本文主要是介绍【项目设计】网络对战五子棋(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
想回家过年…

文章目录
- 一、项目前置知识
- 1. websocketpp库
- 1.1 http1.0/1.1和websocket协议
- 1.2 websocketpp库接口的前置认识
- 1.3 搭建一个http/websocket服务器
- 2. jsoncpp库
- 3. mysqlclient库
- 二、 项目设计
- 1. 项目模块划分
- 2. 实用工具类模块
- 2.1 日志宏封装
- 2.2 mysql_util
- 2.3 json_util
- 2.4 string_util
- 2.5 file_util
- 3. 数据管理模块
- 3.1 数据管理的设计
- 3.2 user_table类的实现
- 4. 在线用户管理模块
- 4.1 在线用户管理的设计
- 4.2 online_manager类的实现
- 5. session管理模块
- 5.1 HTTP的cookie&session机制
- 5.2 websocketpp库中定时器的使用
- 5.3 session的设计与实现
- 5.4 session管理器的设计
- 5.5 session_manager类的实现
一、项目前置知识
1. websocketpp库
1.1 http1.0/1.1和websocket协议
1.
a. http协议在Linux的学习部分我们就已经学习过了,当时http和https是一块学的,我们当时其实已经了解了http的大部分知识内容,比如http请求和响应的格式,各自的报头字段都有哪些,cookie和session机制,http1.1的长连接策略keep-alive,还有请求方法GET和POST等等知识内容,这么看来http感觉已经很优秀了,为什么还要有websocket协议呢?
b. 其实http有一个致命的缺点,就是无法支持服务器向客户端主动推送消息,传统的CS通信方式都是一问一答的,即客户端向服务器发送一个请求,服务器向客户端反馈一个响应,而在最传统的http1.0版本协议中,客户端每和服务器进行一次通信都需要建立一条TCP连接,当浏览器访问了服务器上的某个html网页时,此时就会在应用层协议http的基础上建立一条短连接,而http短连接其实就是tcp短链接,如果浏览器此时想要访问web网页中的其他资源,那就需要重新再向服务器发起一次http请求,以获取到服务器上的对应资源,此时原来的http连接就会自动被断开,然后重新建立一条短连接,这样的方式非常的难受啊,因为用户访问某web资源时,肯定不可能只访问一个资源啊,他一定会向服务器发起多个http请求,获取访问多个web资源,那如果在传统的http1.0协议下,就会频繁的建立和断开连接,这会很浪费服务器的时间和网络带宽,因为http短连接其实就是tcp短连接,本来tcp是一个可靠的,高效的,有链接的协议,但结果http不会用,双方通信一次就关闭掉了,这也太浪费了!
c. 所以在http1.0之后,又推出了http1.1协议,也就是在请求报头中添加了一个字段Connection:keep-alive,也就是http长连接,当上层http连接建立成功后,下层的tcp连接不会在一次通信之后就断开了,而是会在一段时间之后才断开,在这段时间里面,双方都可以使用该连接进行资源的请求和获取,或者是业务的请求和处理,确实是比以前要高效的多了,但http1.1依旧还存在一个问题,就是他的通信模式还是没有变化的,也就是一问一答的通信模式,不过他已经比原来的http1.0要高效很多了,省去了很多不必要的tcp连接建立和断开,也减少浪费带宽。
2.
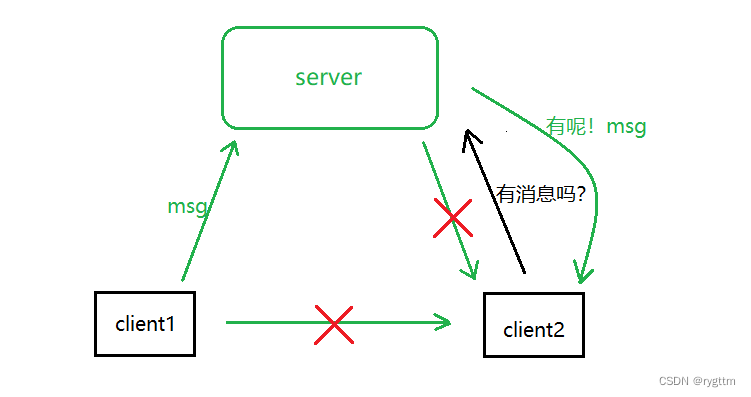
但在实际的用户需求中,一问一答这样的模式是远远无法适用于大多数场景的,就拿聊天这样简单的功能来说,用户1是无法主动将消息发送给用户2的,因为他们俩处于局域网中,而局域网中的ip地址是不唯一的,所以想要实现通信则必须借助中间的服务器角色,用户1将消息发送给服务器,想要让服务器将消息发送给用户2,但这三台机器应用层都使用的是http协议啊,所以服务器无法将消息主动推送给用户2,只有说当用户2向服务器发送请求,询问服务器,现在有没有给我发送的消息啊?服务器此时才能将用户1发送的消息以response的方式返回给用户1。
这样能通信吗?当然是可以的,但他的效率很低,因为想要客户端想要拿到别人发给自己的消息,就必须不断的轮询服务器,看看服务器上有没有发送给我的消息,如果有那就获取,如果没有那就继续轮询,这样的效率非常低!因为服务器会将一部分的资源浪费在不断的回复轮询这件事上,同时也很浪费网络资源。
所以,除了原来的http协议外,我们还需要一种能够支持服务器向客户端主动推送消息的协议,这对服务器或客户端来说,是非常重要的事情!
3.
websocket协议也是基于http协议的来实现的,他是网页端和服务器保持长连接的一种消息推送机制。websocket之间的通信和TCP连接之间的通信非常的相似,websocket长连接其实也就是tcp长连接,即当客户端和服务器建立websocket长连接之后,双方就会一直使用这个连接进行通信,除非某一方主动意愿的想要断开连接,否则其他大部分正常情况连接都是不会断开的,所以websocket和tcp是很相似的。
想要建立websocket长连接,其实还是需要借助http协议的,只不过在原本的http请求报头中多加了一个额外的字段Upgrade:websocket,这样就可以完成websocket协议的切换。

4.
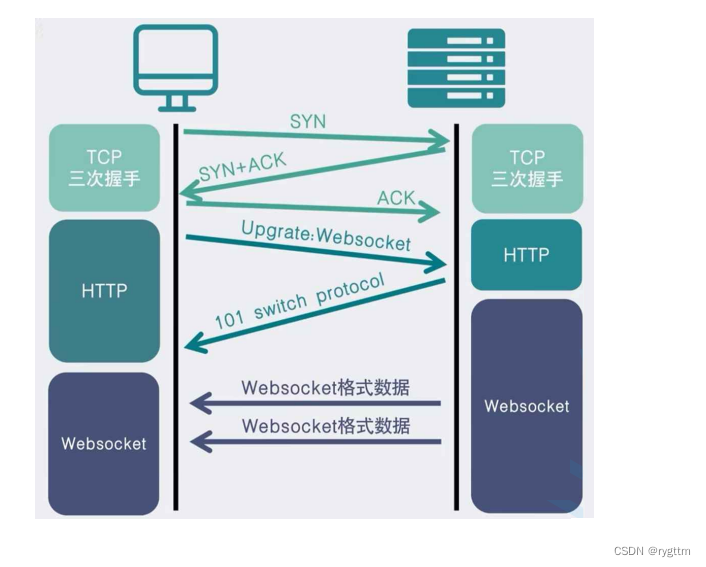
下面是websocket协议切换的示意图,需要注意的是,客户端想和服务器进行通信,包括协议切换的请求或者是任何的请求,都需要在三次握手建立连接的前提下进行。
这里说一个知识点,三次握手是不允许携带任何应用层数据的(严格来说),原因其实和防止SYN洪水攻击非常的相似,之前谈论SYN洪水攻击是在为什么是三次握手,而不是其他次握手这个问题(防止SYN洪水攻击+最小成本验证全双工通信信道)上讨论的,今天这个问题的原因其实就是害怕一个客户端就把服务器搞崩掉,如果在第一次握手中携带大量应用层数据,则服务器需要开辟内存将收到的数据保存起来,并且需要维护建立好的连接,而此时客户端并不认为连接建立成功,或者压根就不给你建立连接,就疯狂的向服务器发送一次握手,并同时携带大量的数据,这样就会极大的消耗服务器上的资源,最终可能导致服务器宕机!而二次握手也是不能携带数据的,道理和前面的一样,客户端只在第一次握手发送的SYN报文段中加入大量的数据,而第二次握手服务器发来的SYN报文段,客户端也是可以选择丢弃的,这么一来无论是一次握手,还是二次握手都是不允许携带数据的,但第三次握手其实是可以携带数据的,因为此时客户端已经认为连接建立成功了,双方的消耗是同等的,而服务器的配置又比客户端高,所以你单主机想要搞掉服务器是不大可能了。
但实际通信中,第三次握手也是不携带数据的,等到双方连接都建立成功后,此时再携带数据看起来更合理一些,不过你要是强行想在第三次握手中携带数据也是可以的,只不过实际使用的时候大部分情况不会这么做。
5.
等到三次握手成功之后,双方已经建立好TCP连接了,此时客户端只要发送一个携带Upgrade:Websocket的http请求即可,然后服务器返回一个101响应状态码以及switch protocol的状态码描述,再配一个http/1.1组成一个状态行,添加上其他的响应报头组织成一个响应报文发送回客户端,此时就可以完成websocket协议的切换。
后续CS双方就可以使用websocket长连接进行通信了,任何一方都可以主动的给对方推送消息!非常的方便
三次握手会携带应用层数据吗?
1.2 websocketpp库接口的前置认识
1.
由于本项目使用了http和websocket两种应用层协议,而websocketpp这个网络库恰好支持了这两种协议,所以我们使用了该库作为本项目的依赖库来实现http/websocket服务器。
2.
connection_hdl相当于websocket连接的句柄,server是endpoint的子类,server也就是我们实例化服务器对象的一个类,所以想要搭建服务器必须了解endpoint里面声明了哪些接口,timer_ptr是一个定时器对象指针,配合set_timer这个接口来使用,可以在服务器内部设置定时任务,这个接口在我们后面的session模块中会用到,connection_ptr是websocket连接的智能指针管理对象,后面的各个通信模块都会大量用到这个智能指针,connection类就是该对象所属类,通常用来进行http响应的回复,http请求内容的获取,以及websocket消息的推送,这个指针对象非常的重要。message_ptr是一个专门用来获取websocket请求消息的指针对象,可以通过get_payload获取websocket请求的有效载荷数据。
还有四个指定事件的回调函数,当服务器上特定事件被触发时,服务器对象会自动调用这四个回调函数,而这几个回调函数的内容是由程序员来编写的,实现服务器对业务的处理逻辑,这四个函数中只有set_http_handler是设置http请求的回调函数,其他三个都是用于处理websocket连接上消息的回调函数

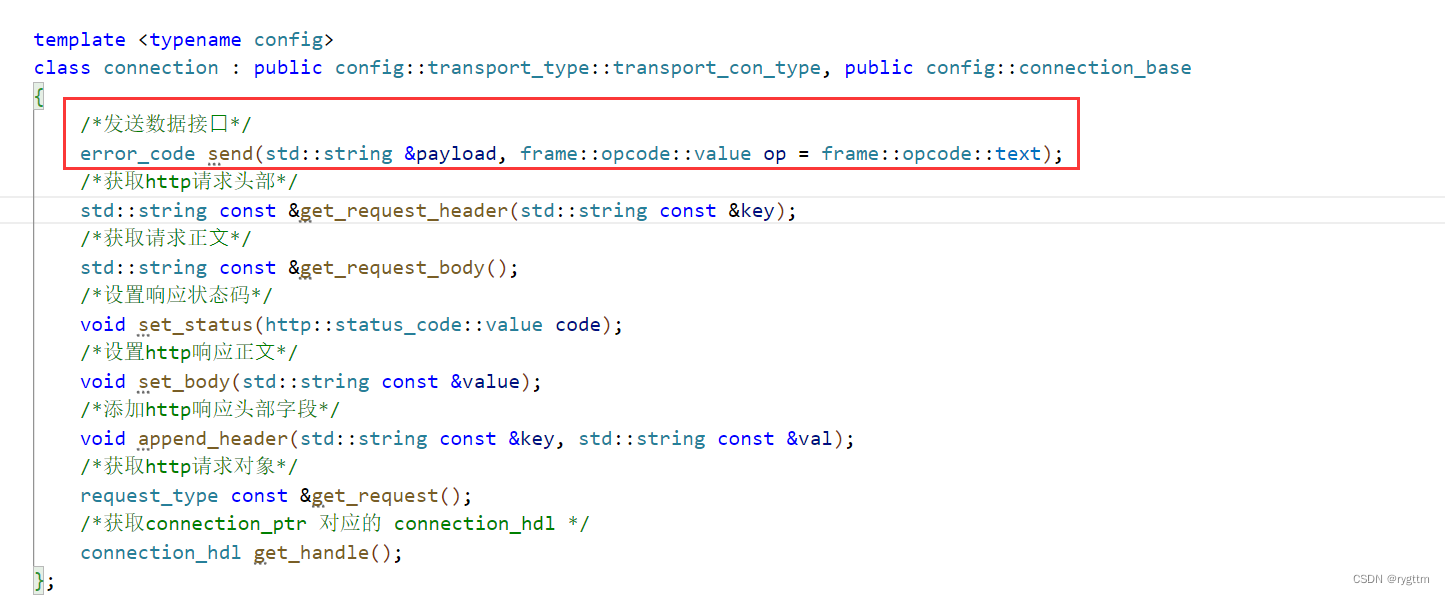
3.
下面是connection类的实现,从接口对应的协议来划分可以分为两类,一类是http,一类是websocket,只有send一个接口是在websocket连接上发送消息的,其他的接口全是和http有关的。

4.
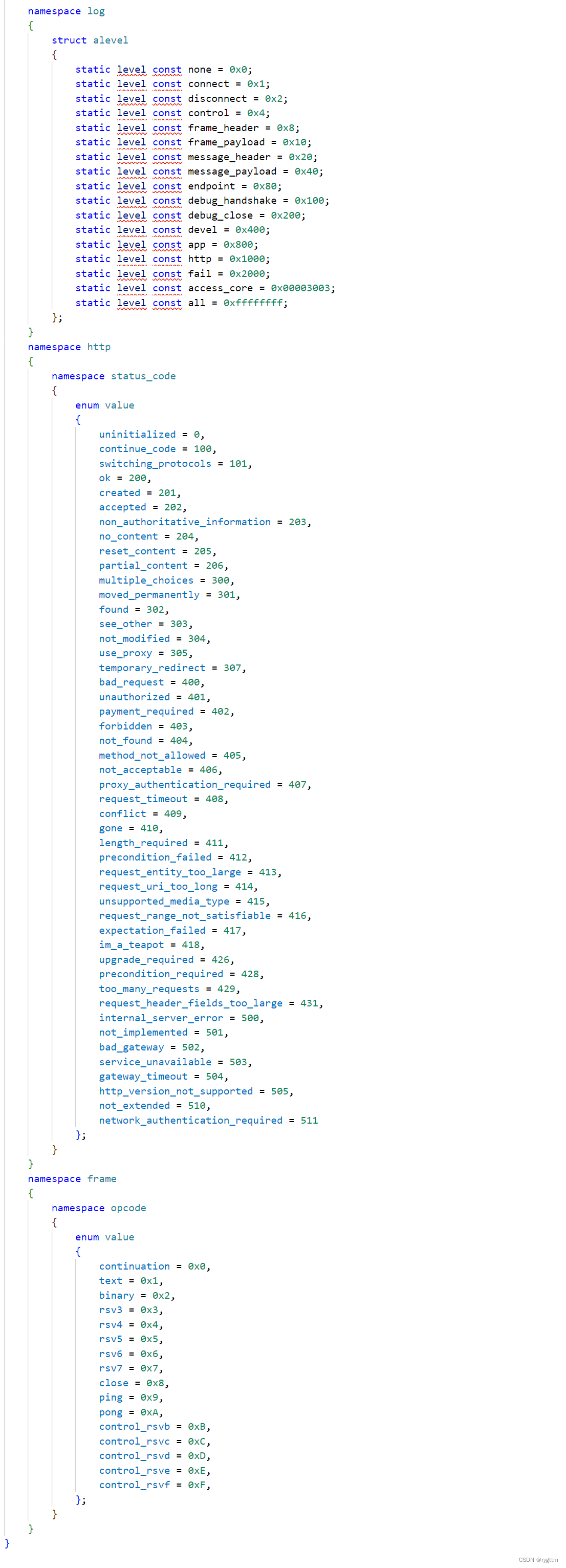
下面的这些都是websocketpp定义的一些日志等级,http响应状态码,websocket发送数据的类型等,日志这块我们到时候写项目的时候会自己实现,所以会将日志设置为none,表示禁止websocketpp打印所有日志。
至于websocket发送数据的类型,我们在写项目的时候也不会做改动,直接使用text类型,发送json风格的字符串响应。
1.3 搭建一个http/websocket服务器
1.
上面说了那么多肯定没啥用,干说咋可能学会呢,下面还是通过搭建一个服务器来熟悉websocketpp库中接口的使用吧。
2.
搭建服务器其实可以分为两个部分,一个是四种回调函数的实现,一个是调用wssvr对象进行服务器的各项功能初始化,第二个部分隐含了诸多的linux网络的知识细节,例如当服务器宕机后立马重启依旧还可以绑定原来的端口号,通过调用set_reuse_addr来实现,不使用websocketpp库所提供的日志输出函数,则可以通过调用接口set_access_channels(),传递一个none来实现。

3.
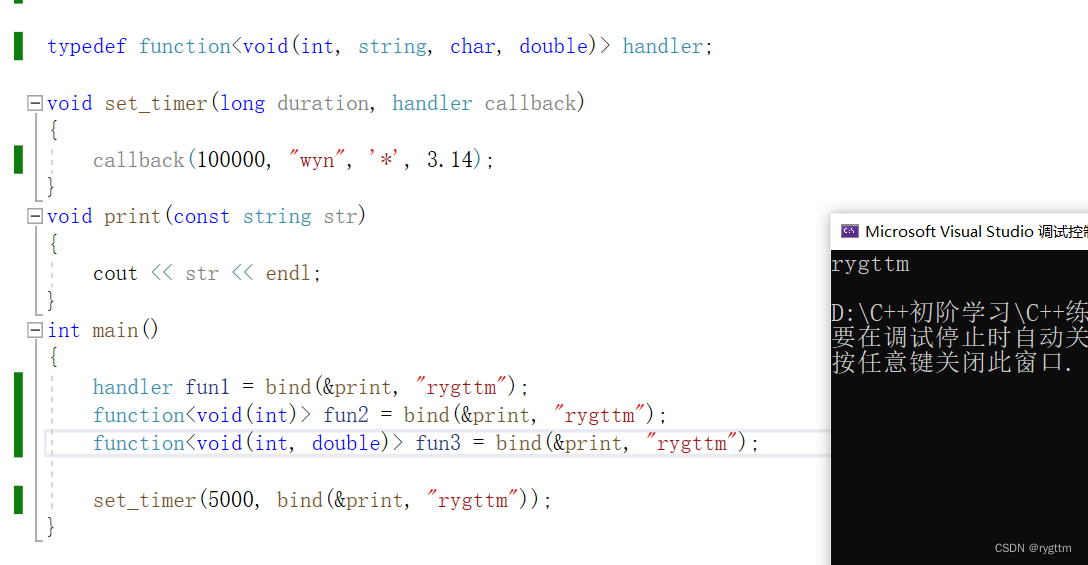
这里需要着重说一下bind的用法,bind有两种用法。
一种是绑死参数,这样的用法下,bind生成的对象在传参给包装器时,是不会影响类型的,也就是说你可以使用bind来传递任意的可调用对象给包装器,而无需关心包装器的类型是什么,bind绑定的可调用对象的类型又是什么,你想传什么传什么,在这种情况下,bind不影响传递参数时,参数的类型是什么,只影响实际调用时的参数是什么,实际调用时候的传参其实就是绑死的参数。
(这样的用法比较少见,常见于某些API的包装器参数功能无法满足我们的需求,我们此时想让这个包装器在调用时按照我们所实现的一个函数去执行,那么此时就可以采用绑死参数的方式来使用bind)
另一种是预留参数位置,等到bind生成的可调用对象被调用时,再去传参,bind提前用占位符来预留参数的位置。
下面的用例代码就可以很好的说明,bind生成的可调用对象的类型是完全适配包装器的,不管包装器的类型是什么,bind生成的可调用对象都可以传过去,并且无论最后你怎么给包装器对象传递参数,这都是徒劳的,因为bind已经将可调用对象print的参数给绑死了,callback实际调用的就是print(“rygttm”)这个函数。
另一种用法就是下面的四个回调函数的设置,这几个回调函数未来其实是由服务器自己去调用的,而不是我们来调用,当服务器收到http请求,则服务器就会自动调用我们所实现的http_handler类型的回调函数,当服务器收到websocket握手的请求,则在握手建立好之后会调用我们所实现的open_handler类型的回调函数,其他两个类型也是如此,这几个类型都是包装器类型重定义的,但在回调函数种,我们想用服务器类里面的某些接口来实现简单的业务处理,所以我们希望把wssvr对象也传到四个回调函数里面,而此时的做法就是通过bind来绑定部分参数,其余服务器自己调用时传递的参数我们通过占位符给预留出来,让服务器自己去传参,我们不操这个心,这就是bind的第二个用法。

4.
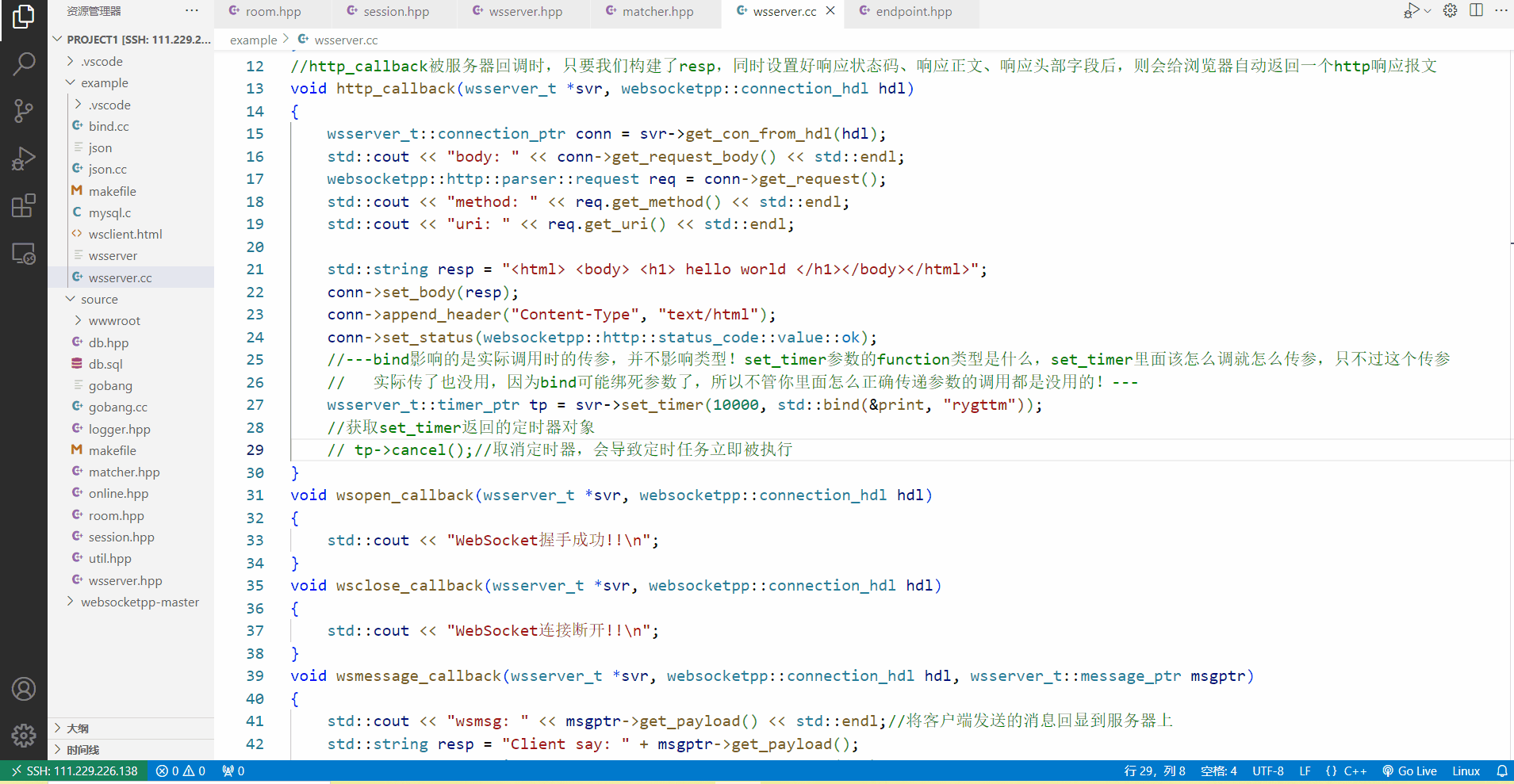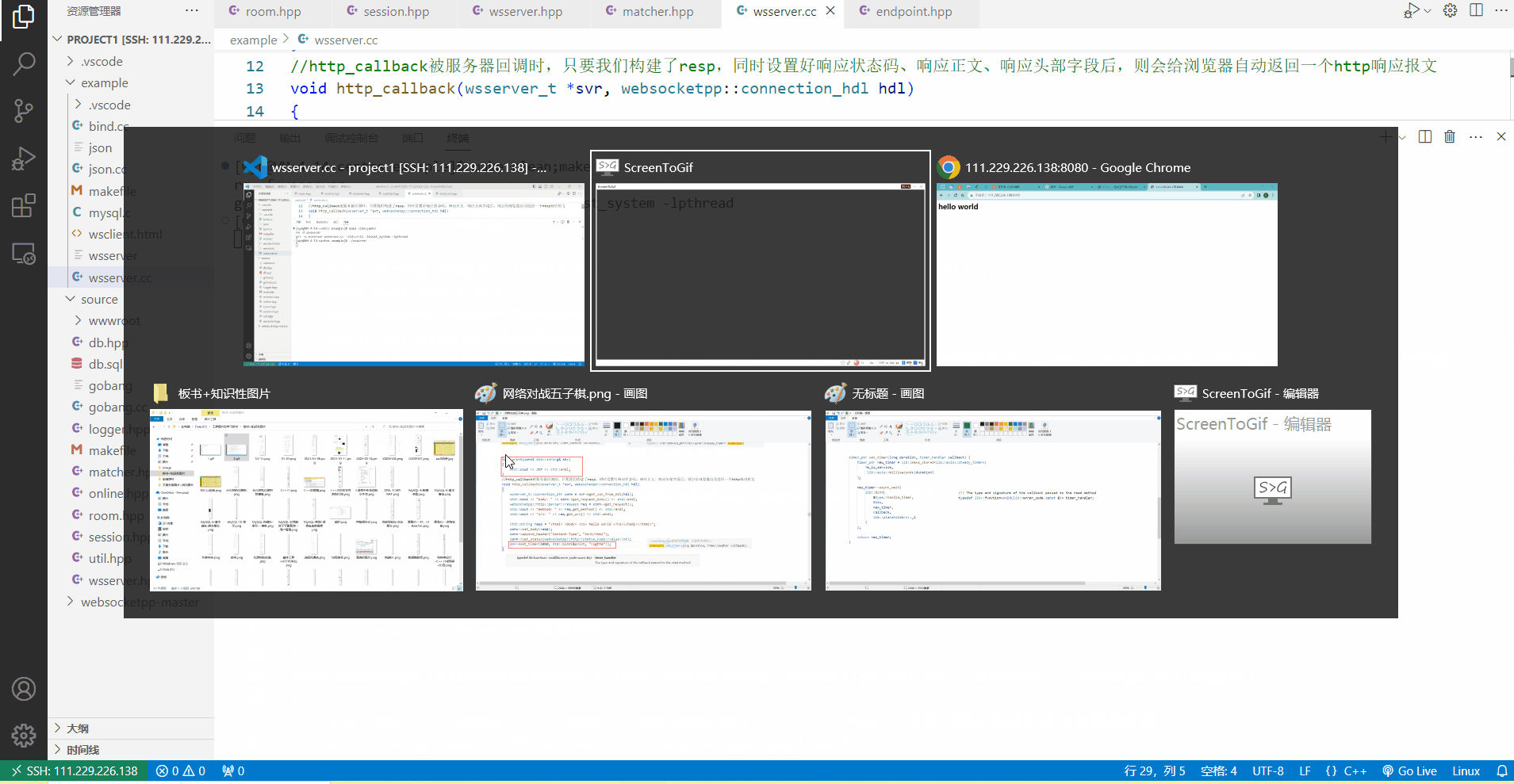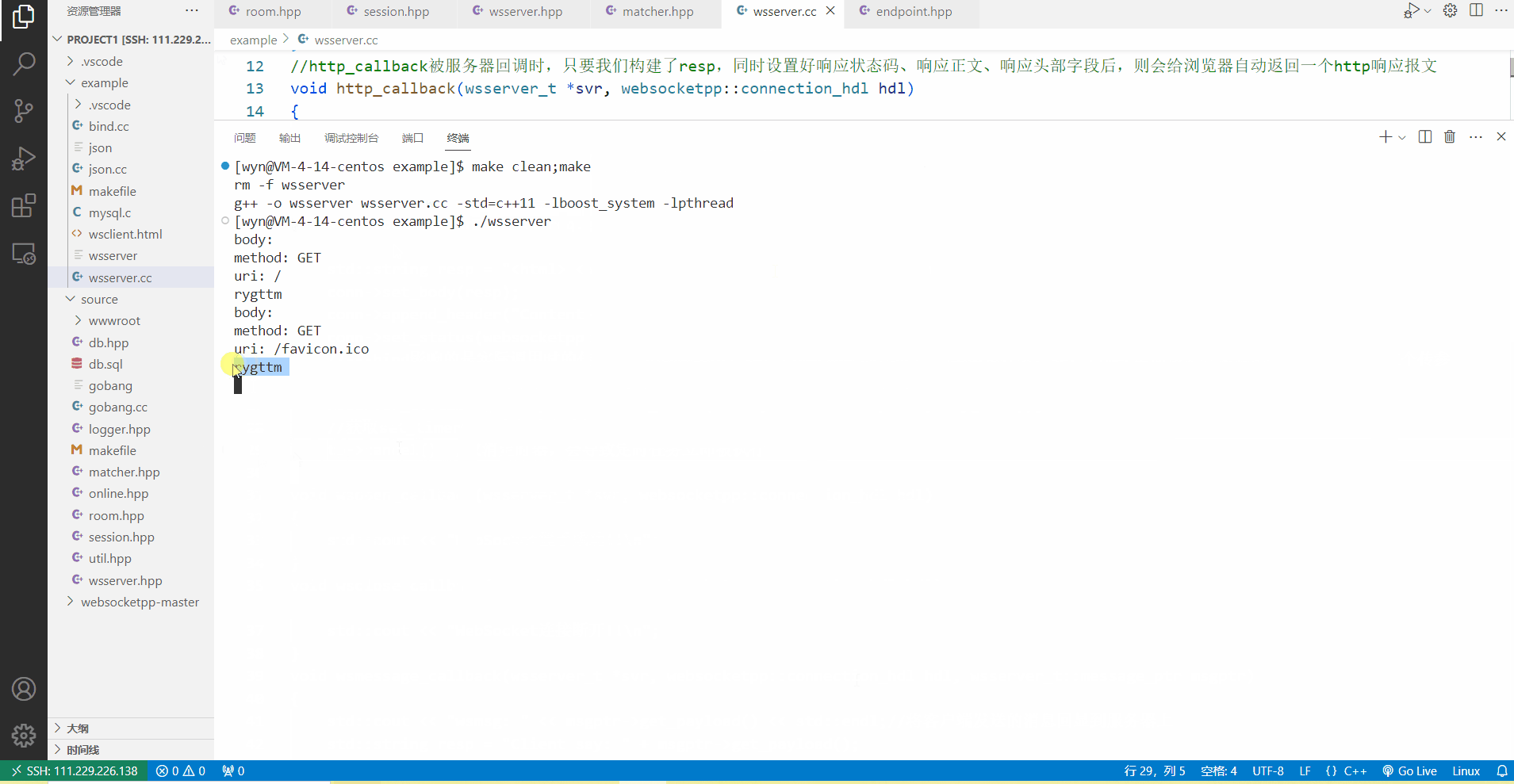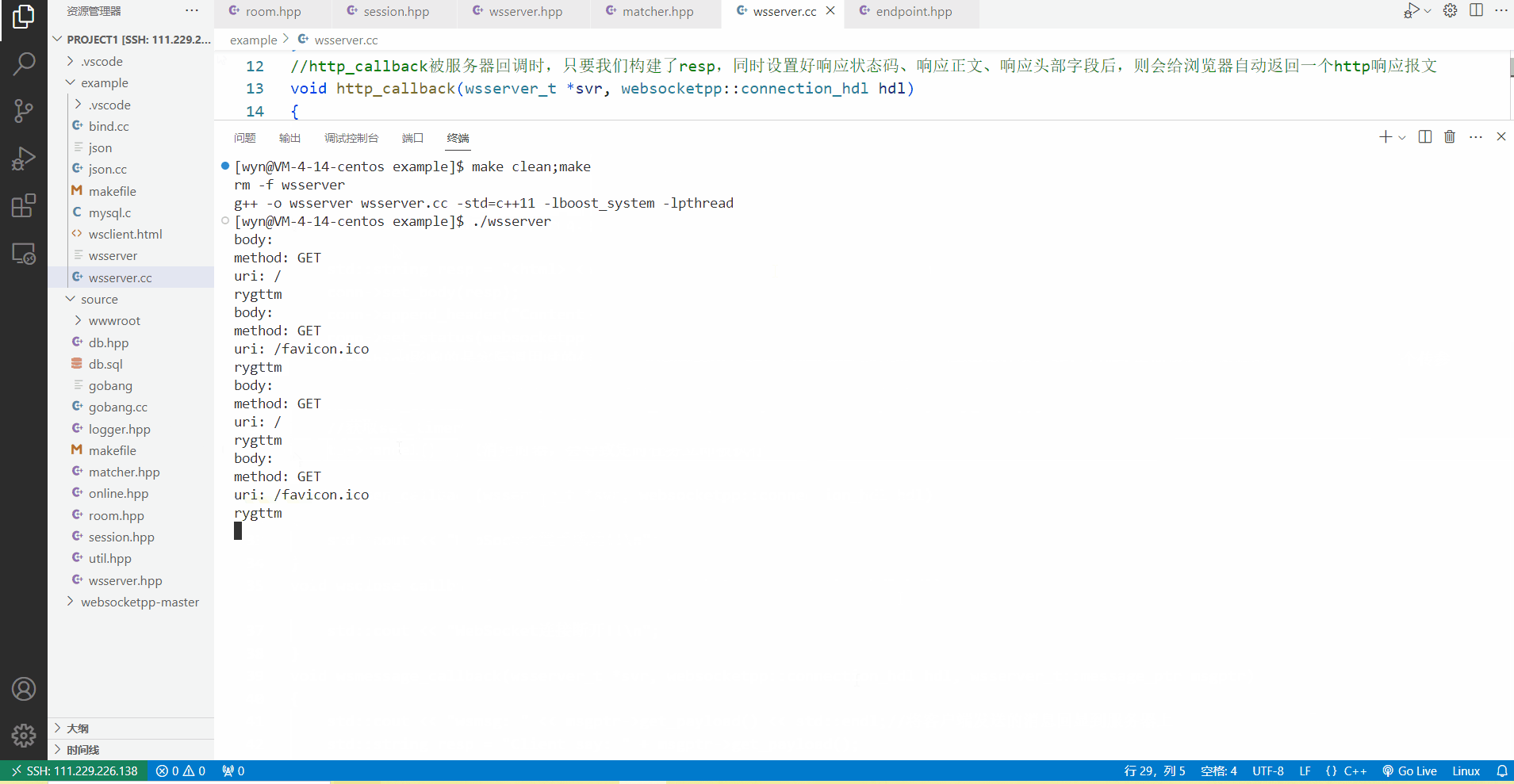
这四个接口中重点实现http_callback和wsmessage_callback,在http_callback里面,我们打印一下http请求的几个重要信息,然后给客户端返回一个简单的html页面。
值得注意的是,http响应的返回和websocket消息的发送所调用的API是不一样的,我们只需要通过conn这个连接智能指针管理对象,调用set_body设置好响应正文,调用append_header设置好响应头部字段,调用set_status设置好响应状态码,然后服务器就会自动构建一个包括状态行,响应报头,空行,响应正文的完整的http响应信息返回给客户端!
而对于websocket消息的发送我们也是通过conn这个智能指针来发送的,发送的方式非常的简单,只要调用send接口即可,第一个参数是要发送的websocket有效载荷数据,第二个参数缺省值默认是文本类型,我们可以传也可以不传这个参数。resp正文的内容其实就是客户端发送的消息,我们服务器这里做一个消息的回显,回显给客户端,同时也把消息打印到服务器上看看消息内容是什么,发送websocket数据,可以看到调用的正好也是send接口。

