本文主要是介绍深入 K8s 网络原理(一)- Flannel VXLAN 模式分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 概述
这周集中聊下 K8s 的集群网络原理,我初步考虑分成3个方向:
-
Pod-to-Pod通信(同节点 or 跨节点),以 Flannel VXLAN 模式为例;
-
Pod/External-to-Service通信,以 iptables 实现为例;
-
Ingress原理,以 NGINX Ingress Controller 实现为例;
-
其他:(到时候看心情)Flannel host-gw 模式,Calico,……
今天先介绍下 Flannel 实现 Pod 跨节点通信的原理。
2. TL;DR
我知道你们着急,这样吧,先看图:
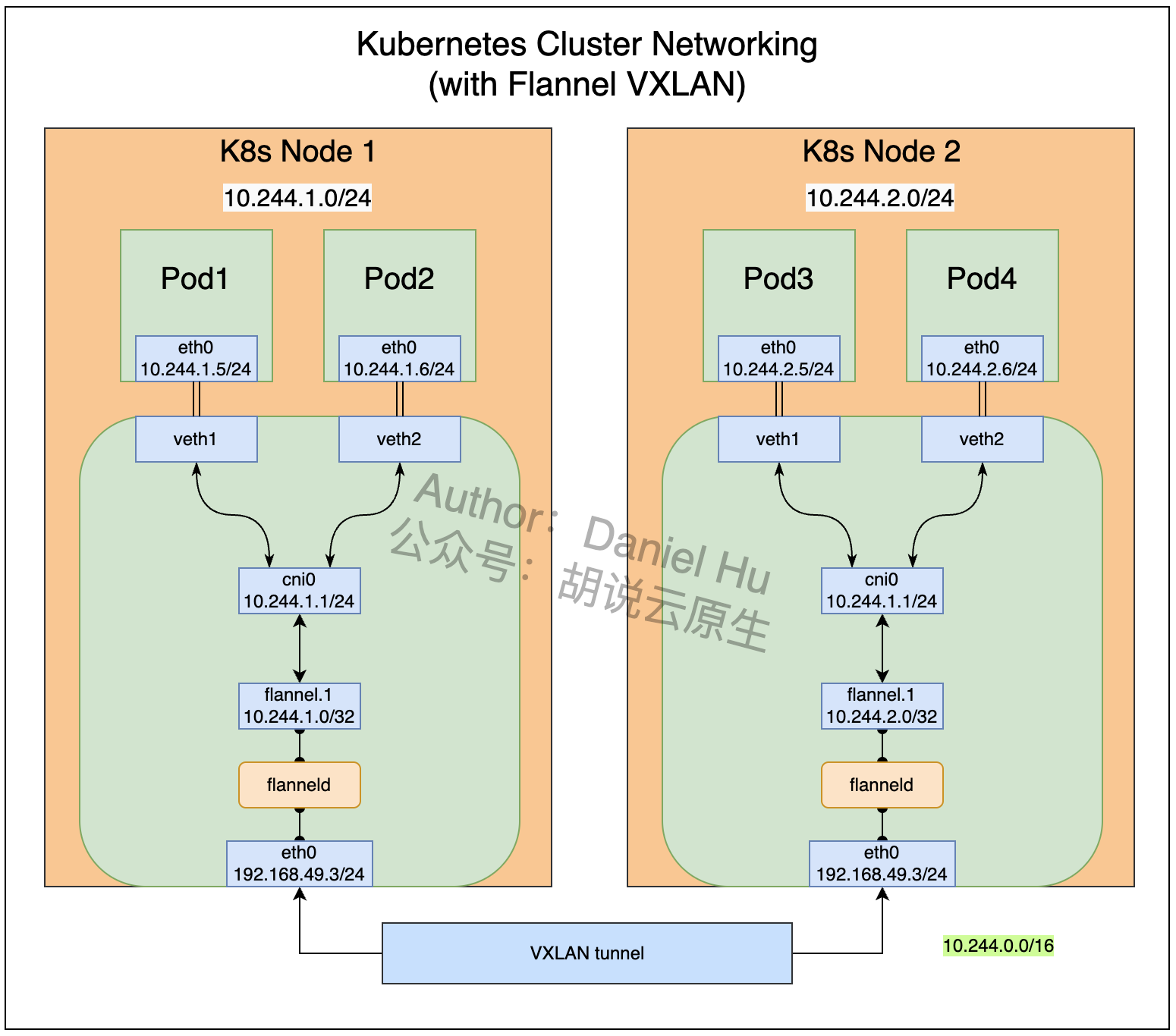
一图胜千言,下文都不知道咋展开了。哎。
此外,网络这块涉及的概念有点多,逐个细讲感觉不合适。这样,此处默认大家都熟悉 TCP/IP 协议族,下文该偷懒的地方我就偷懒。
3. Pod 间通信问题的由来
容器化以前,当需要将多个应用灵活部署到一些服务器上时,就不可避免地会遇到端口冲突问题,而协调这种冲突是很繁琐的。K8s 体系的处理方式是将每个 Pod 丢到单独的 netns 里,也就是 ip 和 port 都彼此隔离,这样就不需要考虑端口冲突了。
不过这套网络架构应该如何实现呢?整体来由需要解决下面这2个问题(结合上图的 Pod1234):
-
Pod1 如何和 Pod2 通信(同节点)
-
Pod1 如何和 Pod3 通信(跨节点)
K8s 的网络模型要求每个 Pod 都有一个唯一的 IP 地址,即使这些 Pod 分布在不同的节点上。为了实现这个网络模型,CoreOS 团队发起了 CNI 项目(后来 CNI 进了 CNCF 孵化)。CNI (Container Network Interface) 定义了实现容器之间网络连通性和释放网络资源等相关操作的接口规范,这套接口进而由具体的 CNI 插件的去实现,CNI 插件负责为 Pod 分配 IP 地址,并处理跨节点的网络路由等具体的工作。
行,接下来具体跟下 CNI 的 Flannel 实现是怎么工作的。
4. 测试环境准备
我在本地通过 Minikube 启动一个3节点的 K8s 集群,3个节点的 IP 和 hostname 分别是:
-
192.168.49.2 minikube
-
192.168.49.3 minikube-m02
-
192.168.49.4 minikube-m03
此外在这个集群内创建了几个 Pod,信息如下(主要留一下 Pod 的 IP 以及所在的节点):
-
kgpoowide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-deployment-7fbb8f4b4c-89bds 1/1 Running 0 20h 10.244.2.4 minikube-m03
nginx-deployment-7fbb8f4b4c-d29zm 1/1 Running 0 20h 10.244.1.5 minikube-m02
nginx-deployment-7fbb8f4b4c-k5vh4 1/1 Running 0 102s 10.244.2.5 minikube-m03
nginx-deployment-7fbb8f4b4c-m4scr 1/1 Running 0 3s 10.244.1.6 minikube-m02Pod 用的镜像是带有 ip 等命令的 NGINX,Dockerfile 如下:
FROM nginx:latestRUN apt-get update && \apt-get install -y iproute2 && \rm -rf /var/lib/apt/lists/*相应的 Deployment YAML 如下:
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deployment
spec:replicas: 4selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:test1ports:- containerPort: 805. 从 veth 设备聊起
