOp\} at∈{SwitchIn,SwitchOut,Replace,NoOp}。
3.2 NENYA Workflow
NENYA的设计目标是通过应用合适的缓解动作,以最小的缓解成本自适应地减少主动数据库副本的故障概率。
该模型由若干NoOp层和Op层组成,采用级联结构。NoOp层首先会通过早期的NoOp决策过滤掉尽可能多的数据库副本。然后,没有被NoOp层过滤掉的数据库副本将被传递给Op层,以决定应该采取哪些缓解动作。请注意,在这种设计下,对NoOp和Op动作的反馈都将被用于改善NoOp层的决策,而只有对Op动作的反馈被用于改善Op层的决策。
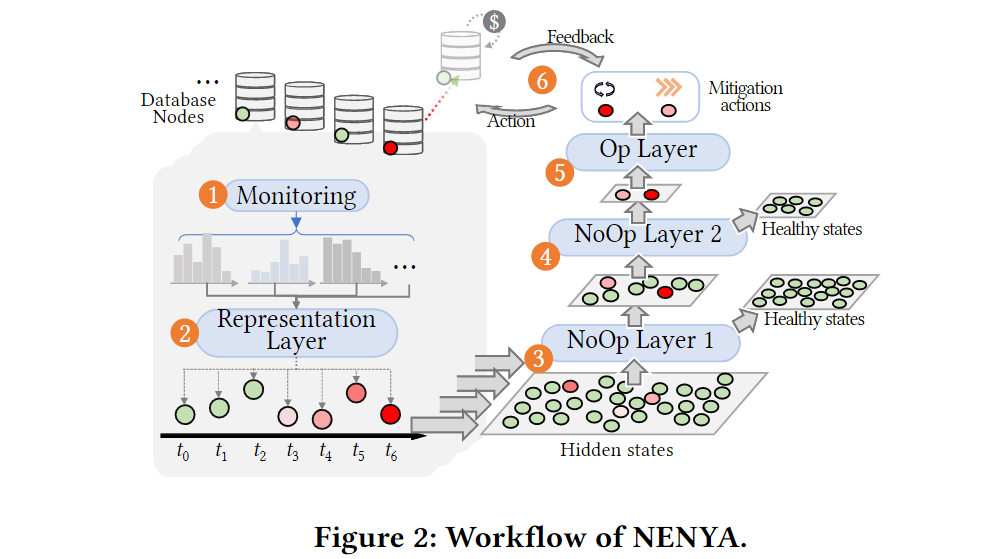
NENYA的工作流程概览见图2,主要步骤如下。
- 在M365数据库系统的每个节点上部署监测器,收集各种遥测信号,形成数据库副本的状态。
- NENYA的表示层将数据库副本在不同
time step的状态作为输入,并在每个time step输出每个数据库副本的缓解决策。整个决策过程由一个级联结构的决策层序列组成。 - 所有数据库副本的状态都流入第一个NoOp层,该层决定是否应该为每个数据库副本选择无缓解动作。如果决定采取NoOp动作,相应的数据库副本将被标记为 “healthy state”,并且在下一个
time step之前不会再对该数据库副本作出决定。 - 第一个NoOp层没有选择不采取缓解动作的数据库副本将进入第二个NoOp层。另一个关于是否应该采取缓解动作的决定将被做出,以确保缓解动作将只在真正需要的数据库副本上应用。
- 只有极小部分的数据库副本可以进入这个Op-layer,由它来决定选择哪些缓解动作应该被应用。
- NENYA观察应用于每个数据库副本的缓解动作的故障概率和缓解成本的联合反馈,以确保NENYA可以在状态感知和成本感知的情况下优化决策过程。
3.3 Cascade Reinforcement Learning
为了学习缓解策略函数 π θ ( a t ∣ s t ) \pi_\theta(a_t |s_t) πθ(at∣st),将数据库副本的状态 s t s_t st 直接映射为缓解动作 a t a_t at ,NENYA需要像标准强化学习问题那样找到使预期累积奖励最大化的参数。具体来说,NENYA的目标可以概括为:。

𝜃 表示缓解策略 π θ ( a t ∣ s t ) \pi_\theta(a_t |s_t) πθ(at∣st) 的参数, τ = { s 0 , a 0 , r 0 , . . . } \tau=\{s_0, a_0, r_0, ...\} τ={s0,a0,r0,...}是通过 𝜋 产生的轨迹, p θ p_\theta pθ 表示由 π θ \pi_\theta πθ 产生的轨迹分布, P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t,a_t) P(st+1∣st,at) 表示第 3.1 节中提到的状态转换概率。
