本文主要是介绍JUC并发编程 09——队列同步器AQS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一.Lock接口
1.1Lock的使用
1.2Lock接口提供的 synchronized 不具备的主要特性
1.3Lock接口的所有方法
二.队列同步器(AQS)
2.1队列同步器的接口与示例
2.2AQS实现源码分析
①同步队列
②获取锁
③释放锁
一.Lock接口
说起锁,你肯定会想到 synchronized 关键字, 没错,这是在jdk1.5之前java程序用来实现锁功能的。而 jdk1.5 之后,并发包中增加了 Lock 接口用来实现锁功能,它的功能和 synchronized 类似,不过使用时需要显示的获取和释放锁。虽然它缺少了(通过synchronized 块或方法所提供的)隐式获取释放锁的便捷性,但是却拥有了锁获取与释放的可操作性、可中断的获取锁以及超时获取锁等多种synchronized关键字所不具备的同步特性。
1.1Lock的使用
Lock 的使用也很简单,如下所示:

在 finally 块中释放锁,目的是保证在获取到锁之后,最终能够被释放。注意:
- 不要将获取锁的过程 lock.lock() 写在 try 块中,因为在于加锁(自定义锁的实现)操作可能会抛出异常
- 如果加锁操作在try块之前,那么出现异常时try-finally块不会执行,程序直接因为异常而中断执行;
- 如果加锁操作在try块中,由于已经执行到了try块,那么finally在try中出现异常时仍然会执行,此时try中的加锁操作出现异常,finally依然会执行解锁操作,而此时并没有获取到锁,执行解锁操作会抛出另外一个异常
- 虽然都是抛出异常结束,但是此时finally解锁抛出的异常信息会将加锁的异常信息覆盖,导致信息丢失。因此应该将加锁操作放在try块之前执行。
- 加锁 lock.lock() 之后以及 try 块之前,最好不要插入语句,如果在predo的操作中出现异常,程序会因为异常而终止,而由于并未执行try块,因此finally也不会执行,此时锁并没有释放掉,因此可能会出现死锁。所以,加锁之后直接执行try块,不要执行predo操作。
1.2Lock接口提供的 synchronized 不具备的主要特性
- 尝试性的非阻塞的获取锁:当前线程可以尝试性的获取锁,如果当前锁没有被其它线程获取到,则成功获取并持有。如果获取失败则立刻返回,非阻塞。
