本文主要是介绍Python - 深夜数据结构与算法之 Recursion,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
一.引言
二.递归的简介
1.Recursion 递归
2.Factorial 阶乘
3.Template 模版
三.经典算法实战
1.Generate-Parentheses [22]
2.Climbing-Stairs [70]
3.Is-Valid-BST [98]
4.Max-Depth [104]
5.Construct-Binary-Tree [105]
6.Min-Depth [111]
7.Invert-Tree [226]
8.Ser-And-Deset-Binary-Tree [297]
9.Low-Common-Ancestor [236]
四.总结
一.引言
前面介绍了树和图,其中很多都用到了递归的方式,本文我们介绍泛型递归以及树的递归,加深对二者的印象。
二.递归的简介
1.Recursion 递归

递归的基本含义是我们通过构建一个函数体,不断自身调用直到停止,其本质上也是循环的一种,用我们小时候的说法叫:

注意虽然递归是循环且不断调用,但是一定要有退出条件,这里使用抽象的返回 1,视实际情况而定。
2.Factorial 阶乘

以阶乘计算为例,递归的实现其实是系统在内部构建一个栈,先进后出,最后一步一步调用出来,这里给出递归树的形式我们称为人肉递归,即自己模拟整个递归过程,用来更直观的理解递归。

3.Template 模版

◆ terminator - 终止条件,避免死循环,调用递归时一定要想好停止或者退出的边界条件
◆ process - 处理逻辑,每层递归的处理逻辑
◆ drill donw - 向下钻,很形象,其实就是到更深的一层继续探索,n -> n+1
◆ reverse state - 一些情况下需要保持该层的状态,此时需要再递归结束后进行恢复
Tips:

学过数学归纳法的同学应该比较熟悉递归,数学归纳法的步骤我们先初始化 f(1)、f(2),然后推广到 f(n),最后再证明 f(n+1) 也 ok 就 ok 了,递归也相似,我们需要把可拆解的重复问题进行归纳,然后推广到 f(x) 的通式上。
三.经典算法实战
1.Generate-Parentheses [22]
括号生成: https://leetcode-cn.com/problems/generate-parentheses/

◆ 题目分析
首先可以使用暴力法,共 2n 个字符,每次只能出 '(' 或者 ')',把所有结果的括号验证一下是否可用,即可。还有一种可以递归,观察上面的 n=3 的情况,对于有效的括号而言,其一定满足num-左括号 = num-右括号 and 最左边一定是 '(',所以我们可以从 0 -> n 递归生成并判断合法性。
◆ 逐步生成
class Solution(object):def generateParenthesis(self, n):""":type n: int:rtype: List[str]"""# 保存结果result = []self.generate(0, 0, n, "", result)return resultdef generate(self, left, right, n, s, result):if left == n and right == n:result.append(s)# 保证最左边一定是 '('if left < n:self.generate(left + 1, right, n, s + "(", result)# right 不够就补充if right < left:self.generate(left, right + 1, n, s + ")", result)从左括号开始,后面遍历全部情况,并通过边界条件对生成进行过滤,避免无效的生成。这里主要还是明确递归四要素:
terminator - len(left) = len(right) && s.start_with('(')
process - s + '(' || s + ')'
drill donw - left + 1 || right + 1
recerse state - 没有全局变量改动,所以无需操作

2.Climbing-Stairs [70]
爬楼梯问题: https://leetcode-cn.com/problems/climbing-stairs/

◆ 题目分析
我们尝试使用数学归纳法的思想,因为一次只能走 1 or 2 步,所以 f(1) = 1、f(2) = 2、往后类推,对于 f(n) 的情况,其有两种方式到达,一种是 f(n-1) 走 1 步,还有事 f(n-2) 走两步,所以:
f(n) = f(n-1) + f(n-2)
即走到 n 有几种方法,就等于走到 n-1 和 n-2 方法的和,同理,走到 n-1 是走到 n-2 和 n-3 的方法的和,依次类推。退出条件,退出条件就是到达 1 or 2 即可。
◆ 递归实现
class Solution(object):def climbStairs(self, n):""":type n: int:rtype: int"""# 终止条件if n <= 2:return n# 下一层return self.climbStairs(n-1) + self.climbStairs(n-2)这里我们根据递归的模版,直接套即可得到上述代码,边界条件的 1->1、2->2 我们合在一起。不过时间超出限制了,我们每次扩展 n-1、n-2 两个分叉,共 n 次,所以时间复杂度是 2^^n,还是有点高,但是能够匹配模版就说明我们递归的思想逐渐熟悉。