不得不先提一句 veth(Virtual Ethernet Device)。veth 是一种在 Linux 中用于网络虚拟化的技术,常用于容器网络中。veth pair 可以看作是一对虚拟网络接口设备,它们像管道的两端一样相连。在一个 veth 对中,数据从一端发送出去,可以在另一端被接收到,就像它们是通过一根以太网线连接的两个独立设备一样。
在容器网络中,veth 对经常被用来连接容器和主机。具体来说,veth 对的一个端点(通常称为 veth 接口)位于容器的网络命名空间内,好像是容器的网络接口卡,而另一个端点位于主机的全局网络命名空间内,通常会连接到一个 Linux 桥接或者其他网络设备。
这种设置允许容器内的网络流量通过 veth 接口流出容器,进入主机的网络命名空间,并通过主机的网络路由和策略进行进一步的处理或转发。
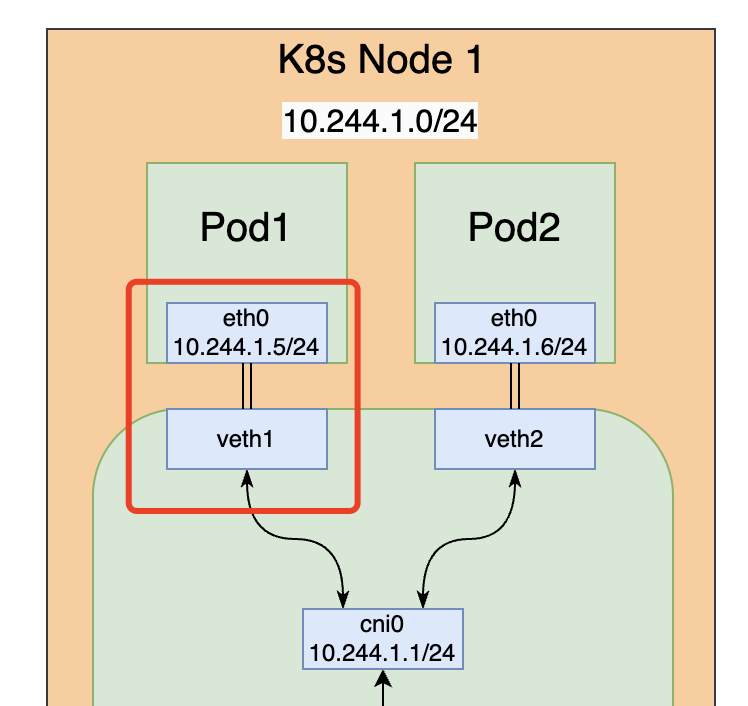
如图所示,Pod 内的 eth0 和 host 上的 veth1 其实就是一个 veth pair,Pod 和 host 在2个不同的网络命名空间内,通过 veth 设备实现了2个 netns 之间的网络互通。
而 veth-n 又会桥接到 cni0 这个网桥上,进而实现流量在主机上的路由过程。接下来我们具体看下 Pod 内外的网络设备和路由规则等。
6. 网桥 cni0
接着来看网桥 cni0。
6.1 在 Pod 内看网卡信息
Pod 10.244.1.6 内的网卡信息如下:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000link/ipip 0.0.0.0 brd 0.0.0.0
3: ip6tnl0@NONE: <NOARP> mtu 1452 qdisc noop state DOWN group default qlen 1000link/tunnel6 :: brd :: permaddr 1622:c323:de90::
4: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue state UP group defaultlink/ether 4a:2c:84:bb:56:5e brd ff:ff:ff:ff:ff:ff link-netnsid 0inet 10.244.1.6/24 brd 10.244.1.255 scope global eth0valid_lft forever preferred_lft forever可以看到 eth0@f11 设备,对应 IP 10.244.1.6/24,这里看着和一个普通的 vm 没有大差别。此外留一下这里的 if11,这个 11 对应这个 veth pair 在主机上的另外一端的序号。
6.2 在 host 上看网卡信息
节点 minikube-m02 上的网卡信息如下:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
5: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue state UNKNOWN group defaultlink/ether 62:07:aa:05:13:c4 brd ff:ff:ff:ff:ff:ffinet 10.244.1.0/32 scope global flannel.1valid_lft forever preferred_lft forever
6: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue state UP group default qlen 1000link/ether de:07:f7:20:e0:70 brd ff:ff:ff:ff:ff:ffinet 10.244.1.1/24 brd 10.244.1.255 scope global cni0valid_lft forever preferred_lft forever
7: vetha7eec1e2@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master cni0 state UP group defaultlink/ether da:ab:17:55:be:50 brd ff:ff:ff:ff:ff:ff link-netnsid 1
10: vethc9667243@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master cni0 state UP group defaultlink/ether ce:dd:d3:ec:5e:d3 brd ff:ff:ff:ff:ff:ff link-netnsid 2
