本文主要是介绍单挑力扣(LeetCode)SQL题:1951. 查询具有最多共同关注者的所有两两结对组(难度:中等),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目:1951. 查询具有最多共同关注者的所有两两结对组
(通过次数2,464 | 提交次数3,656,通过率67.40%)
表: Relations
+-------------+------+
| Column Name | Type |
+-------------+------+
| user_id | int |
| follower_id | int |
+-------------+------+
(user_id, follower_id) 是这个表的主键.
这个表的每一行,表示这个user_id的用户和他的关注者,关注者的id 就是本表的 user_id.写出一个查询语句,找到具有最多共同关注者的所有两两结对组。换句话说,如果有两个用户的共同关注者是最大的,我们应该返回所有具有此最大值的两两结对组
结果返回表,每一行应该包含user1_id和?user2_id,其中user1_id < user2_id.
返回结果不要求顺序。查询结果格式如下例:
Relations 表:
+---------+-------------+
| user_id | follower_id |
+---------+-------------+
| 1 | 3 |
| 2 | 3 |
| 7 | 3 |
| 1 | 4 |
| 2 | 4 |
| 7 | 4 |
| 1 | 5 |
| 2 | 6 |
| 7 | 5 |
+---------+-------------+Result 表:
+----------+----------+
| user1_id | user2_id |
+----------+----------+
| 1 | 7 |
+----------+----------+用户1 和用户 2 有2个共同的关注者(3和4)。
用户1 和用户 7 有3个共同的关注者(3,4和5)。
用户2 和用户7 有2个共同的关注者(3和4)。
既然两两结对的所有组队的最大共同关注者的数值是3,所以,我们应该返回所有拥有3个共同关注者的两两组队,这就是仅有的一对(1, 7).
我们返回的是(1, 7).,而不是(7, 1).
注意,我们没有关于用户3,4,5的任何关注者信息,我们认为他们有0个关注者。来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/all-the-pairs-with-the-maximum-number-of-common-followers#测试数据
Create table If Not Exists Relations (user_id int, follower_id int);
insert into Relations (user_id, follower_id) values ('1', '3');
insert into Relations (user_id, follower_id) values ('2', '3');
insert into Relations (user_id, follower_id) values ('7', '3');
insert into Relations (user_id, follower_id) values ('1', '4');
insert into Relations (user_id, follower_id) values ('2', '4');
insert into Relations (user_id, follower_id) values ('7', '4');
insert into Relations (user_id, follower_id) values ('1', '5');
insert into Relations (user_id, follower_id) values ('2', '6');
insert into Relations (user_id, follower_id) values ('7', '5');解题思路:
从67.40%的通过率上来看,这道题确实只能算是个中等题。
但是再一看提交次数,截至目前,只有区区3656个。
与之前的题目,动辄上万,甚至上十万的提交次数相比,真的是少的可怜。
不知道是不是因为有部分小伙伴,看到这道题就直接放弃了。
从难度上来说,确实还是有一些的。强哥也思考了5分钟没有头绪。
最后从题目描述“两两结对的所有组队的最大共同关注者”里的“两两结对”的描述,才找到灵感。
什么叫两两结对?无非就是两两对比。两两怎么对比?最简单的理解,就是把两边的数据,拉到同一行,再进行对比。
看完这个描述,是不是觉得很眼熟?这不就是笛卡尔嘛!
如果把表Relations做自关联,不带关联条件的话,那么就实现了两两结对,然后分别算出每一对的共同关注数,并取出共同关注数最大的那一对,是不是就可以了?
比如,1的关注者(1,3),(1,4),(1,5)与2的关注者(2,3),(2,4),(2,6)的共同关注数怎么计算呢?
直接看,可能不直观,我们使用表格看一下。
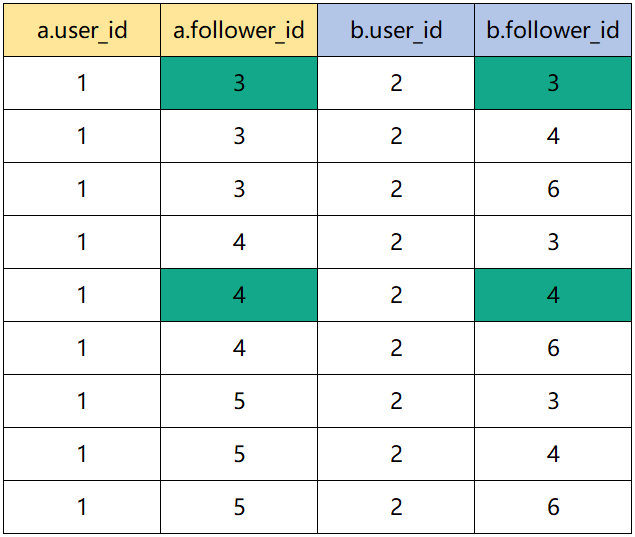
这样看,是不是就很直观了?
把1和2的笛卡尔积的结果,过滤出相同的follower_id,然后以a.user_id和b.user_id分组计数就可以了。
selecta.user_id,b.user_id,count(*) cn
from Relations a
inner join Relations b
on a.follower_id = b.follower_id
group by a.user_id,b.user_id;上面的SQL,可以计算出两两用户之间的共同关注数,有了这个结果,相信再排序得出共同关注数最多的组合,就不是什么难事了。
当然,如果你执行过上面的SQL,可能会发现返回了一些奇怪的结果。比如,用户1与它自身的共同关注数;再比如,用户1和2的结果会出现(1,2)和(2,1)两个组合,而两个组合的共同关注数是一样的。
不过,简单分析一下,做个过滤,相信很容易就可以把这些数据剔除了。
参考SQL:
select user1_id,user2_id
from (select user1_id,user2_id,rank() over(order by cn desc) rkfrom (selecta.user_id user1_id,b.user_id user2_id,count(*) cnfrom Relations ainner join Relations bon a.user_id < b.user_idand a.follower_id = b.follower_idgroup by a.user_id,b.user_id)a
)b
where b.rk = 1;这篇关于单挑力扣(LeetCode)SQL题:1951. 查询具有最多共同关注者的所有两两结对组(难度:中等)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