- 能被中断的获取锁:与 synchronized 不同的是,Lock接口中的 lockInterruptibly() 方法是可中断的获取锁。即获取不到锁的线程能够响应中断,不是死等,当获取不到锁的线程被其它线程中断时,中断异常被抛出。而用synchronized修饰的话,当一个线程处于等待某个锁的状态,是无法被中断的,只有一直等待下去。
- 超时获取锁:在指定时间之前获取锁,超时无法获取则返回。
1.3Lock接口的所有方法
- void lock():获取锁,当前线程获取到锁后,从该方法返回,该方法获取锁过程中阻塞
- void lockInterruptibly() throws InterruptedException:和lock() 的区别在于该方法会响应中断
- boolean tryLock():非阻塞尝试获取锁,方法立即返回,获取到返回true,否则返回false
- boolean tryLock(long time, TimeUnit unit) throws InterruptedException:超时的获取锁,当超时、中断、获取未超时获取到了锁这三种场景都会返回
- void unlock():释放锁
- Condition newCondition():获取等待通知组件,该组件与当前锁绑定,当前线程只有获得了锁,才能调用该组件的 await() 方法,而调用后,当前线程将释放锁
二.队列同步器(AQS)
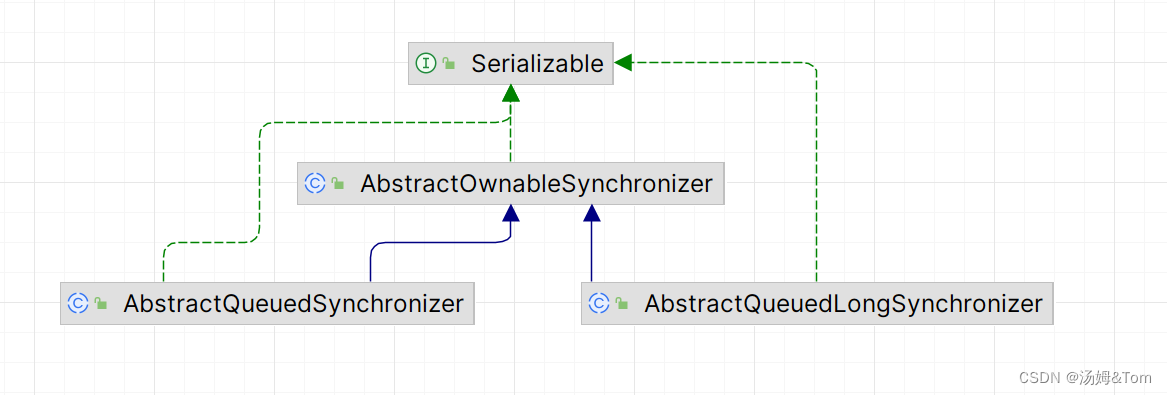
队列同步器 AbstractQueuedSynchronizer,是用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作,并发包的作者(Doug Lea)期望它能够成为实现大部分同步需求的基础。
队列同步器的主要使用方式是继承,子类通过继承队列同步器并实现它的抽象方法来管理同步状态,在抽象方法的实现过程中免不了要对同步状态进行更改,这时就需要使用队列同步器提供的3个方法(getState()、setState(int newState)和compareAndSetState(int expect,int update))来进行操作,因为它们能够保证状态的改变是安全的。子类推荐被定义为自定义同步组件的静态内部类,队列同步器自身没有实现任何同步接口,它仅仅是定义了若干同步状态获取和释放的方法来 供自定义同步组件使用,队列同步器既可以支持独占式地获取同步状态,也可以支持共享式地获取同步状态,这样就可以方便实现不同类型的同步组件(ReentrantLock、ReentrantReadWriteLock和CountDownLatch等)。
