本文主要是介绍【对Adaptive Federated Dropout的解读】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
对Adaptive Federated Dropout的解读
- 前言
- 一、AFD是什么?
- 二、AFD主要使用的技术
- 1.Activations Score Map——激活分数图
- (1)Multi-Model Adaptive Federated Dropout
- (2)Single-Model Adaptive Federated Dropout
- 2.DGC(Deep Gradient Compression——深度梯度压缩)
- (1)Gradient Sparsification
- (2)Momentum Correction
- (3)Local Gradient Clipping
- (4)Momentum Factor Masking
- (5)Warm-up Training
- 3.The FederatedAveraging Algorithm——联邦平均算法
- (1)联邦平均算法是什么
- (2)联邦平均算法实现过程
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
问题:联邦学习服务器需要和客户端经常通信,服务器需要给客户端发送全局模型,而全局模型一般很大,通信过程主要由发送时间和传输时间组成,发送时间主要由要发送的数据大小和带宽决定,发送的数据量越大,时间越长,带宽越大,时间越短,而传输时间主要和距离有关,对比发送时间来说,传输时间要小很多,所以联邦学习的主要通信瓶颈是由发送时间引起的。
解决:大多解决方法都是通过增加服务器额外的计算量来减少通信次数,进而减少通信时间,比如联邦平均算法,通过计算高质量的更新来减少通信次数,从而减少联邦学习的通信时间,但是从服务器下载大型模型还是对客户端有很大负担。
如此,博主详读了AFD(Adaptive Federated Dropout:Improving Communication Efficiency and Generalization for Federated Learning——自适应联邦Dropout:提高联邦学习的通信效率和泛化)这篇文章
提示:以下是本篇文章正文内容,下面案例可供参考
一、AFD是什么?
AFD主要是解决联邦学习客户端需要从服务器下载庞大的全局模型问题,通过使用激活分数图构建一个子模型,然后压缩这个子模型来减少客户端和服务器之间交换的模型的大小。这个压缩的子模型被发送到客户端,客户端对它进行解压,使用它的数据进行本地训练,之后压缩更新的子模型,然后发送回服务器。服务器对各个被压缩的子模型解压,恢复到原来的形状,最后与其他更新的模型聚合到全局模型中。
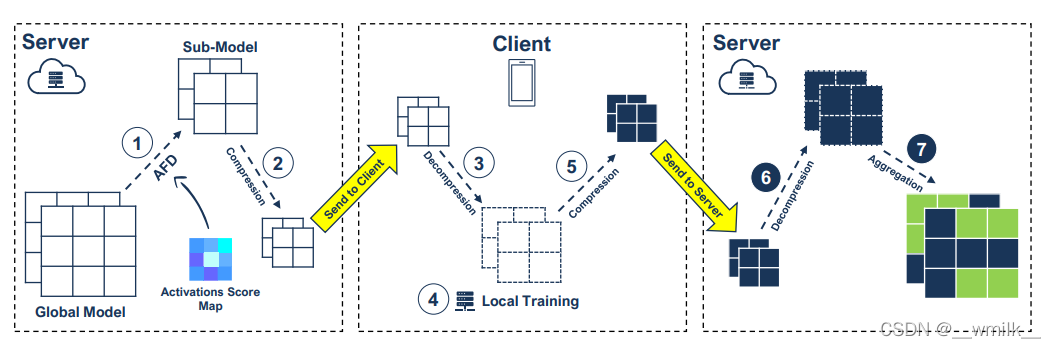
二、AFD主要使用的技术
1.Activations Score Map——激活分数图
子模型是全局模型的子集,通过从卷积层和全连接层的激活中去除固定百分比的过滤器来构建子模型。不是随机删除一部分神经元,而是维护一个激活分数图,以确定应该选择哪些过滤器来删除。每个评分图分配了所有激活的真实值,代表了它们对训练过程的重要性和影响。
那么,如何来构建激活分数图呢?文章提出了两种方法。
(1)Multi-Model Adaptive Federated Dropout
该策略使服务器能够为每个客户端保留不同的激活评分图。在每一轮中,服务器为每一个选定的客户端发送一个不同的子模型,并根据本地损失函数更新每个客户端对应的得分图。

此方法为每个客户端定制一个唯一的激活分数图,在每次学习轮次结束后,服务器会随机挑选一部分客户端更新它们的激活分数图。
(2)Single-Model Adaptive Federated Dropout
多模型存在一个问题,在每一轮只有一部分客户端进行更新,使得算法行为随机。并且多模型为每个客户端保持一个独立的激活评分图。如果某些客户端被选出训练次数较少,激活分数图更新不够频繁,就无法准确反映激活重要性的得分。
由此,作者又介绍了另一种方法——单模型自适应联邦Dropout。此方法在每一轮中为所有选定的客户端创建相同的子模型。在这个分数图的基础上,将创建一个单一的子模型,并在特定的培训回合中分发给所有客户。这个单分数图将以类似于多模型的方式更新。但是使用从随后的培训中选出客户的连续平均损失来更新其值,而不是局部损失。

此方法让所有客户端使用唯一一个激活分数图,但是在更新时随机选取一部分的客户端来更新此分数图,这解决了第一种方法某些客户端的分数图更新频率慢的问题。
