本文主要是介绍多条轨迹数据(文本格式)的可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
轨迹数据通常是以文本格式存储的,一行表示一个点数据,一个文件中包含了多条轨迹。通常我们使用ArcGIS添加XY数据,再通过点转线工具转换获得线数据,但在这里使用的文本通常是仅包含一条线路的数据。
本文将使用python把含多条轨迹的文本数据转换成shp数据,实现轨迹数据的可视化。
附上一个其他博主的轨迹数据集汇总:链接
数据
以一份成都市出租车GPS记录数据为例,该数据集已提前清洗完成,仅提取了原始数据集中某一天的部分数据。数据记录了成都市部分出租车在载客时的GPS位置和时间等信息,数据记录的格式为 CSV 格式。
对各个字段逐个解释如下:
- ID:出租车的ID。每辆出租车的TID都是唯一的。数据里共有384辆出租车
- Lat:出租车状态为载客时的纬度。
- Lon:出租车状态为载客时的经度。
- Time:该条记录的时间戳。如 211846 代表 21 点 18 分 46 秒。
实验
本文所用的 shapefile 库是一个Python库,用于在Python脚本中对ArcGIS中的Shapefile文件 (shp,shx,dbf等格式)进行读写操作。
安装命令:
pip install pyshp使用导入:
import shapefile代码:( import osr 需要安装 gdal 包
import pandas as pd
import osr
import shapefiledata = pd.read_csv("D:\Data\TAXI.csv", encoding='utf-8')ID = data['ID'].unique()outPath = "./line.shp"