◆ 滑动数组
class Solution(object):def climbStairs(self, n):""":type n: int:rtype: int"""if n <= 2:return na, b, c = 1, 2, 3# 滑动数组for i in range(3, n):a, b, c = b, c, b+creturn c熟悉 Fib 即斐波那契数列的同学可以看出 f(n) = f(n-1) + f(n-2) 其实是其对应通式,我们可以通过滑动数组的方式,不断向前推进求解,只需要 o(n) 的时间复杂的和常数的空间复杂度。
3.Is-Valid-BST [98]
有效二叉搜索树: https://leetcode-cn.com/problems/validate-binary-search-tree

◆ 题目分析
二叉搜索树有效的定义在图中已经给出,左边的比 root 小,右边的比 root 大,根据中序遍历 '左根右' 遍历二叉搜索树即可得到一个有序的数组,我们只需判断 pre 节点的值是否小于当前的值即可。
◆ 中序遍历 - 递归
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = rightclass Solution(object):pre = -999999999999999def isValidBST(self, root):# 停止条件if root is None:return True# 遍历左子树if not self.isValidBST(root.left):return False# 上一个值大于等于下一个则为异常if root.val <= self.pre:return Falseself.pre = root.val# 遍历右子树return self.isValidBST(root.right)参考递归的中序遍历写法,在 val 值处进行递增顺序的判断。

◆ 中序遍历 - 栈
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def isValidBST(self, root):""":type root: TreeNode:rtype: bool"""stack = []cur = rootpre = Nonewhile cur or stack:if cur:stack.append(cur)cur = cur.leftelse:cur = stack.pop()# 在中序遍历的基础上添加了顺序的判断if pre and cur.val <= pre.val:return Falsepre = curcur = cur.rightreturn True中序遍历的模版,只是在 process val 的位置由 append or print 变成了比较是否有序。

4.Max-Depth [104]
二叉树最大深度: https://leetcode-cn.com/problems/maximum-depth-of-binary-tree

◆ 题目分析
采用 DFS 递归遍历左右子树,每 DFS 一层就为层数增加1,最后统计 max(左,右) 即可得到最深的深度。
◆ 递归实现
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def maxDepth(self, root):""":type root: TreeNode:rtype: int"""# 停止条件if not root:return 0 else:# 向下出发left_h = self.maxDepth(root.left)right_h = self.maxDepth(root.right)# +1: 根节点return max(left_h, right_h) + 1向下遍历,遍历时返回自己位置左右子树较高的层数并加上自己所在层的 1。

5.Construct-Binary-Tree [105]
重建二叉树: https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal

◆ 题目分析
pre -> 根左右 in -> 左根右,根据这个逻辑,我们可以从 preorder 确定全局的 root 节点,根据 root 节点的位置,我们在中序遍历中可以获取其左子树和右子树的长度,对于左右子树而言,其前序和中序遍历的长度是一样的,所以可以向下递归,对左右子树分别寻找 root。

◆ 递归遍历
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def buildTree(self, preorder, inorder):""":type preorder: List[int]:type inorder: List[int]:rtype: TreeNode"""# 根据 pre 可以获得根节点if not preorder and not inorder:return None# pre -> 根左右 in -> 左根右root = TreeNode(preorder[0])# 获取根节点位置mid_index = inorder.index(root.val)root.left = self.buildTree(preorder[1: mid_index + 1], inorder[: mid_index])root.right = self.buildTree(preorder[mid_index + 1:], inorder[mid_index + 1:])return root大家可以结合上面的思路和 GIF 图理解递归的意图。


6.Min-Depth [111]
二叉树最小深度: https://leetcode.cn/problems/minimum-depth-of-binary-tree/description/

◆ 题目分析
采用 DFS 递归遍历左右子树,每 DFS 一层就为层数增加1,最后统计 min(左,右) 即可得到最小的深度,和上面 Max Depth 是反着来的。但是这里求最小路径时,需要注意边际条件 max depth 有一点差别,当一边为空,一边有叶子节点时,min 的判断方法需要修改,参考下图,左边深度 0,右边深度 4,如果采用 min(0, 4) + 1 则最小为 1,但是题目要求根节点到最近的叶节点,所以我们要 if 把一边 root == None 的情况排除掉。

◆ 递归实现
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def minDepth(self, root):""":type root: TreeNode:rtype: int"""# 无根 -> 0if not root:return 0# 无孩 -> 1if not root.left and not root.right:return 1# 向下递归left_height = self.minDepth(root.left)right_height = self.minDepth(root.right)# 当一边为空一边不为空时,min(h,r) 会返回1,但此时 root 存在叶节点,所以 l+r+1# 因为如果有一个为空 其返回为0,不会影响最终结果if not root.left or not root.right:return left_height + right_height + 1return min(right_height, left_height) + 1
按照题解思路实现即可。