5.
我们自己写完服务器的四个回调函数的逻辑之后,接下来的三个接口应该是不陌生的,其实就是监听端口号,看是否有客户端向我们服务器绑定的端口号发起了连接请求,如果有那就将三次握手后的连接加入到内核监听队列中,这个监听队列的长度一般是5,我们也可以自己设置。
服务器调用start_accept就是将内核监听队列中已经完成三次握手的连接拿上来,通过这个连接服务器就可以和客户端进行通信了,所以三次握手的过程和accept系统调用没有任何关系,三次握手的过程是在listen过程中进行的。
最后只要调用websocketpp库中的server类中的接口run,就可以将服务器运行起来了,到此就完成了wsserver.cc代码的编写。

6.
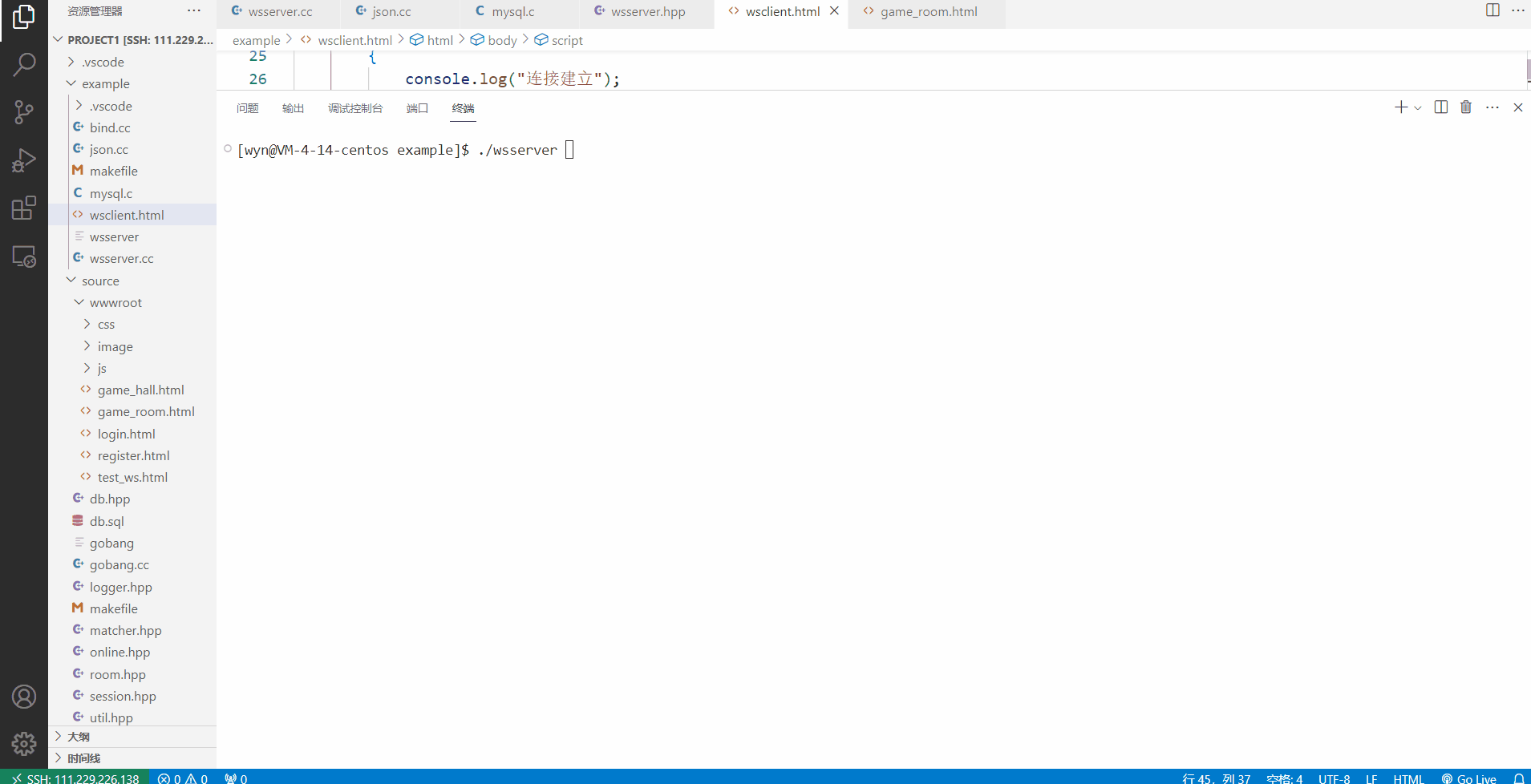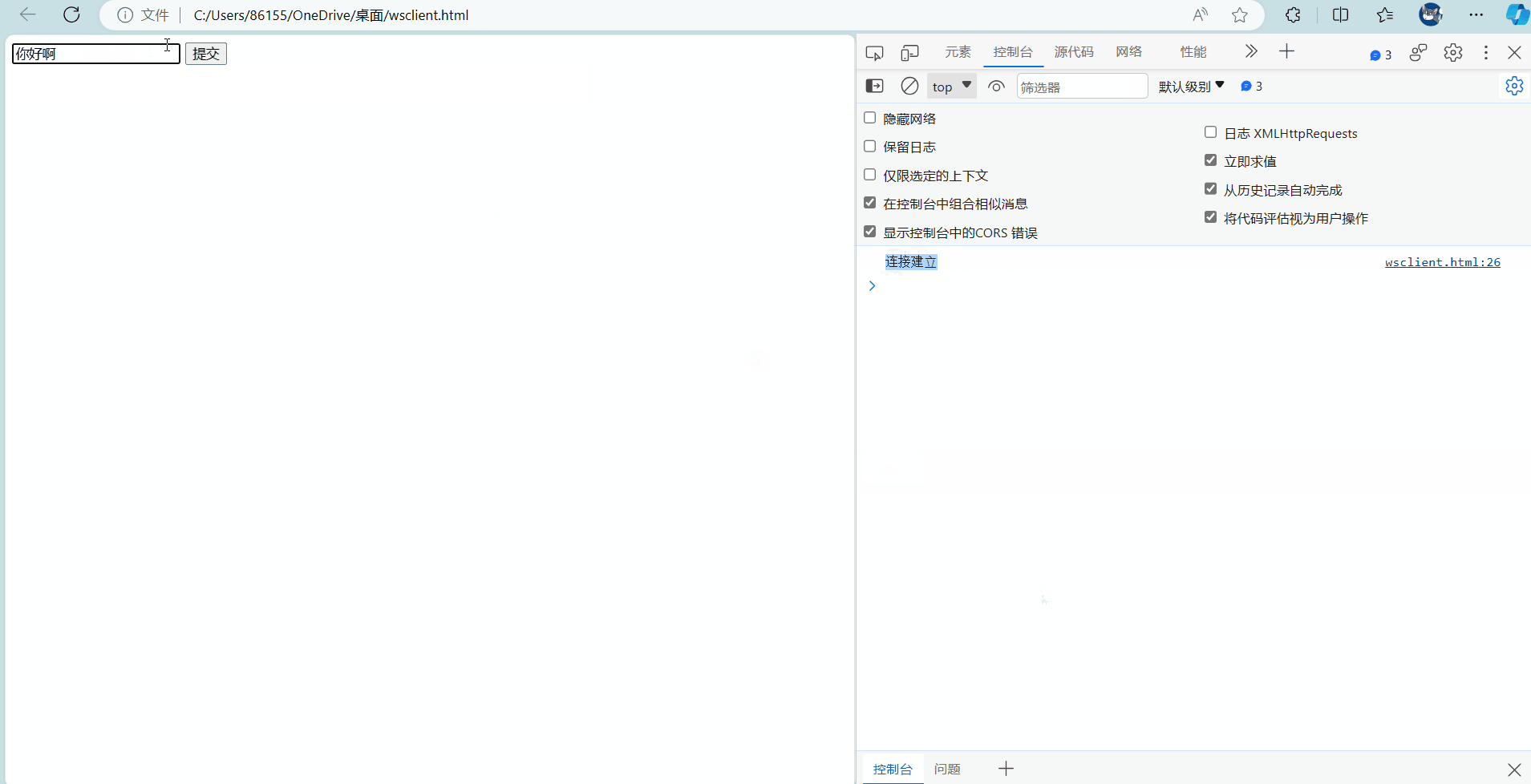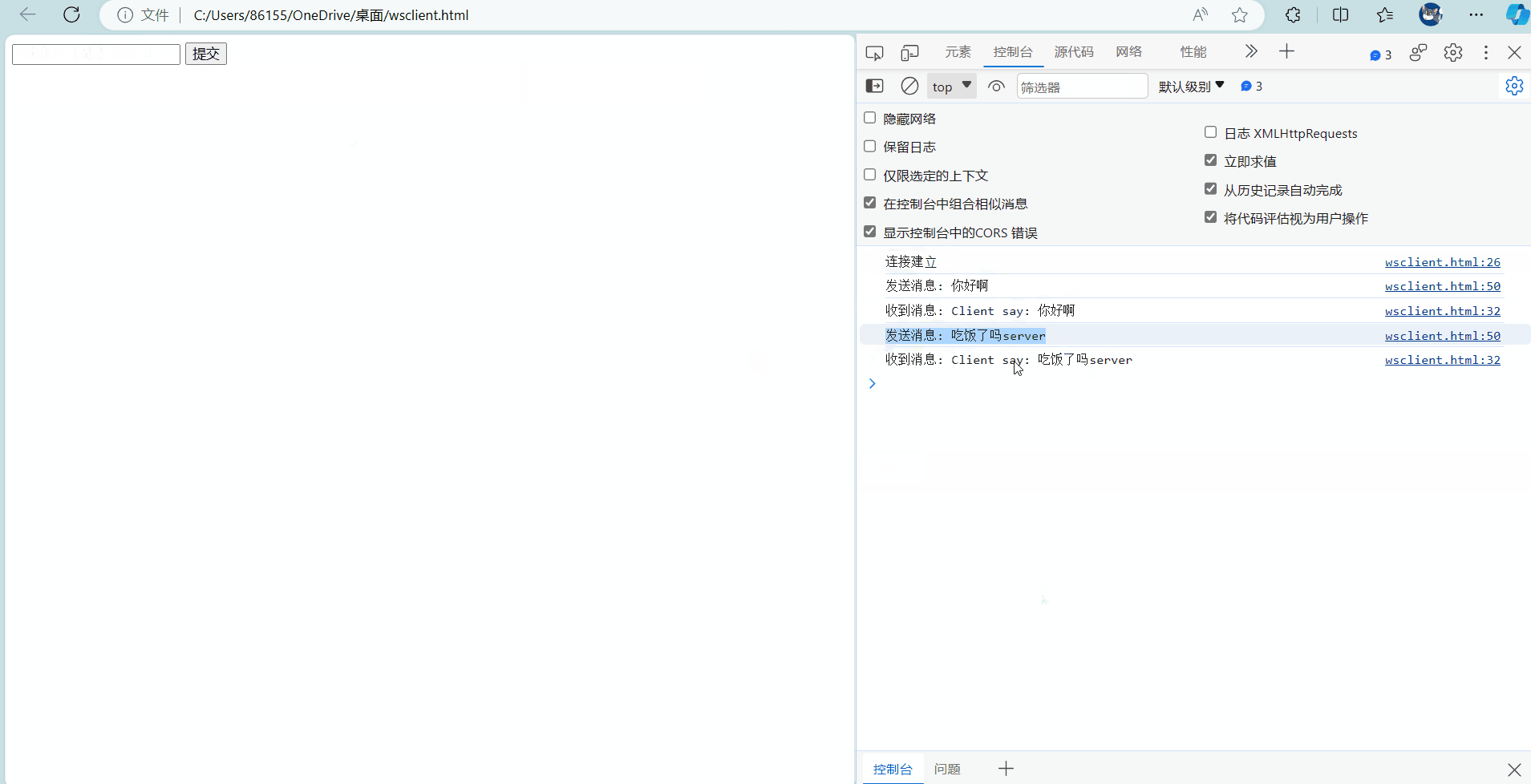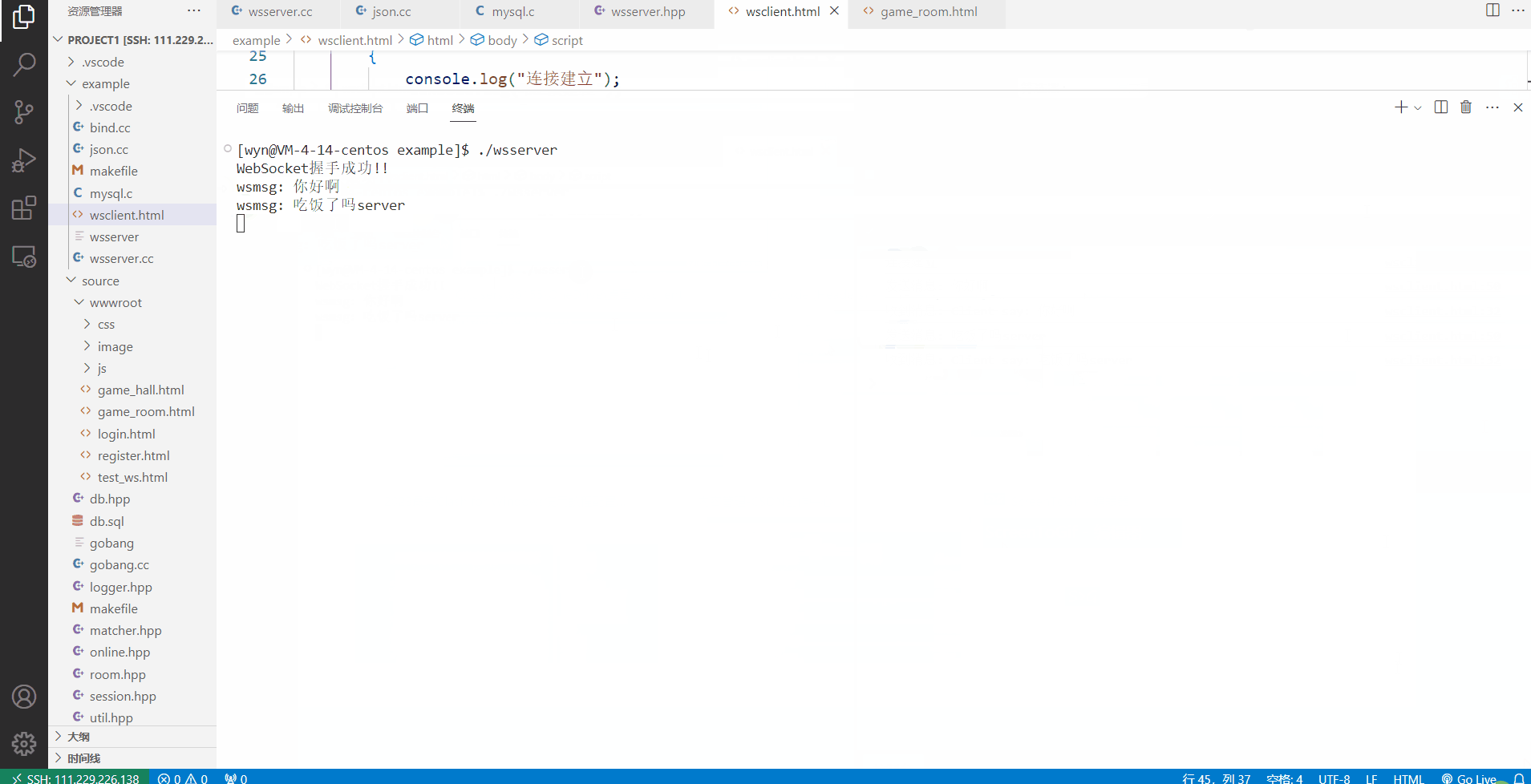
光实现一个服务端肯定还是不行的,http客户端我们可以不用实现,直接使用浏览器向服务器发起http请求就可以解决,但websocket客户端必须由我们来实现了,我们需要自己编写一个wsclient.html的前端页面来充当客户端,通过在浏览器打开这个页面来向服务器发起websocket连接建立的请求。
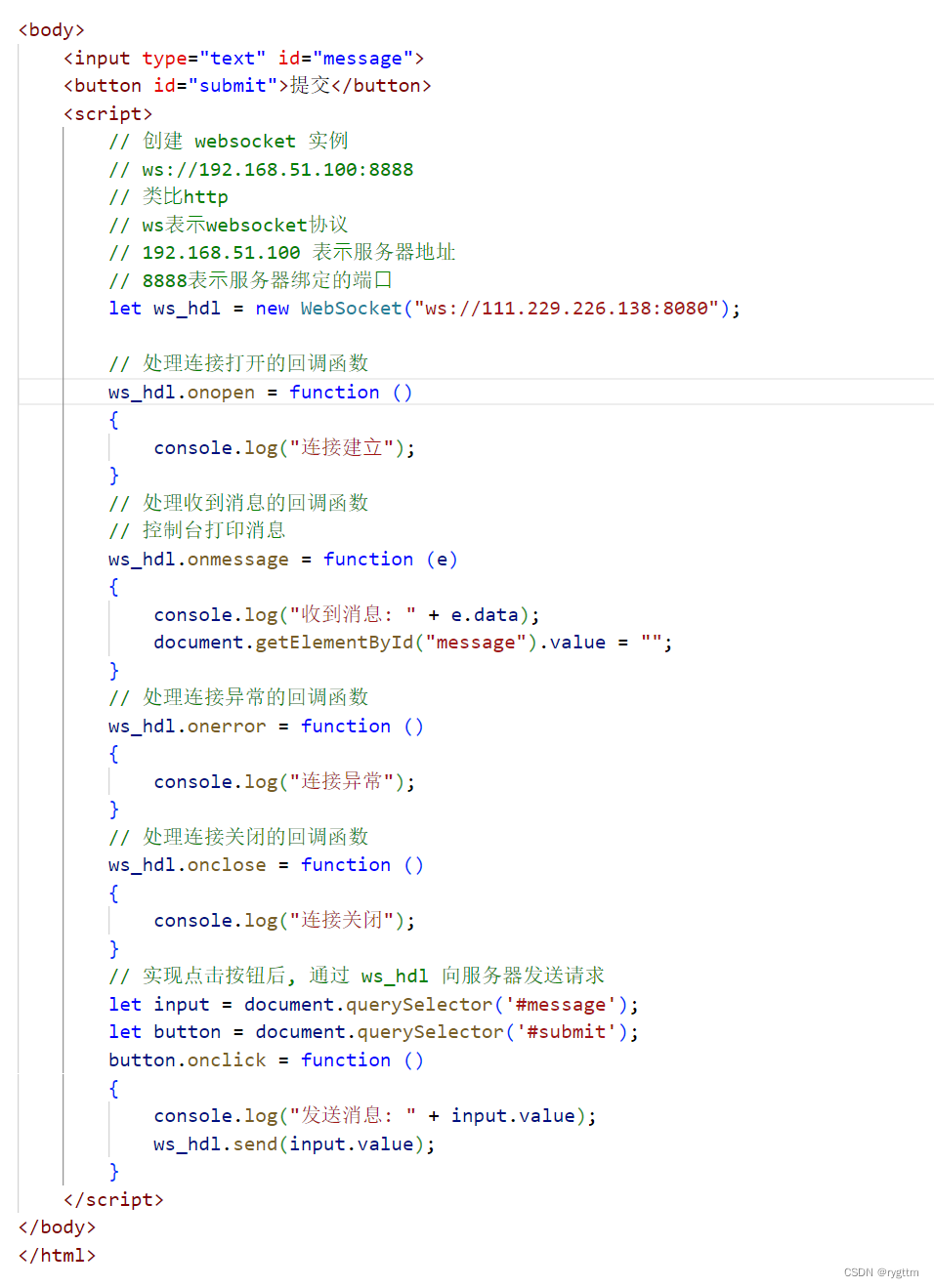
实现客户端主要也是分为两个部分,先通过new WebSocket向指定服务器发起websocket连接握手,当服务器收到连接请求后,服务器会返回一个握手代表双方websocket长连接建立成功,前端这边会有一个连接的句柄,也就是let定义的ws_hdl,通过这个句柄来实现客户端和服务器的websocket通讯,类似于服务器的四个回调函数,前端这里也有ws_hdl被创建成功后的四个回调函数,在onmessage回调函数的参数中,是有一个事件evt参数的,这个evt保存的是服务器返回的一个普通字符串,通过.data的方式就可以访问到里面的内容了,如果服务器返回的是json序列化之后的字符串,则我们需要先对e.data做json格式的解析,然后才能访问到里面的内容,但今天我们只是搭建一个样例服务器,所以就不搞序列化反序列化那一套了,能够实现双方的通信就可以了。
前端这里实现了一个输入框和一个提交按钮,我们同时为这个提交按钮添加了一个点击事件,用于向服务器发送,输入框中用户输入的消息内容,服务器会将我们发送的消息重新作为响应返回到前端这里,前端的onmessage收到响应事件后,会将消息内容通过console.log打印到开发者工具的控制台上,我们到时候通过fn+f12打开控制台就可以看到这些日志消息了。前端这边除了将消息以日志方式打印出来,还做了另一步操作,其实就是将输入框中的消息内容清空,通过id来获取输入框,然后将里面的值置为空串即可。
6.
在观察实验现象前,需要说明一点,我们今天所实现的前端页面虽然确实是在linux机器上,但他不在wsserver里面,因为我们没有在里面搞一个web根目录,将前端页面放到web根目录中,所以想要在浏览器中打开前端页面,只能先将html文件放到win机器本地上,然后通过打开浏览器来访问websocket服务器,以此来实现客户端和服务器通信。
不过不用担心,后面实现项目的时候,我们会将前端资源放到web根目录下,浏览器直接请求服务器上的web资源即可,而无需以本地打开html文件的方式来与服务器进行通讯。
通过下面的CS通信可以看到,服务器和客户端成功以websocket连接的方式实现了通讯,这个前后端通信做的确实比较简陋,等后面实现项目的时候,CS之间的交互会变得很多,到时候就可以更熟练的使用websocket进行通讯了。
2. jsoncpp库
1.
在网络通信中,由于传输的数据往往是一个较大的集合,这个集合中会容纳多种不同类型的数据,所以通信双方往往要对发送的数据做整合封装和拆解,这两个步骤用专业一点的词汇来描述就是序列化和反序列化,双方使用同一种方案来进行序列化和反序列化,保证能够对数据进行合理正确的解析以及对数据打包发送。
这样的序列化和反序列化方案,其实我们可以自己做,但一般我们不自己写,因为应用层已经有大佬帮我们写好了,常用的例如xml,json,protobuf等等,本项目中用到的就是json这样的序列化方案。
2.
json这个类重载了=和[ ]操作,这使得构造一个包含多种数据类型的json对象变得非常的方便,使用json对象时,只需要通过[ ]来使用即可,可以传递一个数组的下标,一个字符串等等。

StreamWriterBuilder这个类其实就是一个工厂类,通过这个工厂类能够生产出一个StreamWriter对象,通过这个StreamWriter对象,我们就能够进行json格式的序列化。
json在进行序列化时,所调用的接口write,即将一个json对象序列化为一个json格式的字符串,然后这个字符串会被放到输出流对象sout里面,我们一般传递的都是stringstream的对象,这个stringstream对象内部有一个str()接口,通过这个接口我们就可以拿到string类型的可以发送到网络中的字符串了。

CharReaderBuilder也是一个工厂类,通过这个工厂类能够生产出一个CharReader对象,通过这个CharReader对象,就能够进行json格式字符串的反序列化。
json在反序列化时,是通过parse接口来将json格式的字符串解析反序列化到Value 类型的root对象中,只不过我们需要传入这个json格式的字符串的起始地址和末尾地址。

3.
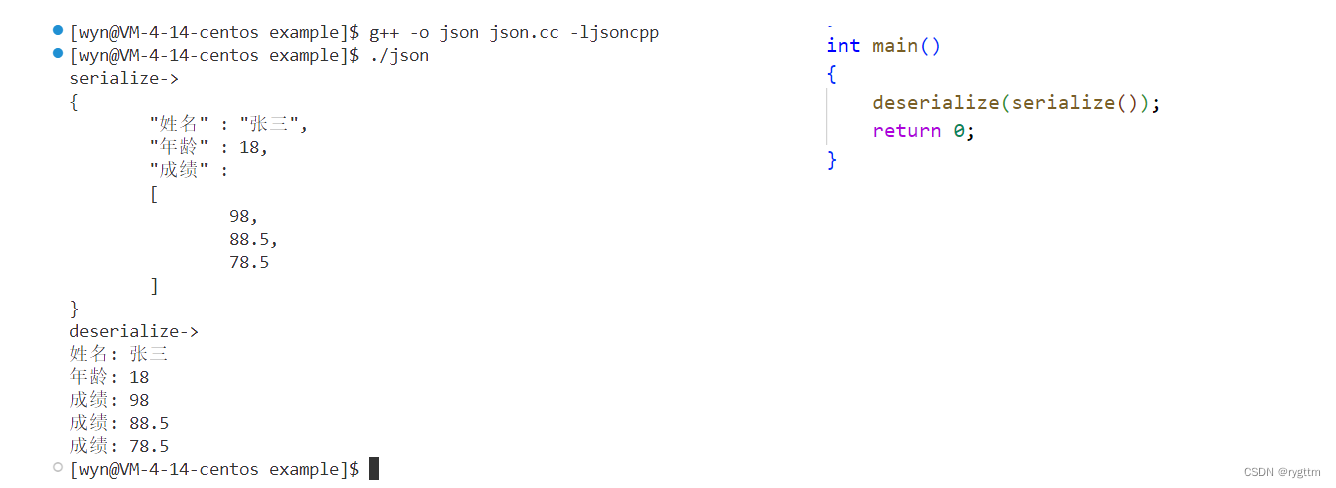
下面是一个json序列化的案例代码,帮助我们进行基本的序列化实现,首先定义一个Json::Value对象root,然后通过=和[ ]运算符,向root里面填充需要发送到对端的字段,比如添加const string类型的字符串,int类型的整数,向root中添加一个浮点数数组,数组的添加我们不能使用=运算符,需要借助Json::Value类里面的append接口来实现,不断的调用append接口,即向数组中不断的添加元素。
真正进行序列化时,我们需要先生产一个StreamWriter对象,然后调用write接口,将root和ss两个对象传递进去,调用成功后ss里面的str()就会返回一个string字符串,这个字符串就可以直接发送到网络里面,通过网络传输到对端主机,别忘了释放掉sw这个StreamWriter对象,因为这个对象的内存是动态开辟出来的,用完了,要记得还给操作系统,否则会造成内存泄漏。

