本文主要是介绍使用克魔助手进行iOS数据抓包和HTTP抓包的方法详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
本文博客将介绍如何在iOS环境下使用克魔助手进行数据抓包和HTTP抓包。通过抓包,开发者可以分析移动应用程序的网络请求发送和接收过程,识别潜在的性能和安全问题,提高应用的质量和安全性。
引言
在移动应用程序的开发和测试过程中,对网络请求的调试和分析是至关重要的。通过抓包,开发者可以监听和分析应用程序发送和接收的网络请求,发现潜在的性能和安全问题。克魔助手提供了数据抓包和HTTP抓包两种方式,本文将详细介绍这两种方式的配置和使用方法,帮助开发者更好地进行网络请求的调试和分析。

数据抓包
在克魔助手中,首先通过数据线连接电脑和手机,然后在控制台的左侧工具栏要选择进行数据包的App,并点击“开始抓包”。这样就可以生成该App的抓包数据包,包括源端口、目的端口、源地址、协议等。用户还可以对抓包的数据进行过滤操作,选择需要的数据进行存储,方便后续的分析和调试。克魔助手抓包分为数据抓包和HTTP抓包两种方式。下面我们将详细介绍这两种方式。
APP过滤

数据过滤
此外 还可以对抓包的数据进行过滤操作,选择需要的数据进行存储。

HTTP抓包
抓取HTTPS请求,通常是通过在PC端安装mitmproxy证书。 通过设置为iOS设备信任mitmproxy证书,实现对HTTPS流量的中间人攻击并解密。
具体步骤如下:
1.魔助手中进行如下设置:点击“开始抓包”,然后点确定。

将会提示是否选取设备安装此描述文件

安装证书步骤: 首先到手机设置找到>已下载描述文件,然后点击安装“mitmproxy证书”。




信任证书步骤:
首先到手机“设置”找到“通用”,然后点击进入“关于本机”,下一步到“信任根设置”,然后点击“信任根证书 mitmproxy”。




配置代理步骤: 首先找到手机“设置” 然后点击WiFi,找到最右侧的按钮,在选项上的“配置代理”中,选择“手动”,然后输入跟电脑一样的服务器号和端口号



配置完成后即可查看抓包的http数据,除此之外还可以看到的数据:请求头(常规,响应标头,请求标头),响应数据,负载数据

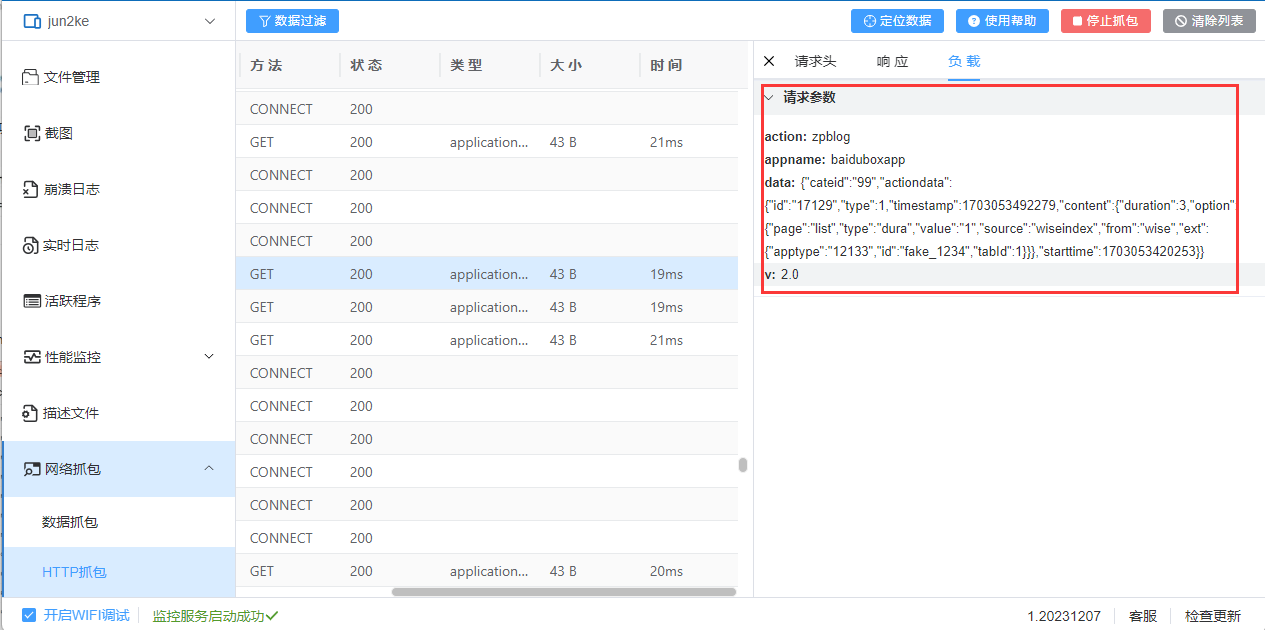
ps:请保持设备与电脑连接的是相同的Wi-Fi>
这篇关于使用克魔助手进行iOS数据抓包和HTTP抓包的方法详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









