本文主要是介绍用iApp写爬虫(手动滑稽),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在安卓和ios出现以前,移动端的游戏主要来自J2ME平台,但随着安卓与ios的出现,这种平台上的游戏逐渐没落,很多提供相关游戏资源下载的网站相继关闭。所以,我打算在所剩不多的游戏网站关闭之前,抓取所有与游戏相关的资源。以7723为例,我们要抓取的内容包括游戏名称、游戏类型、语言、更新时间、游戏介绍、游戏图标、游戏截图(jpg、png、gif)、游戏评论、以及相应的jar、sis、six格式的软件包,以此形成一个资料详细完整的游戏文件夹,资源总大小75G。
实例链接:http://www.7723.cn/download/12215.htm
1.首先找到对应内容的HTML页面,如下图所示。




简单分析一下页面的html代码结构就可以开始写啦。
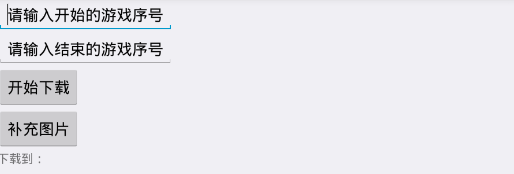
2.创建图形界面,文本框及按钮对应序号如右图所示。

3. 代码部分,写在按钮5点击事件中。
ug(3,"text",st)
ug(4,"text",en)
sss en = en
t()
{//软件总数12216 设为变量javanum//文件名规则:1.文件名=分辨率//2.创建文件夹命名规则=游戏名+类型+语言+编号+更新日期//3.文件夹内包括游戏=游戏介绍文本+更新日期+介绍图+截图+各分辨率版本(触屏)+评论s javanum = stw(javanum!=en){ufnsui(){ss("下载到:" + javanum,xzd)us(7,"text",xzd)}syso(javanum)s downloadaddf="http://www.7723.cn/download/"s downloadaddb=".htm"ss(downloadaddf + javanum + downloadaddb,add)hs(add,origin)w(origin==null){s(javanum+1,javanum) s downloadaddf="http://www.7723.cn/download/"s downloadaddb=".htm"ss(downloadaddf + javanum + downloadaddb,add)hs(add,origin)f(javanum>=en){end()}}//第一步:获取应用名namesiof(origin,"<title>",name1)s(name1 + 50,name11)ssg(origin,name1,name11,namep)siof(namep,"_",name2)ssg(namep,7,name2,name)sr(name,":",":",name)sr(name,"*"," ",name)sr(name,"?","",name)//第二步:获取游戏类型、语言、以及更新日期//1.得到类型typesiof(origin,"<dd>类型",type1)s(type1+150,type11)ssg(origin,type1,type11,typep)siof(typep,"</dd>",type2)ssg(typep,7,type2,type)s(type2 + 6,type2)ssg(typep,type2,typep)//2.得到语言languagesiof(typep,"<dd>语言",language1)s(language1 + 7,language1)siof(typep,"</dd>",language2)ssg(typep,language1,language2,language)s(language2 + 6,language2)ssg(typep,language2,languagep)//3.得到更新日期datesiof(languagep,"更新日期",date1)s(date1 + 5,date1)siof(languagep,"</dd>\n</dl>",date2)ssg(languagep,date1,date2,date)//第三步:获取游戏介绍introduces sign="<div class="container">"siof(origin,sign,introduce1)s(introduce1 + 500,introduce2)s(introduce1 + 24,introduce1)ssg(origin,introduce1,introduce2,introducep)siof(introducep,"</div>",introducepl)ssg(introducep,0,introducepl,introduce)//第四步:获取评论commentalls sign = "<ul class="commentList">"siof(origin,sign,comment1)s(comment1 + 26,comment1)s signa = "<p class="more"><a target=\"_blank"siof(origin,signa,comment2)ssg(origin,comment1,comment2,comment)//评论处理,调用循环sr(comment,"<li>"," ",comment)sr(comment,"</li>"," ",comment)sr(comment,"</h4>"," ",comment)siof(comment,"<h4>",commentst)s order = 0s commentall = ""w(commentst != -1){//获取评论用户名s(commentst + 