file = shapefile.Writer(outPath)
file.field('TAXI_ID')for taxi_id in ID:taxi = data[data['ID'] == taxi_id] # 该出租车的数据line = []for index, row in taxi.iterrows():point = []point.append(row['LNG'])point.append(row['LAT'])line.append(point)polyline = [] # 存储该辆出租车的轨迹数据 polyline.append(line) # [[[lng,lat], [lng,lat], ```, [lng,lat]]]file.line(polyline)file.record(taxi_id)file.close()# 定义投影
proj = osr.SpatialReference()
proj.ImportFromEPSG(4326) # 4326-GCS_WGS_1984;
wkt = proj.ExportToWkt()# 写入投影
f = open(outPath.replace(".shp", ".prj"), 'w')
f.write(wkt) # 写入投影信息
f.close() # 关闭操作流
结果:

导入成都市区划和路网数据:
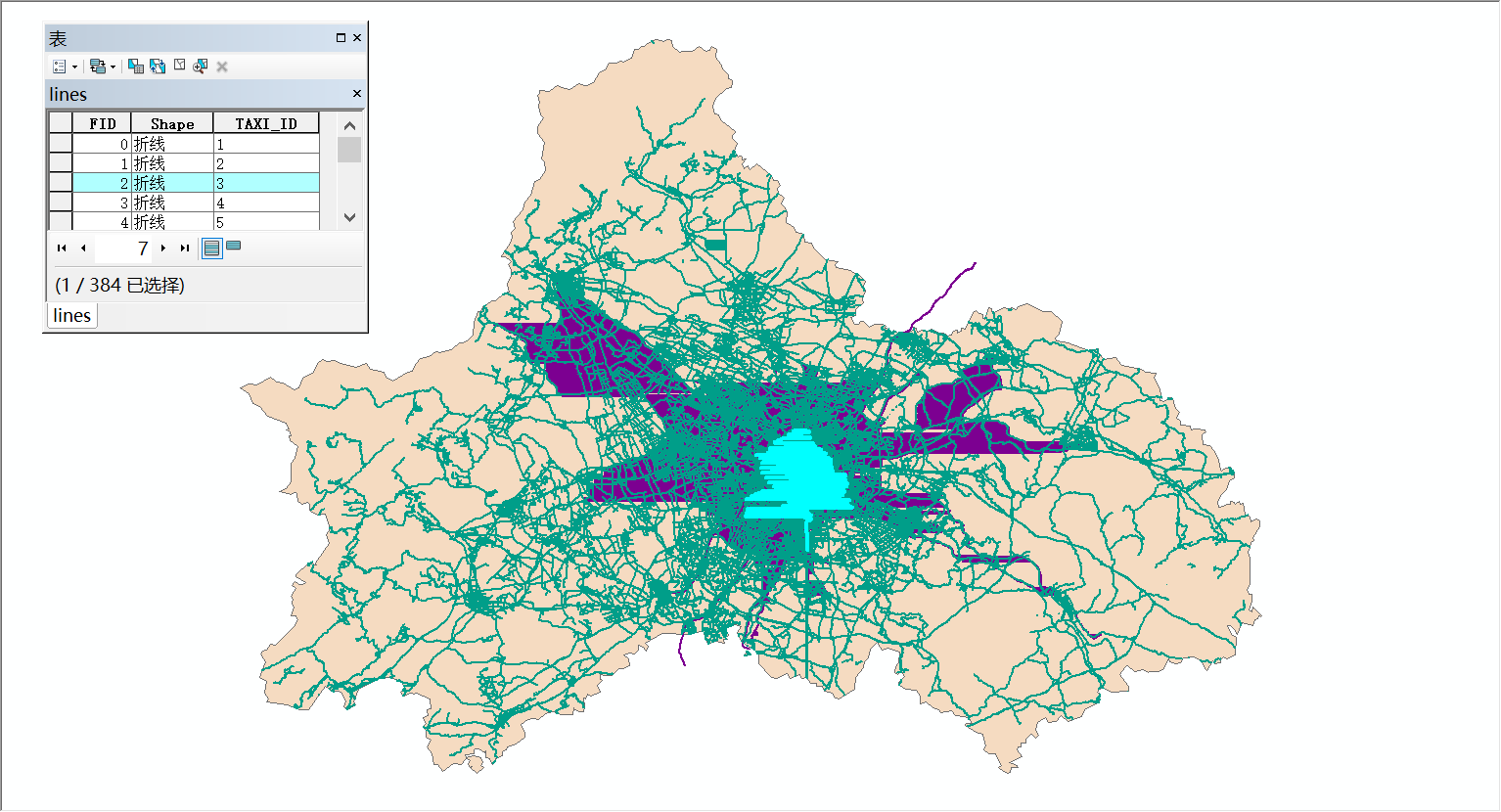
可以看出,这384辆出租车覆盖了成都市的中心城区范围。