RL的标准目标函数需要 full-state-action-space 优化,以学习一个使期望累积奖励最大化的策略。然而大部分数据库副本不需要任何缓解动作,而只有极小部分的数据库副本需要缓解动作(Op)。在这样的环境中,不区分NoOp动作和Op的实际缓解动作的扁平化设计很容易导致过多的缓解动作,大大增加缓解的总体成本。级联学习结构可以用于从大的同质类中快速过滤案例,以便将精力集中在表现出更多多样性的其他案例上。
受监督学习中级联结构的启发,我们提出了一种新的强化学习模型——级联强化学习模型,以改进大多数情况下的学习过程。在M365中的故障缓解的情况下,该级联强化学习框架由一个或多个NoOp层(NoOp层的最佳数量的分析在表2中讨论)和一个Op层组成。目标函数应表述如下:

其中 π θ ( a t l , a t h ∣ s t ) \pi_{\theta}(a_t^l,a_t^h|s_t) πθ(atl,ath∣st) 表示级联策略, a l a^l al 是一个二分向量,其长度等于NoOp层的数量,其值为1表示在相应的NoOp层中没有做出缓解决策, a h ∈ { 0 , 1 , 2 } a^h∈\{0,1,2\} ah∈{0,1,2} 表示缓解动作的选择(即 SwitchIn, SwitchOut 和 Replace)。请注意,由于级联决策结构,如果在其中一个NoOp层中选择了NoOp动作,所有后续的决策层将被跳过。
在本文中,我们将 NoOp 层的数量视为一个超参数,并通过超参数调整将其设置为2。这一选择导致了一个三层级联结构(见图3)。由于只有在前两个NoOp层的输出值为0(表示需要采取缓解措施)时,才会对最后一个Op层进行评估,因此相应的级联策略 π θ ( a t l , a t h ∣ s t ) \pi_{\theta}(a_t^l,a_t^h|s_t) πθ(atl,ath∣st) 可以展开如下

在第一种情况下,鉴于状态 s t s_t st ,第一层或第二层NoOp层都做出了不采取缓解动作的决定,这导致了决策过程的提前停止。在第二种情况下,两个NoOp层都选择不采取NoOp动作,即, a t l = ( 0 , 0 ) a^l_t=(0,0) atl=(0,0)。然后,状态 s t s_t st 将被传送到最后的Op层,以选择应采取的高成本缓解动作 a h a^h ah 。与NoOp层相关的政策函数 π θ l ( a l ∣ s t ) \pi_{\theta}^l(a^l|s_t) πθl(al∣st) 可以进一步扩展如下。

其中, π l , 1 \pi^{l,1} πl,1 和 π l , 2 \pi^{l,2} πl,2 分别表示第一和第二NoOp层, a l , 1 ∈ { 0 , 1 } a^{l,1}∈\{0,1\} al,1∈{0,1} 和表示在 a l , 2 ∈ { 0 , 1 } a^{l,2}∈\{0,1\} al,2∈{0,1} 相应层是否采取NoOp动作。如第一种情况所示,第一个NoOp层中的NoOp动作会触发决策过程的提前停止。如第二种情况所示,只要一开始没有选择NoOp动作,状态就会被传递到第二个NoOp层,这样就可以进行双重检查,以确保只有真正需要缓解动作的数据库副本才会被送到Op层来选择合适的缓解动作。
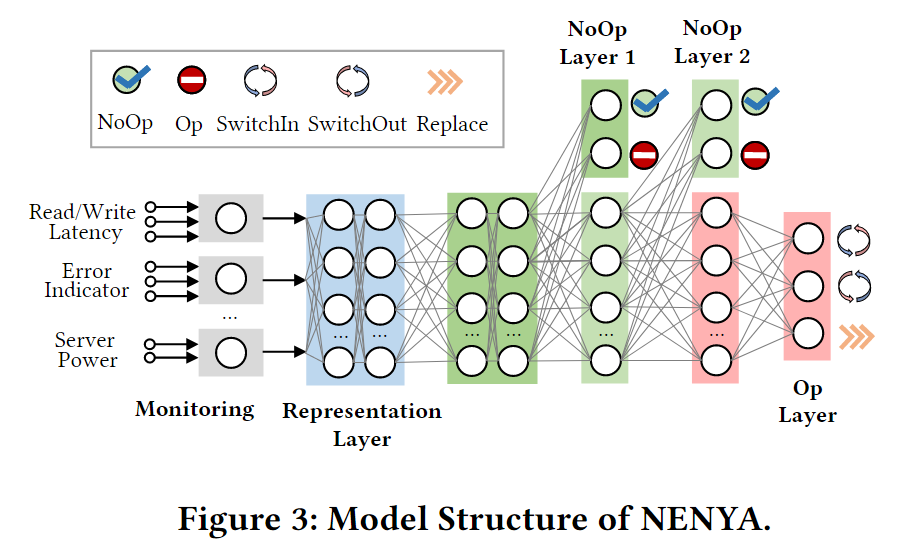