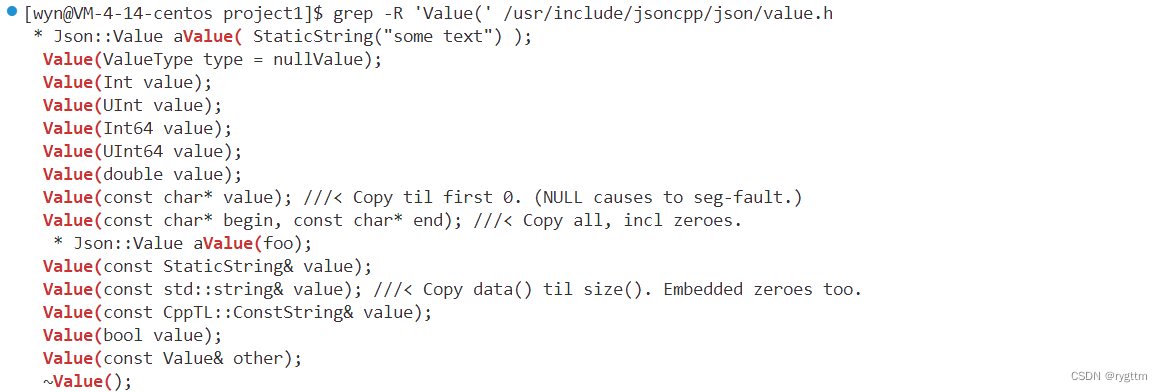
其实在上面的序列化代码里面,隐含了一部分C++的语法知识,那就是单参数构造,从库文件里面我们可以看到,他只重载了一些基本类型到Json::Value类型的构造函数,为什么上面的代码中能够可以讲18这个整形直接赋值给root呢?其实就是因为库里面实现了下面的这些单参数构造函数,所谓的赋值可以细分为先通过参数构造出一个value对象,然后拿着这个对象来进行赋值给root对象,这个赋值的接口是库里面实现了的,Value &operator=(const Value &other);,构造出来的临时对象刚好是一个常对象,正好可以传递。
4.
下面是反序列化的过程,首先实例化一个工厂类对象,通过这个对象生产出一个CharReader对象,然后调用parse接口进行json格式字符串的反序列化,解析的过程可能会发生错误(90%的正常情况下不会发生错误),所以可以传一个输出型参数err,解析成功之后,root对象就是原生的发送方想要发送给我们的内容了。
我们可以通过[“xxx”]来拿到对应的value对象,但需要注意的是,如果想要拿到里面的值,我们还需要做一步类型转换,因为json的[ ]重载函数返回的是jsonvalue对象,而不是我们想要的内置类型,所以还需要进行asInt,asCString,asFloat等接口的帮助,我们才能访问到里面具体的值。
与序列化相同的是,最后别忘记释放动态开辟的内存,否则会造成内存泄露。

5.
调用我们实现的上面两个函数之后,从打印结果可以看出,jsonvalue对象其实是一个{}构成的具有特定格式的一种对象,比如添加了换行符,制表符,包含的内容采用了key : value的形式进行组织,对于数组类型的数据,value采用了[, , ,]的格式进行组织。
我们反序列化上面json格式的字符串之后,打印内容就是简单的逐行打印。
3. mysqlclient库
1.
由于本项目使用的是mysql数据库来存储玩家信息,所以在项目前置知识这里,我们还需要了解如何通过C风格的API接口来操纵数据库。
1> 首先需要初始化一个mysql的句柄,这个句柄是很常用的一个概念,像文件描述符,套接字,文件指针这些都可以称之为句柄,你可以把他理解为一个魔法棒的存在(没办法这个太不好描述了),我们想要做某件事不能直接去做,而是需要借助句柄去做,比如你网络通信,双方能直接通信吗?难道都用嗓子喊一声?这肯定是不行的,在代码层面上,我们就是通过socket套接字来完成通信的,比如对文件进行读取,写入等操作,你是直接对硬盘上的某个文件操作吗?其实不是的,我们是要在代码层面上通过文件指针来完成这样的操作的,mysql也是一样的,在代码层面上我们需要一个指针对象,通过这个指针对象来对数据库进行增删查改,这个指针对象就是mysqlclient库里面定义出来的MYSQL类型,后续所有的对数据库的操作,都是通过这个类型的指针来完成的。
2> 初始化好句柄之后,下一步就是连接数据库,这个句柄一定是要有操作对象的,没有操作对象还玩什么啊,在数据库这里,句柄的操作对象就是database,在文件中,操作对象就是文件,在网络通讯中,操作对象就是socket连接,在今天的websocket协议通讯中,操作对象那就是websocket连接,道理是类似的。连接数据库需要指定mysql所在的主机ip地址,mysqld服务的端口号,database的名字,登录数据库服务的用户名以及密码等,mysql这样的服务为了保证安全性,是不允许用户跨网络远程登录的,必须要求在本地进行登录,所以ip地址就是我的云服务器本身的ip地址,那就是本地环回地址,至于端口号,这个我们可以自己在mysql的配置文件中设置,如果没有设置过的话,则默认就是3306端口。当然连接也有失败的可能,在编写项目类的代码时,日志输出错误信息是非常重要的一种调试手段,所以编写用例代码我们也延续这样良好的代码风格,做好差错处理,因为mysql_real_connect接口是有可能调用失败的,当失败时,我们要在服务器上输出错误信息,确保后期好定位代码中的错误。
3> 连接数据库成功之后,下一步就是设置字符集,客户端和mysqld服务端要保证字符集是一致的,否则我们编写的sql语句都有可能被服务端识别错误,导致sql语句无法正常执行,服务端默认的编码格式是utf8的,所以我们设置客户端的编码格式也是utf8,保证双方是一致的编码格式
4> 选择要操作的数据库,这个接口其实是比较鸡肋的,因为操作数据库的信息我们早在调用mysql_real_connect时就填充好了,所以这个接口我们就不调用了,什么都不做

2.
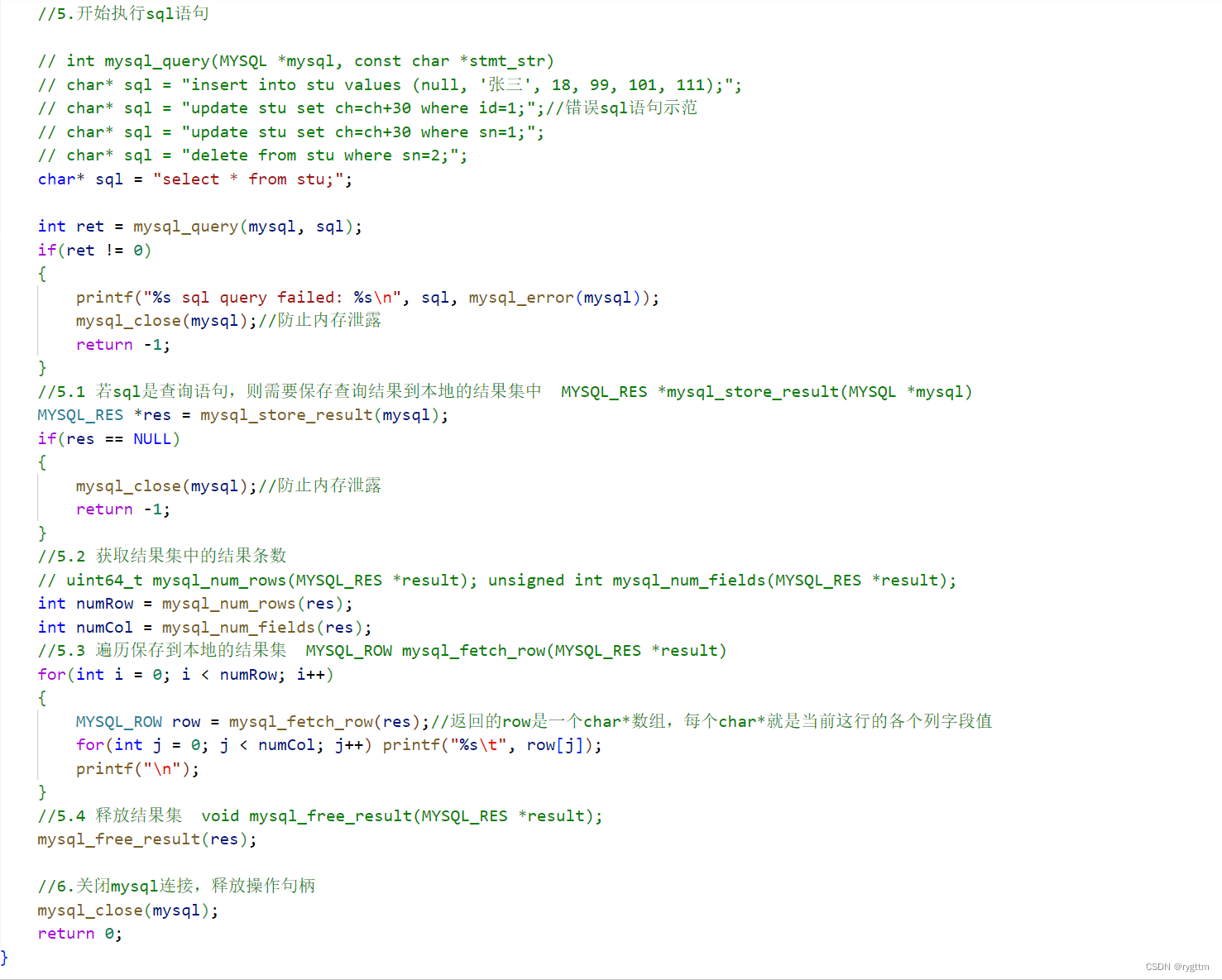
5> 接下来就是让数据库执行对应的sql语句了,sql语句共4类,只有select的执行逻辑是不一样的,因为select需要把数据库中查询显示到的信息展示在我们的终端上,而其他的更新,删除,插入语句是不需要回显的,执行成功就是成功了
6> 针对select语句,MySQL也提供了对应的API,例如mysql_store_result就是用来保存select语句查询结果的,我们需要自己定义一个MYSQL_RES类型的指针,用来指向堆上mysql_store_result帮我们开辟好的一块内存,这块内存就是查询结果。
mysql_num_rows用来获取查询结果中的条数,mysql_num_fields用来获取查询结果中的列数,因为MySQL的存储格式是行列式的,所以就需要这两个接口来获取行数和列数。
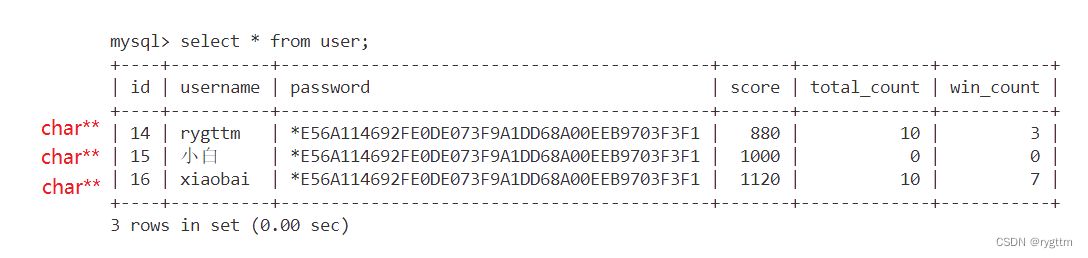
在拥有res查询结果和结果集的行数和列数之后,我们就可以遍历结果集,将select查询结果显示到代码终端上了,mysql_fetch_row是一个返回数组的接口,你把res传给他,他会依次逐行返回每行的结果,每行的结果就相当于一个char**的数组,mysql_fetch_row会给我们返回这个数组的首地址,通过这个首地址+下标索引,就可以拿到每行中所有的列字段值了。
7> 上面sql语句的执行完毕之后,如果有查询语句的话,千万不要忘记释放结果集,因为res这个指针指向的内存是mysql_store_result帮我们动态开辟出来的,所以一定要调用mysql_free_result来释放结果集。最后我们也要释放句柄,因为这个句柄管理的内存也是mysql_init帮我们动态开辟出来的,如果不释放则会内存泄露。
二、 项目设计
1. 项目模块划分
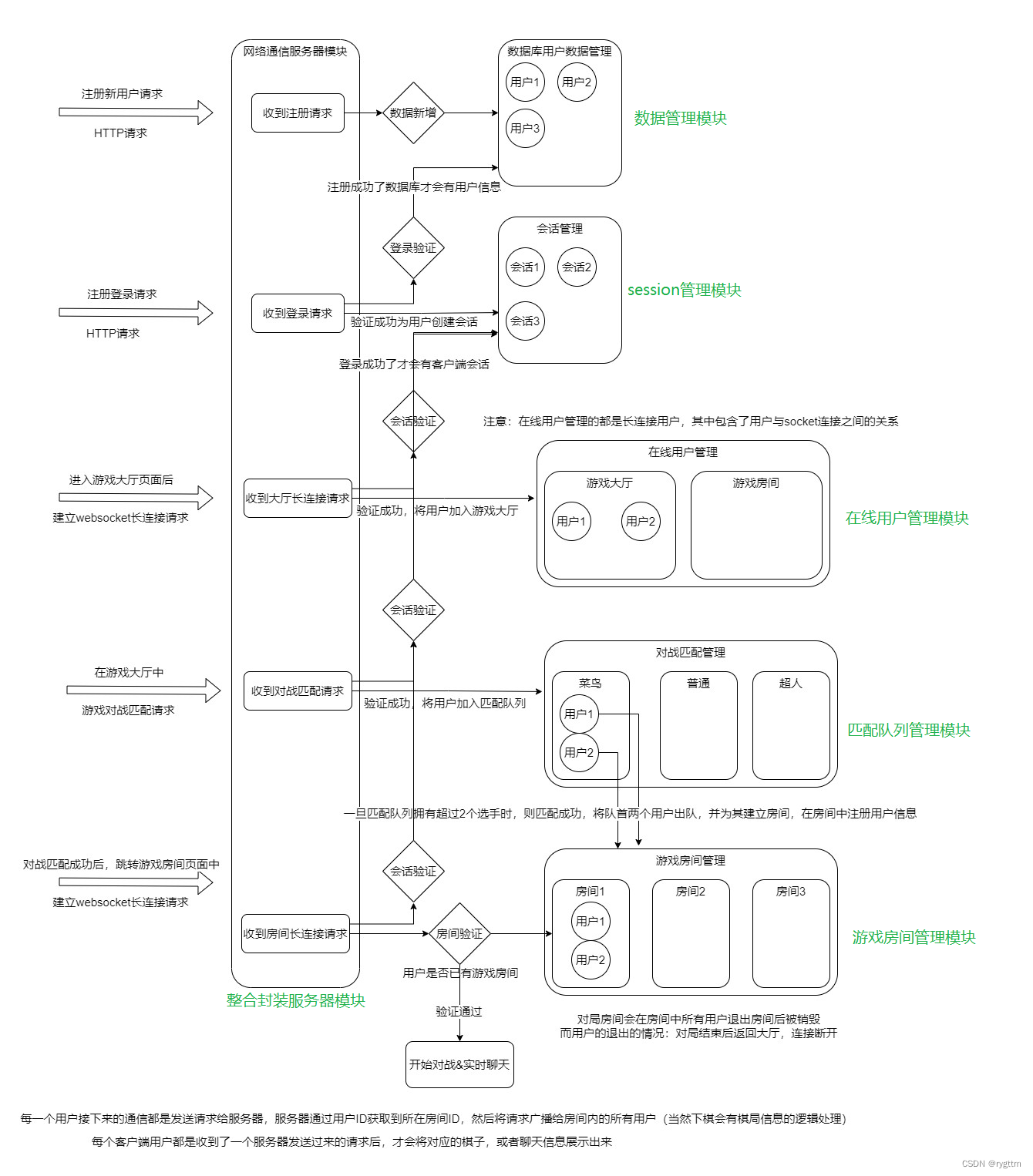
1.
项目总体其实可以划分为三个模块,一个是数据管理模块,也就是进行用户信息的注册,存储用户的对战信息等等,例如用户名,密码,总战斗场次,胜利场次,天梯分数等等信息都是靠数据管理模块来维护的。
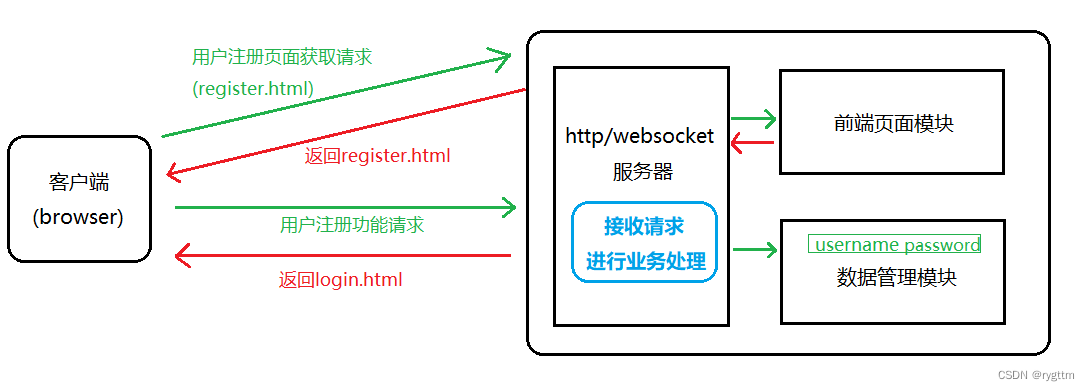
另一个是前端页面模块,这个模块也是很重要的,当前端页面被浏览器获取并运行起来时,他就是用户直接接触的一个模块,用户在页面里进行的所有操作,其实都是一个业务请求,这些业务请求都会被发送到服务器上,由服务器来对这些请求进行业务逻辑处理,客户端可能产生的业务请求有:register.html页面的获取,获取好页面后,用户会输入自己的用户名和密码,然后点击提交按钮进行用户的注册,点击按钮之后,注册的请求就会被发送给服务器,服务器会通过数据管理模块来判断这个用户名是否已经存在,如果存在,则说明注册请求失败,服务器返回一个失败的响应,如果注册成功,则服务器返回一个login.html,用户面前就是展示成登录的页面了,此时用户就又可以输入用户名+密码,点击提交按钮进行登录,当登录的请求被发送到服务器后,服务器会检验用户是否存在,如果存在则判断用户名和密码是否正确,如果正确说明登录成功,此时应该向用户展示游戏大厅game_hall.html的页面,进入游戏大厅后,客户端还要与服务器建立长连接,进行对战匹配的请求,如果对战匹配成功,则还要跳转到游戏房间页面,在游戏房间中还要有下棋聊天等业务请求…
最后一个模块就是项目的主体,也就是业务处理模块,通过上面的前端模块的分析,大概得有10多个业务请求吧,所以我们的服务器除了要能和客户端进行通信以外,还要能够正确处理这些请求,这些处理的逻辑我们统称为业务处理模块。
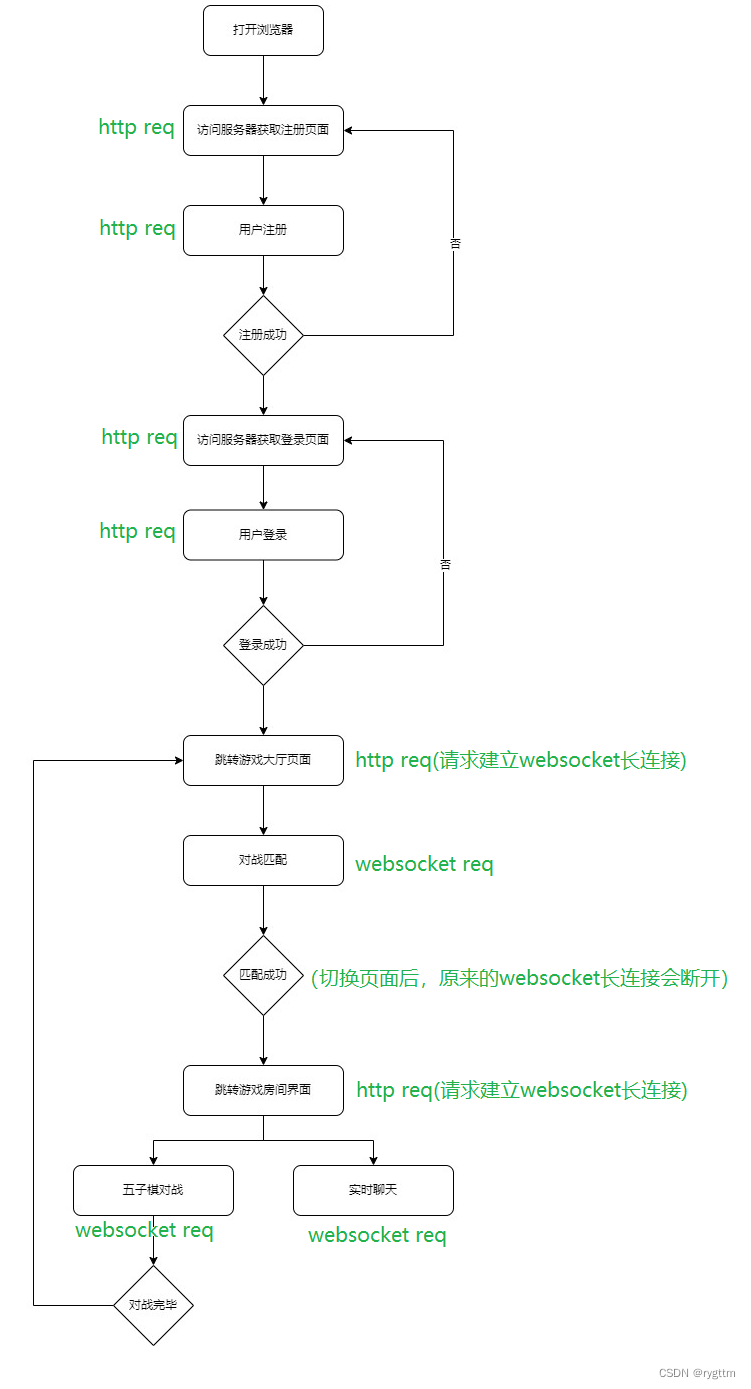
下面是玩家用户玩游戏的整个逻辑流程图,值得注意的是,当页面切换时,浏览器会主动将原来的websocket连接断开,以此来确保资源的释放和网络连接的正常关闭,所以当页面从游戏大厅跳转到游戏房间时,需要重新建立websocket连接,因为原来的连接已经断开了。
2.
但由于业务处理模块非常的繁杂,所以业务处理模块我们还要进行细分,细分到每个子模块功能的具体实现。
总共包括六个模块的实现,数据管理,session管理,在线用户管理,匹配队列管理,游戏房间管理,最后封装实现服务器模块。每个管理模块实现的原因,以及其中的细节,我们都放到每个模块中进行讲解,这里先预热一下,知道项目大概都实现了什么。
2. 实用工具类模块
2.1 日志宏封装
1.
由于在实现项目的时候,如果某些接口调用,或者逻辑有问题总是会进行日志打印,以此来帮助我们进行代码的调试来定位错误,所以为了方便后面进行日志的输出,我们这里封装一个日志宏,通过宏函数来进行调试信息或错误信息的打印。
2.
time是一个用于获取时间戳的一个函数,即从1970年1月1日到现在过了多少秒,然后返回一个time_t类型的对象。

3.
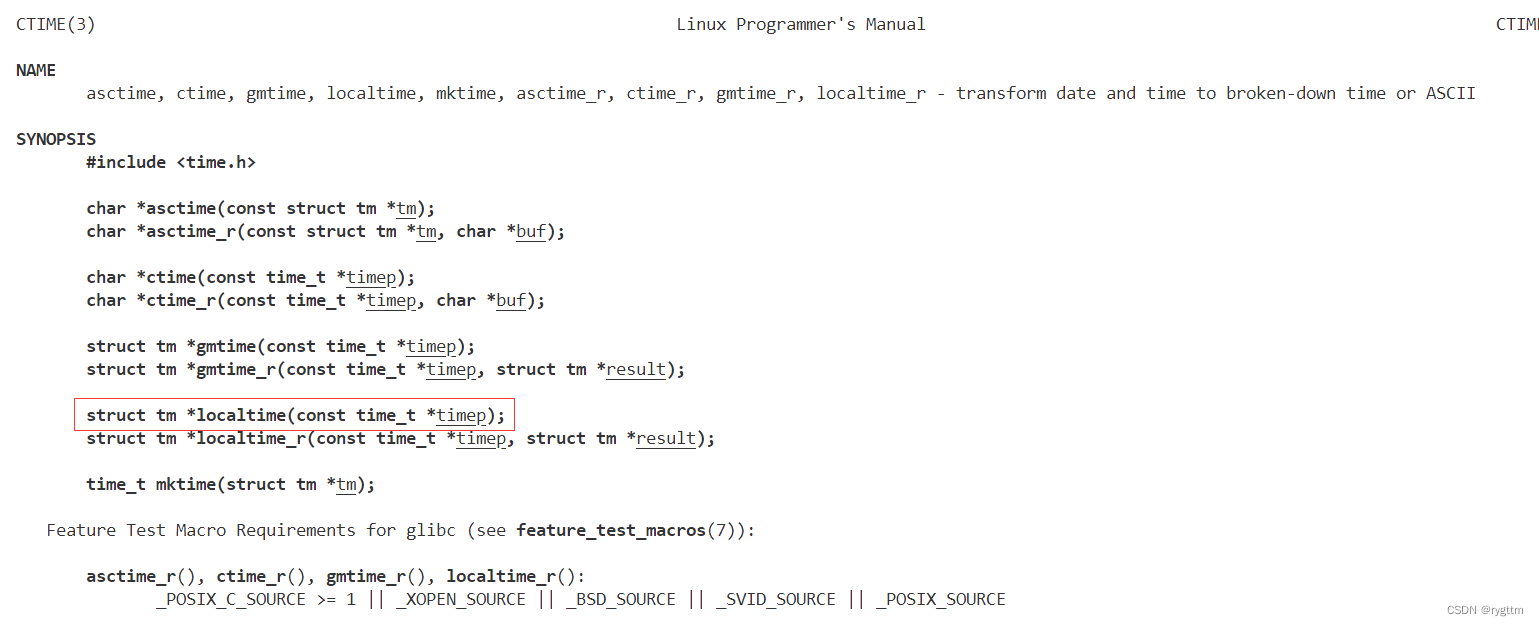
localtime函数用于将time_t类型的对象转换成一个结构体类型struct tm,在这个结构体内部包含了许多的时间字段信息,例如秒,分,时,天,月,年

4.
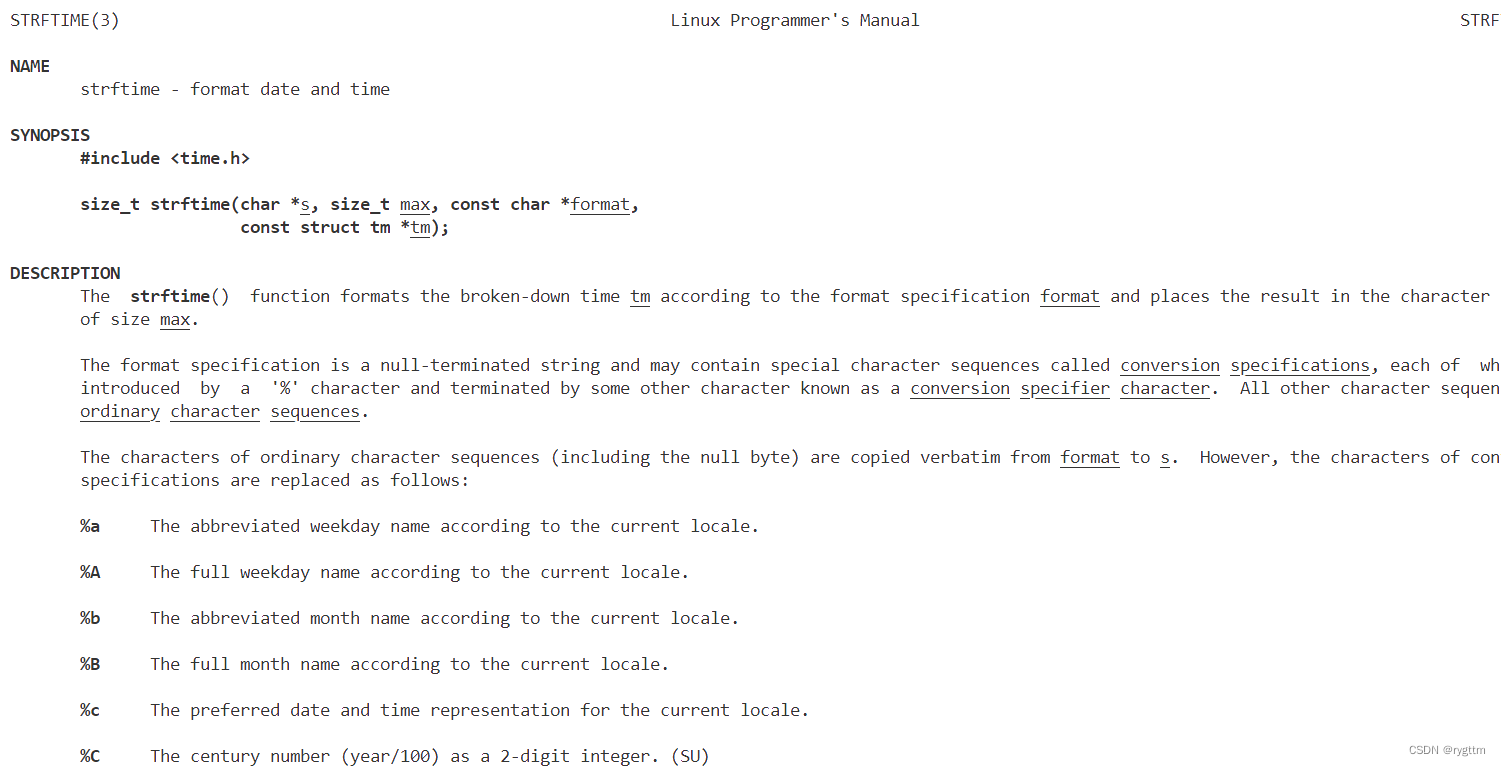
strftime函数用于将struct tm类型的对象指针进行格式化输出,将格式化后的内容放到s缓冲区里面。格式化的形式有很多,我们就使用%H,M,S就可以了,分别代表当前的时分秒。
5.
所以,通过上面三个函数,我们就可以将当前的时间信息输出到一个char buffer缓冲区里面,但日志信息光有时间还是不够的,还要有输出的内容,而C99恰好引入了新特性,允许宏中定义可变参数,也就是. . .(点点点)代表可变参数,所以一个宏函数的实现,只需要两个参数就可以了,一个是format,代表格式化的字符串,另一个是. . . 代表格式化的字符串中等待传递的参数。
最后在调用fprintf,将格式化后的字符串输出到显示器文件上,也就是打印到屏幕终端上,在fprintf的第二个参数中可以看到,我们好像写了三个字符串啊,以前我们使用printf的时候,好像只用到了一个字符串啊,这样符合语法吗?其实是没问题的,在ANSI C标准中规定,在可变参数中,如果两个常量字符串之间没有逗号隔开的话,则这几个常量字符串会自动连接。第一个字符串中的第一个参数,其实就是格式化输出到buffer里面的时间信息,包含时分秒,第二个参数是预定义出来的宏__FILE__表示日志输出所在的文件,第三个参数是__LINE__表示是文件中的第几行输出的内容,format是调用LOG时,调用者进行的可变参数的控制,对应传递的参数会传给. . . ,我们用__VA_ARGS__就可以接收外部调用传进来的可变参数。
为什么要加一个##呢?主要是因为调用的时候,又可能只是简单打印一串消息而已,不会传可变参数进来,那么此时__VA_ARGS__就是未定义的,调用fprintf就会出错,而##的作用就是让__VA_ARGS__和前面的__LINE__宏参数合并,当调用者不传可变参数的时候,LOG宏函数此时也不会出错,因为相当于没有__VA_ARGS__这个参数。

6.
但是光有上面的宏函数还差点意思,日志宏应该还要有日志等级的分类,例如normal debug error这样的等级,所以我们可以预定义出来一个默认的日志等级,表示只输出当前等级往上的所有等级的日志消息,只需要在原来的LOG里面多加一个level参数,然后在实现中多加一个if逻辑条件判断即可。
那每次调用LOG的时候我们都需要自己去传一个日志等级,这样用起来感觉还是不方便,所以我们在对LOG做一层封装,封装出三个不同日志等级的宏函数,分别为NLOG,DLOG,ELOG,这样使用起来就比较方便了。

