本文主要是介绍python用scrapy框架爬取双色球数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、今天刷到朋友圈,看到一个数据,决定自己也要来跟随下潮流(靠天吃饭)

去百度了下,决定要爬的网站是https://caipiao.ip138.com/shuangseqiu/
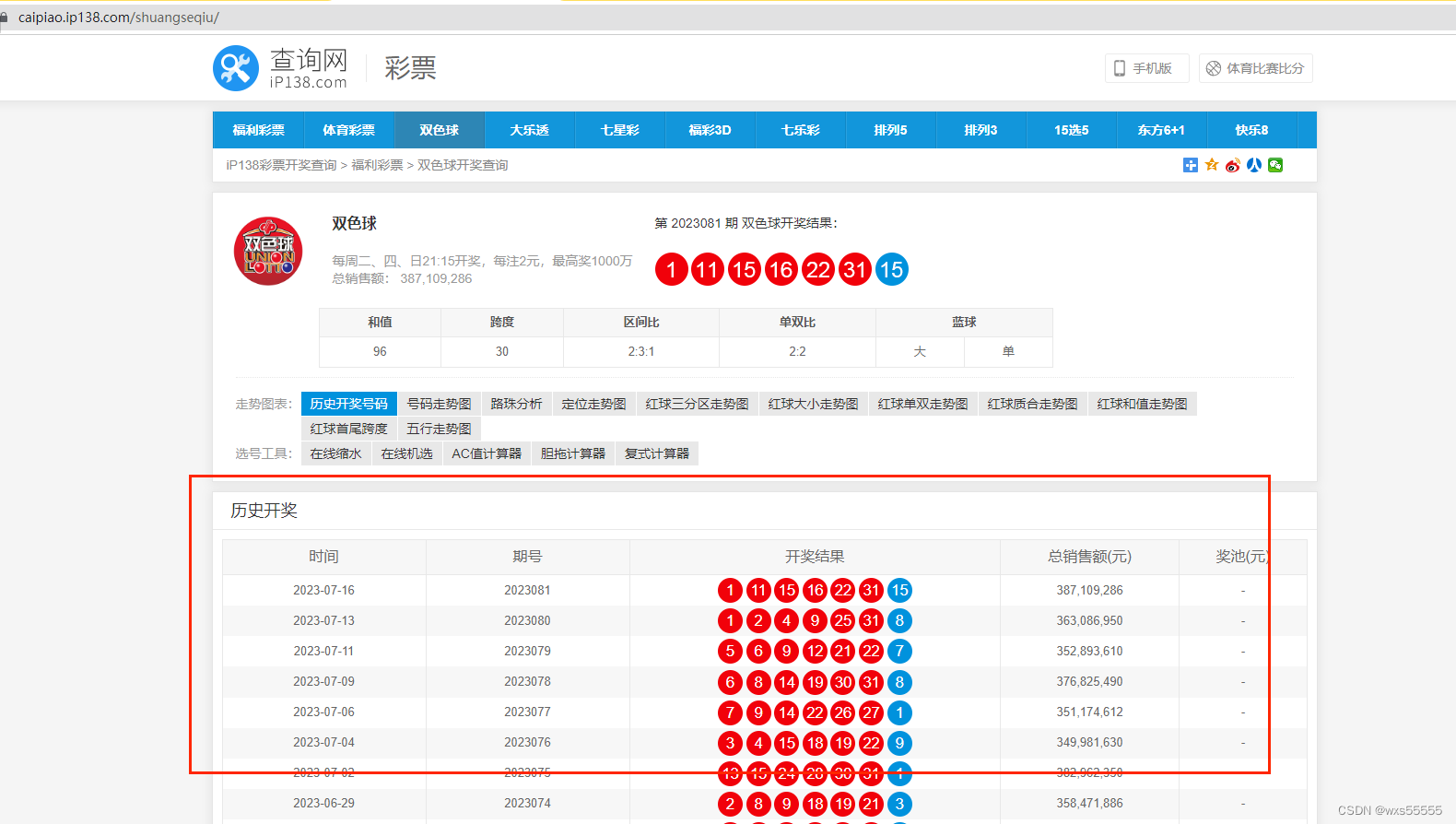
分析:根据图片设计数据库便于爬取保存数据,时间,6个红球,一个蓝球字段
DROP TABLE IF EXISTS `shuangseqiu`;
CREATE TABLE `shuangseqiu` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`openDate` date NOT NULL COMMENT '日期',`red1` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球1',`red2` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球2',`red3` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球3',`red4` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球4',`red5` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球5',`red6` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '红球6',`blue` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '蓝球',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 342 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Dynamic;SET FOREIGN_KEY_CHECKS = 1;2、安装python,去官网下载一个windows版本的,一直下一步就行了
3、安装完后打开cmd,输入pip install scrapy安装scrapy框架
4、框架安装完后,输入 scrapy startproject caipiao新增彩票项目
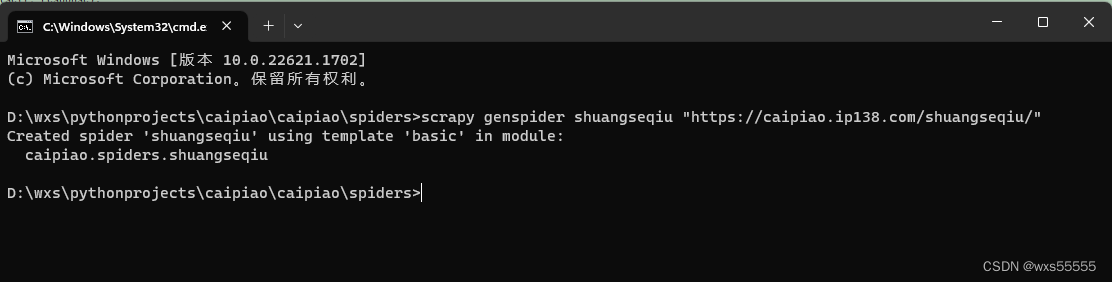
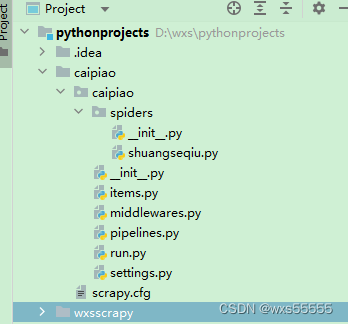
5、进入到spider目录,输入 scrapy genspider shuangseqiu "https://caipiao.ip138.com/shuangseqiu/"新增双色球爬虫,最终生成项目结构如下
6、在items.py里面定义爬取存储的字段
import scrapyclass ShuangseqiuItem(scrapy.Item):# define the fields for your item here like:openDate = scrapy.Field()red1 = scrapy.Field()red2 = scrapy.Field()red3 = scrapy.Field()red4 = scrapy.Field()red5 = scrapy.Field()red6 = scrapy.Field()blue = scrapy.Field()
7、在pipelines.py里面写好保存数据库的逻辑,并在settings.py文件新增配置,数据库连接配置在settings.py文件里面新增下面配置就行