通过将决策过程设计成由NoOp层和Op层组成的级联结构,NENYA确保在决策的早期阶段可以可靠地过滤掉绝大多数不需要采取缓解动作的数据库副本,从而大大减少了在后续Op层学习代价高昂缓解动作的负担。具体来说,Op层的搜索空间从 S × 3 \mathcal{S}×3 S×3 减少到 S − × 3 \mathcal{S}^-×3 S−×3 ,其中 S \mathcal{S} S 代表所有数据库副本的集合, S − \mathcal{S}^- S− 代表传递给Op层的数据库副本的集合。在训练有素的NoOp层中, S − / S \mathcal{S}^-/\mathcal{S} S−/S的比率相当小(总是小于1/1000)。此外,与NoOp层相比,Op层的学习过程更难也更有风险,因为它涉及到在更大的动作空间中具有更高成本的缓解动作。
最后,由于NENYA的目标是以最小的缓解成本最小化主动数据库副本的故障率,累积缓解成本和故障概率被用作奖励信号,通过目标函数方程1优化NoOp层和Op层。
4 EXPERIMENTS
4.1 Experimental setup
4.1.1 Production Datasets
我们使用从M365数据库系统收集的工业数据集来评估NENYA。每个数据库通常有几个副本,包括一个主动副本,其他是被动副本。数据库的日志是通过监听系统软件事件的监视器或定期查询硬件状态的定时器产生的。此外,在我们的实验中,缓解的成本是根据第3节定义的奖励函数添加的,该函数同时考虑了时间成本和财务成本。我们还基于对信号延迟和诊断的共同考虑,在日志数据中标记故障信号。
状态转换模型是通过从M365平台获得的日志数据而构建的。在标准RL方法的训练过程中,状态转换模型通常是基于与真实世界环境的频繁交互来评估的。然而,在一个工业数据库系统中进行在线训练是不现实的。幸运的是,由于缓解动作的目的是恢复服务的可用性,而不是改变数据库副本的内部状态,就实际情况而言,可以合理地假设3.1节中讨论的静态特征不会受到大多数缓解动作的影响。相反,像SwitchIn和SwitchOut这样的缓解动作会改变数据库副本的主动/被动状态,因此会直接影响动态特性的值。因此,在合理的假设下,状态向量中的静态特征不受或略受缓解动作的影响,我们可以通过利用由静态特征 { s 0 0 , s 1 0 , . . . , s T 0 } \{s_0^0, s^0_1, ..., s^0_T\} {s00,s10,...,sT0} 的序列组成的日志数据来构建过渡模型。具体来说,下一个状态 s t + 1 s_{t +1} st+1 可以通过从日志数据中提取静态特征 ( s t 0 , s t + 1 0 ) (s^0_t , s^0_{t +1}) (st0,st+10) 并根据时间 𝑡 采取的动作 a t a_t at 更新动态特征 s t + 1 1 s_{t+1}^1 st+11 来获得。奖励函数可以得到相应的更新以模拟真实的数据库环境。
我们将数据集分为训练和测试部分。具体来说,我们使用60%的数据库副本进行训练,40%的数据库副本进行测试。此外,每个训练集的10%的数据库副本将被用作验证集,用于调整不同方法中的超参数。
4.1.2 Metrics