2.2 mysql_util
1.
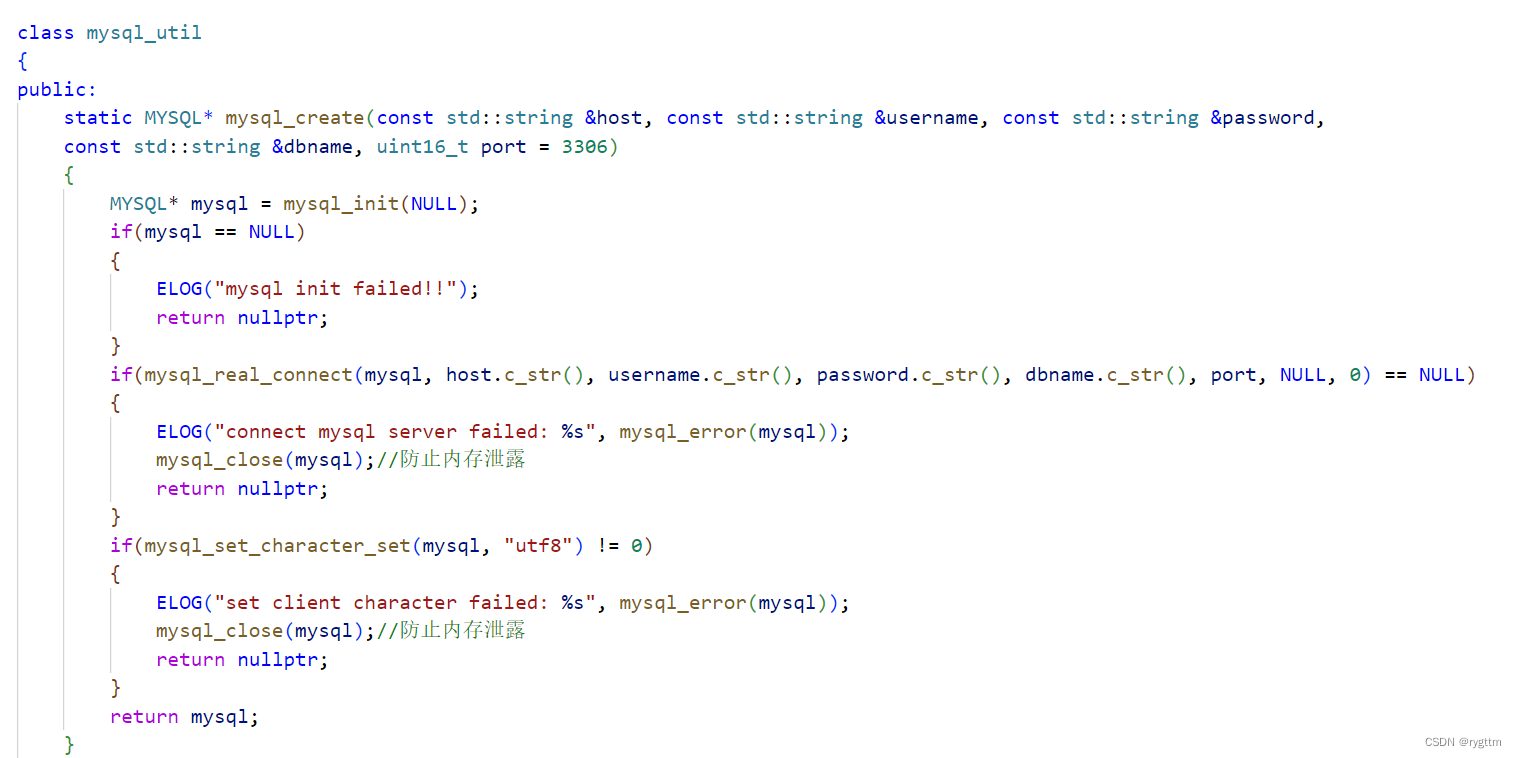
在mysql_util这个类里面,封装实现了静态方法mysql_create,用于创建并初始化mysql句柄,以及设置好客户端的字符集等工作。
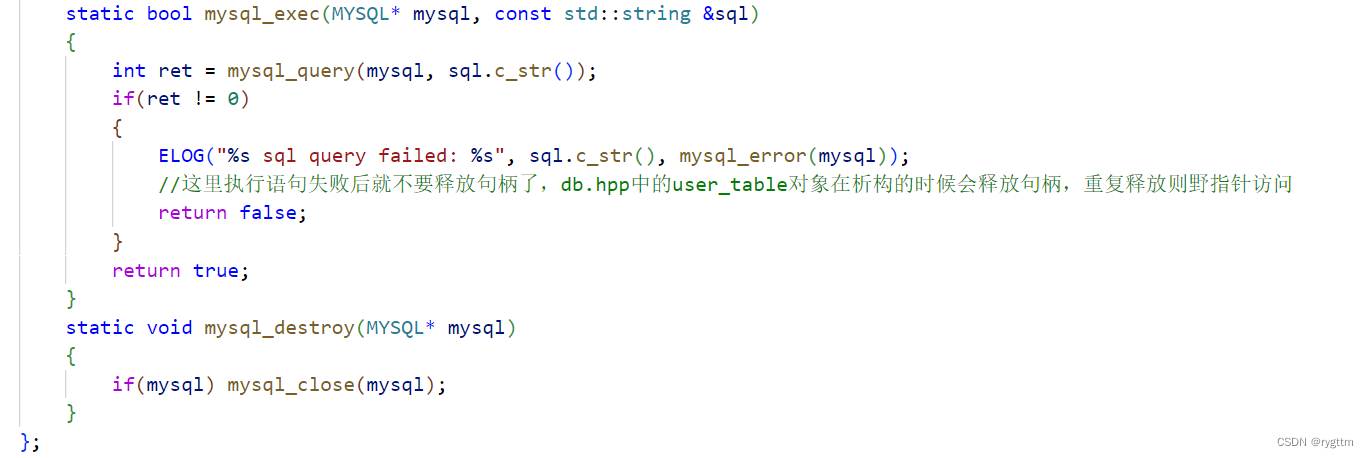
2.
mysql_exec用于执行mysql语句,但这个接口的封装实现只能执行插入,更新和删除语句,因为只有这三个语句的执行逻辑是一样的,他们执行成功后不用做任何额外的操作,但查询语句却需要执行额外的操作,所以封装实现时,我们只封装mysql_query这一个接口,如果调用者想要执行查询语句,则可以使用我们封装的接口,如果想要将查询的结果输出显示到自己的终端,则需要自己去实现保存结果集,遍历结果集,释放结果集等一系列操作。
mysql_destroy用于释放销毁mysql句柄。
2.3 json_util
1.
在json_util这里,封装实现序列化和反序列化的静态方法即可,在序列化接口里面,需要外部传入一个root对象和一个str对象,在内部我们会将root中的json格式的数据组织成为一个string对象,然后将这个对象赋值给str输出型参数,外部就可以拿到序列化后的字符串str了。
在内部实现中,我们不在使用普通的指针来管理StreamWriter对象,而是使用智能指针unique_ptr来管理,这样就不需要我们在手动释放内存了,当智能指针销毁时,就会自动释放动态申请的内存。
在反序列化这里,也是需要外部传入一个json格式的字符串str,然后内部将str做反序列化,将反序列化后的json格式的value对象赋值给输出型参数root中,外部就可以拿到反序列化后的value对象了。
与序列化相同的是,我们不在使用普通指针管理CharReader对象,也是采用智能指针unique_ptr来进行管理,道理相同。

2.4 string_util
1.
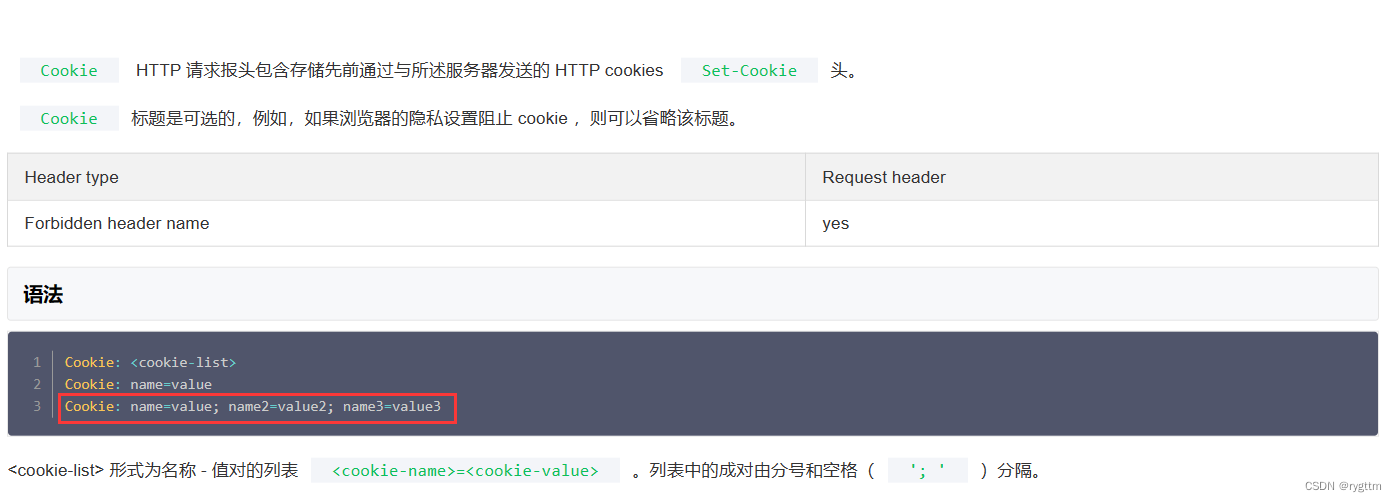
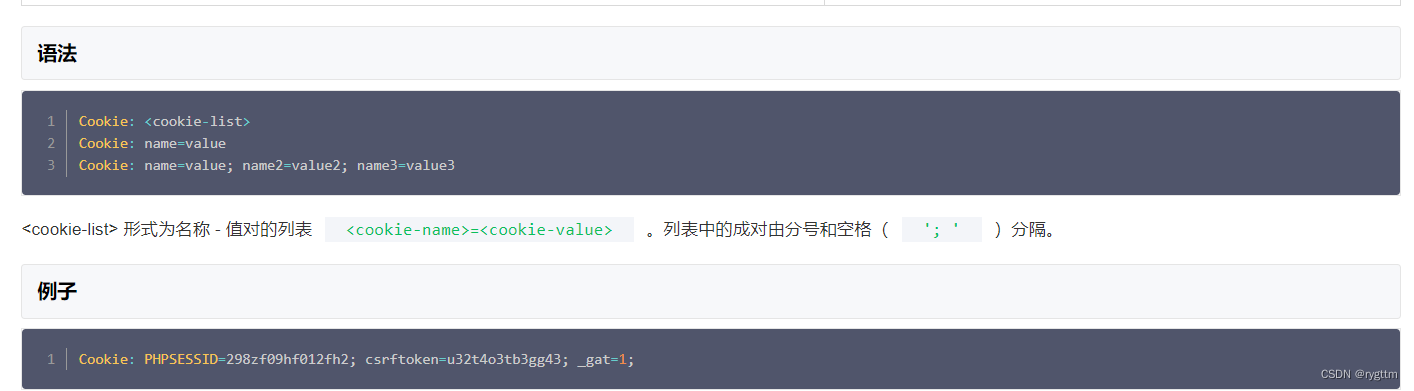
由于后面在封装实现服务器的时候,每次客户端的请求我们都需要做会话的验证,而会话的验证离不开http请求头部字段Cookie: ,我们需要获取到cookie中的ssid字段,所以要对请求头部中特点的字段作解析,拿到特定的值,所以在实用工具类这里在实现一个split函数,用于进行字符串的解析获取。
下面是http请求头部中Cookie字段的格式,内容是以name=value的形式呈现,多个值之间用分号+空格来区分开,所以如果想要拿到ssid的值,则必须进行字符串解析。
(cookie中的值是服务器让客户端设置什么,cookie里面就携带什么的,比如客户端和服务器建立http连接进行登录,登录成功后,服务器会为该用户建立一个session,这个session对应的唯一标识符ssid就是服务器返回的响应头部字段Set-Cookie中设置的,当客户端收到http响应后,后续客户端所有的请求字段中都会携带Cookie字段,无论是websocket请求还是http请求都会携带,所以服务器必须保证能够获取请求头部字段中的Cookie字段,那么就一定要有能够根据特定分隔符,解析字符串的能力)
2.
上面说的其实是有瑕疵的,比如我说后续客户端所有的请求字段中都会携带Cookie字段,无论是http还是websocket请求,其实对于websocket请求来说,他的头部字段中是压根没有Cookie字段的,因为http和websocket的报文格式是不一致的,怎么可能有Cookie字段,但为什么还能获取到呢?
其实是因为在第一次协议切换请求后,websocketpp库会将请求中携带的Cookie信息保存下来,将保存后的信息设置到connection这个类里面,我们调用connection类中的get_request_header来拿到Cookie字段的值时,依旧是可以拿到的,所以后续即使是websocket请求,服务端也能够通过get_request_header来拿到cookie信息,因为在第一次协议切换的http请求中,websocketpp库已经将cookie信息替我们保存起来了,供我们后续调用API来获得这个cookie信息。
3.
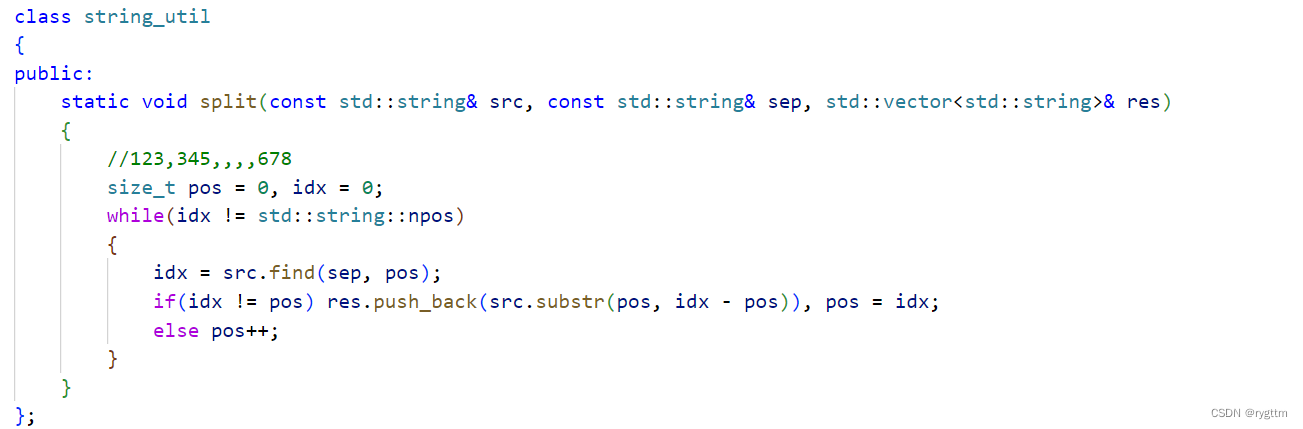
在split实现这里,需要传入的参数有三个,一个是需要解析的字符串src,一个是解析时的分隔符sep,一个是解析后的内容存放到输出型参数res字符串数组中。
解析的方式也很简单,我们定义两个变量pos和idx,idx表示下一个分隔符的位置,pos表示当前位置,搞一个while循环,只要idx的值没超过string::npos,那就一直向后查找,查找到分隔符后,判断分隔符的位置是否和pos的位置相同,如果相同,那就说明pos位置本身就是分隔符,那么pos位置就应该++向后挪动1位,下次从新的pos位置开始查找,如果不同,那就直接调用substr进行子串的截取,将截取后的子串放到res里面,然后直到整个字符串遍历完毕后,循环结束,res中保存的就是以sep为分隔符,将src进行截取,截取出来的子串内容了。
2.5 file_util
1.
由于后续项目实现时,客户端会频繁请求获取服务器上的web前端资源,所以服务器需要在http_callback部分实现能够将前端页面发送回客户端的功能,而这一功能的实现就少不了文件读取,服务器需要将文件内容读取到一个string中,然后服务器调用set_body这样的函数,将string内容设置为响应正文发送回客户端,此时客户端就会显示出来一个前端网页了。
所以文件读取的功能我们也要在使用工具类模块中实现一下,未来在处理前端请求web资源的业务时,可以直接调用read接口将linux机器上实现的前端html页面能够返回给浏览器客户端。
2.
read接口需要外部传入两个参数,一个是输入型参数文件名,一个是输出型参数body,读取文件后文件的内容会被放到body里面,外部服务器在获取到文件内容后,就会将文件内容返回给浏览器客户端。C++操作文件的方式其实就是定义一个ifstream或ofstream对象,读取文件是in,写入文件是out,我们这里就定义一个ifstream的对象,以二进制和读取的方式来打开文件。
我们需要获取一下文件的大小,这样以便于提前resize开辟好body的空间大小,然后将读取出来的文件内容放到body里面。获取文件的大小也是有技巧可言的,常见的一种方式就是先调用seekg,将文件读取位置移动到文件末尾处,然后调用tellg,拿到当前的位置大小,拿到的这个位置大小,其实正好就是该文件的大小,获取完文件大小后,不要再将文件读取位置调整到开始。
有了文件大小之后,我们直接调用body.resize(filesize)进行body的扩容,然后调用ifs.read(),将文件的内容以二进制的形式存储到body里面,最后记得将文件关闭即可,其实关闭的这一步,我们不搞也行,因为ifs对象销毁的时候,会自动关闭文件,(这话可不是我说的,是C++ primer说的),如果你比较保守的话,不放心的话,也可以自己去手动调用close来关闭文件。

3. 数据管理模块
3.1 数据管理的设计
1.
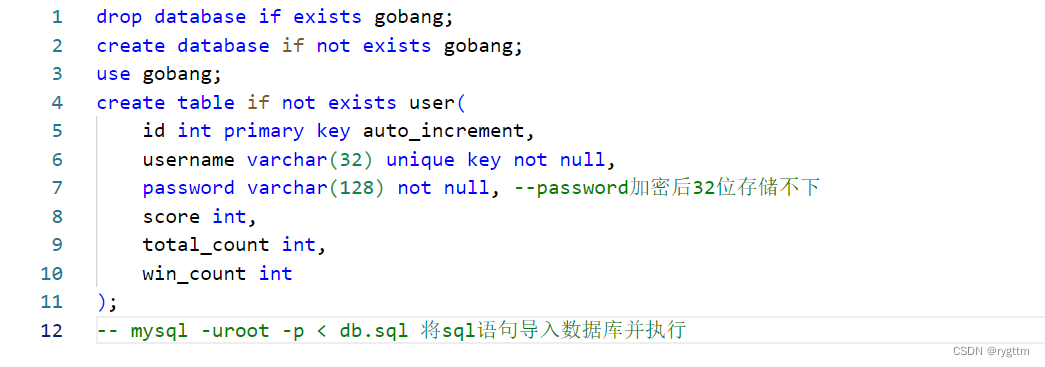
数据管理这里的设计分为两个部分,一个是数据库中user表结构的设计,一个是项目代码中user_table类的设计。用户信息表这里,共创建6个字段,分别是用户的唯一标识,也就是user_id,还有username,password,用户的天梯分数,后续我们会根据天梯分数的不同来判断用户的游戏等级,例如1000 ~ 2000是青铜,2000 ~ 3000是白银,3000 ~ 4000是黄金,用户在匹配对战时,只能匹配到和自己游戏等级相同的玩家,还包括total_count总战斗场次,win_count胜利场次。
当用户进入到游戏大厅页面时,我们要展示出用户的名称,天梯分数,总战斗场次,胜利场次等详细信息。
2.
我们需要自己设计一个user_table类,这个类的主要功能是完成浏览器在向服务器发起的诸多请求中,涉及到访问数据库的操作,我们将这些操作接口全部封装起来,方便后面服务器模块进行调用。
类成员变量是比较简单的,因为我们要访问数据库嘛,那肯定需要一个MySQL句柄,除此之外,其实我们还需要一把互斥锁,因为websocketpp这个库是多线程实现的,我们项目中的各个接口都有可能会在多线程的情况下被调用,所以只要涉及到共享资源的访问,或者是其他的线程安全问题,我们都需要一把锁来进行保护。
有人可能会说,人家mysql提供的各个接口本身就是线程安全的啊!你搞个互斥锁有什么意义呢?其实不然!当我们调用mysql_query执行sql语句时,mysql_query本身确实是线程安全的,如果执行的是增删改这样的sql语句也不会出现线程安全问题,但如果是查询语句,此时就出现线程安全的问题了。
在查询语句执行后,我们是需要调用其他的API来进行结果集的保存,遍历,释放等操作,在执行mysql_store_result之前,上一条在数据库中执行的语句必须是select才行,但在多线程的情况下,你能保证执行完select语句后,下一条语句执行的一定是mysql_store_result吗?我们的接口是可能会被多个线程调用的啊,有可能此时某个用户在注册,那执行的就是插入语句,但也有可能其他用户在登录,那执行的就是查询语句,所以你能保证select执行之后,下一个执行的API是mysql_store_result吗?当然是无法保证的!
每个API各自确确实实是一个原子操作,是线程安全的,但我们现在的需求是希望在查询语句结束后,下一个执行的MySQL API一定要是mysql_store_result,因为mysql句柄是只有一份的,mysql句柄是共享资源,多个线程都会访问mysql句柄,我们希望mysql_query执行select语句 + mysql_store_result这两个操作合起来是一个原子操作,如何做到呢?那就只能通过加锁来实现,所以user_table类的成员变量除mysql句柄外还需要一把互斥锁。
(你试想一下,如果不加锁,A线程拿着句柄在执行select语句,执行完select语句后,B线程此时想要执行insert语句,B线程抢过来这个句柄进行insert语句的执行,因为mysql_query是线程安全的,所以在执行期间是不会有其他线程来打扰他的,A线程执行select语句时,也是同样如此,现在B线程执行完了,A线程又拿着这个句柄执行mysql_store_result了,此时mysqld服务直接报错,MySQL数据库懵逼了,你上一条语句执行的是insert语句啊,你现在要让我执行mysql_store_result,我给你保存个毛啊?你上条语句执行的又不是select,此时mysqld服务直接就报错了。
因为mysql句柄是共享资源,所以A线程拿到进入API执行流程中,那此刻其他线程不能执行任何的API,因为mysql API是线程安全的,如果是B线程拿到,那也是同样如此,如果是C,D,E等线程也是这样的,你们随便拿不要紧,重要的是查询语句和mysql_store_result合在一起得是原子操作啊!否则这就是有问题的啊!)
3.
需要我们实现的接口有构造,析构,涉及到用户动态请求功能的处理接口有,insert,它可以帮助我们向数据库中新增用户的注册信息,login负责对登录的用户进行验证,看看数据库中是否存在该用户,如果存在,则比对用户输入的密码是否正确,如果正确则说明登录成功,同时login会以输出型参数的方式来将数据库中获取到的用户详细信息返回给user变量里面,为什么要有这一步呢?主要是用户登录成功请求发起,发起的请求中会携带用户的username和password这样的信息,这些信息是要作为输入型参数来告知login的,同时当服务器处理完登录请求后,外部其实是要为用户创建session的,而创建session需要uid来进行创建,所以这里的user就作为了输入输出型参数来使用,给外部返回一个用户的详细信息,外部想知道哪个信息字段值,只要使用json提供的[ ]重载即可使用。除此之外,还可以实现一些其他的辅助接口,例如通过用户名来获取用户的详细信息,通过用户id来获取用户的详细信息,因为后面在用户大厅展示用户信息时,我们是需要通过user_table类提供的API来获取到用户信息并展示的。此外在实现两个接口,id对应的某个用户胜利时,要在数据库中更新用户的信息,比如total_count++,win_count++,score+=30,当然也少不了用户失败时的信息更新,所以再加一个loseAPI。