队列同步器是实现锁(也可以是任意同步组件)的关键,在锁的实现中聚合队列同步器,利用队列同步器实现锁的语义。可以这样理解二者之间的关系:
- 锁是面向使用者的,它定义了使用者与锁交 互的接口(比如可以允许两个线程并行访问),隐藏了实现细节;
- 同步器面向的是锁的实现者, 它简化了锁的实现方式,屏蔽了同步状态管理、线程的排队、等待与唤醒等底层操作。锁和同步器很好地隔离了使用者和实现者所需关注的领域。
2.1队列同步器的接口与示例
队列同步器AQS的设计是基于模板方法的,即使用者需要继承队列同步器并重写指定的方法,然后将队列同步器组合在自定义同步组件中,并调用同步器提供的模板方法,这些模板方法会调用使用者的重写方法。
同步器为了让使用者重写指定的方法,提供了三个基础方法:
- getState():获取当前同步状态
- setState(int newState):设置当前同步状态
- compareAndSetState(int expect,int update):使用CAS设置当前状态,该方法能够保证状态 设置的原子性
同步器可重写的方法分为 独占式获取锁 和 共享式获取锁,如下图所示:

实现自定义同步组件时,将会调用同步器提供的模板方法(这些模板方法会调用使用者的重写方法),部分模板方法如下:

同步器提供的模板方法基本上分为3类:独占式获取与释放同步状态、共享式获取与释放同步状态和查询同步队列中的等待线程情况。自定义同步组件将使用同步器提供的模板方法 来实现自己的同步语义。
独占锁就是在同一时刻只能有一个线程获取到锁,而其他获取锁的线程只能处于同步队列中等待,只有获取锁的线程释放了锁,后继的线程才能够获取锁。
接下来,我们自己实现一个独占锁,采用组合自定义同步器AQS的方式,只有搞懂了AQS才能更加深入的去学习理解 并发包中的其它同步组件。
public class Mutex implements Lock {private static class Sync extends AbstractQueuedSynchronizer {//是否处于独占状态@Overrideprotected boolean isHeldExclusively() {return getState() == 1;}//当状态为 0 时获取锁@Overrideprotected boolean tryAcquire(int