7.Invert-Tree [226]
反转二叉树: https://leetcode-cn.com/problems/invert-binary-tree/description/

◆ 题目分析
交换左右子树,对于 root 交换其左右,继续向下对 left 交换左右,对 right 交换左右 ... 典型的递归题目。
◆ 左右递归
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution(object):def invertTree(self, root):""":type root: TreeNode:rtype: TreeNode"""# 停止条件if not root:return None# 处理 左右交换root.left, root.right = root.right, root.left# 向下出发self.invertTree(root.left)self.invertTree(root.right)# 无全局变量修改return root再啰嗦一遍递归四步法: 停止条件 + 处理 + 下一层 + 恢复状态。

8.Ser-And-Deset-Binary-Tree [297]
BT 序列化与反序列化: https://leetcode-cn.com/problems/serialize-and-deserialize-binary-tree/

◆ 题目分析
这个题目整体来说不麻烦,但是很绕,而且很容易和官方要求的返回内容不一致。我们编码阶段可以通过 BFS 层序遍历将结果生成为符号分割的字符串,或者存到 [] 再使用 ','.jion。解码时只需要根据节点对应关系依次还原 Node 即可,需要注意 python 中如果节点为 None,需要返回特定的字符串标识并在解码时识别,下面示例采用 "null"。
◆ BFS 层序遍历
class Codec:def serialize(self, root):"""Encodes a tree to a single string.:type root: TreeNode:rtype: str"""if not root:return ""queue = collections.deque([root])res = []while queue:node = queue.popleft()if node:res.append(str(node.val))queue.append(node.left)queue.append(node.right)else:res.append('None')return '[' + ','.join(res) + ']'def deserialize(self, data):"""Decodes your encoded data to tree.:type data: str:rtype: TreeNode"""if not data:return []dataList = data[1:-1].split(',')root = TreeNode(int(dataList[0]))queue = collections.deque([root])i = 1while queue:node = queue.popleft()if dataList[i] != 'None':node.left = TreeNode(int(dataList[i]))queue.append(node.left)i += 1if dataList[i] != 'None':node.right = TreeNode(int(dataList[i]))queue.append(node.right)i += 1return root这里使用 index += 1 和 queue 配合分别决定下一个 node 该匹配给谁。这里博主自己实现了一版通过父亲索引寻找对应节点的方法,本地可以验证但乐扣总是少 None,也懒得纠结了,放在这里有兴趣的同学可以看看,主要思想是通过 parent = int((i - 1) / 2) 的父亲节点计算公式和 choose = ["l", "r"] 决定当前节点该放左还是右。
class Codec:def bfs(self, root):result = []if root is None:returnmy_queue = [root]while my_queue:# 返回列表第一个节点的数据node = my_queue.pop(0)result.append(node.val)if node.left is not None:my_queue.append(node.left)if node.right is not None:my_queue.append(node.right)return resultdef serialize(self, root):"""Encodes a tree to a single string.:type root: TreeNode:rtype: str"""result = []if not root:return ""queue = [root]# BFS 遍历二叉树while queue:node = queue.pop(0)result.append(str(node.val))if node.left:queue.append(node.left)if node.right:queue.append(node.right)return ",".join(result)def deserialize(self, data):"""Decodes your encoded data to tree.:type data: str:rtype: TreeNode"""if not data:returntree = data.split(",")root = TreeNode(int(tree[0]))result = [root]choose = ["l", "r"]for i in range(1, len(tree)):parent = int((i - 1) / 2)c = choose[(i-1) % 2]if tree[i] != "None":cur_tree = TreeNode(int(tree[i]))else:cur_tree = TreeNode(None)if c == "l":result[parent].left = cur_treeresult.append(cur_tree)if c == "r":result[parent].right = cur_treeresult.append(cur_tree)return result[0]
9.Low-Common-Ancestor [236]
二叉树最近公共祖先: https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree

◆ 题目分析
![]()
根据题目要求,p、q 公共祖先共有如上三种情况,考虑通过递归对二叉树进行前序遍历,当遇到节点 p 或 q 时返回。从底至顶回溯,当节点 p,q 在节点 root 的异侧时,节点 root 即为最近公共祖先,则向上返回 root 。
◆ DFS 遍历
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = Noneclass Solution(object):def lowestCommonAncestor(self, root, p, q):""":type root: TreeNode:type p: TreeNode:type q: TreeNode:rtype: TreeNode"""# 退出条件: 顶节点没有祖先了,最高就这么高了if root == None or root == p or root == q:return root# 分别到左右子树找 p、q 的 rootleft = self.lowestCommonAncestor(root.left, p, q)right = self.lowestCommonAncestor(root.right, p, q)# 左边没找到,右边找if not left:return right# 右边没找到,左边找if not right:return leftreturn root此题比较绕,推荐大家看大佬的图文题解: DFS 清晰图解。
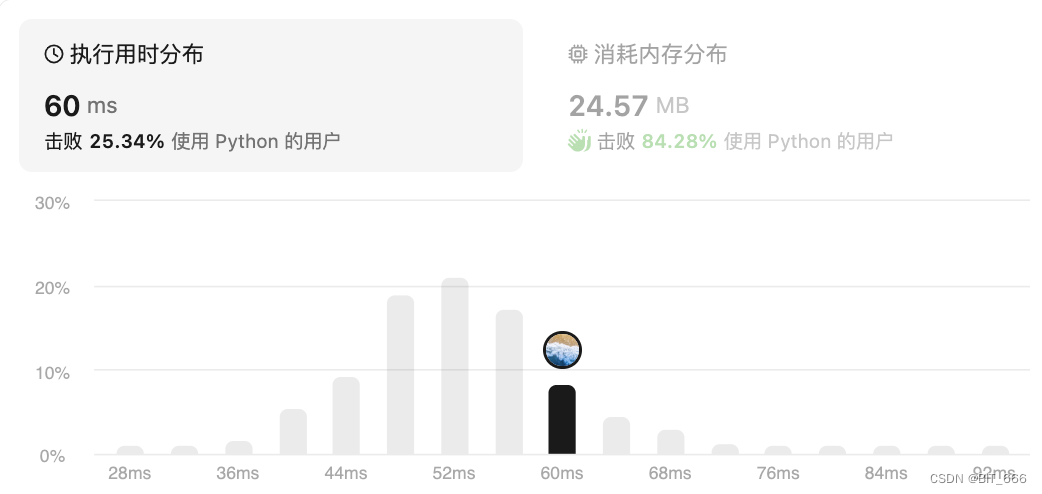
◆ 分头寻找
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = Noneclass Solution(object):def lowestCommonAncestor(self, root, p, q):""":type root: TreeNode:type p: TreeNode:type q: TreeNode:rtype: TreeNode"""record = {root: None}stack = [root]while stack:node = stack.pop()if node.left:record[node.left] = nodestack.append(node.left)if node.right:record[node.right] = nodestack.append(node.right)# p、q 都找都就可以退出了if p in record and q in record:break# 把 p 的父亲节点都标记while p:parent = record[p]record[p] = Truep = parent# 从 q 向上找,第一个为 True 的即为公共祖先while record[q] is not True:q = record[q]return q先通过遍历子树并记录的方法将 p 和 q 的全部父亲节点记录下来,随后标记 p 或者 q 的节点父亲为 True,然后从另一个节点的父亲自下而上寻找,第一个为 True 的就是公共的了。
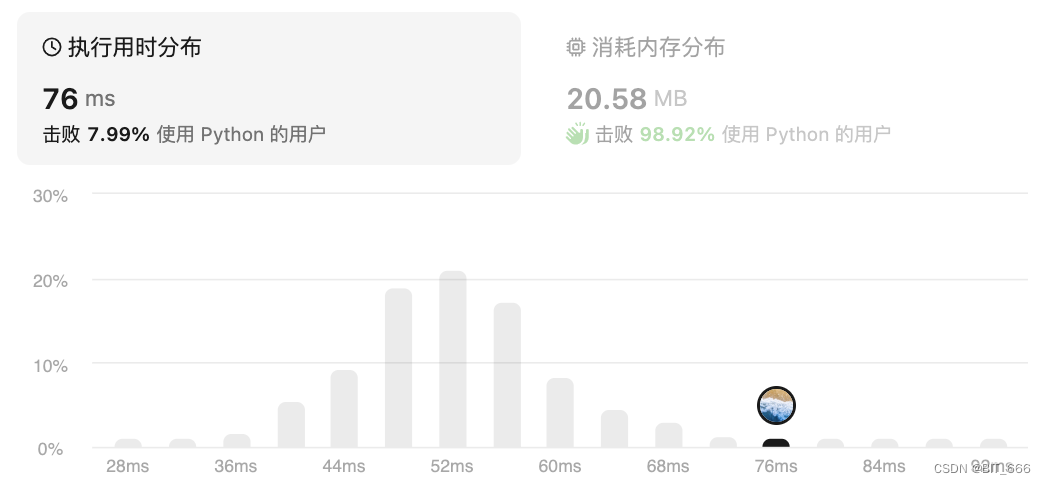
四.总结
上面介绍了递归以及大量树的题目,因为树的结构与遍历天生比较适合递归实现,上面的题思路都很巧妙,属于看了忘、忘了看、几天不看全忘的状态,还是要多多练习多多巩固。
这篇关于Python - 深夜数据结构与算法之 Recursion的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