3.2 user_table类的实现
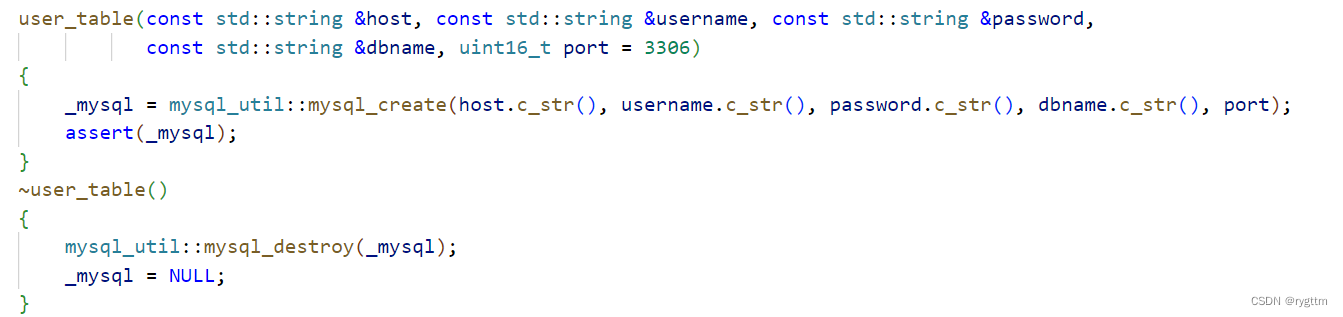
1.
构造函数其实就是调用我们上面mysql_util里面实现的多个静态方法,调用mysql_create进行句柄的创建,析构函数中进行句柄的销毁。
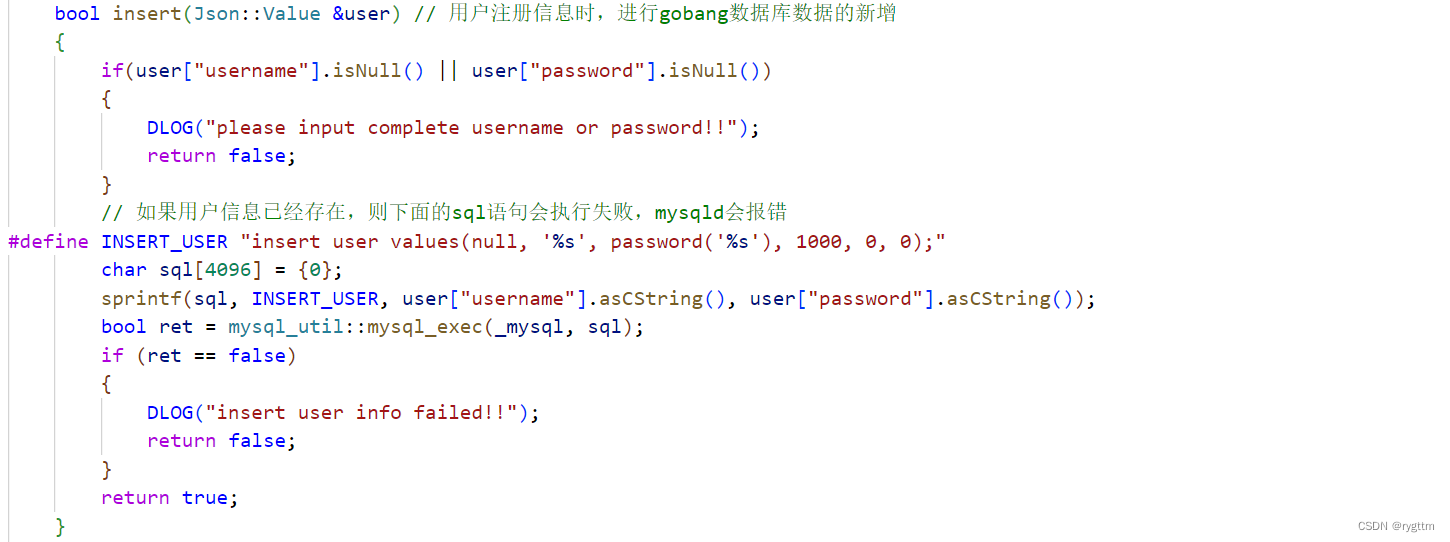
2.
在注册信息这里,我们首先要判断输入型参数user中用户信息的完整性,只有有一个不完整,则注册信息失败,如果全部完整,我们则编写sql语句,进行用户信息的注册,sql语句需要sprintf进行格式组织,将输入型参数中的username和password字段拿到并格式化到sql语句中,最后调用工具类中的mysql_exec执行语句即可。
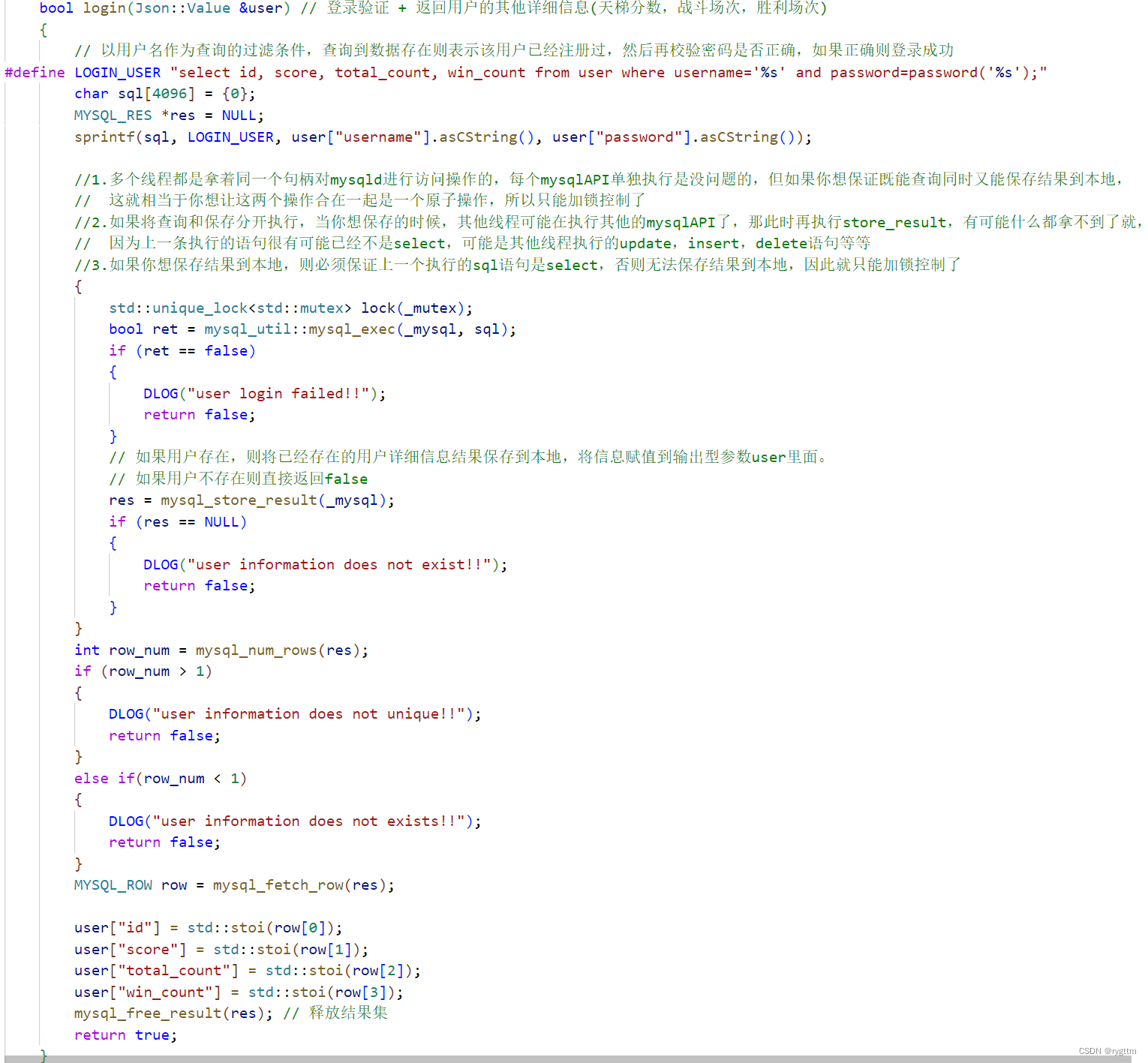
3.
在登录验证这里,其实要做的就是将数据库中对应的信息取出来同时进行密码的校验,所以我们直接根据输入型参数user中的用户名和密码字段,组织出具有筛选条件的查询语句,在进行查询时,如果能够在数据库中找到对应的用户信息,则我们需要将结果保存到本地,所以查询和保存结果这两步,必须是一个原子操作,那我们就进行RAII风格的加锁控制。
在获取到查询结果集的行数之后,我们还需要进行校验,如果rowNum大于1,则说明用户信息不唯一,如果小于1,则说明用户信息不存在,只有等于1的时候,才是符合预期的,其实这里的校验也算是稳一手的操作,99%的概率这里是不可能出错的。然后通过调用mysql_fetch_row遍历结果集,将数据库中的信息拿出来,把每个字段填充到user这个输入输出型参数当中,最后释放一下结果集就行。
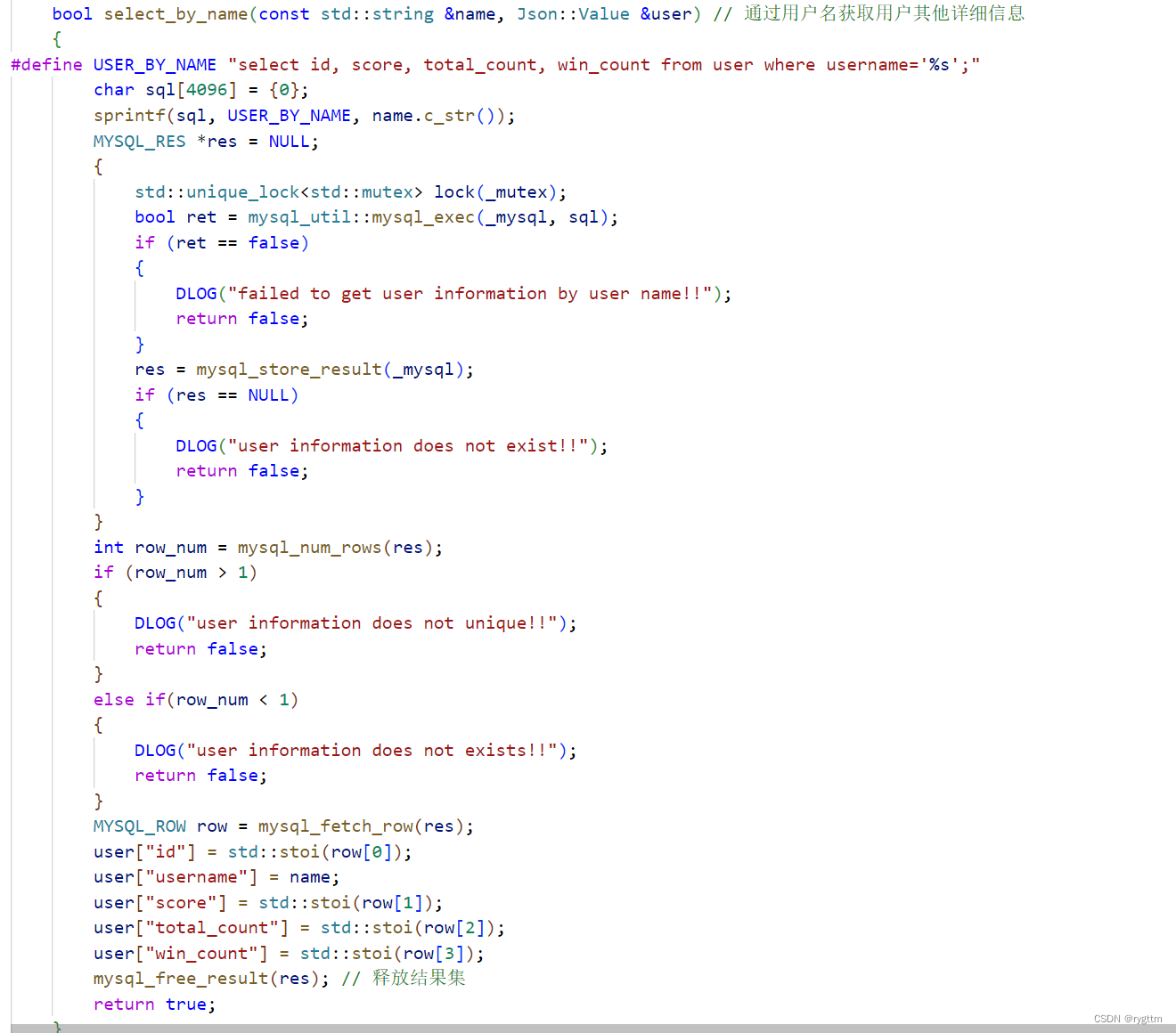
4.
通过用户名来获取用户详细信息的逻辑和上面一模一样,唯一不同的就是sql语句的筛选条件改动了而已,这里也就不再赘述了。
道理相同,仅仅是改变了一下select的筛选条件,这里也不在赘述
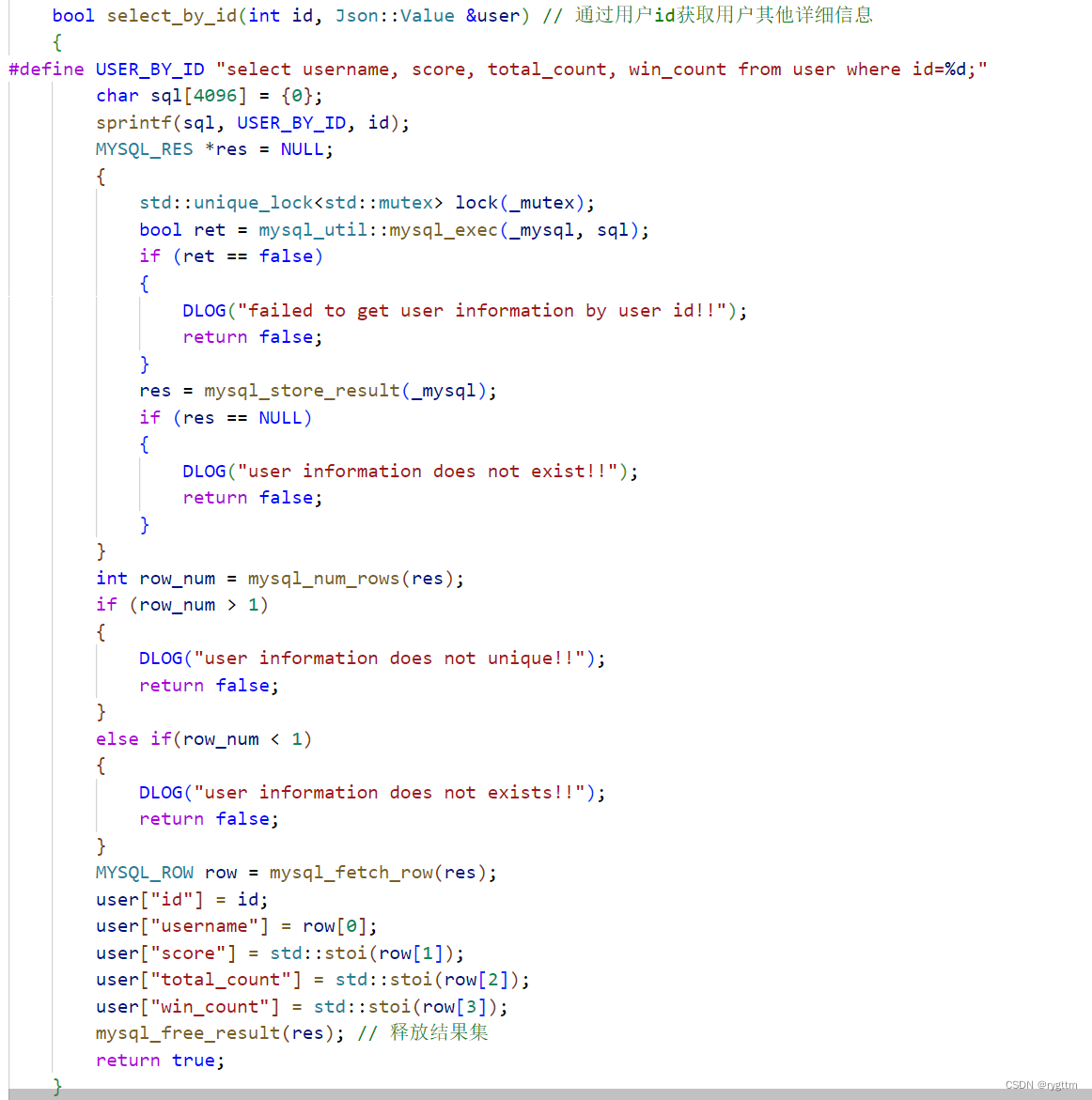
5.
win和lose在实现时,其实就是进行数据库信息的更新,编写update语句即可,然后调用工具类中的mysql_exec执行就完成函数的编写了。

4. 在线用户管理模块
4.1 在线用户管理的设计
1.
由于后期我们会通过用户id,来获取到用户对应的websocket连接,只有获取到连接之后,服务器才能通过连接,将自己对于业务的处理结果发送给客户端,比如说,在后面的游戏房间实现中,双方下棋时,如果有一方胜利,那么此时就应该将谁胜利的消息广播给房间中的双方玩家,然后前端页面会进行检测,看看服务器发送回来的消息中,胜利者是不是我自己,如果是我自己,那就应该在页面上显示,我胜利了,如果不是我,那就应该显示我失败了,所以必须实现一个能够通过用户id来获取用户对应的websocket连接的API,这个API就是在线用户管理模块,也就是online_manager类中实现的。
在该类里面,不仅要有获取游戏大厅用户长连接的API,还应该有获取游戏房间用户长连接的API,因为我们知道房间和大厅是两个不同的页面,使用的长连接也是不同的,所以获取这两个长连接的API也是不同的,两者是解耦的。
2.
除了上面获取连接的API之外,在线用户管理还具有判断一个用户此时是否在线的功能,因为用户有可能玩的玩的不想玩了,直接关闭前端页面,那么后续服务器在进行相关业务处理时,就应该进行用户是否在线的判断,如果不在线,那么服务器就不提供相应的服务,如果在线,则继续进行业务处理。
3.
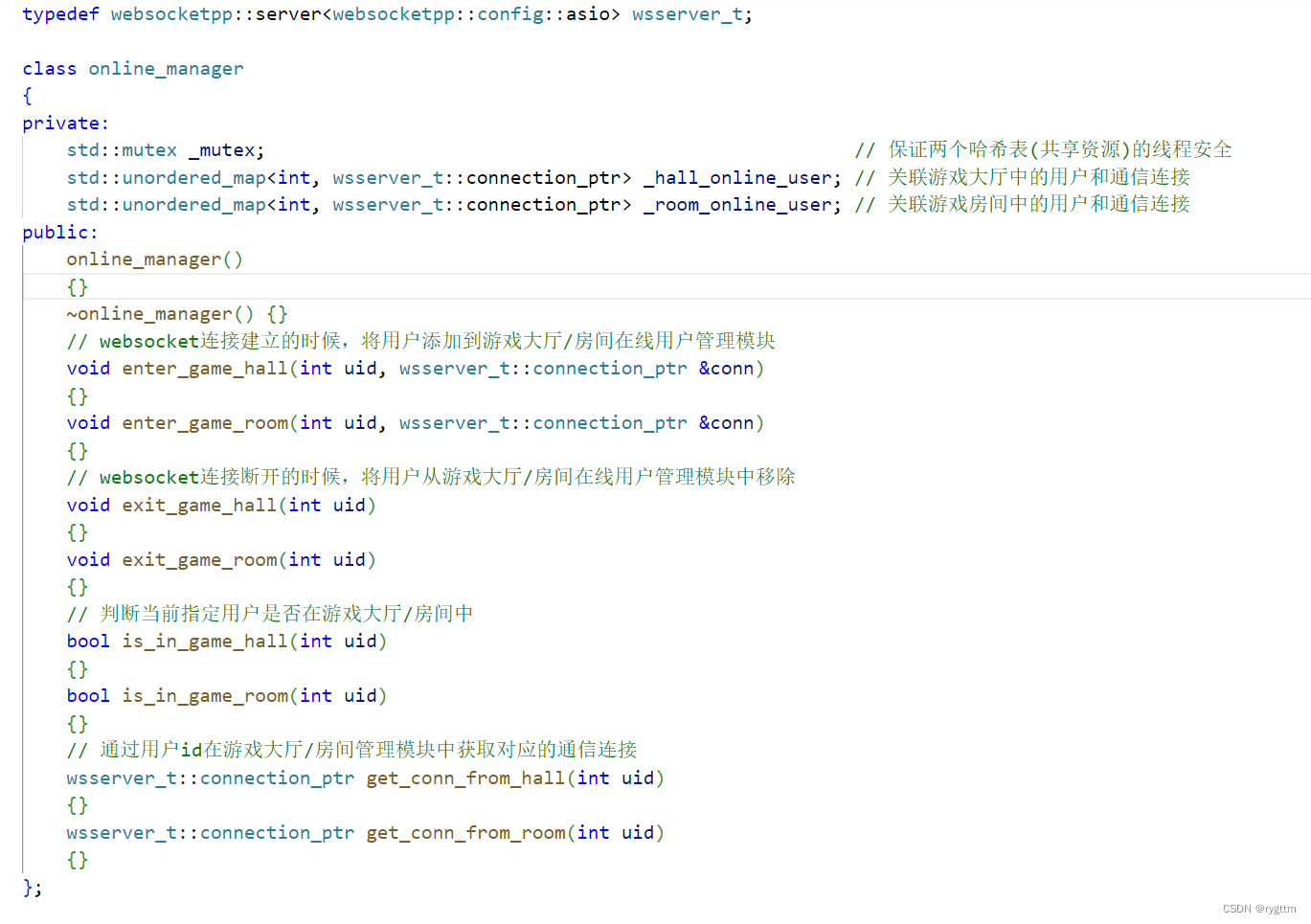
为了进行上述功能的实现,online_manager需要两个哈希表来分别构建用户id和用户对应的websocket通信连接之间的映射关系,由于哈希表是共享资源,我们要对哈希表进行插入和删除,所以也需要一把互斥锁来保证共享资源访问的安全性。
需要实现的API有,当websocket连接建立成功时,将用户加入到游戏大厅/游戏房间在线用户管理中,当websocket连接断开时,将用户从游戏大厅/游戏房间在线用户管理中移除,判断当前用户是否还在游戏大厅/游戏房间中,通过uid来获取用户在游戏大厅/游戏房间中的长连接。
(由于connection_ptr这个类型是websocketpp库里面的server类中定义的,所以我们提前typedef了一下这个server类,这样使用起来会比较方便)
4.2 online_manager类的实现
1.
当服务器与客户端建立好websocket长连接之后,那就需要将用户添加到在线用户管理模块中,而所谓的加入游戏大厅或房间的在线用户管理,其实就是将uid和对应的conn连接构造成键值对插入到_hall_online_user或_room_online_user哈希表中,需要多说一嘴的是,插入键值对到哈希表中,是需要加锁控制的,因为哈希表是共享资源,在多线程同时访问下,如果不加锁控制,可能会出现线程安全问题。

2.
当服务器和客户端websocket长连接断开的时候,就需要从在线用户管理中将用户进行移除,而所谓的移除,其实就是从哈希表中找到特定的键值对,然后将键值对删除就可以了。同样的,由于涉及到对共享资源的访问,我们也需要进行加锁控制。

3.
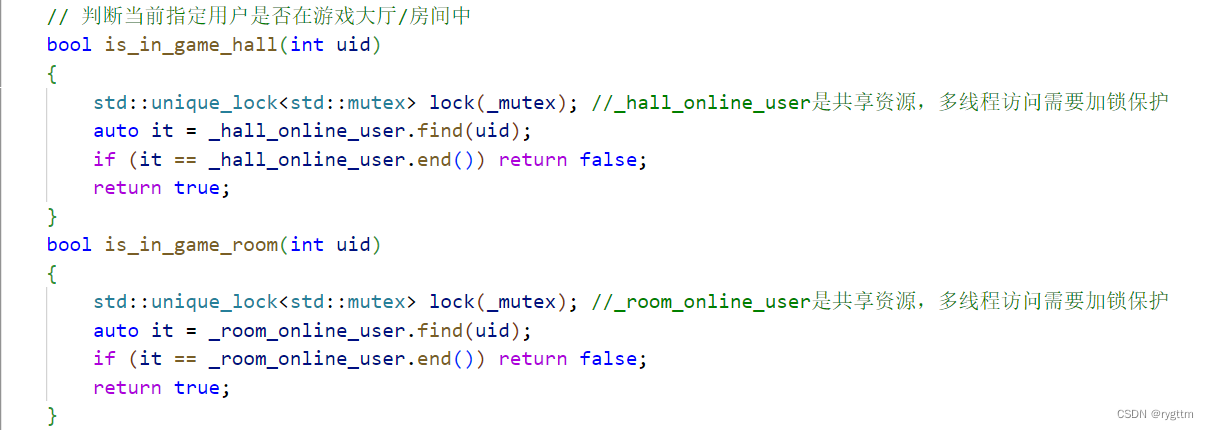
判断用户是否在在线用户管理中,其实就是判断uid对应的迭代器是否存在,我们直接调用find查找uid对应的迭代器,如果迭代器不为end(),那就说明当前用户确实在在线用户管理中。同样的,访问共享资源,需要进行加锁控制。
4.
只要用户在在线用户管理中,那我们就可以通过迭代器的方式,找到uid对应的connection_ptr,然后进行返回即可,如果找不到,那我们就返回一个空的connection_ptr对象。

5. session管理模块
5.1 HTTP的cookie&session机制
1.
在web开发里面,http是一种无状态短连接的通信协议,也就是说,当客户端和服务器建立了一次http连接完成通信后,http连接就会断开,下次客户端想要访问服务器的其他web资源时,服务器是不知道你这个客户端是谁的,服务器不知道你是谁,也不知道你现在登没登录,那服务器此时给客户端提供服务就是不合理的,因为http是无状态的啊,他不会保存任何客户端的信息,但用户有这样的需求啊,比如你现在在B站的网页端,你提交用户名和密码进行登录后,跳转到B站的主页面,你的登录请求是http的,如果B站的服务器不报存你的任何信息,那当你跳转到B站的主页面的时候,B站的服务器不认识你啊,为啥要给你提供展示视频等服务呢?还有一个例子,假设你现在已经登录好了,正访问B站的视频呢,然后你不小心把网页关闭了,当你重新打开时,你希望B站的服务器认识你吗?你当然希望啊,如果他不认识你,你打开B站页面后,又得重新输入用户名和密码进行登录验证,你觉得这样烦不烦啊?每次新打开页面,我都需要输入用户名和密码,烦都烦死了。
所以,即使http是无状态的,但用户需要他是有状态的,那么服务器就会为每个用户浏览器,都在后端中创建一个session会话对象(默认状态下,一个浏览器独占后端服务器的一个session,不会出现你在一个浏览器中打开了多个标签页访问web资源,那么服务器就会为该网页对应创建多个session的这种情况),用来保存用户的状态信息(比如用户的uid,用户是登录状态还是未登录状态),让服务器能够具有识别当前用户是谁的能力!
2.
那服务器如何通过session校验当前客户端的状态呢?其实除了后端session的创建之外,还需要一个cookie信息,当客户端访问服务器进行第一次登录后,服务器此时就会为客户端创建一个session,然后服务器会给客户端返回一个http响应,响应头部字段中会有一个Set-Cookie字段,后面的值表示的就是服务器让客户端以后发送请求时,在他自己的http请求头部都设置一个Cookie字段,里面的值就是服务器的Set-Cookie设置的值
http响应的Set-Cookie头部字段
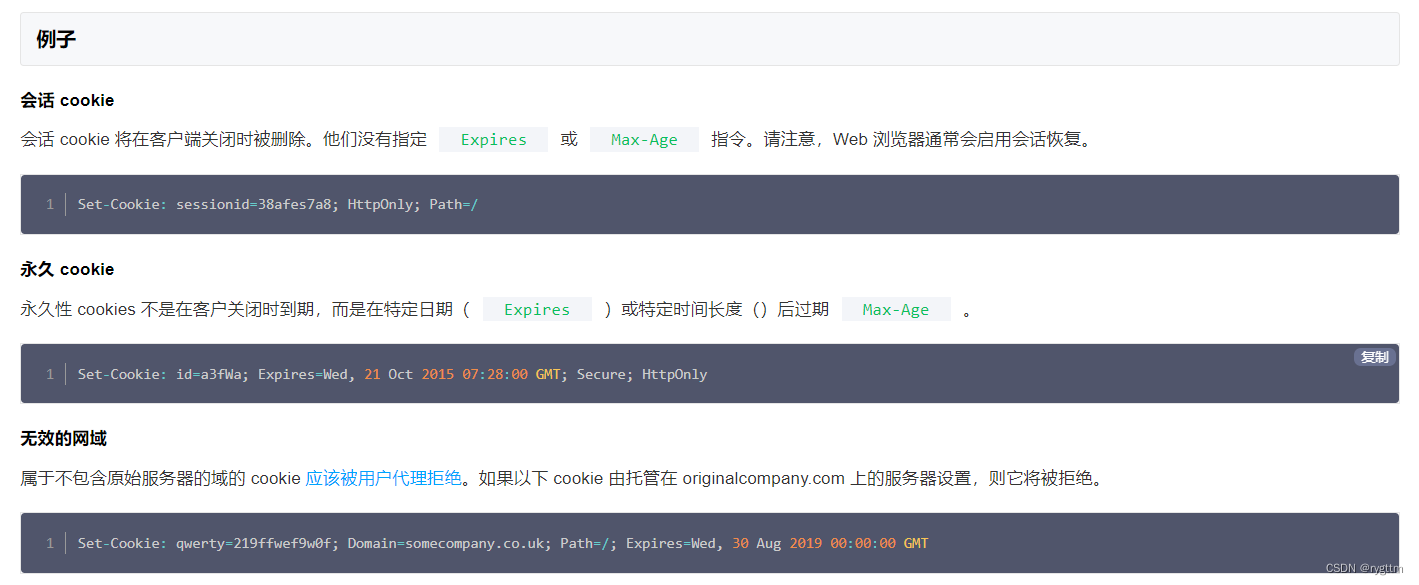
http请求的Cookie头部字段
3.
但Set-Cookie的值应该设置成什么呢?如果向下面的图中所示,设置的消息内容如果就直接是用户的状态信息的话,那么浏览器本地就需要保存一份包含用户状态信息的cookie文件,在后面的所有请求中,都去携带上用户的登录状态信息,这样确实可以保证服务器能够识别客户端,但安全性太低,因为cookie文件可能会被不法者盗取和篡改,不法者可能会冒充客户端向服务器发起请求,同时这也会对用户产生无法预料的影响,因为用户的信息可以被任意篡改和盗取,通过cookie文件就可以拿到。
所以下面这样的方式是不够合理和安全的。

4.
此时就有大佬提出了解决方案,在cookie的基础上引入session,形成cookie&session机制。即服务器来保存用户的详细状态信息,而不是客户端来保存,服务器为每一个已经登录的用户创建一个唯一对应的session,每一个会话都有自己的会话标识符,也就是会话id,服务器返回的Set-Cookie字段中不再是用户的详细信息了,而是会话id,客户端收到响应后,会将ssid保存在自己本地的cookie文件中,后续每次请求服务器的头部字段都会有Cookie信息,服务器只需要拿着请求中的ssid值在本地的session管理模块中找一下,看看是否存在对应的session,如果存在,则看一下用户此时的状态是什么,如果是合法的状态,那么服务器就会返回一个登录成功的响应信息,客户端页面就会发生跳转。
(此时不法者就无法盗取到用户的状态信息了,因为用户发送的cookie信息中只有一个ssid啊,你要ssid有啥用啊,用户信息泄露的问题就大大改善了,但如果不法者冒充用户向服务器发起请求,这个问题是cookie&session解决不了的,此时需要配合其他策略来进行解决,例如白名单,防火墙,异地登陆警告等等策略。况且这个问题也不应该由cookie和session机制来解决,这是你网络安全需要解决的问题,我就是个识别客户端的机制,让我解决这种问题干嘛啊。)