这种转换有个缺点,因为直接生成线数据,丢失了轨迹数据的时间属性,无法动态展示数据,如果需要的话,也可以再根据文本数据创建一个点数据,附上时间属性, 使用Tracking Analyst 工具条上的追踪管理器来动态展示。当然,更好的、不用写代码的方式就是用 Kepler.gl [链接]
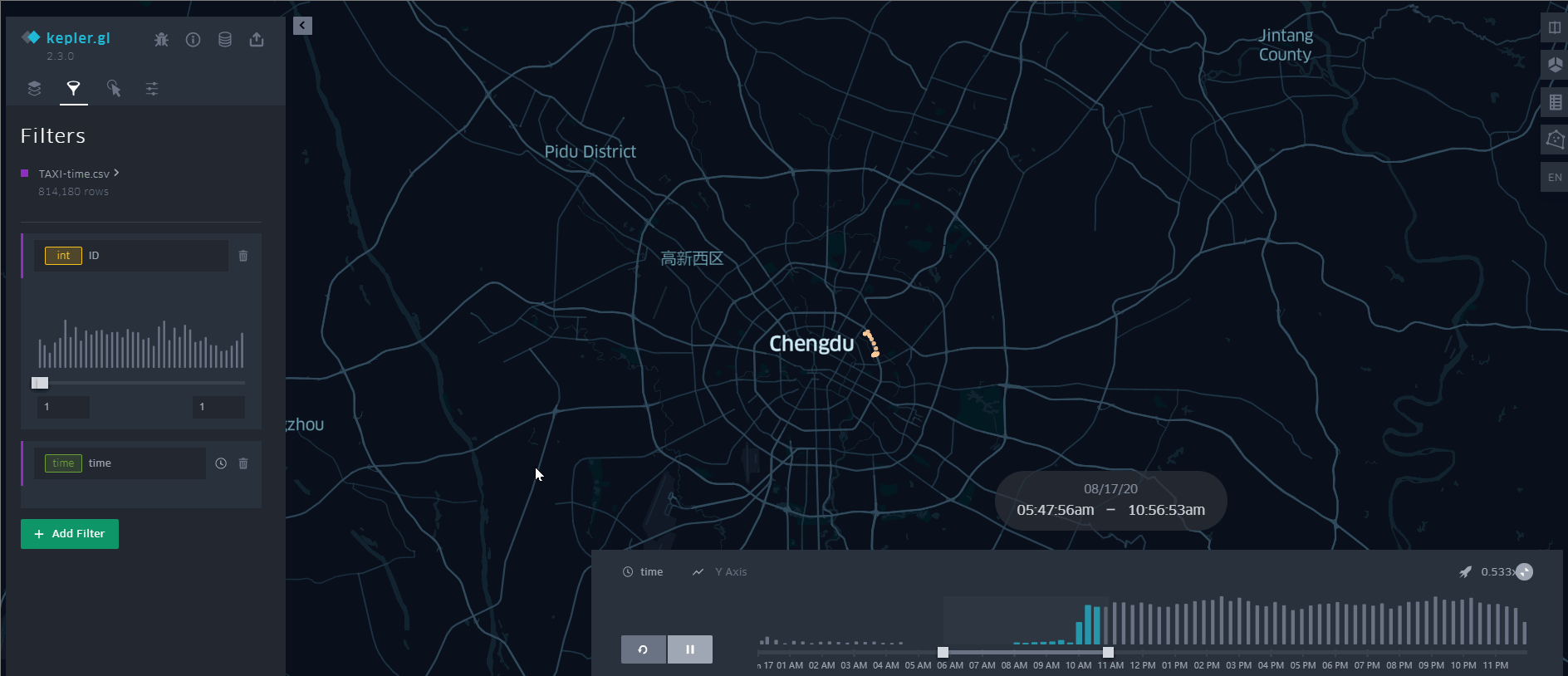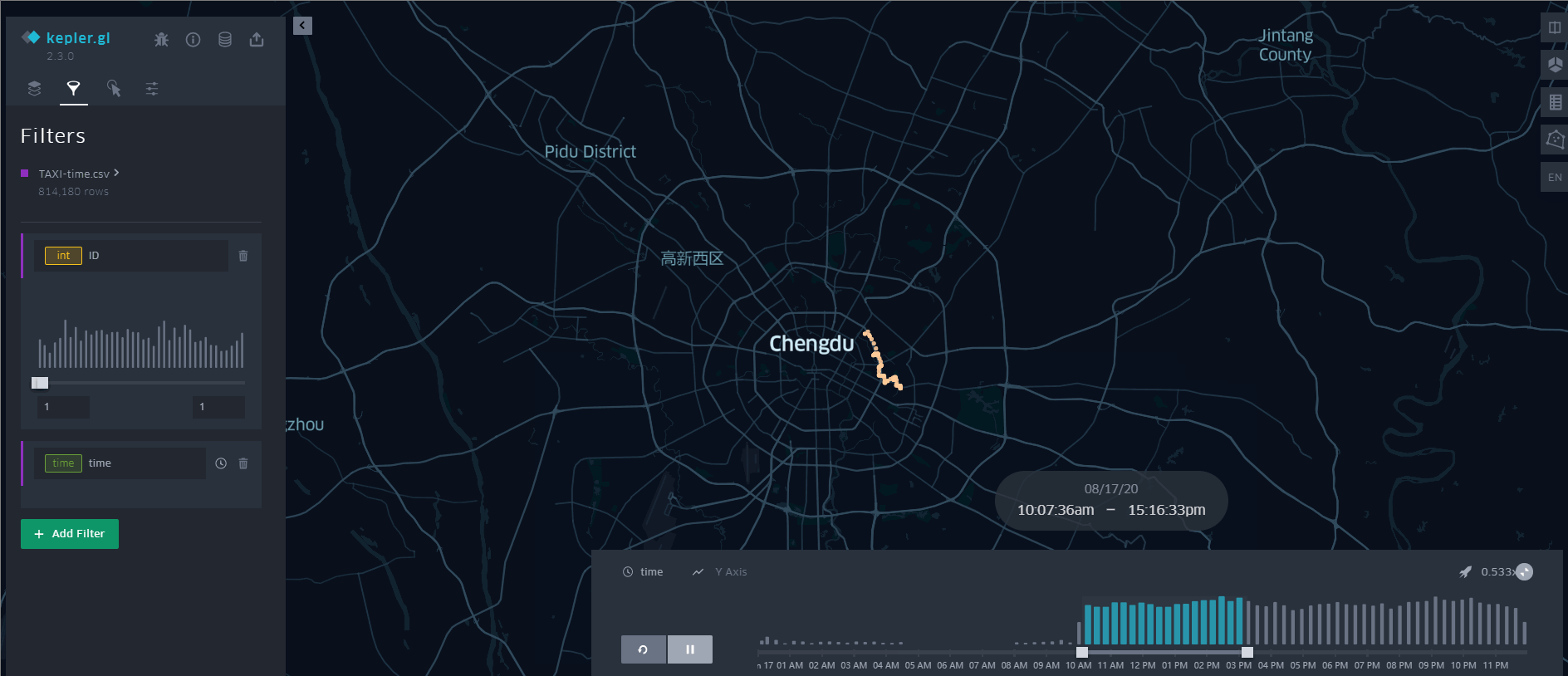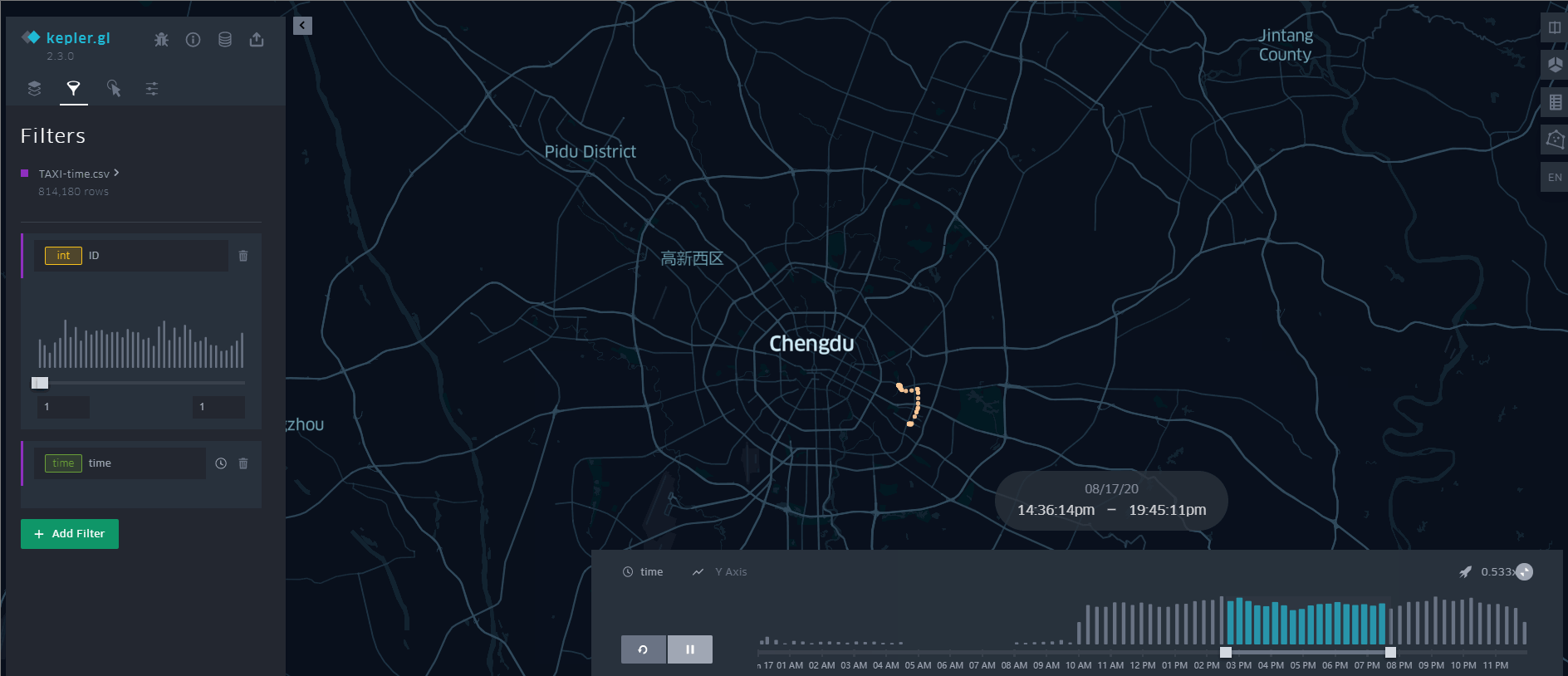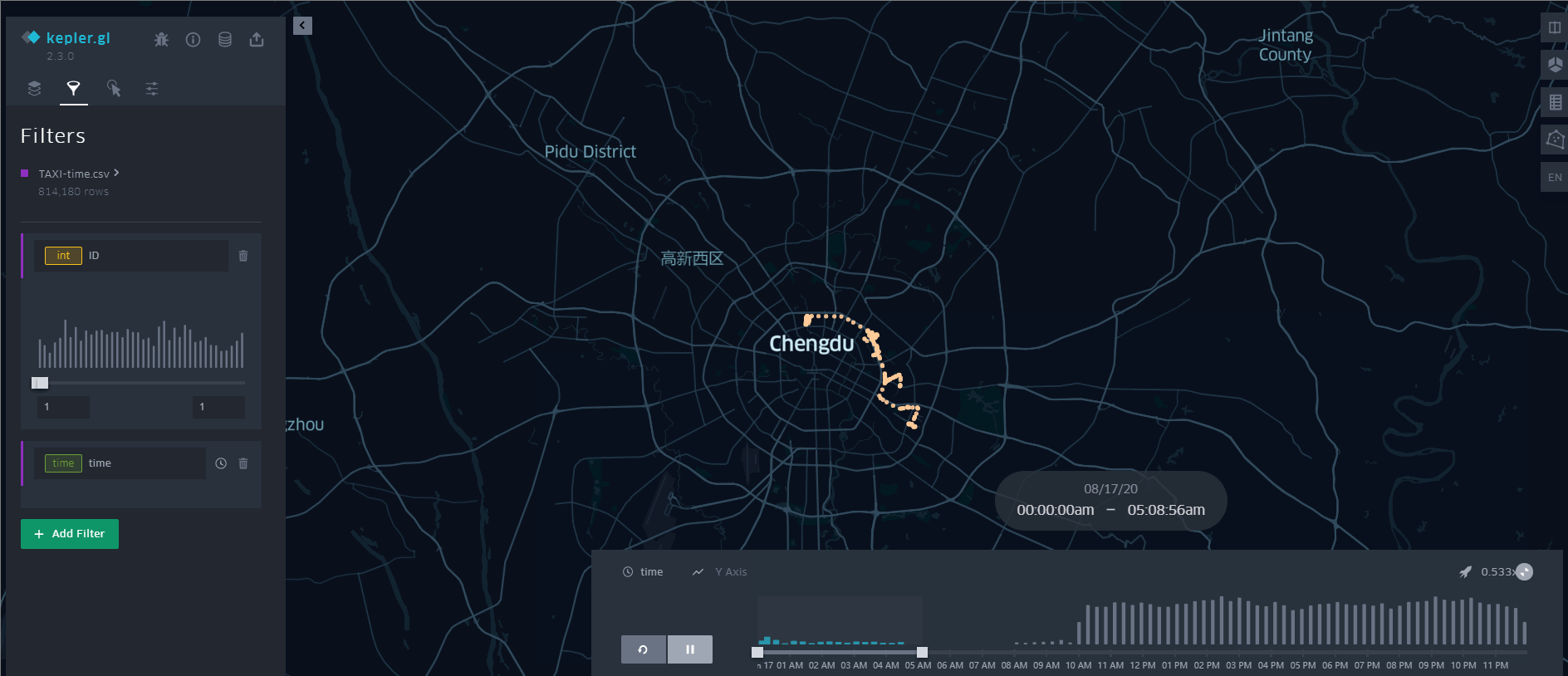
其他
麻辣GIS:Python读取、创建shapefile文件
这篇关于多条轨迹数据(文本格式)的可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