A v g A d b F a i l R a t e AvgAdbFailRate AvgAdbFailRate 表示主动数据库副本 m m m 的平均故障率,并定义 A v g A d b F a i l R a t e = 1 T ∑ t = 1 T U t M F U t M AvgAdbFailRate = \frac{1}{T}\sum_{t=1}^T{\frac{U_t^{MF}}{U_t^M}} AvgAdbFailRate=T1∑t=1TUtMUtMF。其中,𝑇为任务的总时间进度, U t M {U_t^M} UtM表示在时间进度 𝑡 的主动数据库副本的大小, U t F M {U_t^{FM}} UtFM示在时间进度 𝑡 的失效主动数据库副本的大小
A v g C o s t AvgCost AvgCost 代表缓解动作的平均成本,定义为 A v g C o s t = 1 T ∑ t = 1 T ( F t c f + O t c o + E t c e + N t c n ) AvgCost = \frac{1}{T}\sum_{t=1}^T(F_tc_f + O_tc_o + E_tc_e + N_tc_n) AvgCost=T1∑t=1T(Ftcf+Otco+Etce+Ntcn) 其中 F t , O t , E t , N t F_t,O_t , E_t , N_t Ft,Ot,Et,Nt代表不同的缓解动作,即SwithchIn、SwithchOut、Replace、NoOp。 c f , c o , c e , c n c_f , c_o , c_e ,c_n cf,co,ce,cn分别表示每个动作的成本。
4.1.3 Competitors
我们将NENYA与两种故障缓解模型进行比较:经典的被动式缓解方法和最近的两阶段主动式缓解方法,以验证NENYA的应用贡献。此外,我们还比较了最先进的强化学习方法和随机策略来验证NENYA的方法论贡献。
- Reactive Mitigation Method: 基于规则的故障缓解模型。
- Two-Stage Proactive Mitigation Method: Narya是SOTA故障缓解方法。
- Standard RL methods:SAC是一种经典的基于最大熵强化学习框架的off-policy RL方法。在SAC中,动作候选者被平行地考虑采取。DDPG是一种基于确定性策略梯度的的算法,可以在连续和离散的动作空间中运行。
- Random Policy: 随机选择缓解动作。
我们在DDPG的基础上实现了NENYA,其中我们加入了一个具有两个NoOp层和一个Op层的演员网络的级联结构。为了进行消融研究,我们对不同数量的NoOp层进行实验。相关模型表示为NENYA-0、NENYA-1、NENYA-2和NENYA-3,其中数字后缀表示NoOp层的数量。请注意,NENYA-0模型等同于DDPG。
4.2 Overall Performance
4.2.1 Comparisons against State-of-the-art Competitors
不同模型的比较结果与消融实验结果如下表:

所有这些方法都优于随机策略,这表明故障缓解可以受益于采用领域知识(Reactive policy)、主动缓解策略(Narya)、状态意识(SAC、DDPG)和级联决策机制(NENYA)。