4,commentst)siof(comment,"评论于",commenten)ssg(comment,commentst,commenten,username)s(commenten + 3,commenten)ssg(comment,commenten,comment)//获取评论时间commenttimesiof(comment,"<span>",commenttimest)s(commenttimest + 6,commenttimest)siof(comment,"</span>",commenttimeen)ssg(comment,commenttimest,commenttimeen,commenttime)s(commenttimeen + 9,commenttimeen)ssg(comment,commenttimeen,comment)//获取评论内容commentcontentsiof(comment,"<p>",commentcontentst)s(commentcontentst + 3,commentcontentst)siof(comment,"</p>",commentcontenten)ssg(comment,commentcontentst,commentcontenten,commentcontent)s(commentcontenten + 9,commentcontenten)ssg(comment,commentcontenten,comment)//循环关键s(order + 1,order)siof(comment,"<h4>",commentst)//评论组合ss(order + ". " + username + " " + commentcontent + "(" + commenttime + ")" + "\n" + "\n",commentsum)ss(commentall + commentsum,commentall)}//第五步:创建文件夹(包含创建游戏详情)s head = "windows/BstSharedFolder/Gaoithe/javagame/"s bl = " "ss(javanum + "." + name + bl + type + bl +language + bl + date + "/",body)ss("游戏名:" + name + "\n" + "类型:" + type + "\n",p1)ss("语言:" + language + "\n" + "游戏介绍:" + introduce + "\n",p2)ss("评论:" + "\n" + commentall + "\n" + "更新日期:" + date + "\n",p3)ss(p1 + p2 + p3,information)ss(head + body + "游戏介绍.txt",file)fw(file,information)//第六步:获取介绍图siof(origin,"7723网游群",pic1)siof(origin,"如何下载到手机",pic2)ssg(origin,pic1,pic2,pic)siof(pic,"src=",picwebst)s(picwebst + 5,picwebst)siof(pic,"alt=",picweben)s(picweben - 2,picweben)ssg(pic,picwebst,picweben,picweb)slof(picweb,".",add1)s(add1 + 1,add1)ssg(picweb,add1,add)f(add!="jpg" && add!="png" && add!="gif" && add!=null){ss(head + body + "缺少介绍图.text",filepic)fw(filepic,"lack")}f(add == "jpg"){ss(head + body + "介绍图.jpg",file)t(){hd(picweb,file,true,picreturn)f(picreturn==-1){ss(head + body + "缺少介绍图.text",filepic)fw(filepic,"lack")} }stop(100)}else{f(add == "gif"){ss(head + body + "介绍图.gif",file)t(){hd(picweb,file,true,picreturn)f(picreturn==-1){ss(head + body + "缺少介绍图.text",filepic)fw(filepic,"lack")}}stop(100)}else{f(add=="png") {ss(head + body + "介绍图.png",file)t(){hd(picweb,file,true,picreturn)f(picreturn==-1){ss(head + body + "缺少介绍图.text",filepic)fw(filepic,"lack")}} stop(100) } } }//第七步:获取截图siof(origin,"<h3>游戏截图</h3>",gamepic1)siof(origin,"<h3>游戏下载</h3>",gamepic2)ssg(origin,gamepic1,gamepic2,gamepictext)siof(gamepictext,"src=",gamepicwebst)s order = 1w(gamepicwebst != -1){s(gamepicwebst + 5,gamepicwebst)siof(gamepictext,"nbsp",gamepicweben)s(gamepicweben - 4,gamepicweben)ssg(gamepictext,gamepicwebst,gamepicweben,gamepicweb)slof(gamepicweb,".",add1)s(add1 + 1,add1)ssg(gamepicweb,add1,add)f(add!