本文主要是介绍28、清华大学脑机接口实验组SSVEP数据集:通过视觉触发BCI[飞一般的赶脚!],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
哈喽,最近对清华大学脑机接口的数据进行了尝试,输入到了DL模型中,以下是本人对于清华BCI数据的个人见解。

数据地址:
清华大学脑机接口研究组 (tsinghua.edu.cn)
打开网站可以看到有很多个数据,官方对于每个数据都有介绍,但是只对于第一个数据:Benchmark Dataset官方所言最多,英文直接翻译就是基准数据集,下面的其他SSVEP数据都是对于该数据的变体,并且其他数据清华介绍也很少。下面对于这个基准数据进行介绍:
Benchmark Dataset:
该数据集收集了35名健康受试者(17名女性,年龄17-34岁,平均年龄:22岁)的SSVEP-BCI记录,重点关注在不同频率(8-15.8 Hz,间隔0.2 Hz)下闪烁的40个字符。对于每个受试者,实验由6个trials组成。每个trials包含40个试验,对应于以随机顺序指示的全部40个字符。每次试验都以指示目标刺激的视觉提示(红色方块)开始。提示在屏幕上出现0.5秒。受试者被要求在提示持续时间内尽快将目光转向目标。提示偏移后,所有刺激开始同时在屏幕上闪烁,并持续5秒。刺激偏移后,在下一次试验开始前,屏幕空白0.5秒,这使得受试者在连续试验之间有短暂的休息时间。每次试验总共持续6秒。为了便于视觉固定,在刺激期间,闪烁的目标下方出现了一个红色三角形。在每个区块中,受试者被要求在刺激期间避免眨眼。为了避免视觉疲劳,在两个连续的盖帽之间休息几分钟。
使用Synamps2系统(Neuroscan,股份有限公司)以1000Hz的采样率采集EEG数据。放大器的通频带范围为0.15Hz到200Hz。六十四个通道覆盖受试者的整个头皮,并根据国际10-20系统排列。地面位于Fz和FPz之间。引用位于顶点上。电极阻抗保持在10KΩ以下。为了消除常见的电源线噪声,在数据记录中应用了50Hz陷波滤波器。事件触发器由计算机生成到放大器,并记录在与EEG数据同步的事件通道上。
连续的脑电图数据被分割为6秒的时期(刺激前500毫秒,刺激后5.5秒)。这些时期随后被下采样到250Hz。因此,每次试验包括1500个时间点。最后,这些数据作为双精度浮点值存储在MATLAB中,并命名为主题索引(即S01.mat,…,S35.mat)。对于每个文件,加载在MATLAB中的数据生成一个名为“data”的4-D矩阵,其维数为[64,1500,40,6]。四个维度表示“电极数”、“时间点”、“目标指数”和“区块指数”。电极位置保存在“64通道.loc”文件中。每个SSVEP频率有六个试验。40个目标索引的频率和相位值保存在“Freq_phase.mat”文件中。
所有受试者的信息都列在“Sub_info.txt”文件中。对于每个科目,有五个因素,包括“科目指数”、“性别”、“年龄”、“熟练程度”和“群体”。根据受试者在基于SSVEP的脑机接口中的经验,将受试者分为“有经验”组(8名受试者,S01-S08)和“幼稚”组(27名受试人,S09-S35)。
总结:
sub:35人
采样率:250hz
data=(64,1500,40,6):电极数”、“时间点”、“目标指数”和“区块指数
target=(1,40)
标签print一下:
[[ 8. 9. 10. 11. 12. 13. 14. 15. 8.2 9.2 10.2 11.2 12.2 13.2
14.2 15.2 8.4 9.4 10.4 11.4 12.4 13.4 14.4 15.4 8.6 9.6 10.6 11.6
12.6 13.6 14.6 15.6 8.8 9.8 10.8 11.8 12.8 13.8 14.8 15.8]] (1, 40)
类别:40
数据重塑:
(64,1500,40,6)
(64,1500,240)
(240,64,1500)
(240,1,64,1500)
数据最终以(240,1,64,1500)作为CNN的输入,240个样本,1个人工的扩维的维度,当作输入通道数=1,H=64,W=1500.
标签独热编码结果:
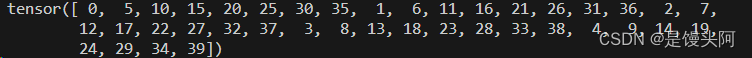
这篇关于28、清华大学脑机接口实验组SSVEP数据集:通过视觉触发BCI[飞一般的赶脚!]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





