本文主要是介绍spaCy:No module named ‘en’ || Can‘t find model ‘en’,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
了解到 ChatterBot 后,打算上手试试,安装好库包、敲好入门代码,一运行报错:1️⃣ ModuleNotFoundError: No module named 'en' ,亦或是 2️⃣ OSError: [E050] Can't find model 'en'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory.
先贴上最后配置的库包版本:
| 库包 | 版本 |
| chatterbot | 1.1.0 |
| pyyaml | 5.3.1 |
| en_core_web_sm | 2.1.0 |
| spacy | 2.1.9 |
解决
网上看了很多篇博客,把经验总结一下。
📍 错误原因:导致这个错误的源头在于 spaCy 加载模型时报错(1️⃣ 没有安装模型,2️⃣ 模型软链接问题)
1. 下载spacy 英文语言包
网上大多数使用命令 python -m spacy download en 或者 python -m spacy download en_core_web_sm,但我实践时直接就报错,所以改到GitHub上先把语言包下载下来(下载网址见下面【注意2】部分)。
更新:当spaCy版本 < V1.7时,上述命令才有效 [链接]

2021.3 更新:Spacy又提供了一种语言包 en_core_web_trf ( trf 相比之前的,缺点是更大、更慢,但优点是精度更高 [来源]
>>> 注意1:spacy en_core_web_sm/md/lg三种model有什么区别
英文的第二个包和第三个包会比较大,也比较难下载,其实它和第一个包最大的区别就是它是内置训练好的词向量的,在相似度任务中会具体用到 [来源]
题外话:在使用Rasa框架进行英文自然语言处理时,官方建议下载medium版本,原因是可以使得意图分类更有效。
We recommend using at least the “medium” sized models (
_md) instead of the spaCy's default smallen_core_web_smmodel. Small models require less memory to run, but will somewhat reduce intent classification performance. [来源]
>>> 注意2:语言包的版本和spacy的版本有对应的要求
① #en 2.0.0语言包 #要求spaCy >=2.0.0a18
下载地址:https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-2.0.0
② #en 2.1.0语言包 #要求spaCy >=2.1.0
下载地址:https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-2.1.0
③ #en 2.2.5语言包 #要求spaCy >=2.2.2
下载地址:https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-2.2.5
④ #en 2.3.1语言包 #要求spaCy >=2.3.0,<2.4.0
下载地址:https://github.com/explosion/spacy-models/releases/tag/en_core_web_sm-2.3.1
>>> 注意3:语言包名称说明

2. 解压语言包,用管理员方式打开命令行,并进入语言包文件夹执行命令
D:\ChatterBot\en_core_web_sm-2.1.0>python setup.py installBUG:可能会遇到报错 File "setup.py", line 2 SyntaxError: encoding problem: utf8
解决:打开setup.py,把 # coding: utf8 改成 # -*- coding: utf-8 -*-
3. 进入Python环境,测试是否安装完成
# 方式一
>>> import spacy
>>> nlp = spacy.load("en_core_web_sm")# 方式二
>>> import en_core_web_sm
>>> nlp = en_core_web_sm.load()4. 再次运行chatterbot的入门案例,依旧得到No module named 'en'的错误....

猜测多半是name这里出了问题,应该是默认的 en 现在变成了 en_core_web_sm
打开 C:\Anaconda3\Lib\site-packages\spacy\util.py,输出data_path看看

得到了data_path的路径:C:\Anaconda3\lib\site-packages\spacy\data
5.1 方法一:把之前解压的语言包下的 en_core_web_sm 文件夹拷贝到 data_path 的路径下,并重命名为en
5.2 方法二(推荐):以管理员方式打开cmd,为这个模型建立一个新链接
python -m spacy link en_core_web_sm en6. 再次运行chatterbot代码,成功!
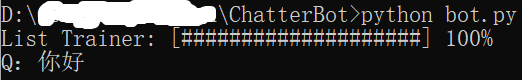
其他问题
BUG1:无法卸载 PyYAML 3.13
解决:到C:\Anaconda3\Lib\site-packages下找到pyyaml相关文件删除后再pip uninstall pyyaml
BUG2:想用 chatterbot 提供的中文语料库实验,pip install chatterbot-corpus后,说是兼容性的问题,把PyYAML 5.3.1卸载了,又把PyYAML 3.13安装回来了...虽然显示 ERROR: chatterbot 1.1.0 has requirement pyyaml<5.4,>=5.3, but you'll have pyyaml 3.13 which is incompatible. 但似乎ChatterBot还是能正常使用,真是个迷惑行为
chatterbot 语料库:https://github.com/gunthercox/chatterbot-corpus/tree/master/chatterbot_corpus/data
中文模型

SM:https://github.com/explosion/spacy-models/releases/tag/zh_core_web_sm-2.3.0 (要求spaCy >=2.3.0,<2.4.0)
SM:https://github.com/explosion/spacy-models/releases/tag/zh_core_web_sm-2.3.1 (要求spaCy >=2.3.0,<2.4.0)
SM:https://github.com/explosion/spacy-models/releases//tag/zh_core_web_sm-3.0.0 (要求spaCy >=3.0.0,<3.1.0)
MD:https://github.com/explosion/spacy-models/releases//tag/zh_core_web_md-3.0.0(要求spaCy >=3.0.0,<3.1.0)
LG:https://github.com/explosion/spacy-models/releases//tag/zh_core_web_lg-3.0.0(要求spaCy >=3.0.0,<3.1.0)
TRF:https://github.com/explosion/spacy-models/releases//tag/zh_core_web_trf-3.0.0(要求spaCy >=3.0.0,<3.1.0)
链接:spaCy 2.1 中文NLP模型语法使用
其他:displaCy Named Entity Visualizer
这篇关于spaCy:No module named ‘en’ || Can‘t find model ‘en’的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