4.2.2 Effectiveness of the Cascade structure.
通过NENYA-1和NENYA-2的比较,将noop层数从1个增加到2个会导致相对显著的性能改善,特别是在故障率方面。然而,从NENYA-2到NENYA-3的性能下降也表明,不必要的NoOp层可能会导致过拟合,这可能会略微增加故障率和缓解成本
4.3 How does NENYA Reduce the Cost?
4.3.1 Qualitative analysis: NoOp-layers can filter out “healthy” databases more effectively
我们在三天内随机选择了1000个数据库副本,以检查不同故障缓解方法所采取的动作的分布情况。结果显示在图4中。我们使用T-SNE将数据库副本的状态向量投射到二维空间中,图4中的每一点都表示某个时间步长的数据库副本。如图例所示,不同的图标代表不同的缓解动作。
- 与NENYA-0和Narya相比,NENYA采取的高成本缓解动作明显较少,这表明NENYA中的NoOp层可以识别更多的 "healthy"数据库,避免更多不必要的缓解成本。
- 尽管基于规则的策略在专家的指导下也能识别出许多不需要采取缓解动作的 "healthy "数据库,但它很容易采取高成本的 "Replace "动作,这可能是由于故障后缓解策略在防止小问题发展成严重故障方面的限制。因此,与NENYA相比,基于规则的政策仍然产生了更高的平均缓解成本。

4.3.2 Qualitative analysis: Op-layer can better differentiate mitigation actions based on the states of database copies and the long-term feedback.
为了证明 Op-layer 可以更好地区分不同缓解动作的数据库副本,我们检查了图4所示预测状态中不同缓解动作之间的界限。很明显,对应于NENYA-0和NENYA的子图在不同缓解动作之间表现出相对清晰的界限。这一事实表明,对数据库副本的状态和长期反馈的考虑有助于NENYA学习从状态到缓解动作的良好映射。如果没有这样的考虑,Narya就很难区分不同缓解动作的状态。
4.3.3 Quantitative analysis: when and which mitigation to take for reducing the cost.
在本节中,我们总结了72小时内每个小时的每项策略的平均成本(见图5)和同一时期内不同缓解动作的频率(见图6),以分析何时以及采取何种缓解动作。图5显示了不同方法 "何时 "采取的动作。请注意,SwitchIn和SwitchOut动作的频率条是相同的,因为每个SwitchIn动作必须与SwitchOut动作配对,以保持主动和被动数据库副本1:3的比例的硬约束。

