本文主要是介绍php调取 zabbix实时数据_centos7安装部署zabbix(躲坑版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:zabbix简介
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。
zabbix能监视各种网络参数,保证服务器系统的安全运营;并提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题。
zabbix由2部分构成,zabbix server与可选组件zabbix agent。
zabbix server可以通过SNMP,zabbix agent,ping,端口监视等方法提供对远程服务器/网络状态的监视,数据收集等功能,它可以运行Linux Solaris,HP-UX,AIX,Free BSD,Open BSD,OS X等平台上。
一、注意事项
1、关闭selinux
setenforce 0
2、安装zabbix-server-mysql zabbix-web-mysql zabbix-agent时设置数据库导入数据时会报错,提示没有安装mysql,这是因为mysql已经不开源了,用mariadb-server替代,完全兼容mysql命令
3、firewall暂时关闭,或者配置firewall开放80端口,否则会出现页面无法打开
#iptables -L -n查看防火墙配置#firewall-cmd --add-port=80/tcp --permanent添加80端口#firewall-cmd --reload重新载入frilewall规则二、安装zabbix相关包
1、安装yum源包
安装repo源#rpm -Uvh https://repo.zabbix.com/zabbix/4.0/rhel/7/x86_64/zabbix-release-4.0-1.el7.noarch.rpmZabbix前端需要基本安装中不提供的其他软件包。 您需要在将在以下位置运行Zabbix前端的系统中启用可选rpm的存储库:#yum-config-manager --enable rhel-7-server-optional-rpm2、安装Zabbix服务器,前端,代理
#yum install zabbix-server-mysql zabbix-web-mysql zabbix-agent -y在安装过程中如果网速慢会提示安装失败,不要担心,重复命令直到进度条完成3、创建初始数据库