arg) {if(compareAndSetState(0,1)){setExclusiveOwnerThread(Thread.currentThread());return true;}return false;}//释放锁,将状态置为 0@Overrideprotected boolean tryRelease(int arg) {if(getState()==0||getExclusiveOwnerThread()!=Thread.currentThread()){throw new IllegalMonitorStateException();}setExclusiveOwnerThread(null);setState(0);return true;}//返回一个 Condition,每个 condition 都包含了一个 condition 队列Condition newCondition(){return new ConditionObject();}}//仅需要将操作代理到 Sync 上即可private final Sync sync=new Sync();@Overridepublic void lock() {sync.acquire(1);}@Overridepublic void lockInterruptibly() throws InterruptedException {sync.acquireInterruptibly(1);}@Overridepublic boolean tryLock() {return sync.tryAcquire(1);}@Overridepublic boolean tryLock(long time, TimeUnit unit) throws InterruptedException {return sync.tryAcquireNanos(1, unit.toNanos(time));}@Overridepublic void unlock() {sync.release(1);}@Overridepublic Condition newCondition() {return sync.newCondition();}public boolean isLocked(){return sync.isHeldExclusively();}public boolean hasQueuedThreads(){return sync.hasQueuedThreads();}
}如示例代码所示,Mutex中定义了一个静态内部类,它继承了同步器实现了独占式获取和释放同步状态。
在 tryAcquire(int acquires) 方法中,如果经过CAS设置成功(同步状态设置为1),则代表获 取了同步状态,而在 tryRelease(int releases) 方法中只是将同步状态重置为0。
用户使用Mutex时并不会直接和内部同步器的实现打交道,而是调用Mutex提供的方法,在Mutex的实现中,以获取锁的 lock() 方法为例,只需要在方法实现中调用同步器的模板方法acquire(int args) 即可,当前线程调用该方法获取同步状态失败后会被加入到同步队列中等待,这样大大简化了实现一个可靠自定义同步组件的门槛。
2.2AQS实现源码分析
接下来将从实现角度分析队列同步器是如何完成线程同步的,主要包括:同步队列、独占式同步状态获取与释放、共享式同步状态获取与释放以及超时获取同步状态等同步器的核心数据结构与模板方法。
①同步队列
我们先看看AQS中的一些重要属性:

同步器依赖内部的同步队列(一个FIFO双向队列)来完成同步状态管理,流程是这样的:当线程获取同步状态失败时,同步器会将当前线程以及等待状态构造成为一个节点(Node),将其加入到队列,同时阻塞当前线程,当同步状态释放时,会把首节点中的线程唤醒,使其再次尝试获取锁同步状态。
同步队列中的节点用来保存获取同步状态失败的线程的引用、等待状态以及前驱和后继节点,我们来看下代码:
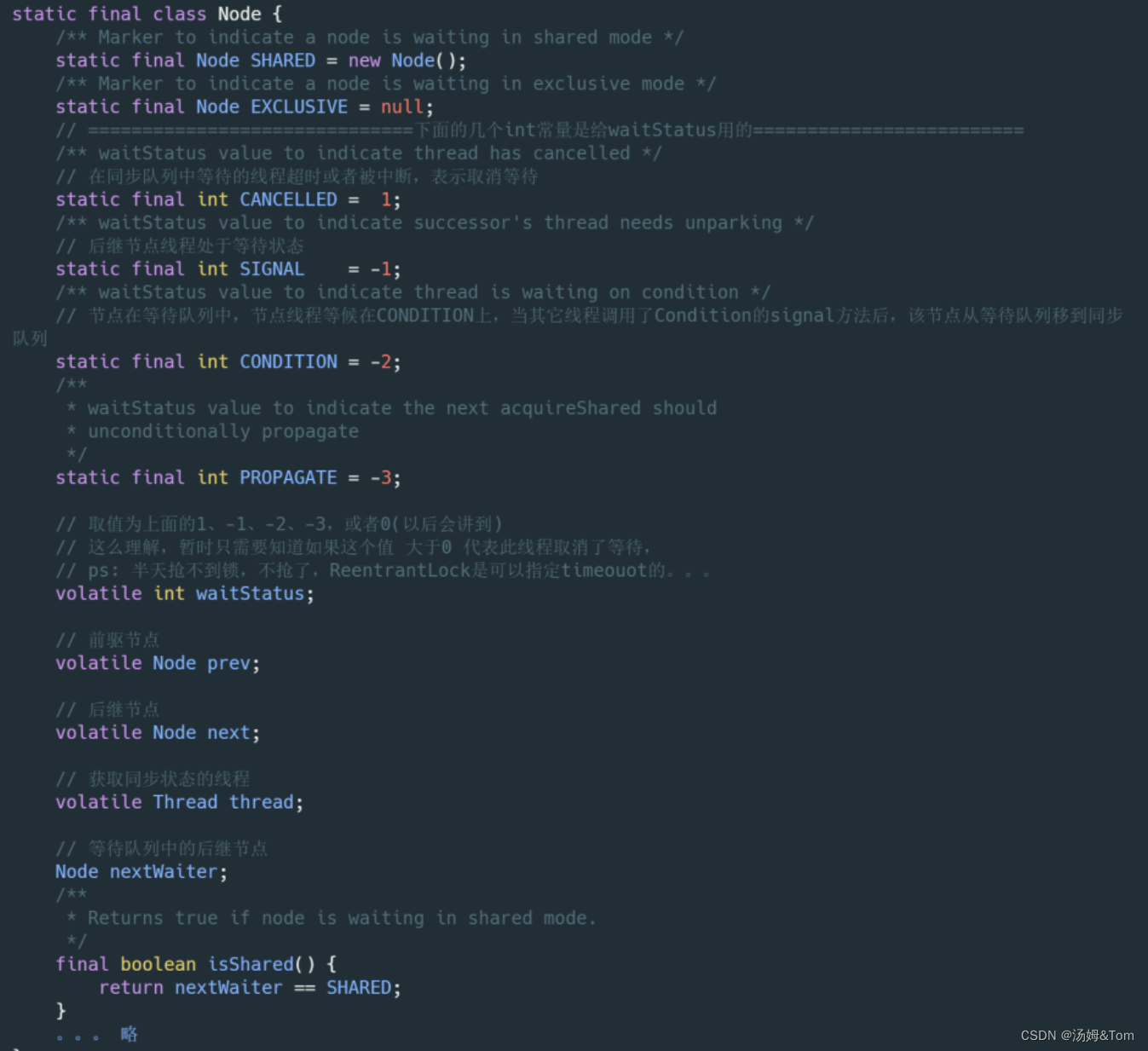
其实就是5个属性:thread(获取同步状态的线程) + waitStatus(等待状态) + prev(前驱结点) + next(后继结点) + nextWaiter(等待队列中的后继结点)
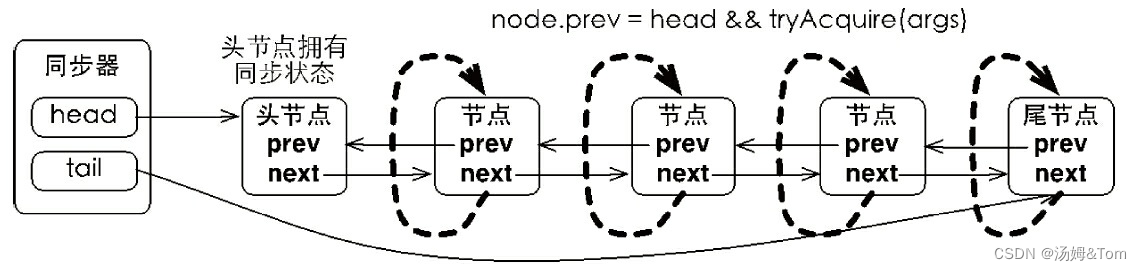
节点是构成同步队列的基础,同步器拥有首尾节点,获取同步失败的线程将会成为节点加入到该队列尾部,同步队列的基本结构如下图:

同步器包含了两个节点类型的引用,一个指向头节点,而另一个指向尾节点。试想一下,当一个线程成功地获取了同步状态(或者锁),其他线程将无法获取到同步状态,转而被构造成为节点并加入到同步队列中,而这个加入队列的过程必须要保证线程安全,因此同步器提供了一个基于CAS的设置尾节点的方法:compareAndSetTail(Node expect,Node update),它需要传递当前线程“认为”的尾节点和当前节点,只有设置成功后,当前节点才正式与之前的尾节点建立关联。