4.4 How does NENYA Reduce the Failure Rate of Active Database Copies?
用案例研究来说明NENYA是如何降低主动数据库副本的故障率的。将选择SOTA缓解方法Narya作为比较方法,图7显示了两个主动数据库副本的故障案例和两个从测试集中随机选择的健康案例
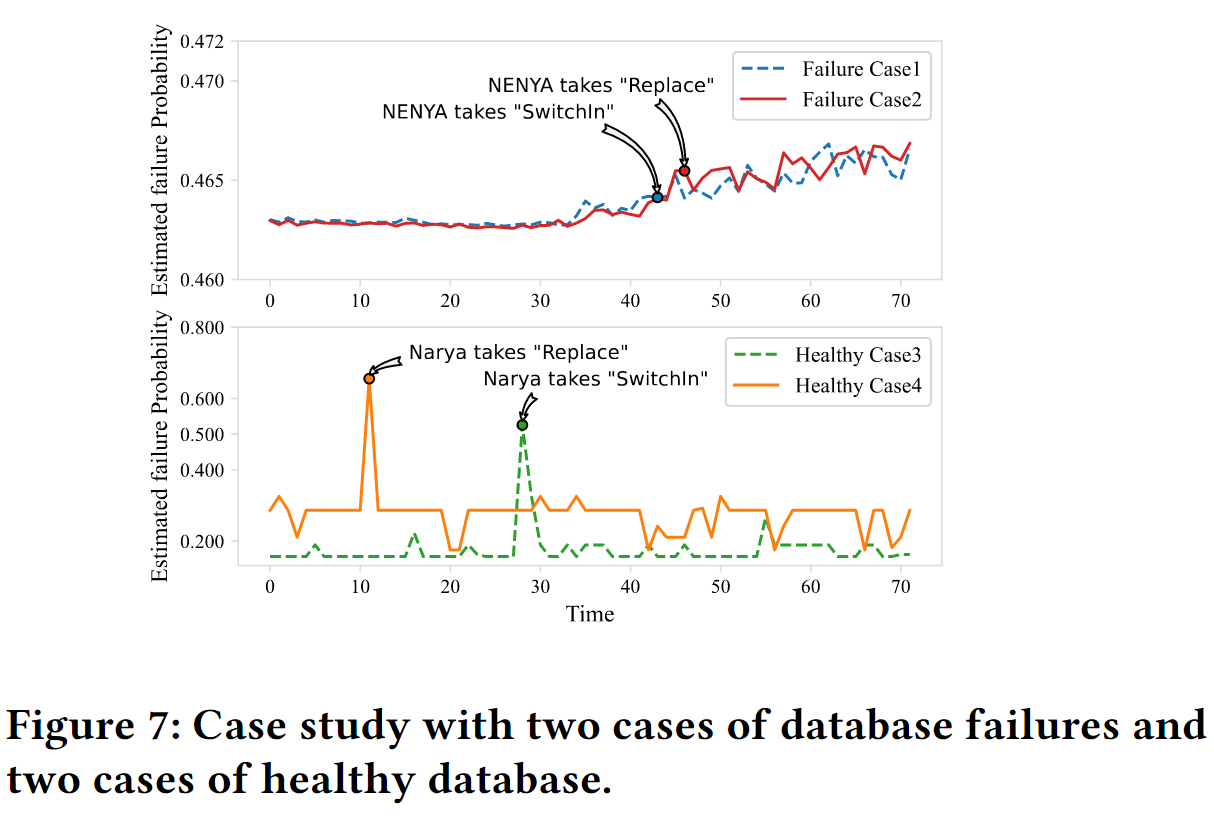
对于两个故障案例,故障概率随着时间的推移逐渐增加,这表明有一个明显的实际故障的趋势。尽管如此,在这72小时内,估计的故障率还没有提高到0.5以上,这是Narya激活缓解模块的决策阈值。因此,在此期间,Narya始终选择𝑁𝑜𝑂𝑝。然而,考虑到对累积故障概率和缓解成本的反馈,NENYA对这两种情况分别选择了SwitchIn和Replace动作
对于两个健康的案例,延迟信号中类似的时间尖峰触发了故障概率的突然增加,超过了Narya的决策阈值。作为回应,Narya启动其缓解模块,分别采取SwitchIn和Replace动作。由于这些问题只是时间性的,Narya所采取的缓解动作实际上是不必要的。相反,通过考虑长期的换算成本,NENYA在两种情况下都正确地选择了𝑁𝑜𝑂𝑝。
5 INDUSTRIAL PRACTICE
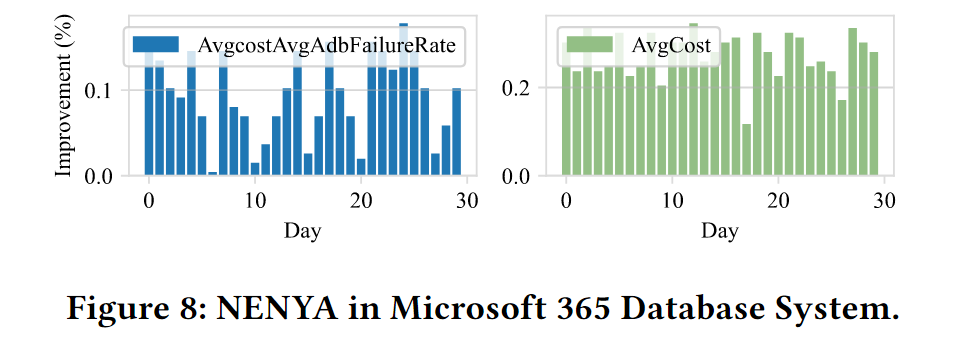
在实际的生产云中, A v g A d b F a i u r e R a t e AvgAdbFaiureRate AvgAdbFaiureRate 的整体改进为5.46%, A v g C o s t AvgCost AvgCost 为25.87%,表明NENYA可以为M365数据库系统带来实际效益。
6 RELATED WORK
Failure Mitigation
以前关于故障缓解的工作可以概括为两类,反应性缓解和两阶段主动缓解。前者长期以来一直是最常用的缓解方法,即在观察到严重症状后,才采取一些专家预先确定的固定措施。
最近的工作主要基于机器学习的方法来预测故障,以支持两阶段主动缓解方法:
- 2016-Predicting Disk Replacement towards Reliable Data Centers
- 2001-Bayesian approaches to failure prediction for disk drives
- 2020-Making Disk Failure Predictions SMARTer
- 2017-Hard Drive Failure Prediction for Large Scale Storage System