="jpg" && add!="png" && add!="gif" && add!=null){ ss(head + body + "缺少截图.text",filepic)fw(filepic,"lack") }f(add == "jpg"){ss(head + body + "截图" + order + ".jpg",file)t(){hd(gamepicweb,file,true,gamepicreturn)f(gamepicreturn==-1){ss(head + body + "缺少截图.text",filepic)fw(filepic,"lack")}}stop(100)}else{f(add == "gif"){ss(head + body + "截图" + order + ".gif",file)t(){hd(gamepicweb,file,true,gamepicreturn)f(gamepicreturn==-1){ss(head + body + "缺少截图.text",filepic)fw(filepic,"lack")}}stop(100)} else{f(add=="png") {ss(head + body + "截图" + order + ".png",file)t(){hd(gamepicweb,file,true,gamepicreturn)f(gamepicreturn==-1){ss(head + body + "缺少截图.text",filepic)fw(filepic,"lack")}}stop(100) } } }s(order + 1,order)s(gamepicweben + 10,gamepicweben)ssg(gamepictext,gamepicweben,gamepictext)siof(gamepictext,"src=",gamepicwebst)}//第八步:获取java文件//获取下载文本部分siof(origin,"<h3>游戏下载</h3>",gamedownload1)siof(origin,"<h3>手机用户评论",gamedownload2)ssg(origin,gamedownload1,gamedownload2,gamedownloadtext)siof(gamedownloadtext,"<li>",gamedownloadtext1)ssg(gamedownloadtext,gamedownloadtext1,gamedownloadtext)//获取软件适用机型及分辨率siof(gamedownloadtext,"<p>",gamedownloadtypest)s downnum=1 //防止重复覆盖w(gamedownloadtypest != -1){s(gamedownloadtypest + 3,gamedownloadtypest)siof(gamedownloadtext,"<br /",gamedownloadtypeen)ssg(gamedownloadtext,gamedownloadtypest,gamedownloadtypeen,gamedownloadtype)//获取下载地址siof(gamedownloadtext,"href=",gamewebst)s(gamewebst + 6,gamewebst)siof(gamedownloadtext,"target",gameweben)s(gameweben - 2,gameweben)ssg(gamedownloadtext,gamewebst,gameweben,gameweb)//获取文件后缀名siof(gamedownloadtext,"点击下载",gameadd1)s(gameadd1 + 5,gameadd1)siof(gamedownloadtext,"nbsp",gameadd2)s(gameadd2 - 2,gameadd2)ssg(gamedownloadtext,gameadd1,gameadd2,gameadd)//下载文件ss(head + body + gamedownloadtype + downnum + "." + gameadd,file)t(){hd(gameweb,file,false,gamedownloadreturn)}stop(200)//循环关键siof(gamedownloadtext,"<br /></p>",cuttext)s(cuttext + 20,cuttext)ssg(gamedownloadtext,cuttext,gamedownloadtext)siof(gamedownloadtext,"<p>",gamedownloadtypest)s(downnum+1,downnum)}//ufnsui()
// {// us(1,"text",gameadd)// }stop(3000)s(javanum + 1,javanum)} }4. 文件预览:
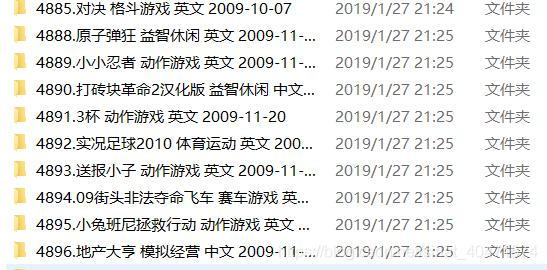
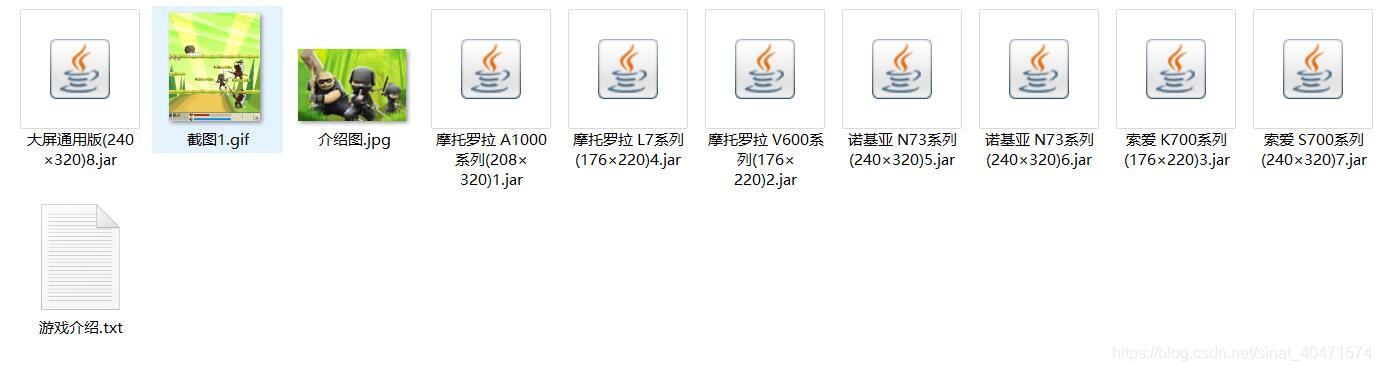
注意:由于软件是用模拟器跑的,所以使用时注意更改路径。
这篇关于用iApp写爬虫(手动滑稽)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