同步队列遵循FIFO,首节点是获取同步状态成功的节点,首节点的线程在释放同步状态时,将会唤醒后继节点,而后继节点将会在获取同步状态成功时将自己设置为首节点。
设置首节点是通过获取同步状态成功的线程来完成的,由于只有一个线程能够成功获取到同步状态,因此设置头节点的方法并不需要使用CAS来保证,它只需要将首节点设置成为原首节点的后继节点并断开原首节点的next引用即可。
②获取锁
获取锁分为独占式和共享式,这里我们只讲独占式获取锁模式。通过调用AbstractQueuedSynchronizer的模板方法 public final void acquire(int arg){}可以获取同步状态,该方法对中断不敏感,也就是由于线程获取同步状态失败后进入同步队列中,后续对线程进行中断操作时,线程不会从同步队列中移出。

如下图所示:

- 首先会调用 tryAcquire(arg) 方法,上面也提到了,这个方法是需要同步组件自己实现的,比如上面我们自己实现的Mutex锁。该方法保证线程安全的获取同步状态,tryAcquire(arg) 返回 true 表示获取成功也就正常退出了。
- 否则会构造同步节点(独占式Node.EXCLUSIVE)并通过 addWaiter(Node mode) 方法将加入到同步队列的尾部。源码中通过使用compareAndSetTail(Node expect,Node update)方法来确保节点能够被线程安全添加。在enq(final Node node)方法中,同步器通过“死循环”来保证节点的正确添加,在“死循环”中只有通过CAS将节点设置成为尾节点之后,当前线程才能从该方法返回,否则,当前线程不断地尝试设置。可以看出,enq(final Node node)方法将并发添加节点的请求通过CAS变得“串行化”了。


- 最后调用acquireQueued(final Node node, int arg) 通过 “死循环”的方式获取同步状态。如果获取不到则阻塞节点中对应的线程,而被阻塞后的唤醒只能依靠前驱节点出队或者阻塞线程被中断来实现。
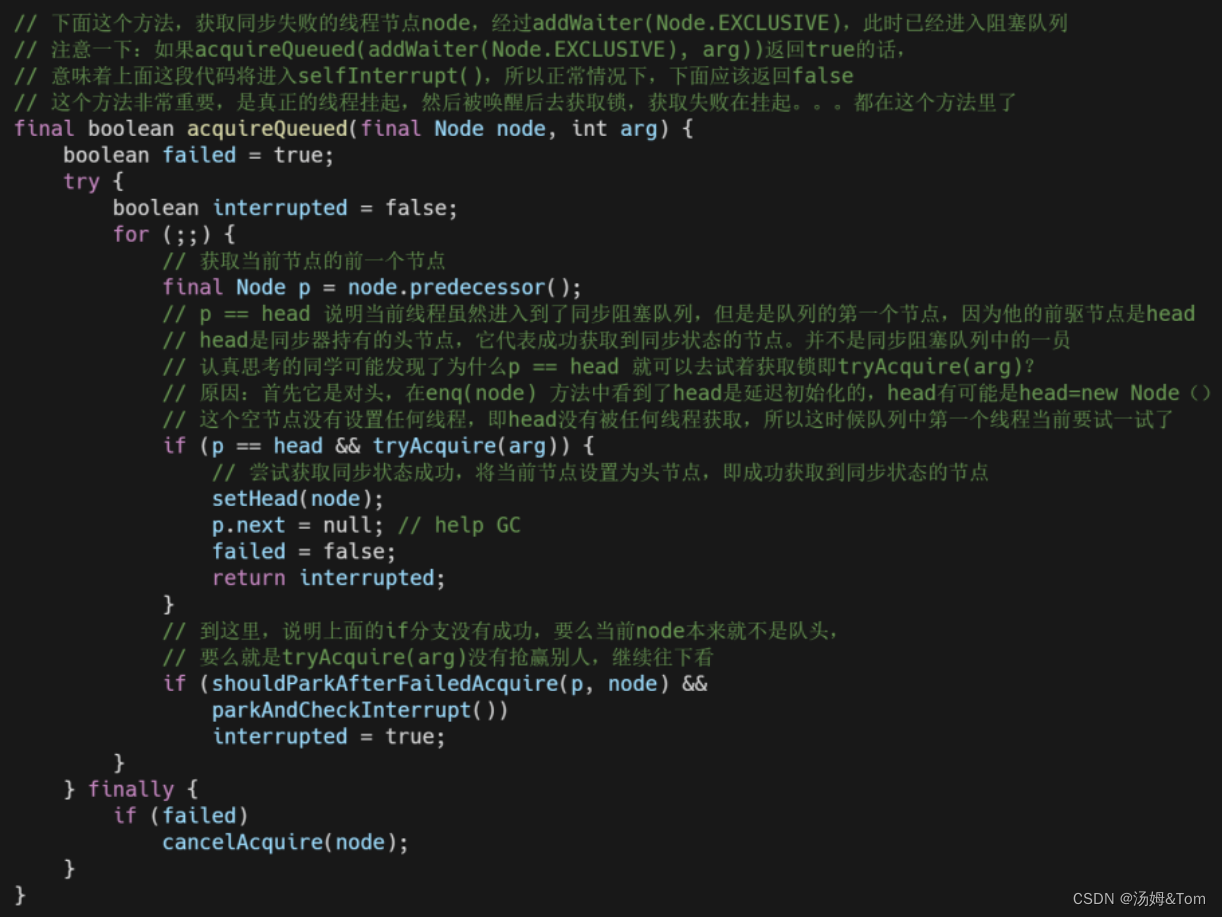
如上,假如当前node本来就不是队头或者就是 tryAcquire(arg) 没有抢赢别人,就是走到下一个分支判断:shouldParkAfterFailedAcquire(p, node) 当前线程没有抢到锁,是否需要挂起当前线程?
