本文主要是介绍Python 在工业生产规划中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在制造业中,往往会因为数据结构的复杂(系统+线下,订单+制造等等)以及对接口的繁多,在进行数据处理、可视化、业务判断方面会消耗大量精力。这点尤其是在当今客户需求多样化的时代显得尤为突出。客户多样的需求,少则小几十条,多则上百条。如何整合现存资源、未来资源、长远资源以满足业务需求,和运营、成本达到平衡显得十分重要。
在我实际操作的过程中,系统能解决一部分问题。但随着业务量的增长和精细化,很多时候我们需要做出最快的响应,模拟出最优化的解决方案。因这些需求很多情况是新增的,甚至是临时的,因此,若完全依赖系统,会因为开放周期较长、资源等原因,不一定能100%相应到业务的变化和调整。
相较之下,对数据源方面进行扩充,增加新的数据内容是相对容易很多的,将这些数据根据实际的业务需求,进行处理、筛选、计算,做成相应的模板,可以大大提高工作效率和精准度,通过模拟计算,及时响应到业务需求。
单独拿“生产—销售”来说,我们要关心的问题有,目前的订单现有情况、订单未来情况、现有的资源情况、即将产生的资源情况,在拿到这些信息后,进行匹配、测试、通过调整,演算出可能产生的结果。最传统的模式是通过Excel进行计算和传递。但随着业务量的增长和客户需求的多样化,仅仅用excel很难跟上业务需求,单纯的某一次运算,都会花费大量的时间。但借助Python的运算,能在极短的时间内产生出大量我们想要的结果。
在用python进行计算时,主要需要的有以下几个步骤。
车同轨书同文
这一点是一切运算的基石和前提。在生产规划中,我们的数据源多种多样,有销售方的,有制造方的,有库存方的等等。这些数据往往是不对称的。比如同一种商品,销售方成为A,制造方称为B,库存方称为C。就好比《海贼王》在不同平台叫法不一是同一个道理,在腾讯就叫《航海王》;比如因翻译不同,《宝可梦》、《宠物小精灵》、《口袋妖怪》、《神奇宝贝》说的实际上是一个东西。在生产—销售中也存在这样的问题。只有统一了名称,我们才能在各个平台间达成共识,以确保信息的对称性。解决这个问题的方法,就是给每一种商品特定的ID,就跟身份证一样。
只有统一的ID,才能把所有的商品给串起来。
但有时候,可能会因为产品的更迭,导致同一种商品,在今年和去年拥有2个ID,所以,我们也需要格外注意把新老ID也统一起来。
以上说的从商品的种类角度出发。当涉及到具体的某个订单对应到某个商品时,我们还需要给每个商品和每个订单给予特定的ID,以进行匹配。
Again,以上的统一,是可以通过EXCEL来实现的,但会存在运算复杂,而影响效率的情况。尤其是当数据量暴增时,常常会出现excel转圈圈的情况,更别说后面我们还需要进行更加复杂的运算(当然换个电脑也不是不行)。
建立常用数据库
这点和上一步的车同轨书同文其实同样重要,优先级甚至可以说不分先后。在python上统一ID有两种方法。一种是直接写入代码,比如A商品对应的ID是12345678,B商品对应的ID是23345678……。但显然这不是最优解。因为如果要新增另一模块的代码时,就会要求我们在另一个模块把这段代码添加进去,当新增模块多的时候,难免会有疏漏。
因此,在实际操作中,建立自己的数据库是最优化的方式。我们仅仅通过更新数据库,在代码中调用这个数据库就可以了。完全节省每个模块都更新代码的工作量,不仅如此,还能极大的提升准确率。
业务分析的优先级
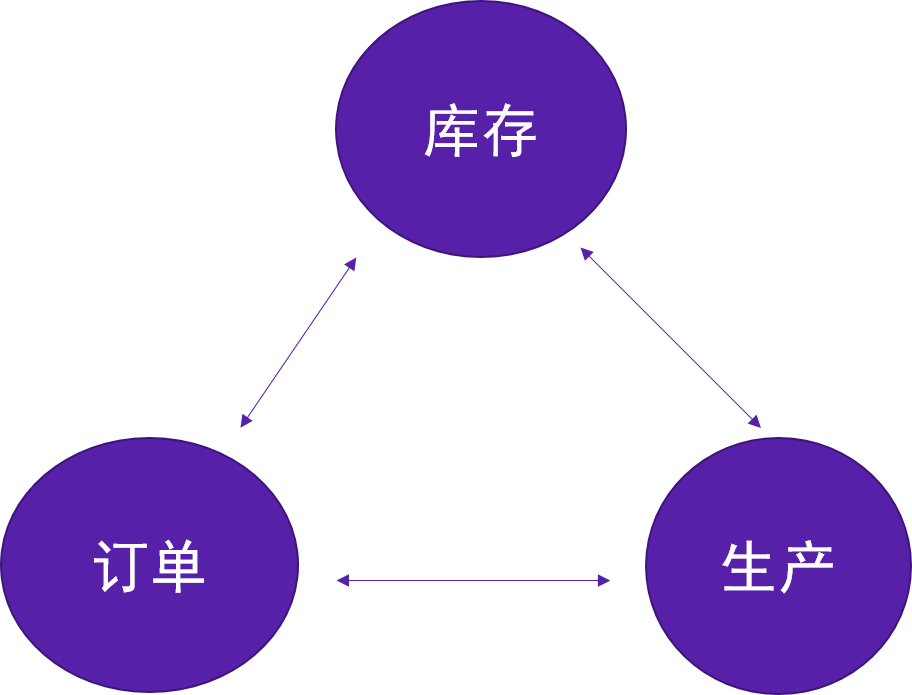
在进行完上面两个步骤后,我们才能进一步的到业务分析的模块。在对业务进行分析时,同样会有优先级,当然也会有不影响的并行情况存在。但如果是我们要总结所有资源来进行模拟分析时,这种并行的情况就会越来越少,所有的资源可以理解成一个生态系统(订单、商品、库存、生产等等),当一个部分的某一个点发生变化后,都会影响整个生态。只不过是影响多少的问题。当资源盘大时,某一个点变化对生态的影响微乎其微,但当资源有限时,即使蝴蝶扇一下翅膀,都会对整个生态产生巨大影响。1对于1000的影响只是0.1%,但对10的影响就是10%了。
因此,在资源有限的情况下,我们要更加关注精确性。
那我们应该如何对资源进行演算和分配优先级呢?先锁定变化比较慢或者相对容易控制的模块,在进一步推进变化稍微快一些的模块,把变化最快的放在最后再进行演算。举个形象的例子,先分析行动最慢的树懒,最后再分析速度最快的猎豹。当然这里的树懒和猎豹是相对的。根据实际情况的不同,树懒有时会是猎豹,猎豹有时会是树懒。
落脚到实际业务,在计算的过程中,优先级便是先库存、再生产、再订单。值得注意的是,这里的优先级并不是指先把库存分析的透透的,过一段时间再分析生产,再分析订单。这里的优先级,是指运算次序上的优先级。先算库存、再算生产、再算订单,实际上,在最后还会通过订单再倒推库存、生产。在时间的维度上,这几方面是可以看成是同时进行的。
那通过运用python,能达到什么效果呢?可以说,想得到什么样的效果完全取决于业务的需求,想达到什么样的效果都可以实现。比如我现在得到的,能通过这一系列的分析,1min就能得到10张想要的报表。这些报价表或独立,或相关。再进一步,我们可以通过可视化软件(如tableau),将这些报表的展现形式做成模板,以实现自动输出。
这篇关于Python 在工业生产规划中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