5.2 websocketpp库中定时器的使用
1.
了解了cookie和session机制之后,我们先不急着实现服务器的session模块,我们需要首先熟悉一下定时器的使用,这是很关键的,因为session的销毁其实就是一个定时任务。如果你登陆过后,不进行任何的操作,session会一直永久保存在服务器吗?当然不会,如果永久保存不销毁的话,随着登录的用户过多,那总有一天服务器扛不住可能就宕机了,所以session一定是有创建有销毁的,当你关闭页面之后,session难道也要一直存在吗?也是不会的,session可能在你关闭页面后,会被保存一段时间,在一段时间之后,session就会定时销毁了。
需要注意的是,在某些安全要求高的使用场景下,如果30s内无操作,则session会自动被销毁,迫使用户重新进行登录,还有一种情况是,为了安全性,可能用户切换一个页面,那其实就是切换一个websocket长连接,则服务器就会将原来的session立马销毁,重新创建一个新的session,这样一般都是在安全性要求比较高的场景下进行使用,只要换连接那就跟着换一个session
但本项目中没有采取这样高级别的安全方式,我们的项目在切换页面后,使用的session还是原来的session,并没有进行更换。
2.
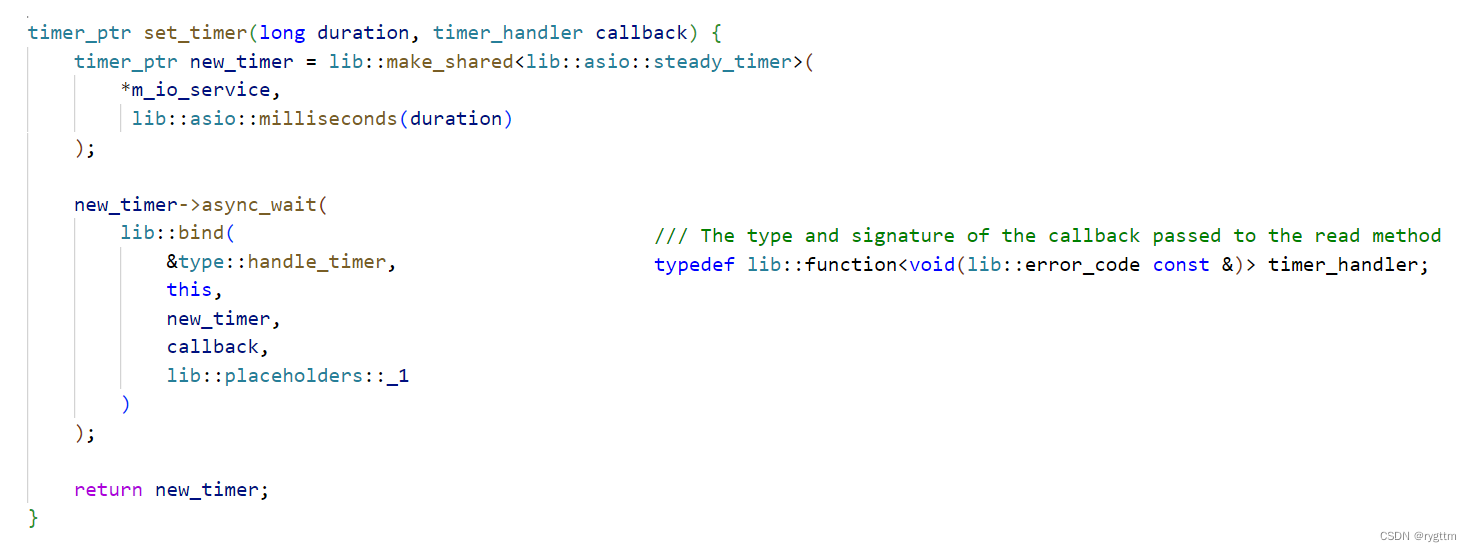
websocketpp库中的endpoint类里面实现了一个set_timer接口,用于设置定时任务,该接口的第一个参数duration表示多长ms时间之后执行该定时任务,第二个参数是一个包装器类型,包装的可调用对象的返回值是void,参数是一个库里面定义的类型。
不过我们压根不用理睬他是个啥包装器类型,直接传一个bind绑死参数的可调用对象就行,让set_timer在规定时间之后,直接执行我们自己传入的可调用对象。
3.
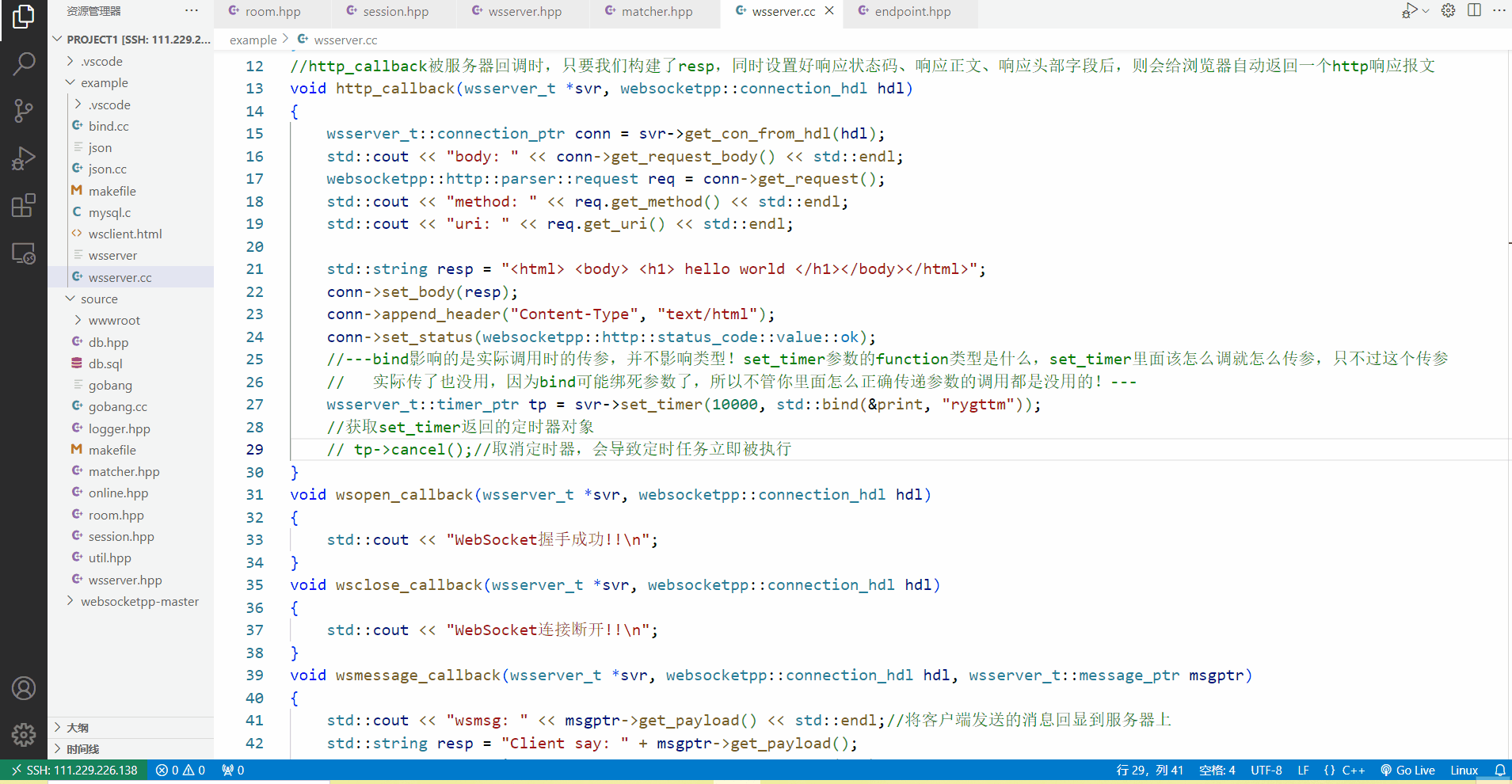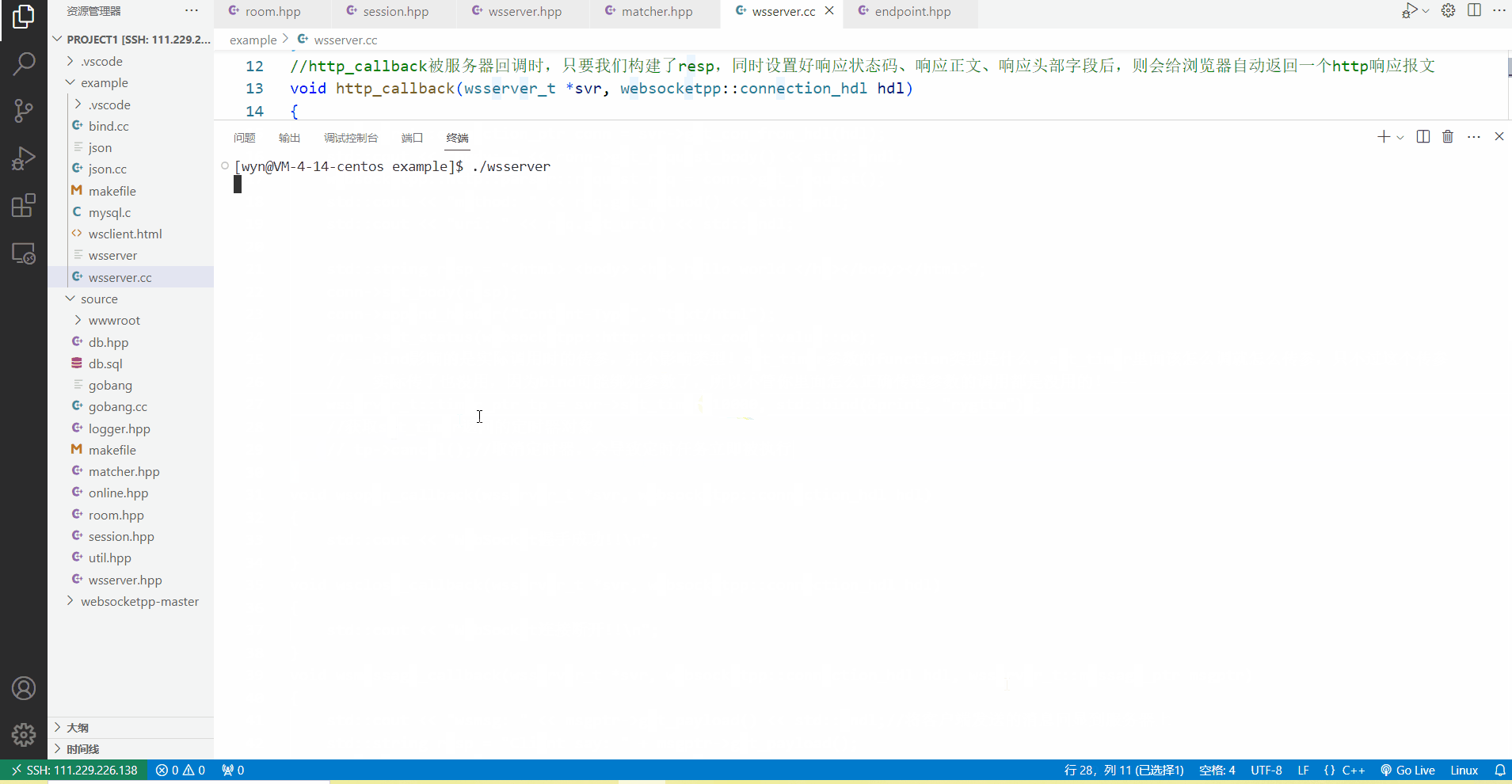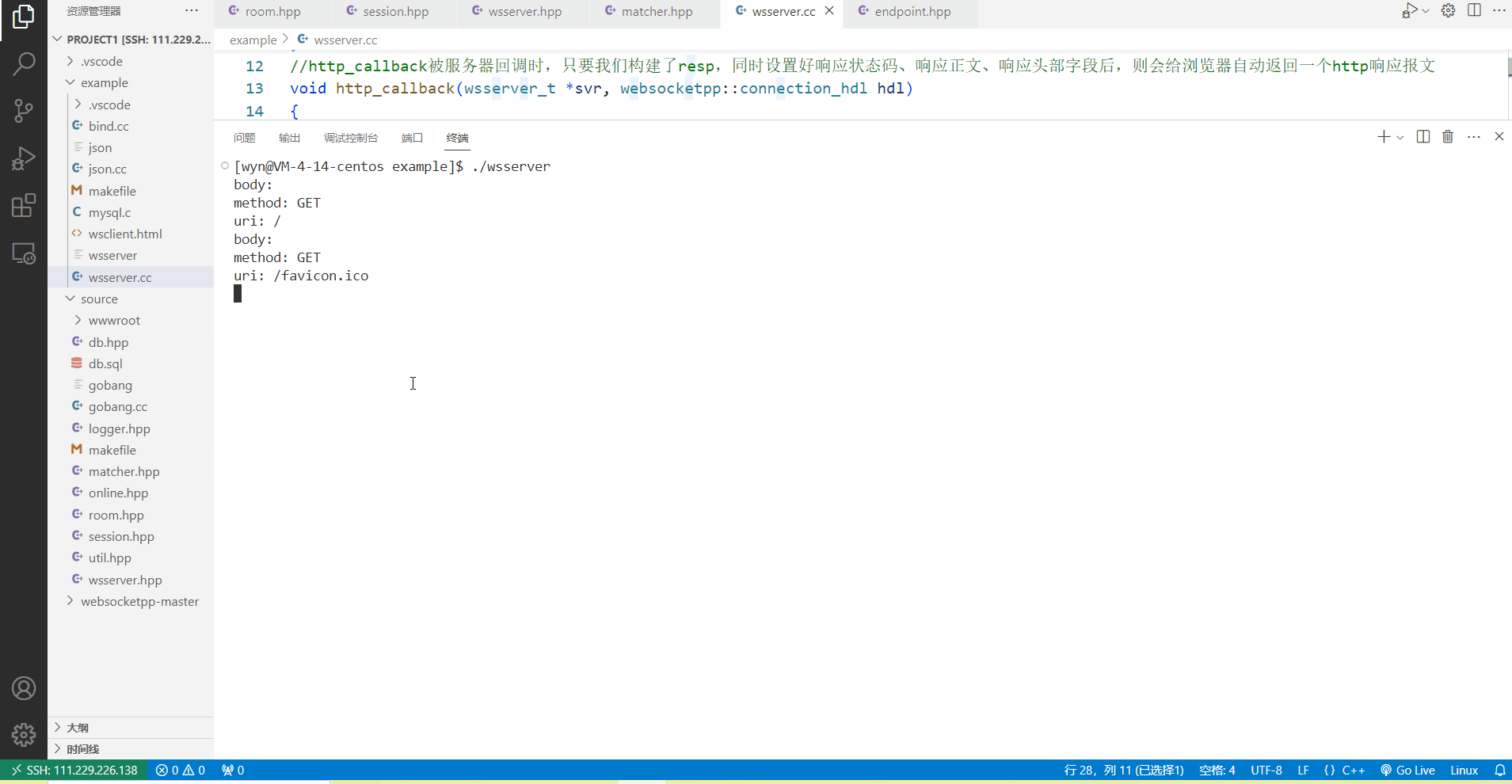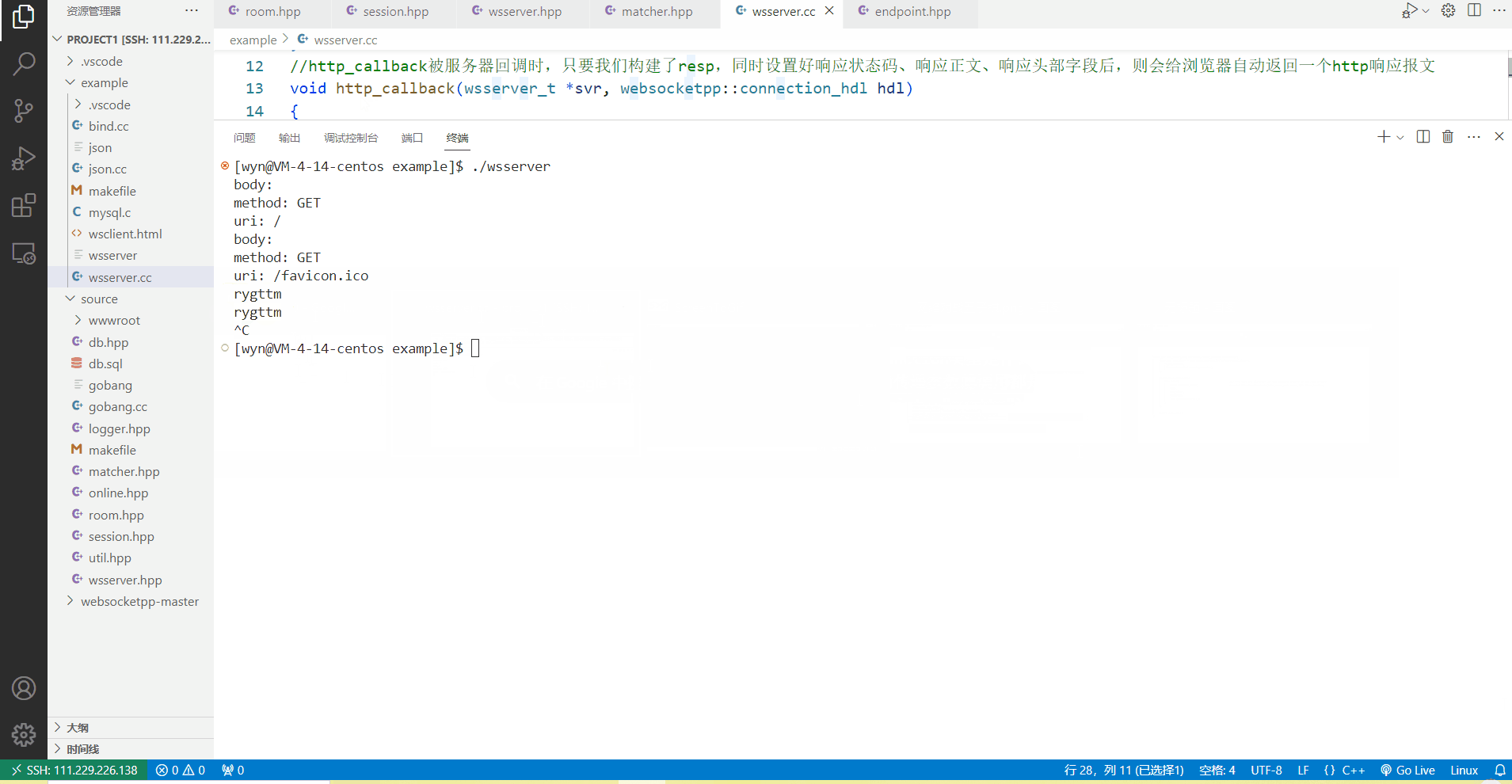
下面的代码希望大家不要感到陌生,其实这段代码就是最开始我们搭建http/websocket服务器时的代码,只不过在http_callback里面最后两行,添加了一个定时任务,也就是调用print函数,上面我讲过bind的用法,bind生成的可调用对象不影响类型,只影响实际调用时候的传参,所以我们直接绑死print的参数,那么在duration毫秒之后,set_timer就会自动调用print函数,我们无需管set_timer的第二个参数timer_handler是什么类型的包装器,直接传个绑死的可调用对象过去就行,那么在实际调用timer_handler类型的callback时,传任何参数都是没有用的,他只会调用print(“rygttm”)这个函数。

4.
通过timer_ptr类型的tp指针接收set_timer的返回值后,如果我们想取消定时器,重新设置一波定时时间,比如我不想5000毫秒后执行任务了,而是想在3000毫秒后执行,那我们就需要将原先的定时任务取消,然后再重新调用set_timer设置新的定时任务。
而取消就需要借助timer_ptr类里面的cancel接口来实现,但这个取消接口又特别的坑,它会导致定时任务被立即的执行,下面在实现session管理模块时,我们还要对定时器被取消导致定时任务立即执行,这样的行为做特殊处理。
当没有取消定时任务时,可以看到客户端发起一次http请求后,服务器终端上在10s过后才会打印出rygttm,这表明在服务器的http_callback中,我们确实设置好了一个10s后执行的定时任务。
当我们取消定时任务之后,客户端发起一次http请求,服务器调用http_callback都会立马在终端上打印出来rygttm,由此可见,取消定时任务后,定时任务会立马被执行一次。
5.3 session的设计与实现
1.
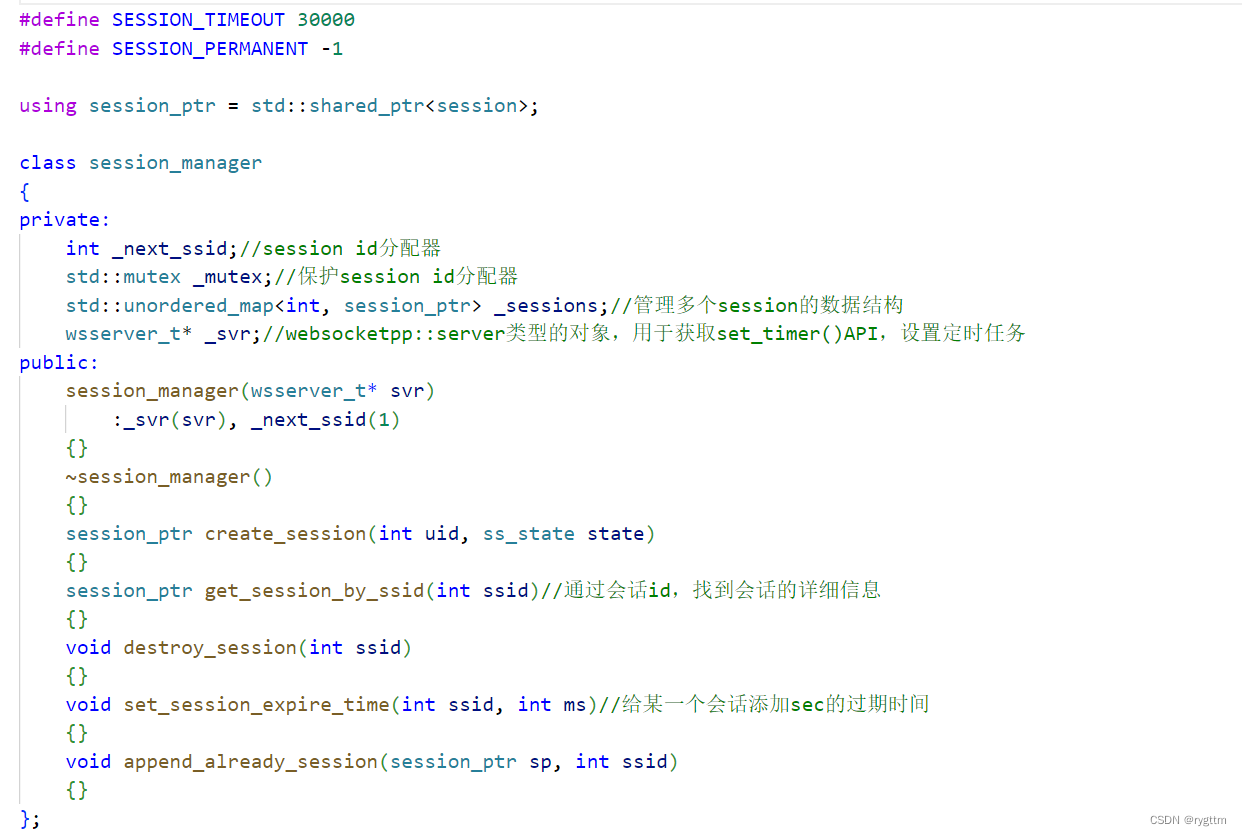
一个会话应该包含的信息有,这个会话本身的标识符,也就是会话id,还应该有用户id,因为每一个session都是和一个用户所关联的,所以session中还要包含uid,表示这个session是哪个用户的,还可以有一个用户状态字段,也就是表示用户是unlogin还是login,这个字段其实有和没有都行,因为我们只会为登陆成功的用户创建会话,所以只有某个会话被创建,那么这个会话对应的用户状态一定是已登录的。每个会话都会有自己的定时任务,例如多少s后销毁,或者会话永久存在等等,那么会话一定是需要和定时器对象所关联的,所以成员变量我们在加一个timer_ptr的定时器对象。
成员函数这里,其实实现的都是辅助接口,比如外部想获取session中指定的信息时,那么session就可以提供一些接口将指定信息进行返回,传给外部调用方,这些辅助接口的实现都很简单,其实就是设置一些成员变量的值啦,或者返回成员变量什么的。
2.
set_user用于设置会话的成员变量_uid的值,get_uid用于获取会话相对应的用户id,is_login用于判断当前会话对应的用户是否处于登录状态,set_state用于设置会话对应用户的状态,set_timer用于设置会话对应的定时器对象,这个接口其实就是由session_manager来调用的,get_timer用于获取会话对应的定时器对象,ssid用于返回会话id,构造函数用于设置会话的ssid。
其实上面这些函数都是成对儿出现的,每一对儿都和成员变量所对应,说白了就是设置一下成员变量的值,然后获取一下成员变量的值。

3.
由于session这个类比较简单,所以设计和实现我放到一块了,实现也是比较简单的,大家看一眼就明白了。

5.4 session管理器的设计
1.
对于未来可能存在的多个session对象进行管理,那我们肯定需要一个数据结构来将多个session对象组织起来,为了更快的查找到特定的session对象,我们采用了哈希表这种数据结构。
同时每个session都应该被分配一个session id,所以session_manager的成员变量中还要有一个_next_ssid分配器,用于给每个session分配唯一的ssid,这个分配器听起来特别高大上,但其实就是一个自增长的int类型值。
与之前的online_manager和user_table类都相同的是,这里涉及到对共享资源_next_ssid和_sessions的访问,所以我们这里还需要加一把互斥锁。
session管理器还需要给每个session添加定时任务,所以我们还需要一个wsserver类对象,用于获取server类中的set_timer接口,以此来设置会话的定时任务。
2.
可能会有人有疑问,为什么管理会话的智能指针是shared_ptr呢?unique_ptr不行吗?
主要是因为session管理器管理的不只有一个session,他需要通过哈希表将多个session组织起来,然后进行管理。哈希表构建会话id和会话智能指针之间的映射关系,那么向_sessions这个哈希表中插入键值对时,当然就会发生智能指针的拷贝了,哈希表有堆上的智能指针,函数栈帧里面有我们定义出来的session_ptr,因为unique_ptr是禁止拷贝的,所以就只能用shared_ptr来对session对象进行管理。
当session对象的引用计数变为0时,session就会自动被销毁了。

3.
session_manager的构造函数需要外部传入一个wsserver类型的对象,create_session负责创建一个会话,需要外部传入会话对应用户的uid,和用户的状态,get_session_by_ssid用于通过ssid来获取到会话管理指针,通过这个智能指针就可以拿到会话中所有的详细信息,也就是session类里面的所有详细信息。destroy_session用于销毁session,其实所谓的销毁,就是将哈希表中的键值对移除掉即可,释放键值对在堆上对应的内存空间,而键值对里面不就有session_ptr吗?该智能指针销毁后,会以RAII的风格释放session所占用的内存,因为实际管理session的智能指针只有堆上这个还存在,其他的函数栈帧内开辟的临时的智能指针,在离开函数后都会被销毁掉了,所以最后一定只剩一个session_ptr在堆上存放着。
set_session_expire_time就是设置会话的过期时间,即在指定时间段后,执行destroy_session,完成session对象的释放,这个接口实现起来是比较复杂的,append_already_session其实就是配合set_session_expire_time来实现会话的定时销毁的,这个接口也是整个session_manager中最繁琐的接口。
我们还预定义了两个宏出来,分别代表session此刻是永久存在、session的过期销毁时间,过期销毁时间的初始值设置为了30000ms。
5.5 session_manager类的实现
1.
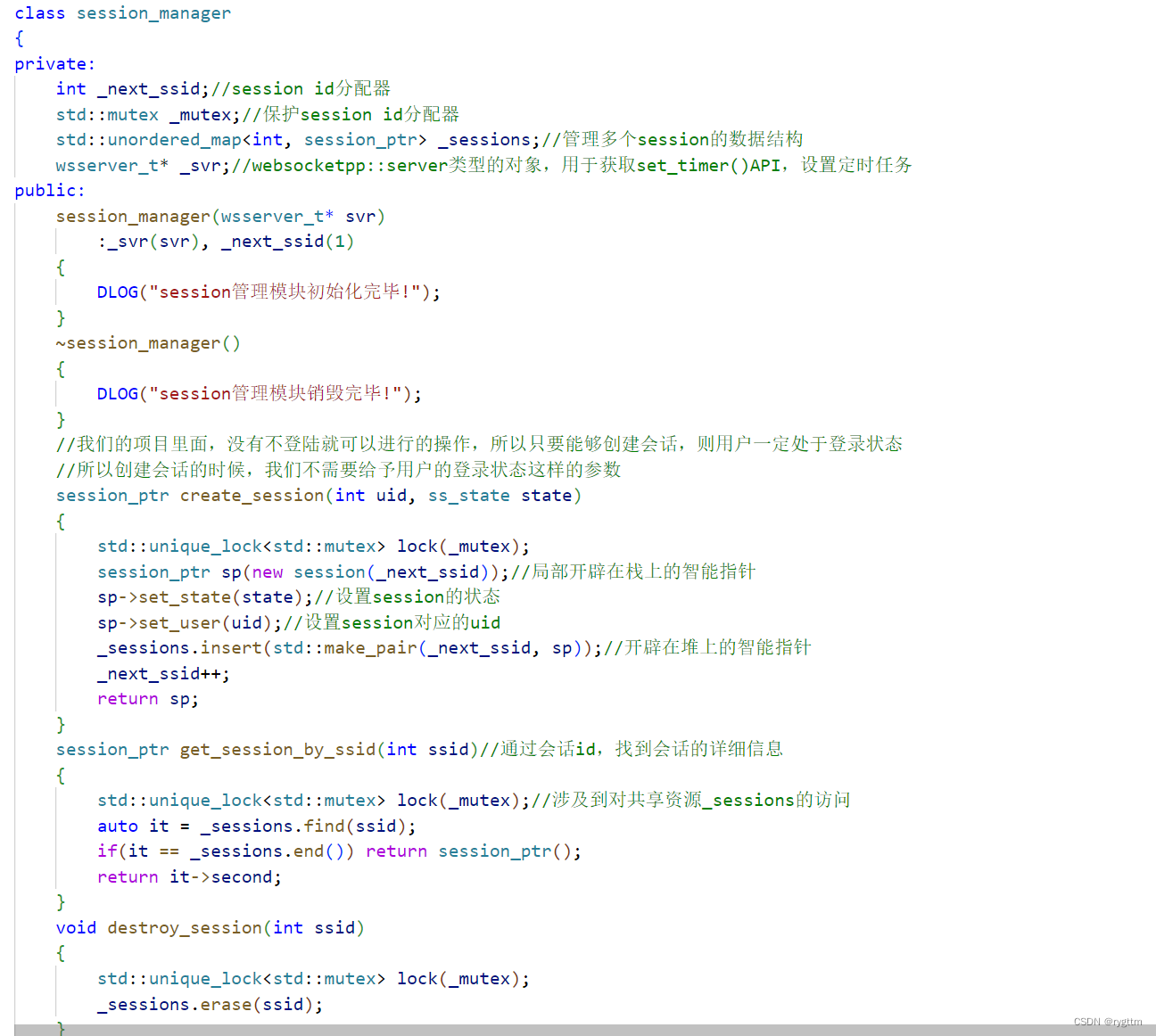
在构造函数中,我们自己初始化_next_ssid的值,这个会话id分配器的值从1开始进行分配。
创建session时,我们上来就直接加锁控制,因为下面的代码会涉及到对共享资源的访问。我们将session会话对象开辟在堆上,用sp指针来进行管理,然后调用session类的接口进行会话相关信息的初始化,将会话状态,uid等字段填充好,最后将sp和_next_ssid构成键值对插入到哈希表中,别忘了将_next_ssid进行自增1,最后返回sp即可。
get_session_by_ssid也比较简单,通过调用哈希表的find接口,即可找到ssid对应的键值对是什么,如果找不到则返回一个空的智能指针对象,如果找到,则返回堆上的智能指针即可。
destroy_session的实现也很简单,直接调用哈希表的erase接口进行键值对的移除即可。
2.
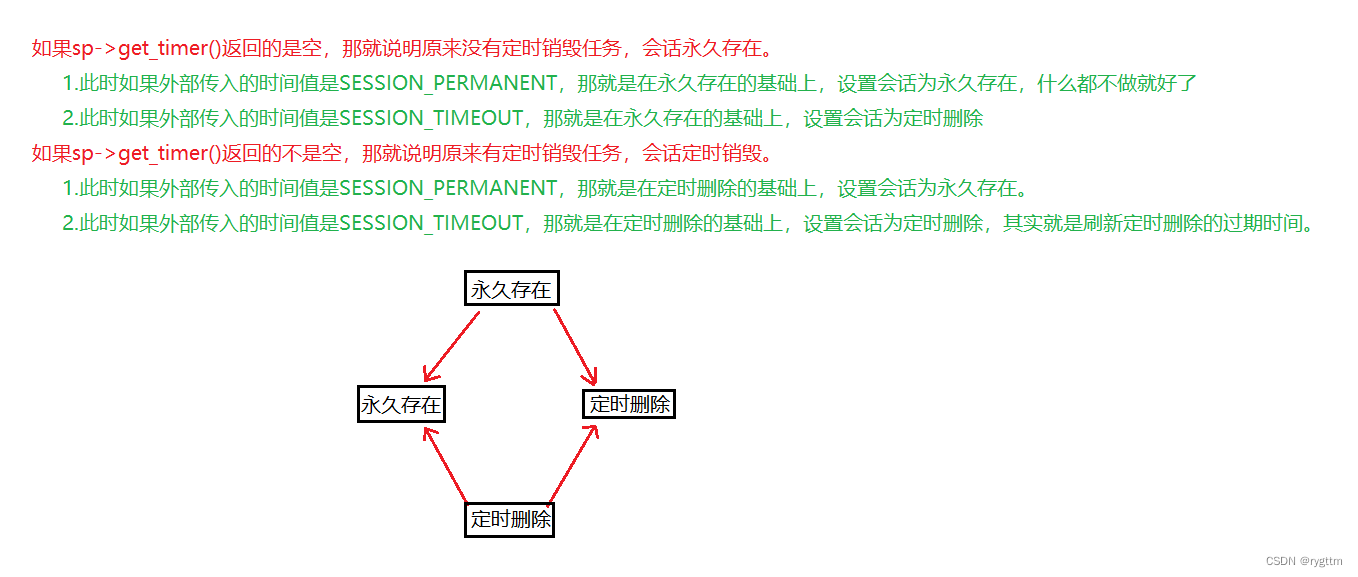
设置会话的过期时间,其实分为四种情况,我们需要判断会话原来有没有定时删除的任务,有和没有就会细分为两种情况,在每种情况下面又都会细分两个子情况,也就是看外部给set_session_expire_time传入的时间参数是permanent永久,还是timeout。
所以总体的情况就会分为四种,对每一种情况都要有不同的处理。
有人可能会有疑问,咋能有这么多种状态呢?你是不存心搞我啊?其实不然!
例如,当用户在登陆成功后,此时服务器会为用户创建一个定时销毁的会话,也就是说,如果在用户登录成功后,用户迟迟不点击一个提示框(前端alert显示的登录框),那么在30s之后,这个会话就会被销毁掉,这也是为了安全起见,如果用户点击了那个提示框,页面从登录跳转到游戏大厅,那么此时会话就应该从定时销毁变为永久存在,因为连接此时会切换为websocket连接,后续服务器提供所有的业务处理之前,都要在websocket连接的基础上,判断会话是否存在,如果定时销毁的话,服务器都找不到会话了,后续的业务处理的服务都提供不了了,当游戏大厅页面被关闭时,我们又需要从永久存在变为定时销毁,还有一种情况是,用户已经登录成功了,结果不小心把登录页面给关闭掉了,用户那就重新输入用户名和密码,重新进行登录,但此时用户对应的session已经存在了啊,所以再次重新进行登录其实就是意味着刷新session定时销毁的时间,从定时销毁再到定时销毁。
(其实在用户登录成功后,完全不需要再重新进行登录,只不过存在用户反复登录这样的可能性,所以我们需要刷新定时销毁的时间,但事实上,只要用户登录了一次,会话创建成功后,如果用户不小心关闭了游戏大厅页面或登录页面,也是没有关系的,用户可以直接再次请求游戏大厅页面,只要重新请求这个过程的时间不超出定时销毁的时间,那么是可以成功跳转到游戏大厅页面的,因为会话在第一次登录创建成功后,还没有被销毁。)
3.
第一个if else分支语句中,我们什么都不做就好,因为会话被创建出来,你没有向他添加任何定时任务,那他默认就是永久存在的。
第二个if else分支语句中,也很简单,我们只需要通过调用_svr里面的set_timer接口,设置SESSION_TIMEOUT时间之后执行销毁session的任务函数即可,也就是调用destroy_session函数,这里使用bind时,也是采用绑死参数的方式来进行,直接绑死参数this和ssid,则在SESSION_TIMEOUT时间之后,会话就会自动被删除。值得注意的是我们需要接收set_timer的返回值,也就是定时器对象,然后把这个定时器对象设置到会话的成员变量里面,表示这个会话现在已经是有定时销毁的任务了的。
第三个if else分支语句中,需要从定时删除设置为永久存在,这里实现的时候,就比较麻烦了,因为我们需要先取消原来会话的定时删除任务,然后将会话搞成永久存在。
但是这里就有一个问题,取消原来的定时删除任务会导致任务被立即执行啊,那也就是说一旦cancel之后,会话就会被删除了啊,那我们怎么搞出来一个永久存在的会话呢?其实很简单,我们再往_sessions这个哈希表里面添加一个键值对不就好了吗?在函数的最开始部分,我们保存过当前会话的会话句柄session_ptr sp啊,这是一个临时对象,那现在我们重新构建sp和ssid的映射关系,搞成一个键值对,然后将键值对插入到_sessions里面不就行了吗?
话说的一点问题都没有,但是吧!这里还有一个bug,那就是cancel的任务确实会被执行,但他不是被立马执行的,他是要等websocketpp库里面统一挨个执行定时任务队列里面的定时任务时,才会被执行的!
所以有可能在我们添加新的键值对之后,cancle导致的定时任务destroy_session才会被执行,那么此时就会导致我们刚刚立马插入的键值对就被删除掉了,那此时会话就没有了,这就是一种错误!所以一定不能立马添加键值对!那怎么添加呢?通过设置定时任务来添加!
也就是调用set_timer,在0ms之后执行append_already_session,这个定时任务的执行,也不是立马被执行的,你可以理解为websocketpp库里面有一个定时任务的队列,set_timer的作用就是向这个队列立马添加定时执行的函数元素,在等到真正执行定时任务的时候,websocketpp会按照队列的先后顺序依次调用并执行这些定时任务,所以在设置append_already_session为定时任务后,那么该函数在被执行时,他的前一个定时任务元素,也就是cancle造成的destroy_session一定会先被执行,那么此时的逻辑才是正确的!
(需要多说一嘴的是,在unordered_map中,如果我们插入具有相同的key的键值对时,哈希表并不会报错,而是会将新的键值对覆盖掉原来旧的键值对!)
第四个if else分支语句中,需要从定时删除设置为定时删除,实现的方式就是在第三个分支语句的基础上,多增加了一次的定时删除任务,先把原来的取消了,然后添加一个永久的会话,然后再给这个会话添加定时删除任务,最后别忘记把tmp这个定时器对象设置到session这个类的成员变量里面,通过调用会话句柄sp指向的set_timer接口来实现(一定要区分开两个set_timer接口,我们自己实现的set_timer和websocketpp库里面的set_timer重名了,但参数和返回值都是不一样的,大家一定不要搞混了)。