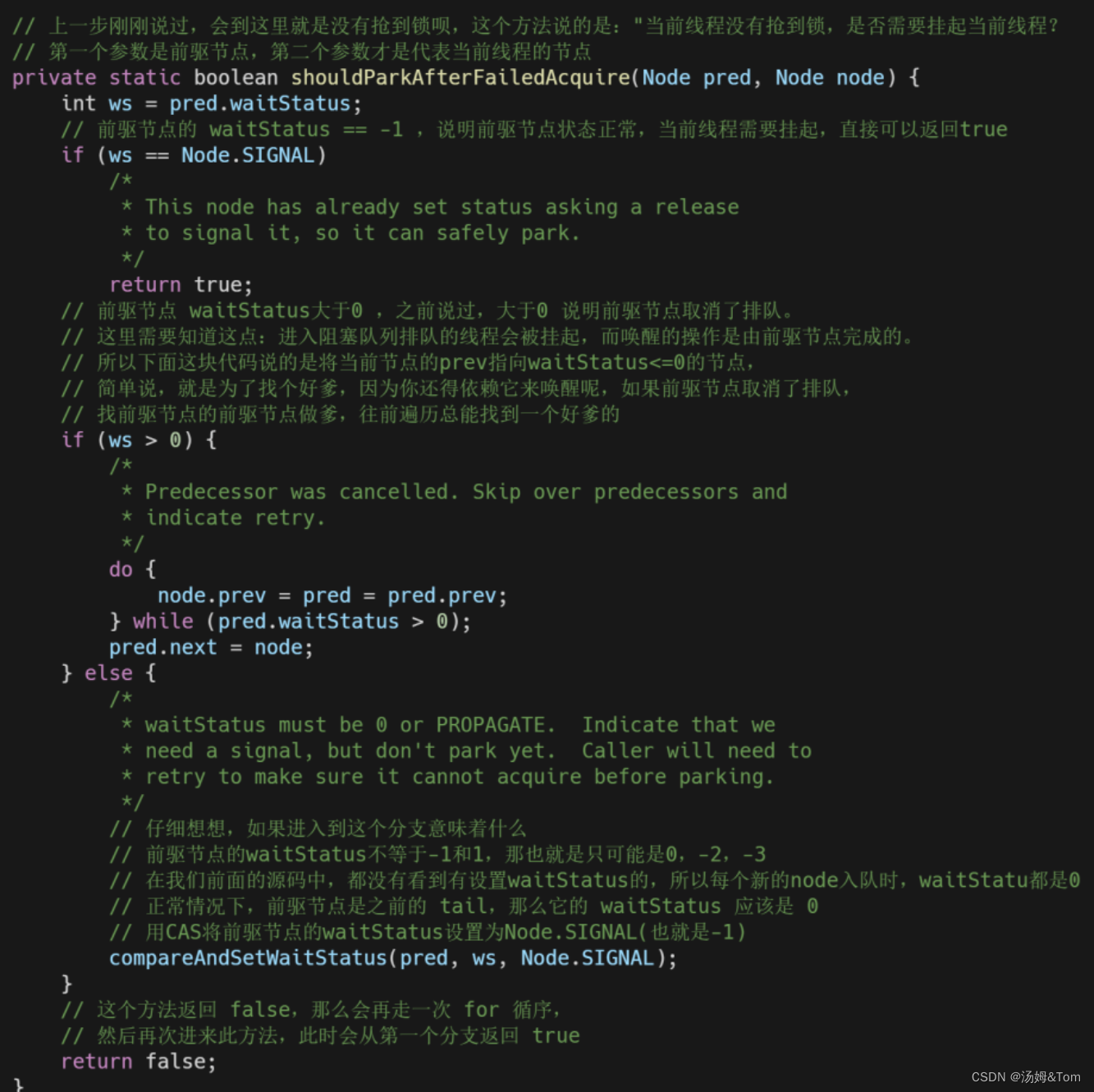
这里我们分析下private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) 这个方法返回值的情况:
- 如果返回true, 说明前驱节点的 waitStatus==-1,是正常情况,那么当前线程需要被挂起,等待以后被唤醒,就等着前驱节点拿到锁,然后释放锁的时候叫你好了。这个方法返回后,是true 则执行 parkAndCheckInterrupt() 方法:

- 如果返回false, 说明当前不需要被挂起。仔细看shouldParkAfterFailedAcquire(p, node),我们可以发现,其实第一次进来的时候,一般都不会返回true的,原因很简单,前驱节点的 waitStatus=-1 是依赖于后继节点设置的。也就是说,我都还没给前驱设置-1呢,怎么可能是true呢,但是要看到,这个方法是套在循环里的,所以第二次进来的时候状态就是-1了。
在acquireQueued(final Node node,int arg)方法中,当前线程在“死循环”中尝试获取同步状态,而只有前驱节点是头节点才能够尝试获取同步状态,这是为什么?原因有两个,如下:
- 第一,头节点是成功获取到同步状态的节点,而头节点的线程释放了同步状态之后,将会唤醒其后继节点,后继节点的线程被唤醒后需要检查自己的前驱节点是否是头节点。
- 第二,维护同步队列的FIFO原则。该方法中,节点自旋获取同步状态的行为,如下图所示:
由于非首节点线程前驱节点出队或者被中断而从等待状态返回,随后检查自己的前驱是否是头节点,如果是则尝试获取同步状态。可以看到节点和节点之间在循环检查的过程中基本不相互通信,而是简单地判断自己的前驱是否为头节点,这样就使得节点的释放规则符合FIFO,并且也便于对过早通知的处理(过早通知是指前驱节点不是头节点的线程 由于中断而被唤醒)。 独占式同步状态获取流程,也就是acquire(int arg)方法调用流程,如图所示:

③释放锁

当前线程获取同步状态并执行了相应逻辑之后,就需要释放同步状态,使得后续节点能够继续获取同步状态。通过调用同步器的release(int arg)方法可以释放同步状态,该方法在释放了同步状态之后,会唤醒其后继节点(进而使后继节点重新尝试获取同步状态)。
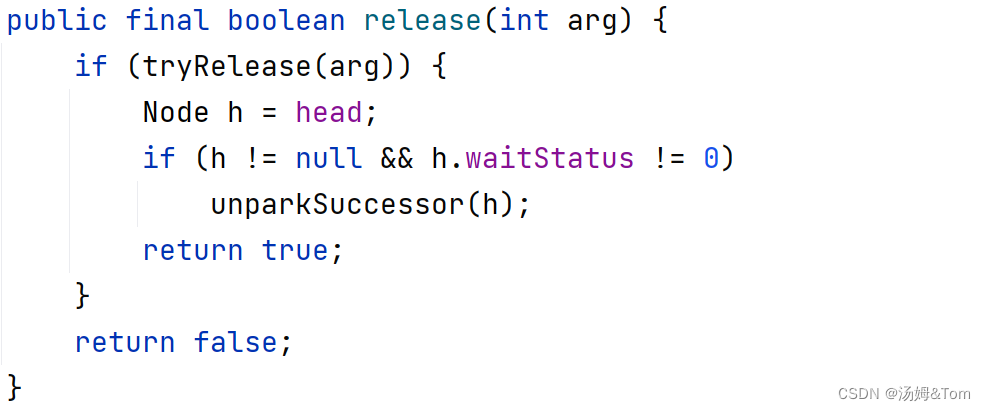
该方法执行时,会唤醒头节点的后继节点线程,unparkSuccessor(Node node)方法使用LockSupport 来唤醒处于等待状态的线程。
总结
分析了独占式同步状态获取和释放过程后,适当做个总结:在获取同步状态时,同步器维
护一个同步队列,获取状态失败的线程都会被加入到队列中并在队列中进行自旋;移出队列
(或停止自旋)的条件是前驱节点为头节点且成功获取了同步状态。在释放同步状态时,同步
器调用tryRelease(int arg)方法释放同步状态,然后唤醒头节点的后继节点。
参考:
《java并发编程的艺术》
并发编程 6:AQS很难? (qq.com)
这篇关于JUC并发编程 09——队列同步器AQS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