- 2021-NTAM: Neighborhood-Temporal Attention Model for Disk Failure Prediction in Cloud Platforms
- 2018-Improving Service Availability of Cloud Systems by Predicting Disk Error
当预测模型预测到较大的故障概率时,系统可以采取相应的预先定义的缓解措施。为了根据预测模块生成的信号自动化缓解动作,微软提出的最先进的故障缓解方法Narya通过强盗学习学习缓解决策模型。然而,Narya仅根据来自预测模型的二分信号做出缓解决策,而忽略了数据库状态的上下文信息
Cascade Learning
级联学习是一种基于多个模型级联的集成学习方法,前一个模型的输出将作为下一个模型的附加信息传递。目前,级联学习已经在监督学习中取得了成功,在后者的分类器之前拒绝不必要的样本。然而,除了Hu等人提出的用于超参数调优的两步Bandit学习方法外,很少有工作利用级联学习来减少动作空间,对高成本动作进行更深入的思考。NENYA中的级联决策结构不同于hierarchical reinforcement learning(HRL)方法。典型的HRL在不同的层上执行抽象动作和基本动作,而NENYA在不同的层上执行基本动作。NENYA也不同于curriculum reinforcement learning。
7 CONCLUSION
故障缓解是确保大规模系统高可用性的关键。在本文中,我们提出了NENYA,一种由新型强化学习模型驱动的端到端主动式故障缓解方法。NENYA在两个方面推进了当前的故障缓解实践:(i)NENYA是状态感知的,将典型的两步预测和缓解策略转变为端到端的缓解决策服务,其中缓解动作是根据数据库副本的具体状态决定的;(ii)NENYA是成本感知的,在强化学习框架中纳入了一个新的成本感知的级联决策结构。在离线和在线数据集上进行的大量实验表明,与SOTA缓解策略相比,NENYA取得了明显的改善。虽然我们的讨论集中在数据库系统的故障缓解上,但通过在强化学习模型中指定包括状态、动作、奖励和状态转换在内的组件,我们的方法可以被推广到其他类型的故障/系统。在未来的工作中,我们将探索用逻辑规则学习可解释的缓解策略,这可以为NENYA建议的缓解动作提供清晰直观的解释。
这篇关于【云原生系统故障自愈论文学习】—NENYA: Cascade Reinforcement Learning for Cost-Aware Failure Mitigation at Microsoft的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