4.
session类里面还需要一个接口,通过uid来判断用户的会话是否已经存在了,如果存在,那就返回会话的句柄,如果不存在,那就返回一个空句柄。
(实现这个接口的原因,主要是服务器模块处理登录功能的时候,需要判断用户是否处于二次登录状态,如果是二次登录状态,并且第一次会话没有过期,那么是不需要重新为用户创建会话的,所以我们需要有一个接口来实现通过uid判断会话管理模块中会话是否存在这样的功能。不过这样的方式不太推荐,因为遍历的效率太低,正确的方式还是当用户反复登录时,每次登录服务器都为用户重新创建一个新的定时销毁的session。)
(这个接口是我自己额外加进去的,大家看个乐子就行,原生项目里面是没有这个接口的,我这样的想法也不太合适,刷新定时销毁的过期时间不应该在用户反复登录这里体现,况且这样的操作也不合理,而且还得遍历哈希表,所以最好还是不要提供这个接口)
5.
下面我会为大家演示不同情况下会话的创建和销毁过程,为了让实验的进度变得快些,我将SESSION_TIMEOUT设置为15000ms,也就是15s后会话定时删除。
登录成功,创建15s后定时销毁的会话,我们15s无操作,跳转到游戏大厅后,游戏大厅页面会向服务器发起websocket长连接请求,服务器收到请求的第一件事情就是进行会话验证,如果会话不存在,则跳转回登录页面,进行重新登录,并以消息框的方式报错,登录过期请重新登录。
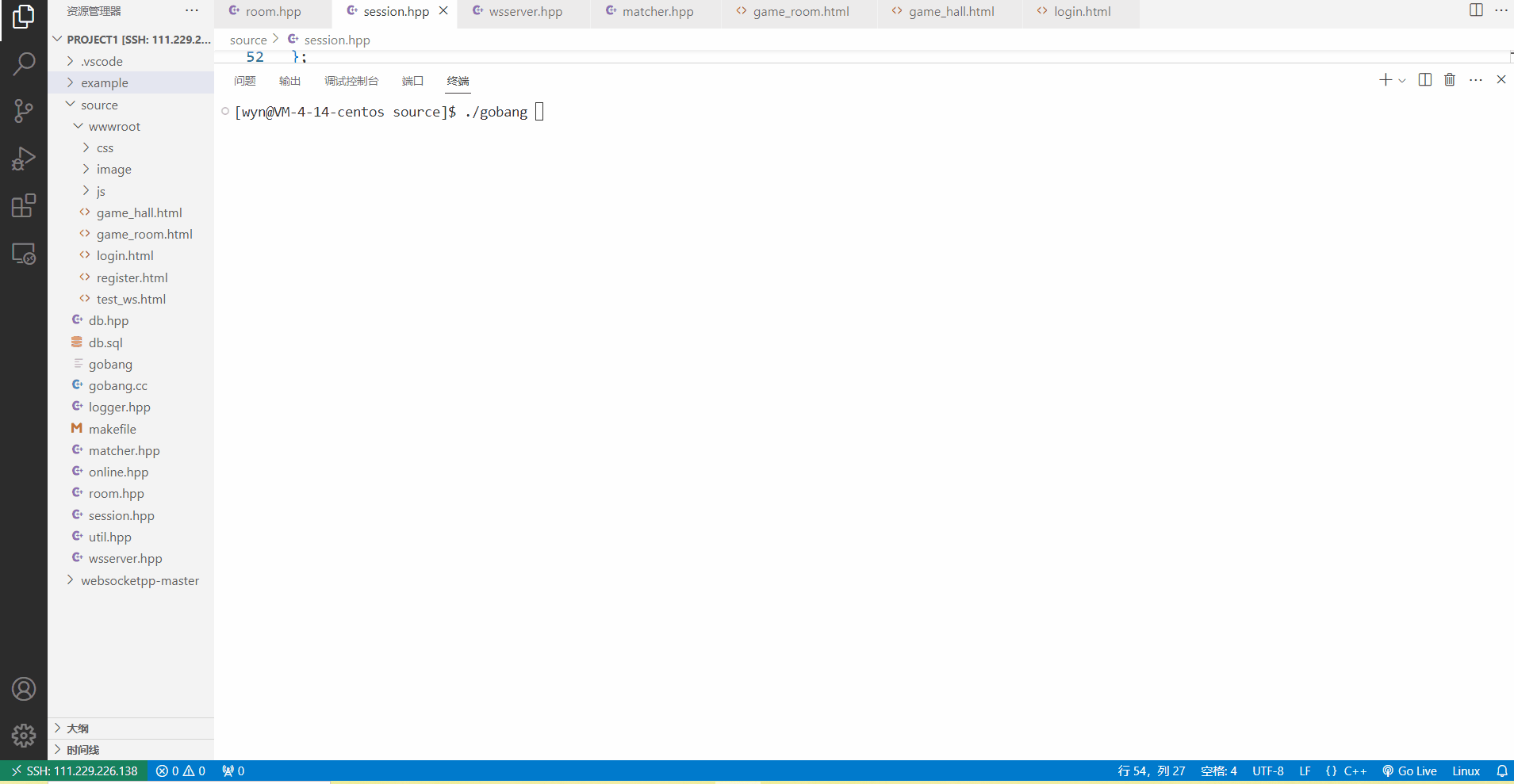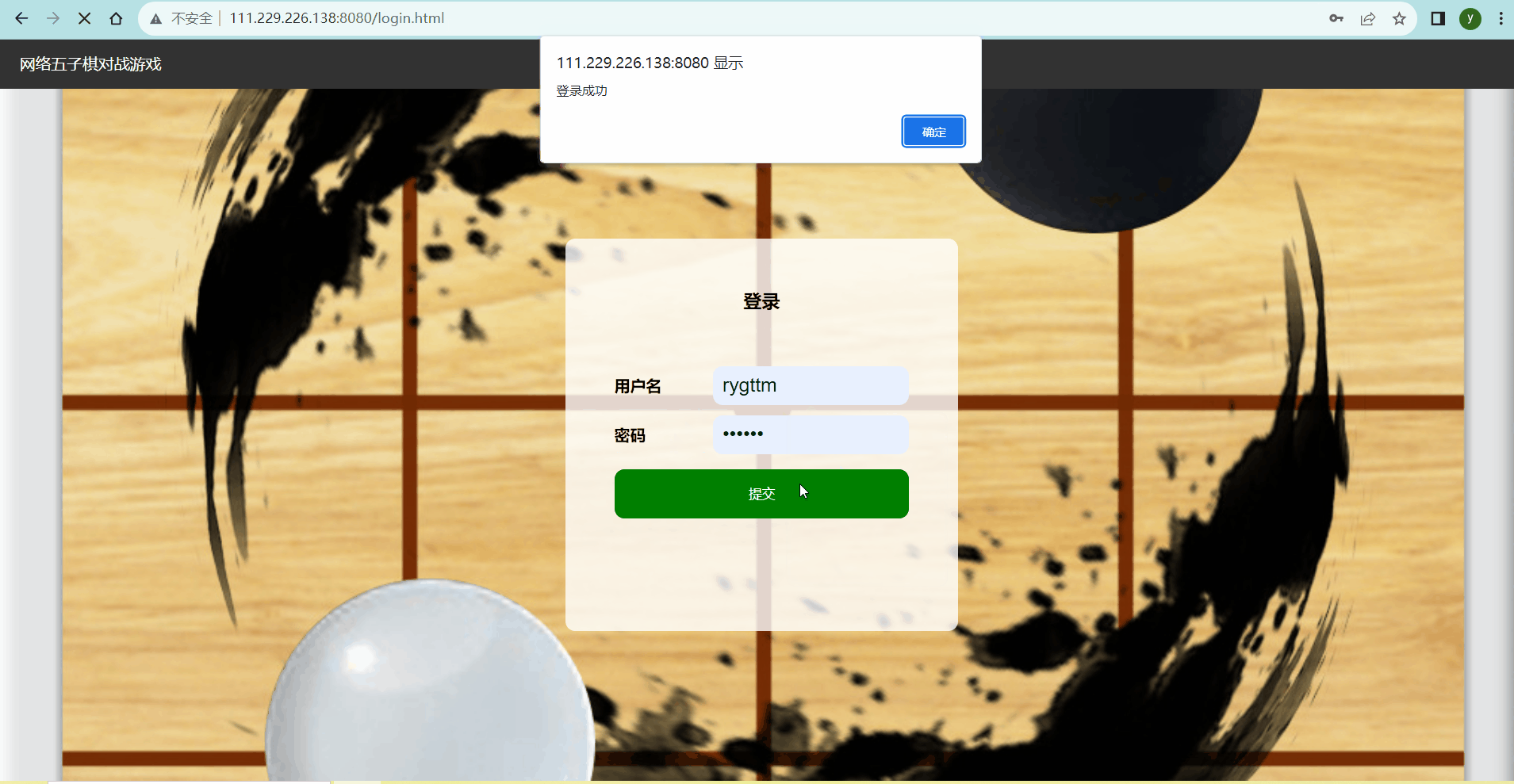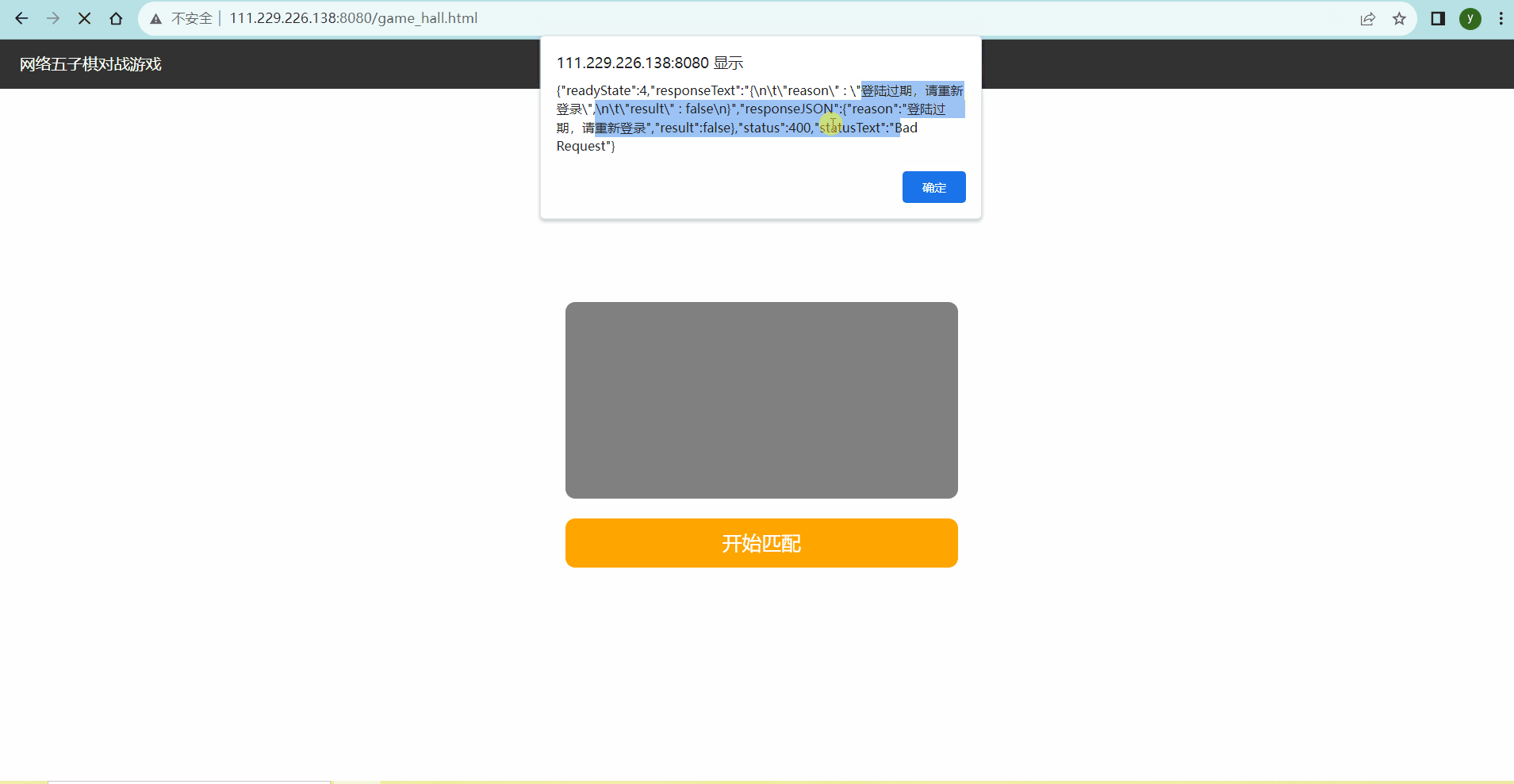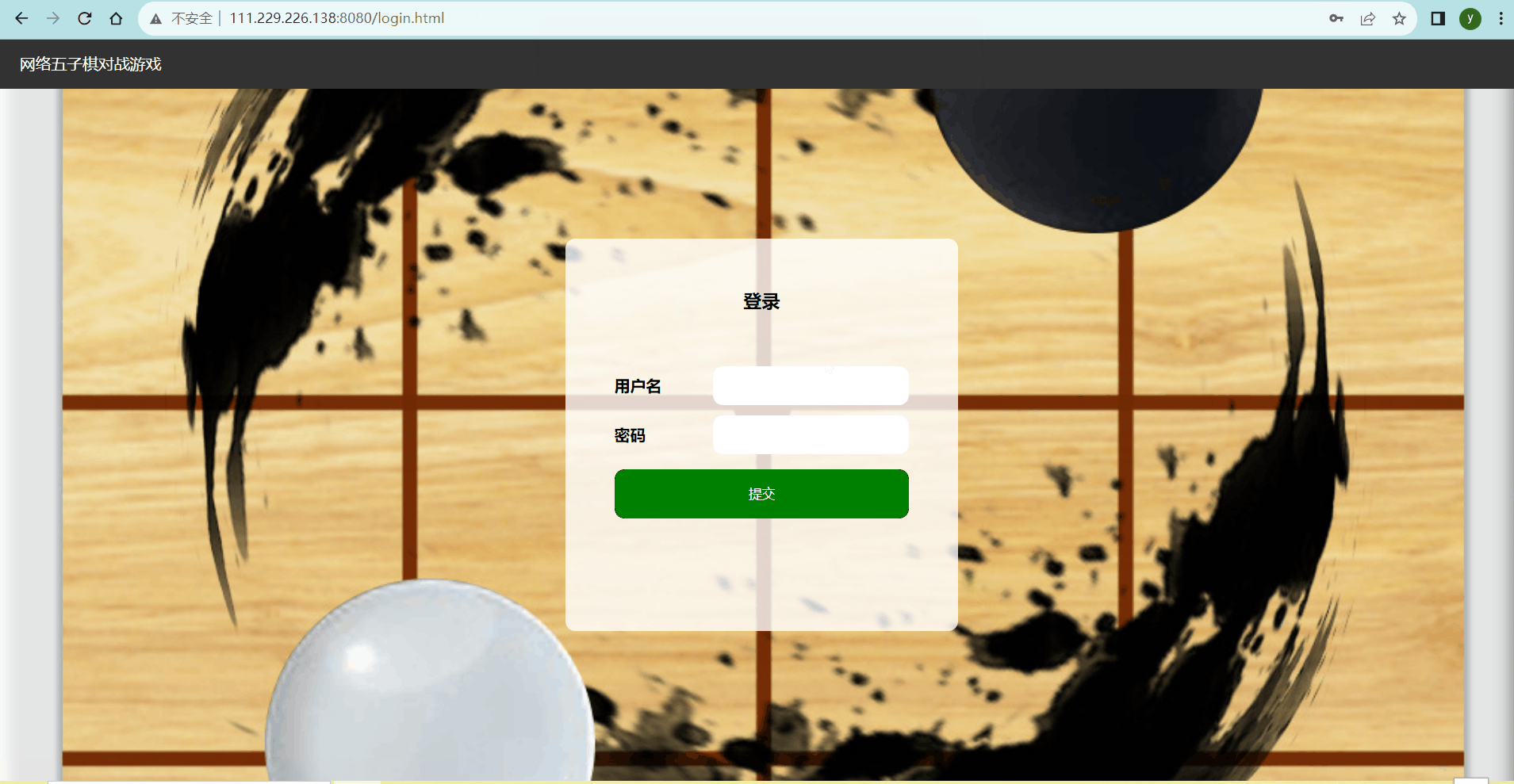
页面跳转到游戏大厅后,长连接建立成功,则session变为永久存在,在15s之后也可以看到,会话是不会被销毁的。
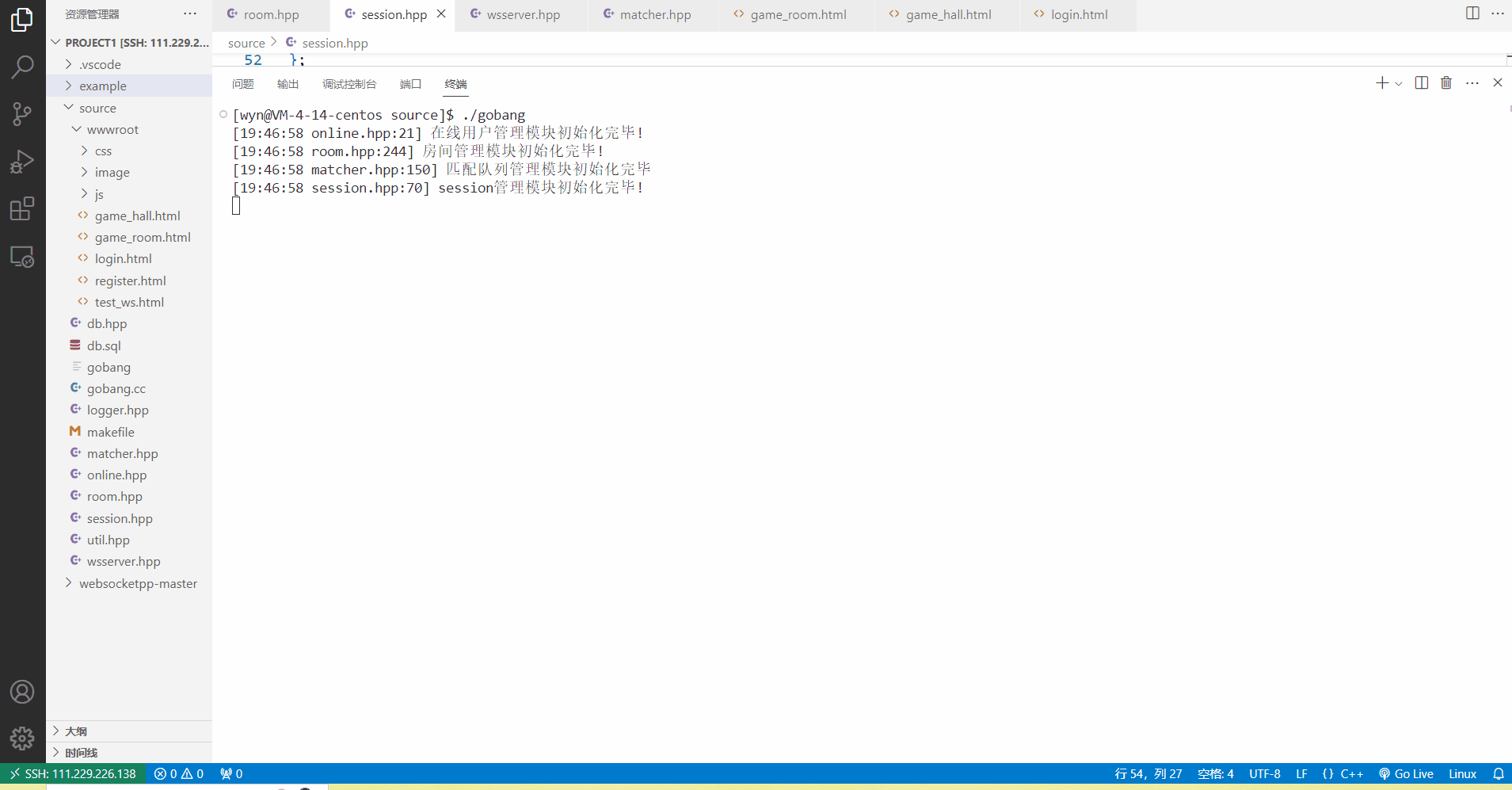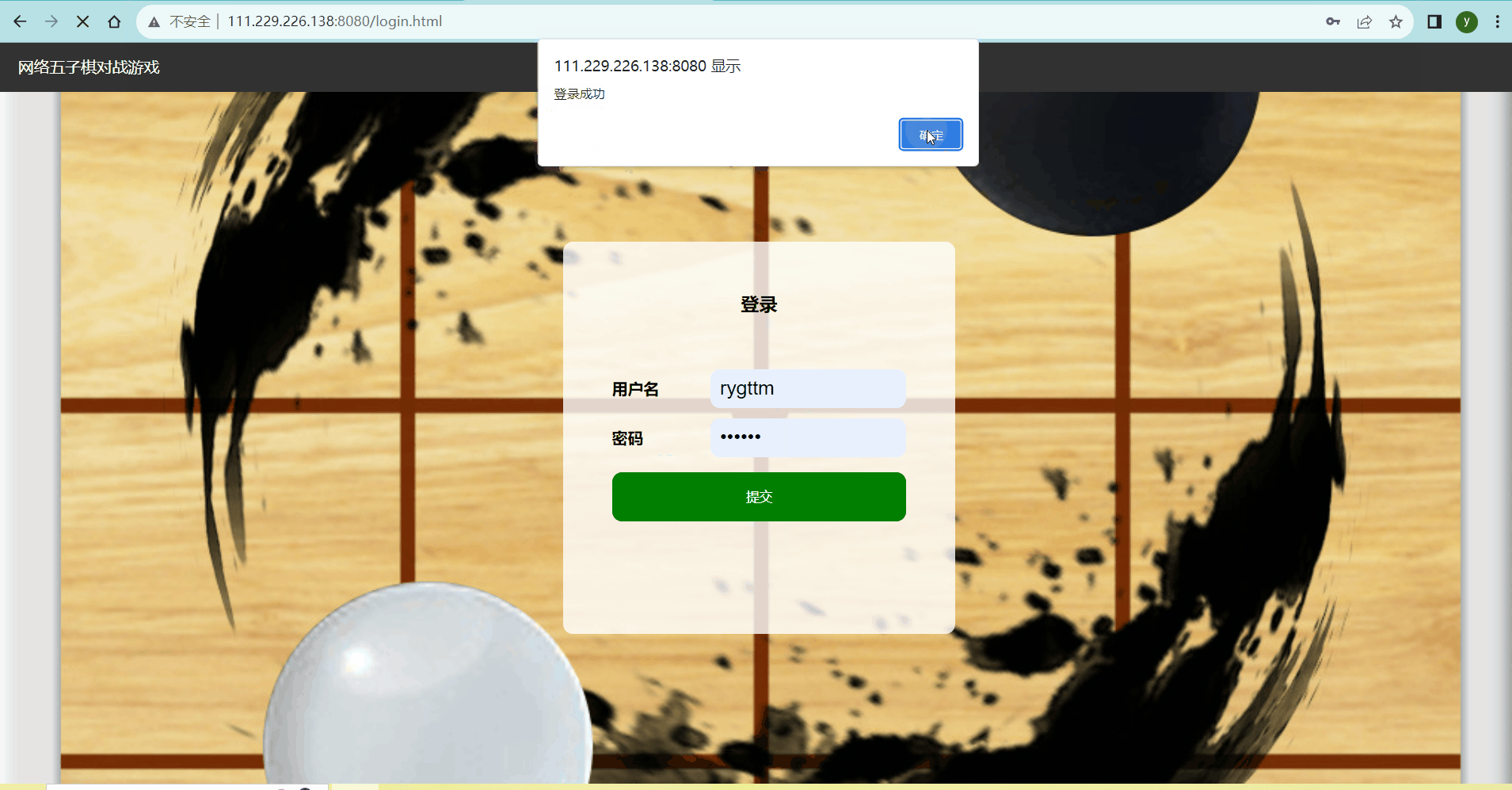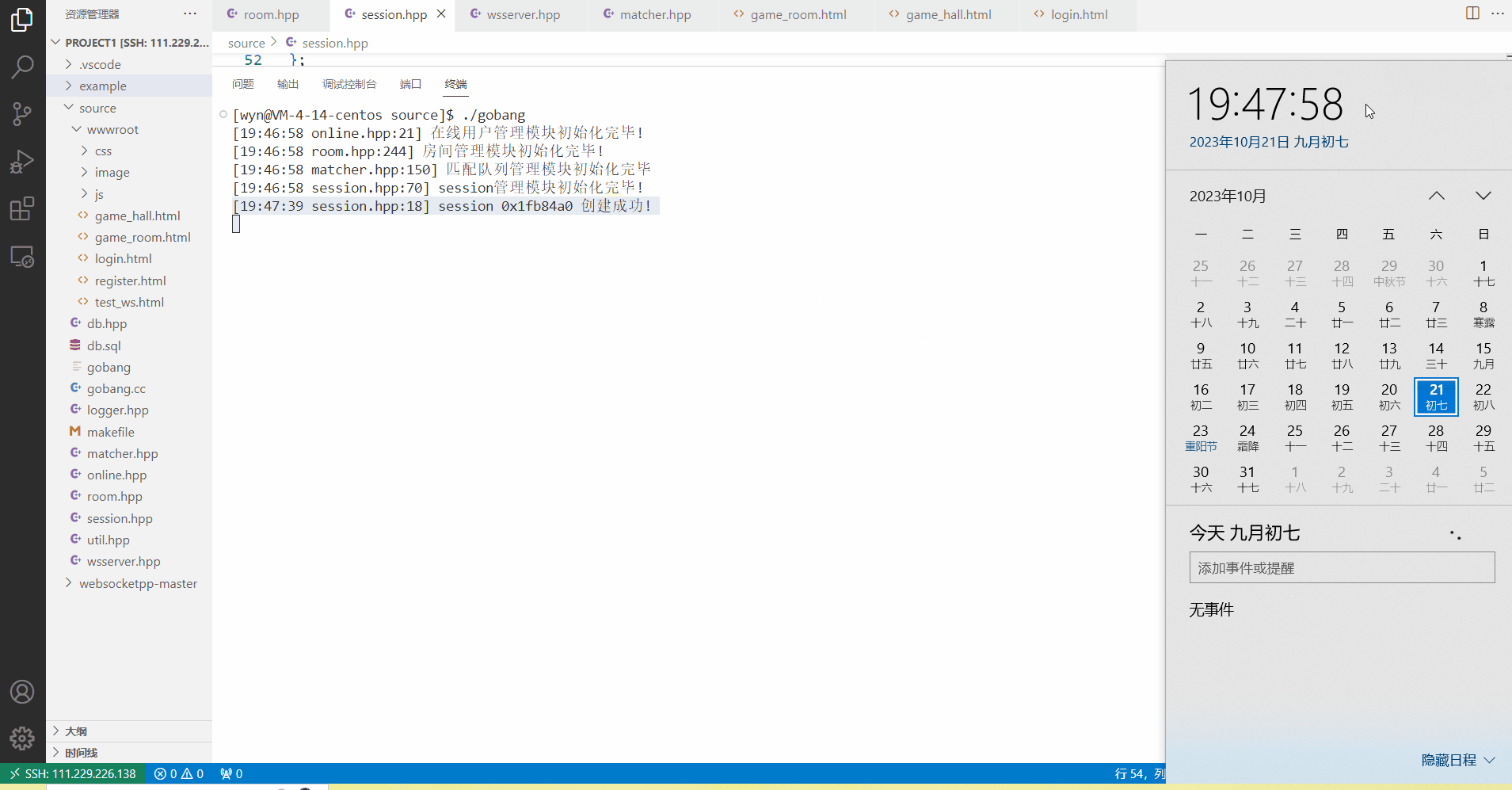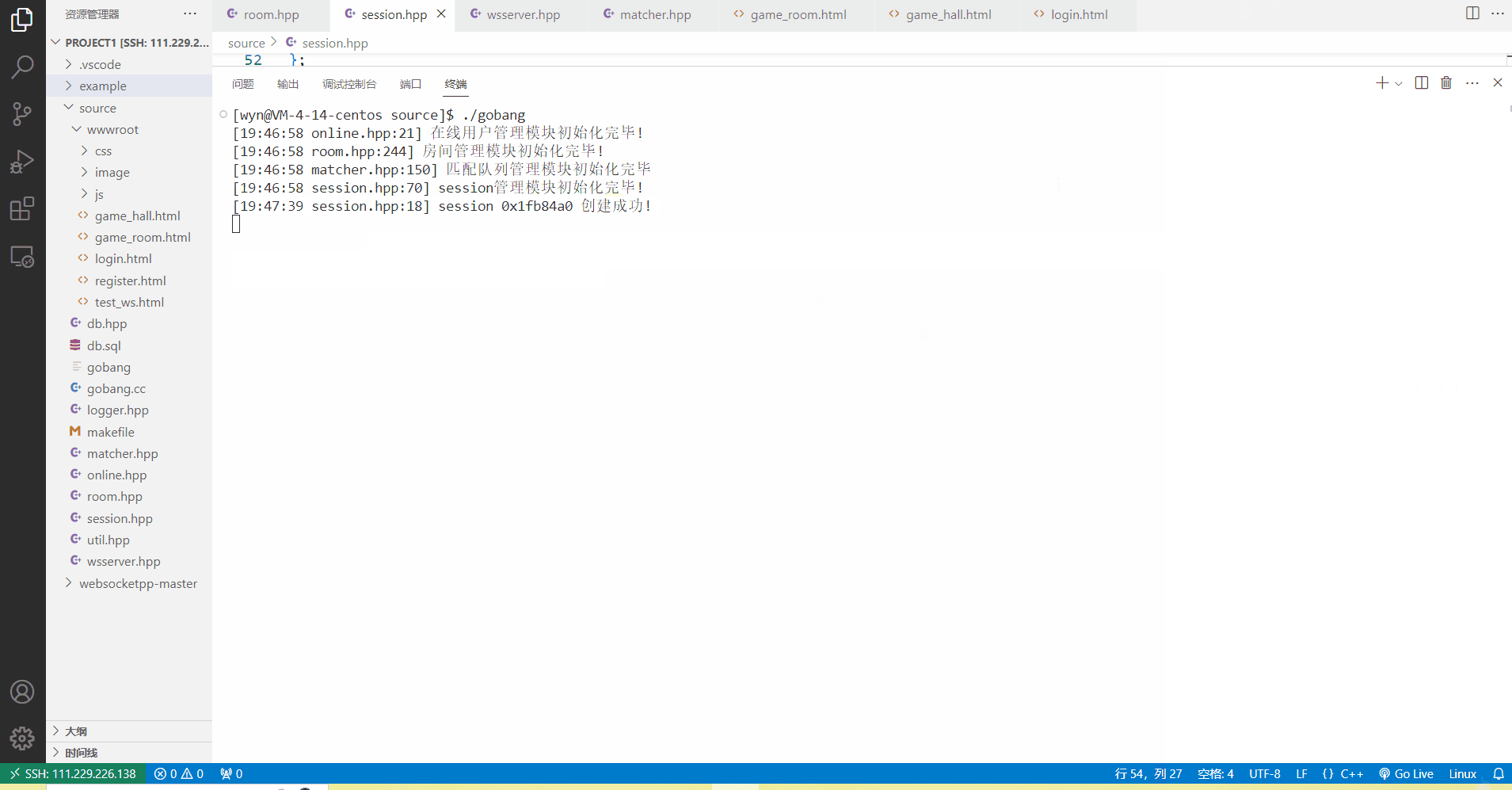
进入游戏大厅后,会话变为永久存在,那么当我们关闭游戏大厅页面之后,会话就会从永久存在变为定时销毁,在服务器终端上可以看到15s过后会话被销毁了。
