本文主要是介绍爬虫实战——爬百思不得姐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
看完了爬虫的入门之后,想实战一下,于是找了一个段子网站——百思不得姐,爬一下段子:
首先进入到 http://www.budejie.com/text/,里面全部是段子,暂时只把段子爬下来,不爬图片,打开页面查看源代码:
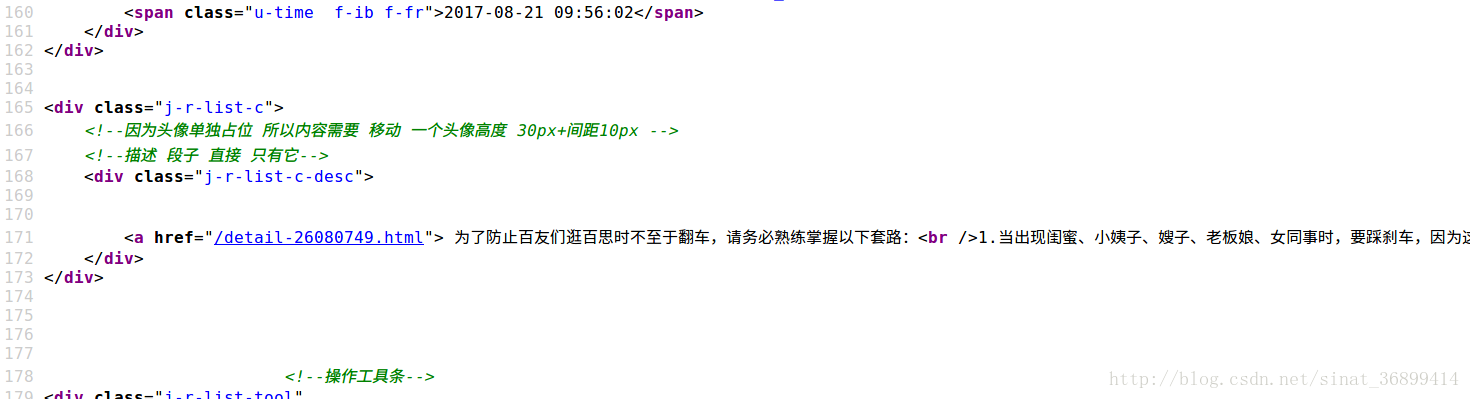
发现段子都在类似于这样 <a href="(/detail-3242432.html)">段子</a> 的结构中,
于是我们有办法了,把段子在的地方放入正则表达式reg = re.compile(r'<a href="(/detail-.*?)">(.*?)</a>')
点赞的人数也是重复上面的过程:

正则表达式reg = re.compile(r'<i class="icon-up ui-icon-up"></i> <span>(.*?)</span>
代码如下:
# encoding: utf-8
import urllib2
import redef getduan():url = 'http://www.budejie.com/text/'user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'#代理headers = {'User-Agent': user_agent}request = urllib2.Request(url, headers=headers)response = urllib2.urlopen(request)res = response.read()reg = re.compile(r'<a href="(/detail-.*?)">(.*?)</a>')return re.findall(reg, res)def up():url = 'http://www.budejie.com/text/'user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'headers = {'User-Agent': user_agent}request = urllib2.Request(url, headers=headers)response = urllib2.urlopen(request)res = response.read()reg = re.compile(r'<i class="icon-up ui-icon-up"></i> <span>(.*?)</span>')return re.findall(reg, res)if __name__ == '__main__':d = zip(getduan(), up())d = dict(d)count = 0for j, i in d.items():print '段子', (count+1),j[1]count = count+1print 'up人数:',i
这里用到了代理,为了防止反爬虫,环境是python2.7,最后得到的效果如图:

非常简单的爬虫没有用任何框架,接下来会用框架解决爬虫问题,请继续关注。
这篇关于爬虫实战——爬百思不得姐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