settings.py配置如下
ITEM_PIPELINES = {"caipiao.pipelines.ShuangseqiuscrapyPipeline": 300,
}MYSQL_HOST = '192.168.XXX.XXX'
MYSQL_DBNAME = '数据库名'
MYSQL_USER = '用户'
MYSQL_PASSWD = '密码'pipelines.py文件内容如下
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
import pymysql
from caipiao import settingsclass ShuangseqiuscrapyPipeline:def __init__(self):# 连接数据库self.connect = pymysql.connect(host=settings.MYSQL_HOST,db=settings.MYSQL_DBNAME,user=settings.MYSQL_USER,passwd=settings.MYSQL_PASSWD,charset='utf8',use_unicode=True)# 通过cursor执行增删查改self.cursor = self.connect.cursor();def process_item(self, item, spider):try:# 先删除数据self.cursor.execute("""delete from shuangseqiu where openDate=%s""",(item['openDate']))# 插入数据self.cursor.execute("""insert into shuangseqiu(openDate,red1,red2,red3,red4,red5,red6,blue)value (%s,%s, %s, %s,%s, %s,%s, %s)""",(item['openDate'],item['red1'],item['red2'],item['red3'],item['red4'],item['red5'],item['red6'],item['blue']))# 提交sql语句self.connect.commit()except Exception as error:# 出现错误时打印错误日志print(error)return item
8、在spiders/shuangseqiu.py下面写爬取逻辑,不知道怎么获取xpath结构的可以在网站右击节点获取copy---->copy full xpath
import scrapyfrom caipiao.items import ShuangseqiuItemclass ShuangseqiuSpider(scrapy.Spider):name = "shuangseqiu"allowed_domains = ["caipiao.ip138.com"]start_urls = ["https://caipiao.ip138.com/shuangseqiu/"]def parse(self, response):print(response.text)#获取历史开奖列表shuangseqiuList = response.xpath("//div[@class='module mod-panel']//div[@class='panel']//tbody/tr")for li in shuangseqiuList:item = ShuangseqiuItem()#获取开奖时间item["openDate"] = li.xpath('td[1]/span/text()')[0].extract()#获取中奖号码balls=li.xpath('td[3]/span/text()');item["red1"] = balls[0].extract()item["red2"] = balls[1].extract()item["red3"] = balls[2].extract()item["red4"] = balls[3].extract()item["red5"] = balls[4].extract()item["red6"] = balls[5].extract()item["blue"] = balls[6].extract()print(item)yield item
9、新增run.py文件,用来在idea里面跑cmd脚本用来爬数据
from scrapy import cmdlinename = 'shuangseqiu'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
10、执行run.py,发现报错
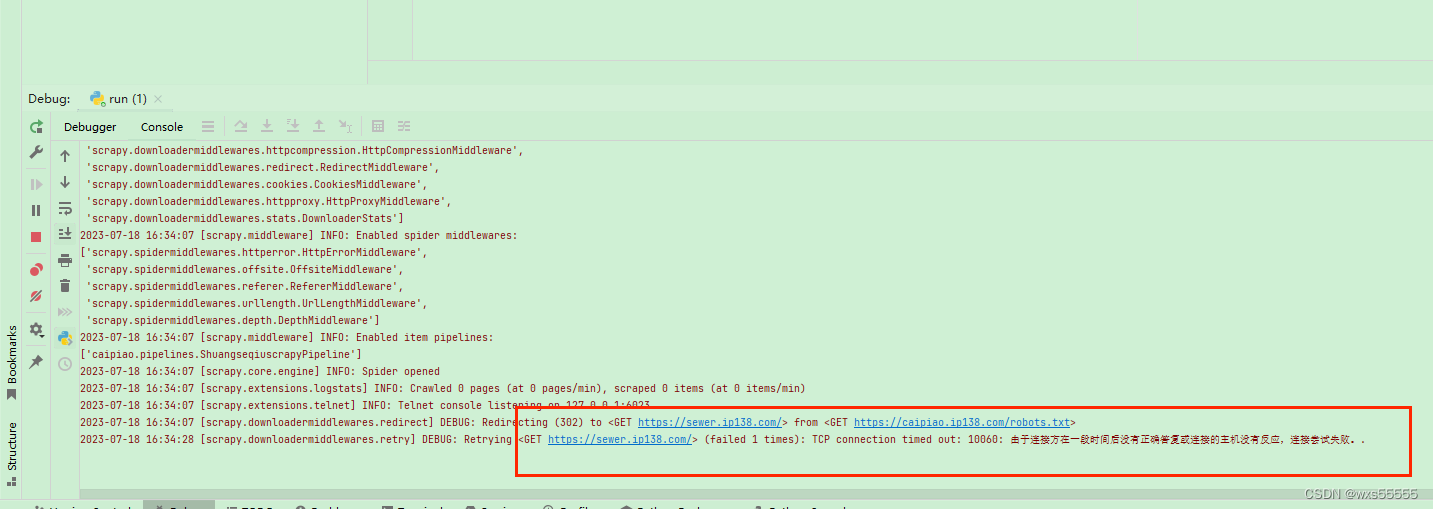
11、百度了一下,通过修改settings.py如下配置,在执行run.py,发现成功了
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"ROBOTSTXT_OBEY = False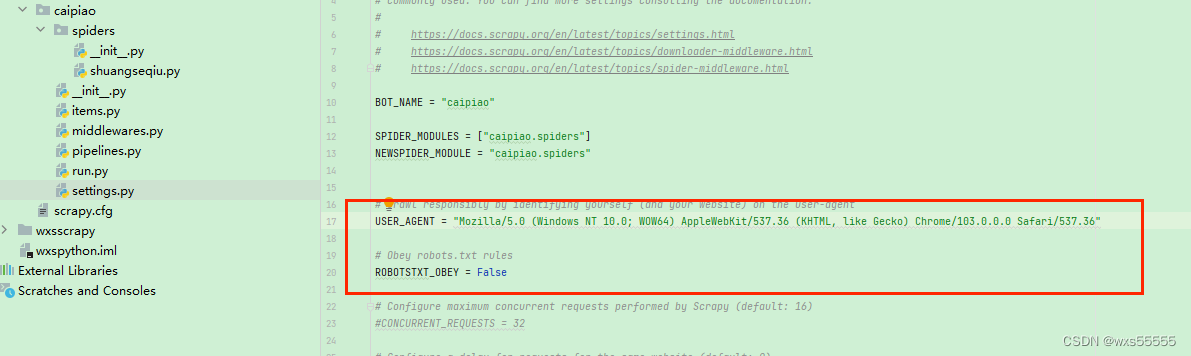
 12.数据库查询表,发现数据成功获取
12.数据库查询表,发现数据成功获取
13、拿数据去分析,离中大奖不远了![]()
![]() ~~~~,下面是几个简单的数据分析sql
~~~~,下面是几个简单的数据分析sql
-- 统计每个位置的球出现最多次数的号码SELECT red1,count(red1) FROM `shuangseqiu` group by red1 order by count(red1) desc;SELECT red2,count(red2) FROM `shuangseqiu` group by red2 order by count(red2) desc;SELECT red3,count(red3) FROM `shuangseqiu` group by red3 order by count(red3) desc;SELECT red4,count(red4) FROM `shuangseqiu` group by red4 order by count(red4) desc;SELECT red5,count(red5) FROM `shuangseqiu` group by red5 order by count(red5) desc;SELECT red6,count(red6) FROM `shuangseqiu` group by red6 order by count(red6) desc;SELECT blue,count(blue) FROM `shuangseqiu` group by blue order by count(blue) desc;-- 统计每周几出现次数最多次的号码 0-6为周日到周六SELECT DATE_FORMAT(openDate, '%w'),red1,count(red1) FROM `shuangseqiu` group by red1,DATE_FORMAT(openDate, '%w') order by DATE_FORMAT(openDate, '%w') asc,count(red1) desc;14 、完事了~~~~~~
这篇关于python用scrapy框架爬取双色球数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