2.DGC(Deep Gradient Compression——深度梯度压缩)
文中提到在选取子模型之后并不是直接发送,而是经过压缩然后在发送到链路上,使用的压缩方法便是深度梯度压缩。
DGC使用梯度稀疏化压缩梯度来解决通信带宽问题。为了保证不损失精度,DGC在梯度稀疏化的基础上采用动量修正和局部梯度裁剪来保持模型性能。DGC还利用动量因子掩蔽和热身训练来克服交流减少带来的陈旧问题。
(1)Gradient Sparsification
通过只发送重要的梯度(稀疏更新)来减少通信带宽。使用梯度大小作为重要程度的简单启发式:只有大于阈值的梯度才会被传输。为了避免丢失信息,将剩余的梯度在局部累加。最终,这些梯度变得足够大,就可以被传输。因此,可以立即发送大的梯度,但最终将随着时间推移发送所有的梯度。
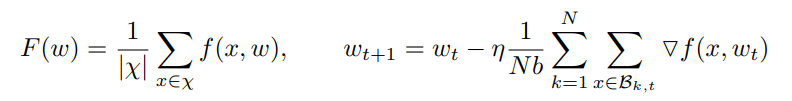
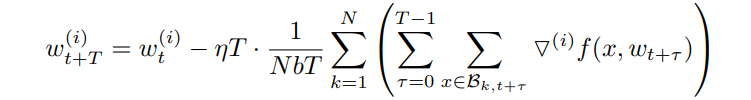
χ是某个客户端的训练数据集,w是一个网络的权重,f (x, w)是计算从样本x∈χ训练的损失,η是学习速率,N是客户端的数量,Bk, t 是t时刻第k个客户端的数据集,1≤k < N,将Bk,t分为很多分,每份大小b。
第一张图的第一个公式是某个个客户端的平均损失函数;第二个公式是t+1时刻的神经网络权重值。第二张图的公式是模型的第i个区域的权重值,梯度稀疏化方法以此来计算出模型每个区域的权重值然后和所设置的阈值进行比较,最终确定那些是重要梯度。
(2)Momentum Correction
动量修正是为了解决模型训练收敛慢的问题。
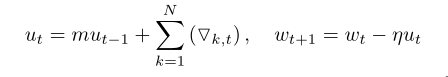
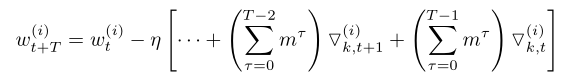
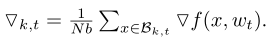
第一张图的两个公式是动量SGD优化方法。将他们展开后就是第二张图的公式(博主尝试展开,但是展开式损失函数值前的系数是连乘而不是连加,不知道文章为什么得出连加)。第二这张图展示的是动量SGD优化方法在不使用梯度稀释化方法的情况下的正常更新。
以下两张图片的公式是动量SGD优化方法直接使用梯度稀疏化的情况下的更新。
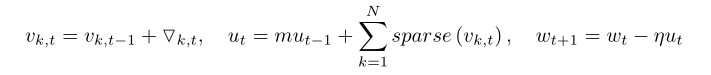
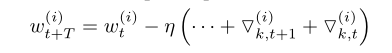
第二张图的公式相较于正常更新的情况下,每个损失函数前少了动量系数。因此便会引起模型训练收敛慢的问题。如下图。
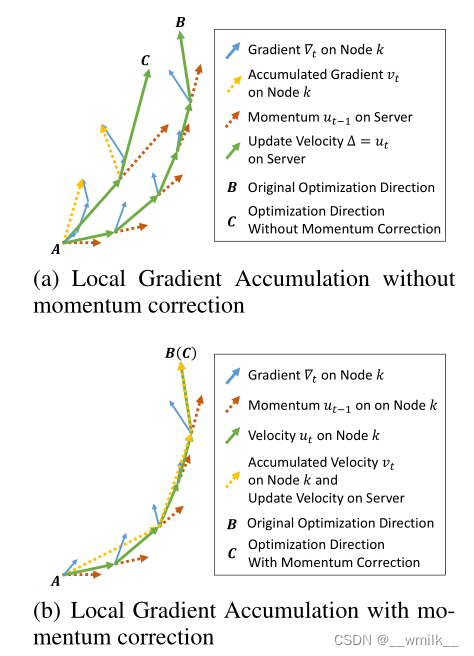
所以,必须引入动量修正使动量SGD在使用梯度稀疏化的情况下权重更新正常化。
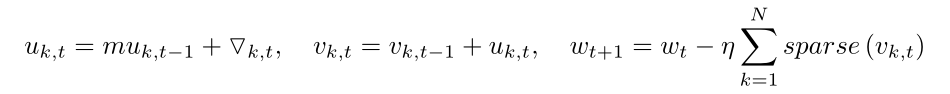
上图公式是对动量SGD直接梯度稀释化公式做了调整,并没有引入额外的超参数,并且解决了收敛慢的问题。
(3)Local Gradient Clipping
梯度裁剪被广泛采用以避免梯度爆炸问题。这个步骤通常在所有节点的梯度聚合之后执行。由于深度梯度压缩在每个节点上独立地通过迭代累积梯度,所以在将当前梯度添加到之前的累积之前,需要在局部执行梯度裁剪。此方法解决由于多次迭代而未能发送的不重要梯度在本地累计造成的梯度爆炸问题。
(4)Momentum Factor Masking
动量因子遮蔽是为了消除本地累计的不重要梯度。在不重要梯度累计到阈值之后被发送出去,那这些梯度就不能被用来添加到下一次迭代中,所以需要对这些累计梯度进行本地删除。
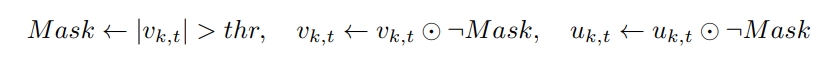
(5)Warm-up Training
在训练的早期阶段,网络变化迅速,梯度更加多样化和侵略性。稀疏梯度限制了模型的变化范围,从而延长了网络剧烈变化时的周期。同时,早期剩余的积极梯度会在下次更新之前积累起来,因此它们可能会超过最新的梯度,并误导优化方向。在大规模小批量训练中引入的热身训练方法是有帮助的。在热身阶段,使用较低的主动学习率来减缓神经网络在训练开始时的变化速度,也使用较低的主动梯度稀疏性,以减少被延迟的极端梯度的数量。我们不是在前几个阶段线性增加学习速率,而是将梯度稀疏度从一个相对较小的值指数增加到最终值,以帮助训练适应更大的稀疏度的梯度。此方法是考虑到那些不重要梯度没有发送而导致数据缺失问题,为了减小数据缺失带来的影响,所以一开始使用较少数据来训练,减慢训练收敛时间,以等待完全的全局模型的接收。
3.The FederatedAveraging Algorithm——联邦平均算法