11: vethd26e8b95@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master cni0 state UP group defaultlink/ether b2:64:95:13:2a:de brd ff:ff:ff:ff:ff:ff link-netnsid 3
24: eth0@if25: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65535 qdisc noqueue state UP group defaultlink/ether 02:42:c0:a8:31:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0inet 192.168.49.3/24 brd 192.168.49.255 scope global eth0valid_lft forever preferred_lft forever前面 Pod 内看到的 eth0@if11 对应这里的11号 vethd26e8b95@if4。别管这里的 if4,如果你是在 vm 里直接跑 Pod 就看不到 ifn 了。我这里因为用了 Docker Desktop 跑 K8s,所以 K8s 所在的 nodes 本质也是容器,这里多套了一层网络嵌套而已。
先看下 cni0:
-
ip link show master cni0
7: vetha7eec1e2@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master cni0 state UP mode DEFAULT group defaultlink/ether da:ab:17:55:be:50 brd ff:ff:ff:ff:ff:ff link-netnsid 1
10: vethc9667243@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master cni0 state UP mode DEFAULT group defaultlink/ether ce:dd:d3:ec:5e:d3 brd ff:ff:ff:ff:ff:ff link-netnsid 2
11: vethd26e8b95@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue master cni0 state UP mode DEFAULT group defaultlink/ether b2:64:95:13:2a:de brd ff:ff:ff:ff:ff:ff link-netnsid 3可以看到前面提到的 veth vethd26e8b95 被桥接到了 cni0 上。
继续看 host 的路由表:
default via 192.168.49.1 dev eth0
10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink
10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.49.0/24 dev eth0 proto kernel scope link src 192.168.49.3留意这里的 10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1
cni0 的信息是:
6: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65485 qdisc noqueue state UP group default qlen 1000link/ether de:07:f7:20:e0:70 brd ff:ff:ff:ff:ff:ffinet 10.244.1.1/24 brd 10.244.1.255 scope global cni0valid_lft forever preferred_lft forever结合起来看,也就是所有发往 10.244.1.0/24 段的数据包都会通过 cni0 传输,10.244.1.0/24 也就是 Flannel 分配给当前节点的 Pod IP 段。
7. VTEP flannel.1
上述路由表中还有这样2条记录:
10.244.0.0/24 via 10.244.0.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink当前集群是3个节点,也就是目的地址是当前节点内的 pods IP 段 10.244.1.0/24,流量交给 cni0 处理;而其他节点的 pods IP 段 10.244.0.0/24 和 10.244.2.0/24 则交给 flannel.1 来处理。
flannel.1 是 VXLAN 网络的 VTEP 设备。简单介绍下 VXLAN 和 VTEP:
VXLAN (Virtual Extensible LAN) 是一种覆盖网络技术,允许在现有的物理网络基础设施之上创建大量虚拟化的局域网(LAN)。它主要用于解决传统 VLAN 技术的一些限制,如 VLAN ID 数量限制(只有4096个)。VXLAN 可以支持高达1600万个虚拟网络,极大地扩展了网络的规模和灵活性。
VXLAN 相关的一些概念与原理:
封装与隧道技术:VXLAN 通过封装原始的以太网帧(Layer 2)到 UDP 数据包(Layer 3)中来工作。这意味着它可以跨越不同的网络和子网,实现跨网络边界的通信。
VXLAN 网络标识符 (VNI):每个 VXLAN 网络都有一个唯一的标识符,称为 VNI(VXLAN Network Identifier),它提供了地址隔离,确保各个 VXLAN 网络之间的数据包不会互相干扰。
VTEP(VXLAN Tunnel Endpoint):VTEP 是 VXLAN 架构中的端点设备,负责封装和解封装数据包。每个通过 VXLAN 通信的网络设备都有一个或多个 VTEP。当数据包从虚拟网络出发时,VTEP 会捕获这些数据包,将它们封装在 VXLAN 格式中(即加入 VNI 和 UDP 头),然后通过物理网络发送。当 VXLAN 数据包到达目的地的 VTEP 时,该 VTEP 将对数据包进行解封装,移除 VXLAN 头部,然后将原始的以太网帧转发到目标虚拟网络中。VTEP 通常部署在数据中心的交换机(物理或虚拟)上,但也可以部署在其他网络设备或服务器上。在容器化环境(如 Kubernetes 使用 Flannel 等 CNI)中,VTEP 可以作为软件组件运行,处理容器或 Pod 之间的 VXLAN 通信。
所以当数据包到达 flannel.1 的时候,就开始了 VXLAN 封包(MAC in UDP)过程,一个以太网帧被依次加上了 VXLAN 头(VNI 信息)、UDP 头、外部 IP 头和 MAC 头等。外部 IP 头里包含了 VXLAN 隧道的源地址和目的地址(VTEP 地址),外部 MAC 头则包含了以太网帧到达下一跳所需的 MAC 地址。
8. 最后看下 Flannel 的配置
在 minikube 环境中,Flannel 会被默认部署到 kube-flannel namespace 下。在这个 namespace 里有一个 ConfigMap 叫做 kube-flannel-cfg,里面包含这样2个配置文件:
-
cni-conf.json
{"name": "cbr0","cniVersion": "0.3.1","plugins": [{"type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}},{"type": "portmap","capabilities": {"portMappings": true}}]
}-
net-conf.json
{"Network": "10.244.0.0/16","Backend": {"Type": "vxlan"}
}如果需要修改网络模式或者 pods 网段,就可以在 net-conf.json 中灵活调整。早几年用 Flannel 的时候,我就习惯将 10.244.0.0/16 改成 10.100.0.0/16。此外 vxlan 改成 host-gw 可以提高网络传输性能,如果你的集群规模不是大几百好几千个节点,也可以考虑用 host-gw 模式。
9. 总结
从来不总结,下班。
算了,补张图吧,前文提到的 Pod1 到 Pod2/Pod3 的流量怎么走:

文章转载自:胡说云原生
原文链接:https://www.cnblogs.com/daniel-hutao/p/17914378.html
体验地址: 引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构
这篇关于深入 K8s 网络原理(一)- Flannel VXLAN 模式分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