# mysql -uroot -p password(初次不需要)回车 mysql> create database zabbix character set utf8 collate utf8_bin; mysql> create user zabbix@localhost identified by 'password';(password为你的密码) mysql> grant all privileges on zabbix.* to zabbix@localhost; mysql> quit;4、为Zabbix服务器配置数据库
(1)编辑文件/etc/zabbix/zabbix_server.conf
#vim /etc/zabbix/zabbix_server.conf找到“DBPassword=”行取消掉注释输入你的数据库密码(2)编辑文件/etc/php-fpm.d/zabbix.conf,取消注释并为您设置正确的时区。
php_value[date.timezone] = Europe/Riga5、启动zabbix服务和代理进程
启动Zabbix服务器和代理进程,并使其在系统启动时启动。
# systemctl restart zabbix-server zabbix-agent httpd php-fpm# systemctl enable zabbix-server zabbix-agent httpd php-fpm打开浏览器输入http://zabbix-ip/zabbix/setup.php
1、点击nextstep

2、查看所有依赖进程是否正常
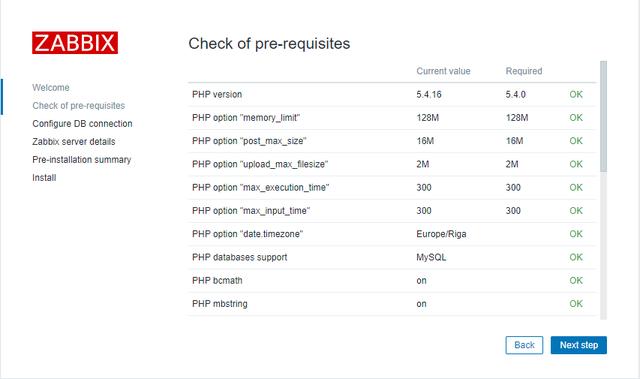
3、输入数据库密码
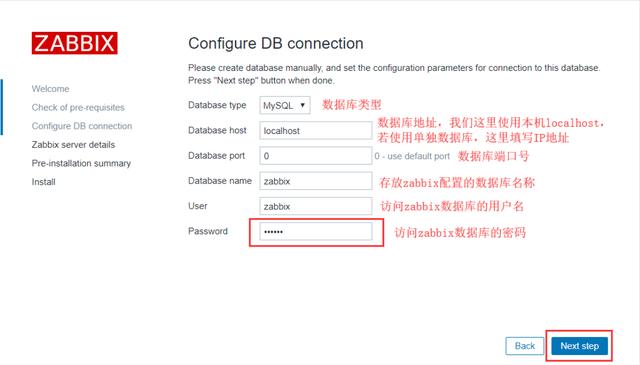
4、命名你的zabbix监控
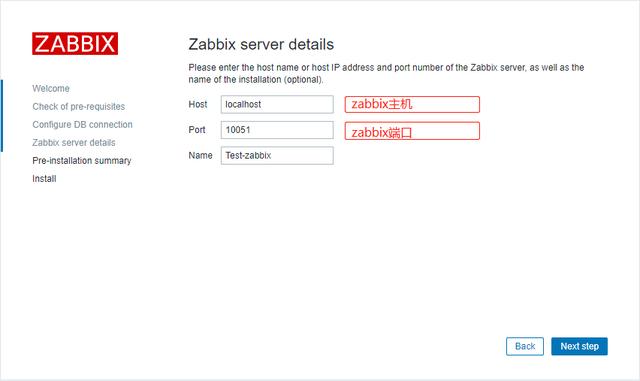
5、确认信息的正确
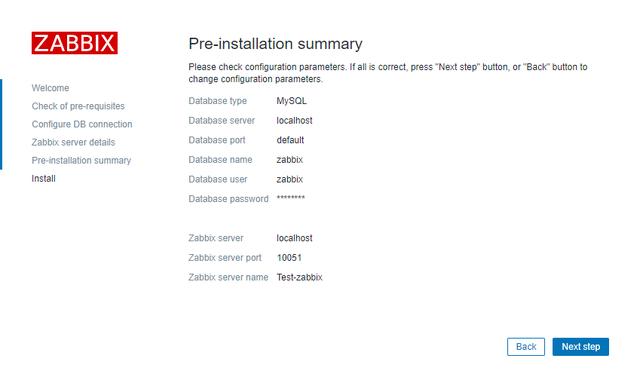
6、完成
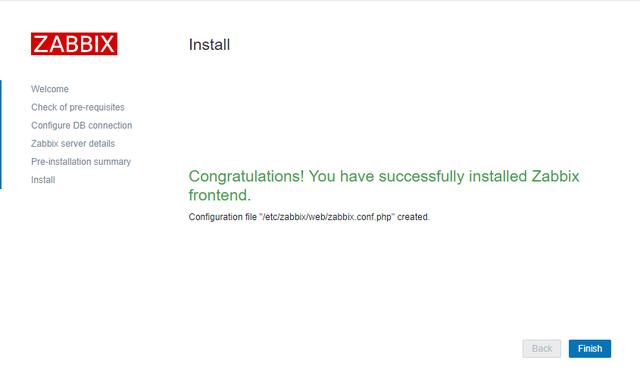
7、首次用户名为Admin 密码zabbix
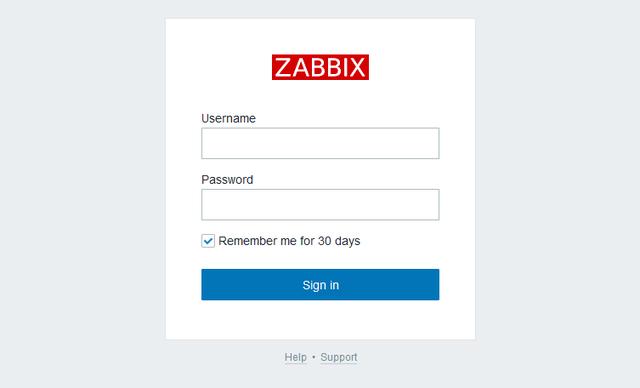
8、登陆进主页查看zabbix-server 状态yes为正常
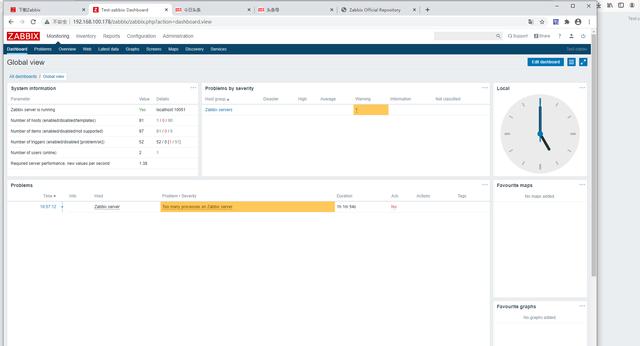
9、默认为English更改语言,改为中文,administrator---user----选择Admin
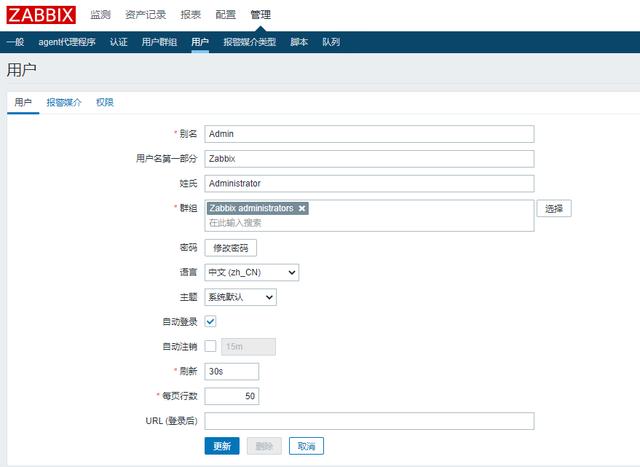
至此zabbix安装完成了
这篇关于php调取 zabbix实时数据_centos7安装部署zabbix(躲坑版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