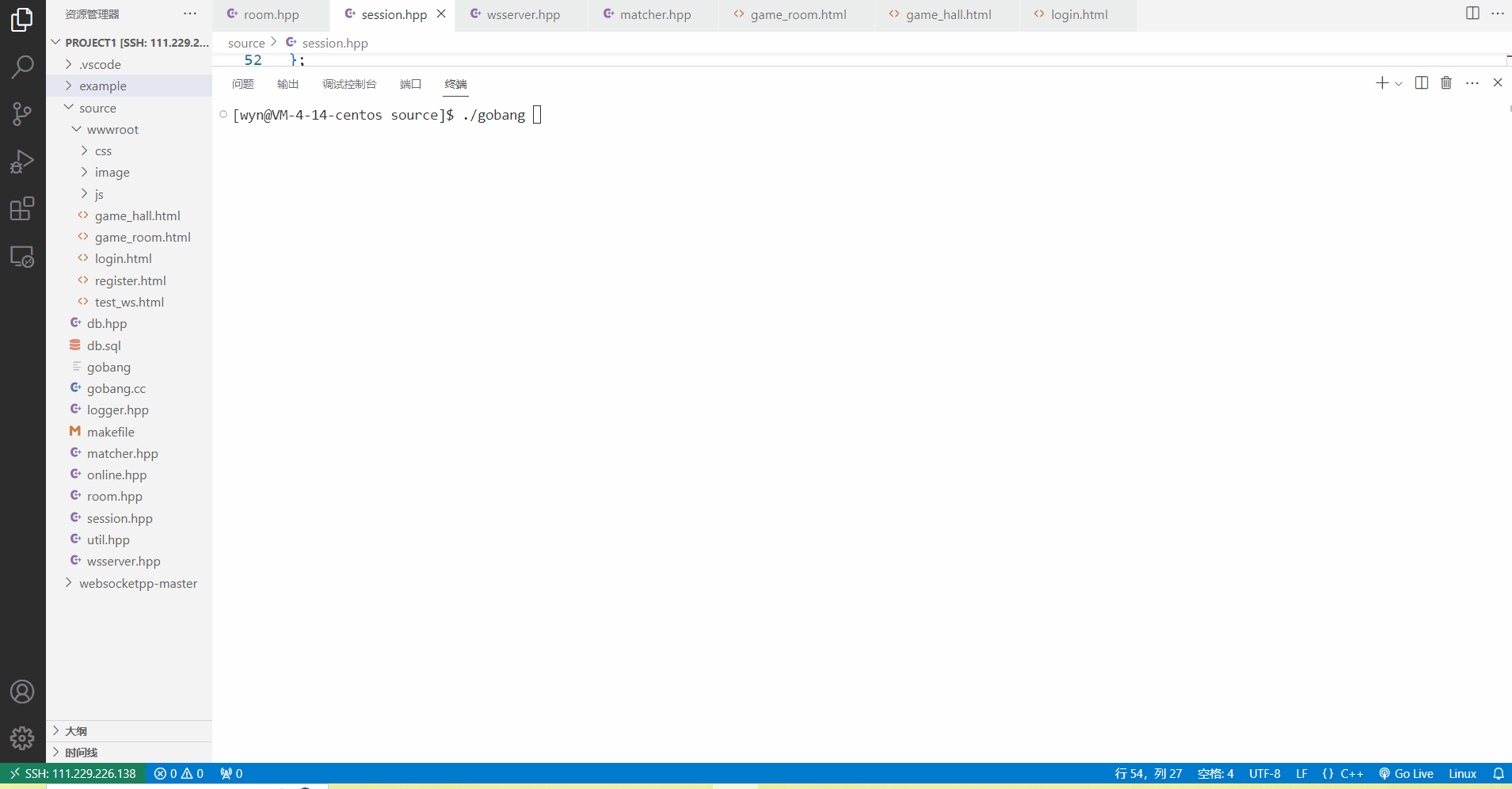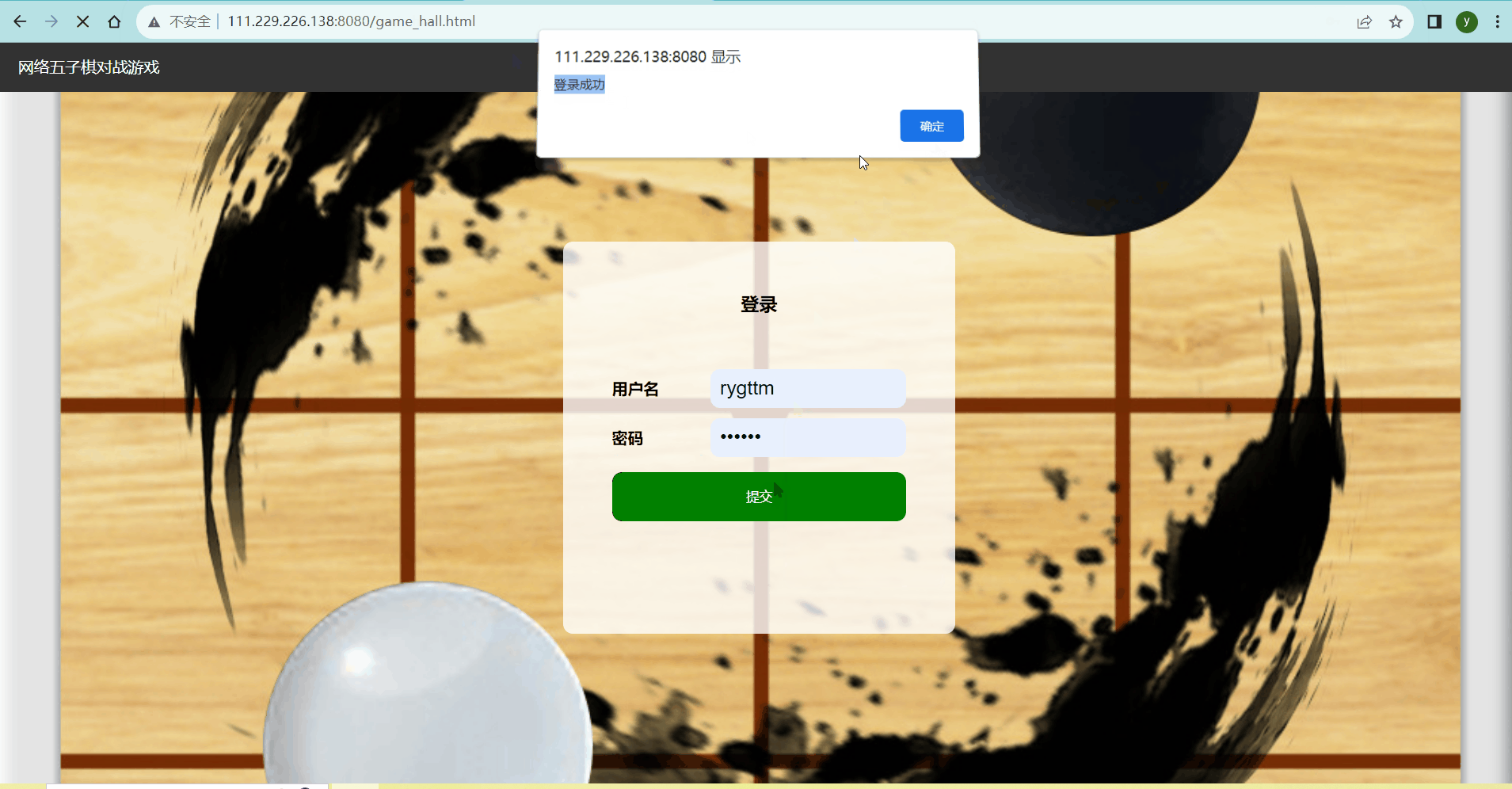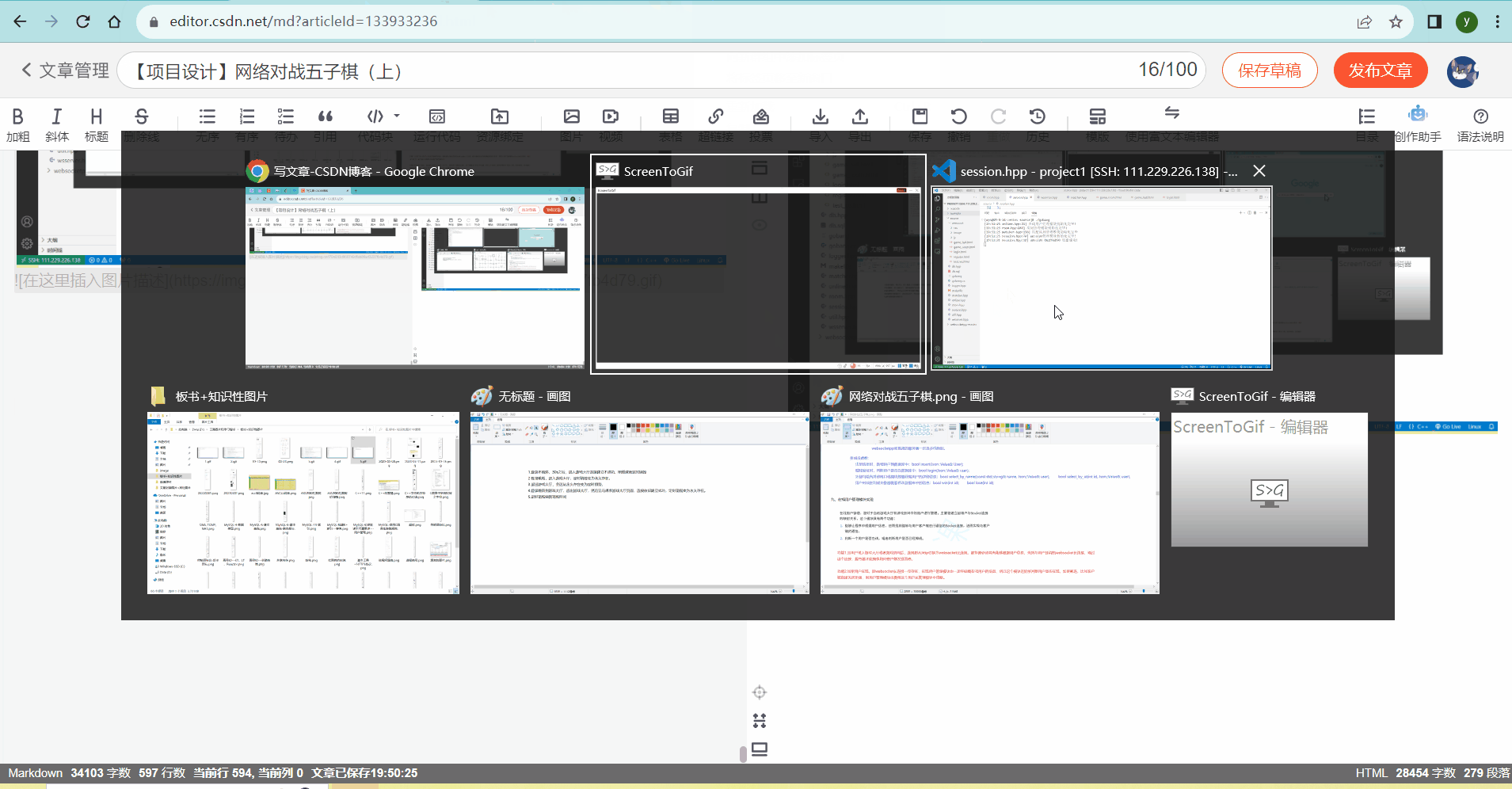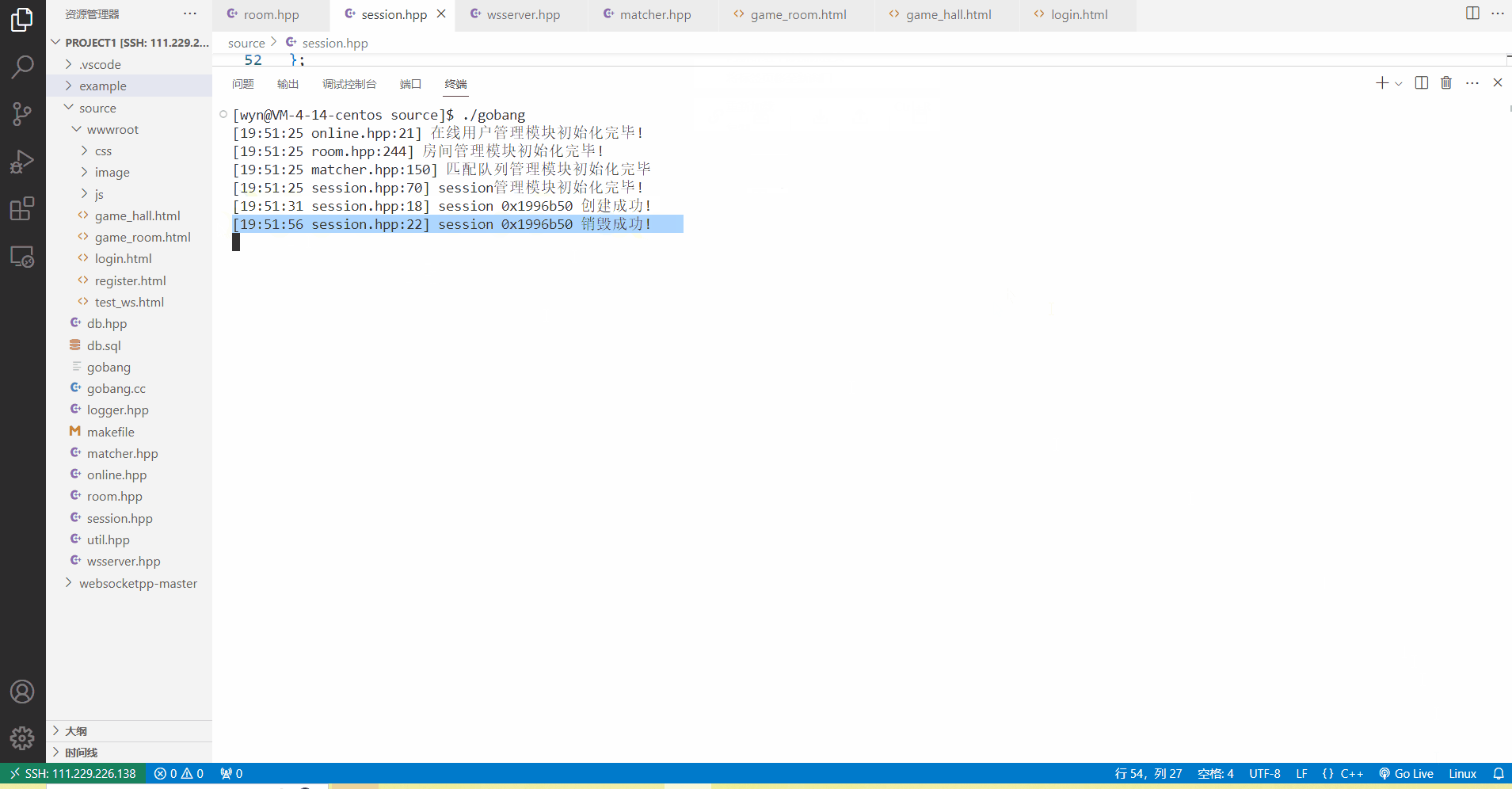
在初次登录成功后,刚创建的会话会保持15s的时间,在这段时间里,我们可以重新访问游戏大厅,重新向服务器发起websocket长连接握手,此时会话就会从定时销毁重新变为永久存在,并且在15s之后,会话是不会被删除的
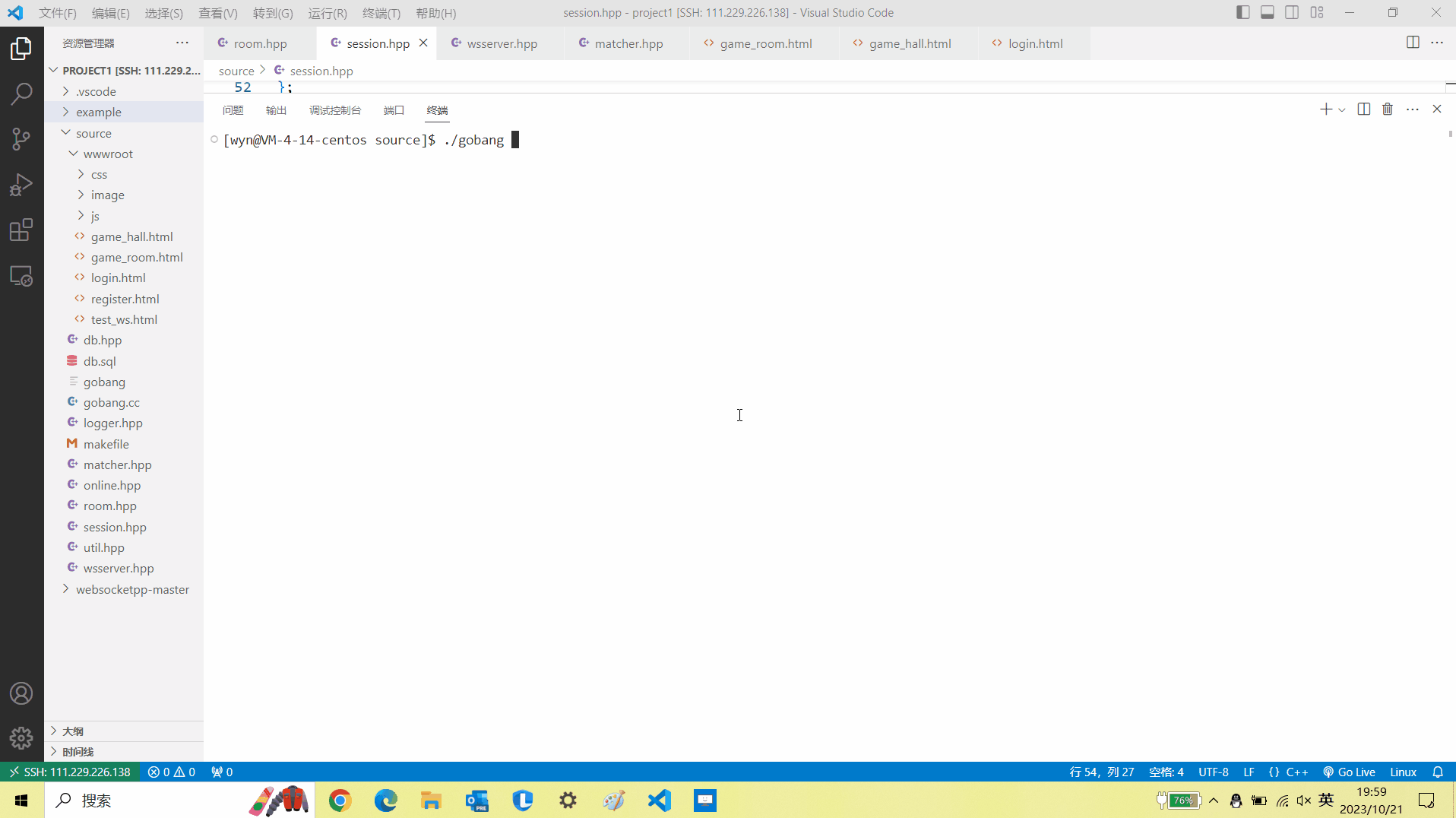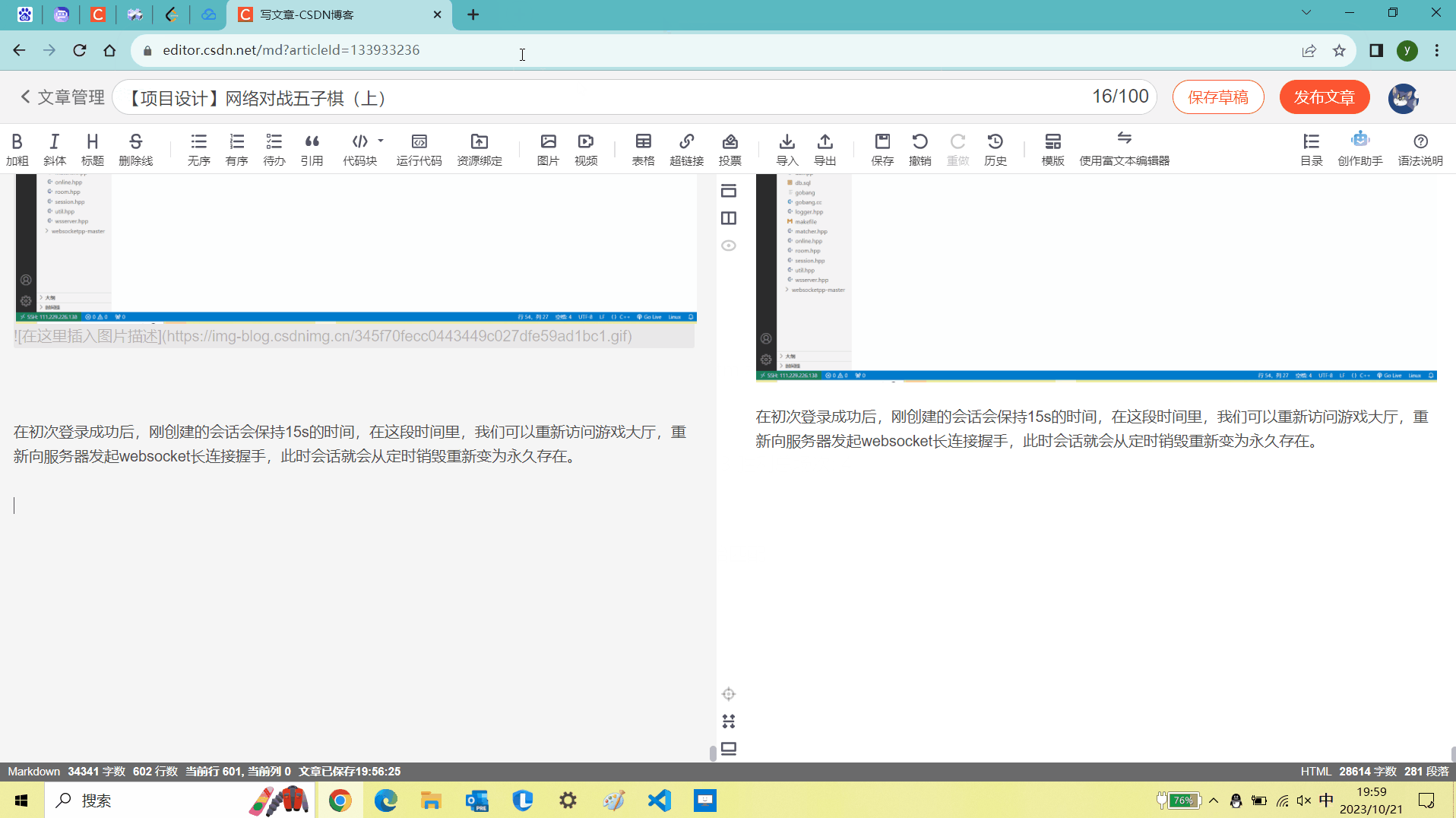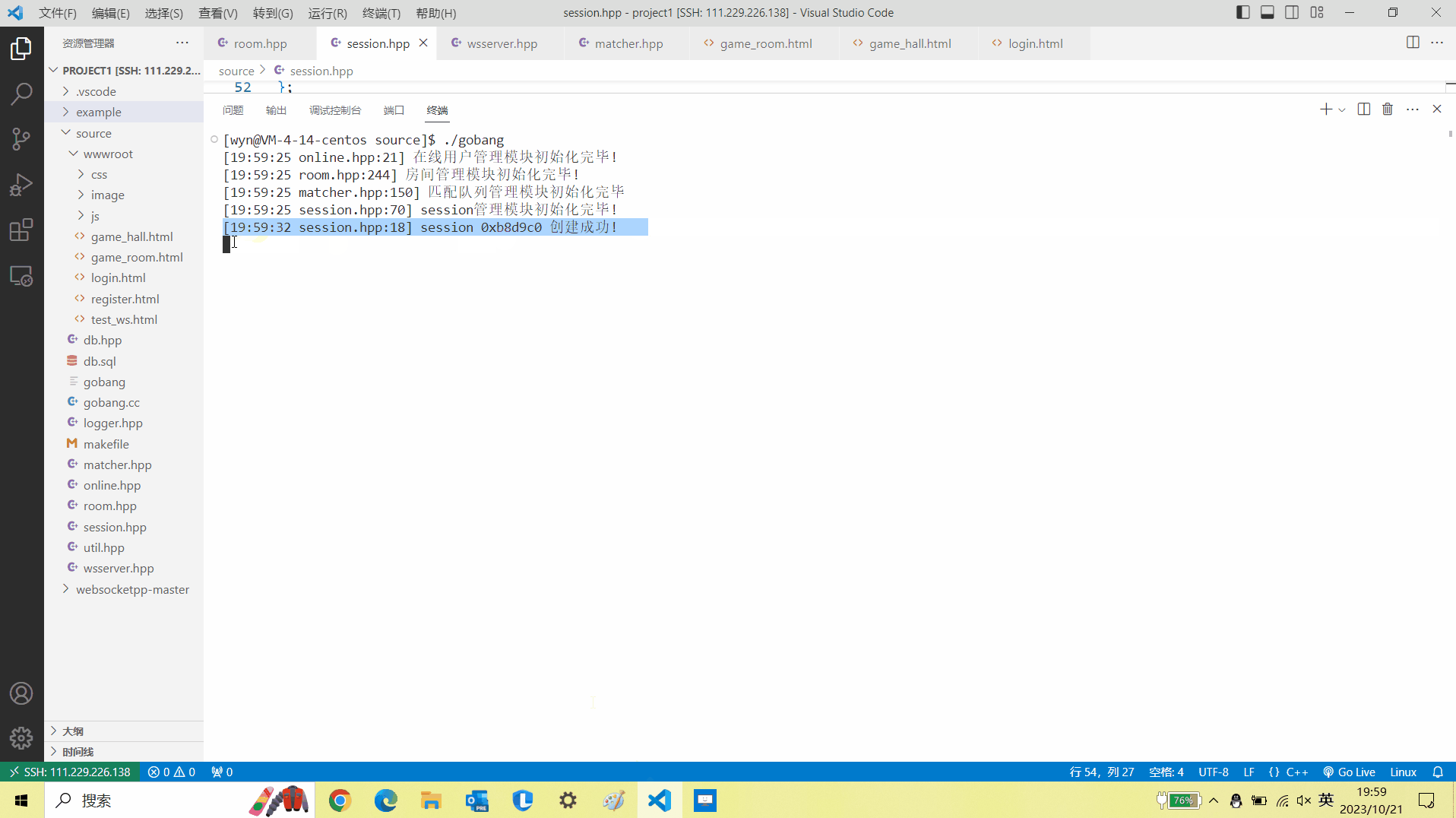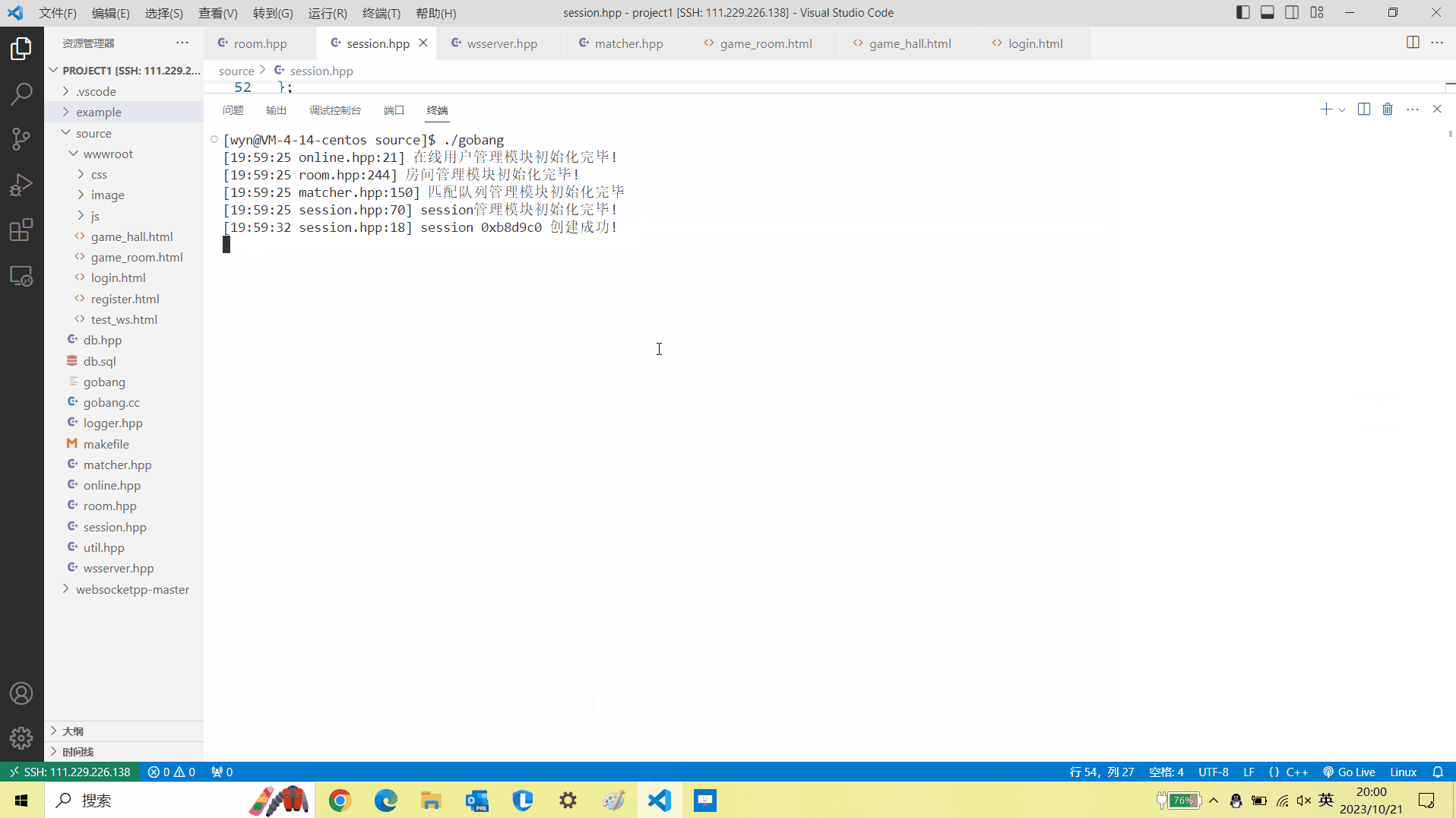
第一次登录成功后,服务器为我们创建了15s后销毁的会话,此时我们将页面关闭,重新进行登录,并且把这个过程控制在15s内完成,那么原来的会话过期时间就会被刷新。
(上面这种情况大家看个乐子就行,项目中正确的刷新会话过期时间应该是下面这种情况,上面我自己所说的这种情况,如果硬要实现,当然是可以实现的,但不推荐实现这个,因为效率比较低,我们需要在后端遍历session管理器的所有键值对,并且上面这样的思想也是不合适的,正确的想法就应该是用户每一次登录成功,服务器为用户创建一次session,你把上次用户登录创建好的session给刷新保留下来,能提高多少服务器的效率啊?提高到没多少,你后端还需要遍历session管理器中的所有键值对,整体服务器的效率还是降低的!
所以我上面叙述的这样的处理方式看个乐子就行,下一篇博文讲述封装服务器模块代码时候,我会再说明一下登录业务处理的逻辑,不要判断处理这种反复登录请求业务,从而使用同一个session的情况。)
还有一种情况是,进入游戏大厅后,前端会通过ajax发送http请求来获取到用户详细信息并展示到前端页面上,这个过程也会触发刷新会话过期时间。
(这种情况是本项目中唯一体现出刷新定时销毁session过期时间的情况!上面那种不算,仅仅是本人脑子里的一个小idea而已!)
从实验现象可以看到,前后两次登录用的是同一个session,第二次登录刷新了第一次登录所创建的session的定时销毁时间。
这篇关于【项目设计】网络对战五子棋(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