文章在实验阶段使用了这个算法。
(1)联邦平均算法是什么
每个客户端使用本地数据对当前模型进行一步梯度下降,然后服务器对结果模型进行加权平均。一旦算法以这种方式编写,我们就可以在平均步骤之前,通过多次迭代本地更新,为每个客户端增加更多的计算量。我们称这种方法为联邦平均算法。
(2)联邦平均算法实现过程

在客户端,每个客户端将本地数据集划分为多个区域,然后使用一部分数据集来训练模型,并且在本地迭代训练多次,然后将梯度发给服务器。
在服务器端,没轮服务器随机选择一部分客户端,对他们的梯度进行加权平均,然后来算出下一轮的梯度值。
在这里没有讲清楚每个客户端的权重怎么选取,在源代码中有所体现。
def average_model(self, sampled_client_indices, coefficients):"""Average the updated and transmitted parameters from each selected client."""message = f"[Round: {str(self._round).zfill(4)}] Aggregate updated weights of {len(sampled_client_indices)} clients...!"print(message); logging.info(message)del message; gc.collect()averaged_weights = OrderedDict() #Weighted weights for each client gradientfor it, idx in tqdm(enumerate(sampled_client_indices), leave=False):local_weights = self.clients[idx].model.state_dict()for key in self.model.state_dict().keys():if it == 0:averaged_weights[key] = coefficients[it] * local_weights[key]#此为加权梯度else:averaged_weights[key] += coefficients[it] * local_weights[key]self.model.load_state_dict(averaged_weights)
# calculate averaging coefficient of weightsmixing_coefficients = #此为权重系数[len(self.clients[idx]) / selected_total_size for idx in sampled_client_indices]#print(type(mixing_coefficients)) #its type is list# average each updated model parameters of the selected clients and update the global modelself.average_model(sampled_client_indices, mixing_coefficients)
averaged_weights[key] = coefficients[it] * local_weights[key]为每个客户端的平均权重,local_weights是
算法实验过程中的t+1时刻第k个客户端的梯度,coefficients则是权重系数。
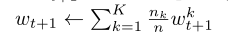
由mixing_coefficients = len(self.clients[idx]) / selected_total_size 可以看出每个客户端的权重系数是每个客户端上传数据大小与所有客户端上传数据大小的比值。
总结
为了解决联邦学习中通信所传模型过大问题,文章使用激活分数图,根据它来选择全局模型的子集进行发送,并提出Multi-Model Adaptive Federated Dropout和Single-Model Adaptive Federated Dropout两种方法来更新激活分数图,然后更进一步地使用了深度梯度压缩来压缩子集的大小,最后再结合联邦平均算法,以此来更多地减少联邦学习所需要花费的通信时间,提高通信效率。
这篇关于【对Adaptive Federated Dropout的解读】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








