本文主要是介绍【AI】使用阿里云免费服务器搭建Langchain-Chatchat本地知识库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
书接上文,由于家境贫寒的原因,导致我本地的GPU资源无法满足搭建Langchain-Chatchat本地知识库的需求,具体可以看一下这篇文章,于是我只能另辟蹊径,考虑一下能不能白嫖一下云服务器资源,于是去找网上找,您还别说,还真有,具体的领取方法可以查看我的这篇文章:【AI】阿里云免费GPU服务资源领取方法。
1.准备工作
1.1进入云服务器
服务器资源准备好之后就可以去做我们的开发任务了,首先在阿里云人工智能PAI控制台打开我们的实例。

打开之后如下图所示:
1.2查看服务器磁盘情况,创建本地工作目录
这一步可以省略,只是为了保险起见,我们查看一下磁盘容量及挂载情况,因为模型通常比较大,会比较浪费磁盘资源,我们先查看一下最大的磁盘资源挂载哪个目录下面,可以在那个目录下面操作我们的数据。
在主界面的Terminal页面,输入lsblk查看磁盘挂载情况:
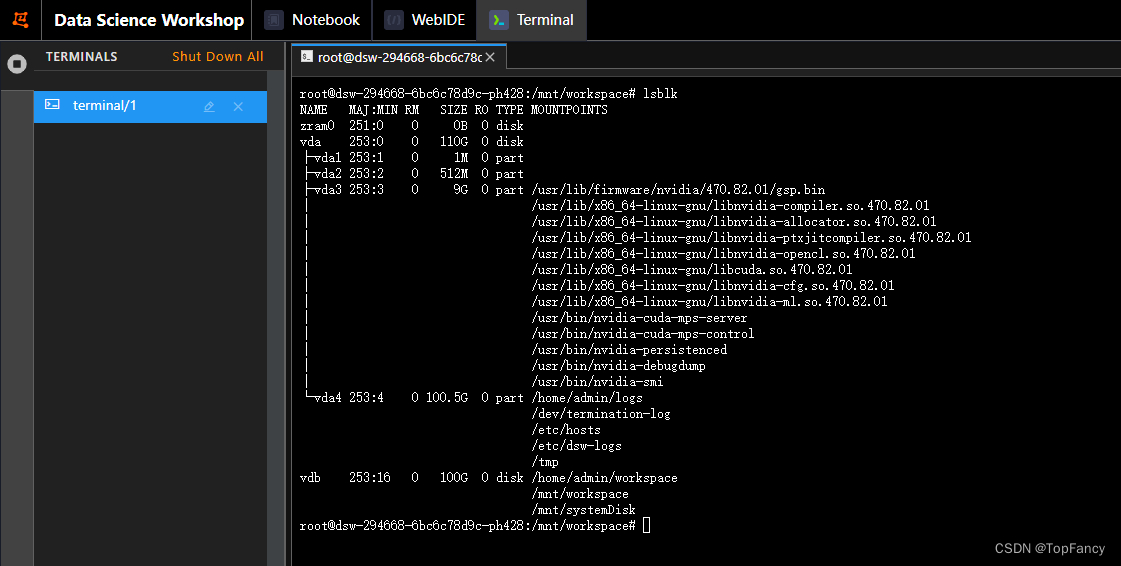
可以看到我们当前的目录/mnt/workspace是建立在100G的磁盘之上的,可以放心使用。
1.3拉取源码,并安装依赖
拉取源码可以直接使用Git工具,这个镜像中已经安装完成,不需要我们再进行安装了。
我们在工作目录下创建一个文件夹,用于我们的项目,然后再将代码拉去到这个文件夹下面。
mkdir chatchat
cd chatchat
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
# 进入项目内部
cd # 进入目录
cd Langchain-Chatchat
# 安装全部依赖
pip install -r requirements.txt
1.4下载模型文件
由于我们在服务器上,下载速度不需要担心,我们可以使用git来拉取模型文件。
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
git clone https://huggingface.co/BAAI/bge-large-zh
这里的模型文件位于huggingface,如果不具备魔法上网的能力话,是没有办法拉取下来的,所以我们换成国内镜像魔搭社区
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
git clone https://www.modelscope.cn/AI-ModelScope/bge-large-zh.git
2.运行模型
2.1 初始化知识库和配置文件
python copy_config_example.py
python init_database.py --recreate-vs
2.2 一键启动
python startup.py -a
等待模型启动
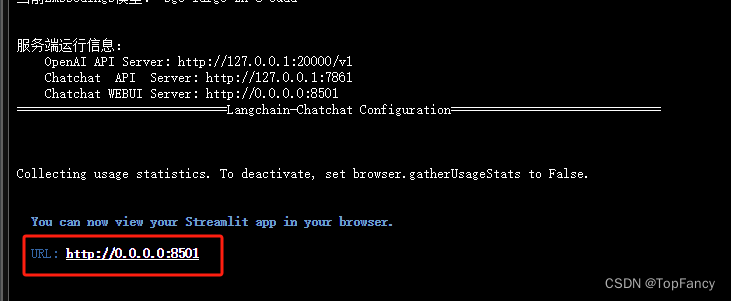
点击url就可以跳转到我们本地的浏览器,展示知识库对话界面:
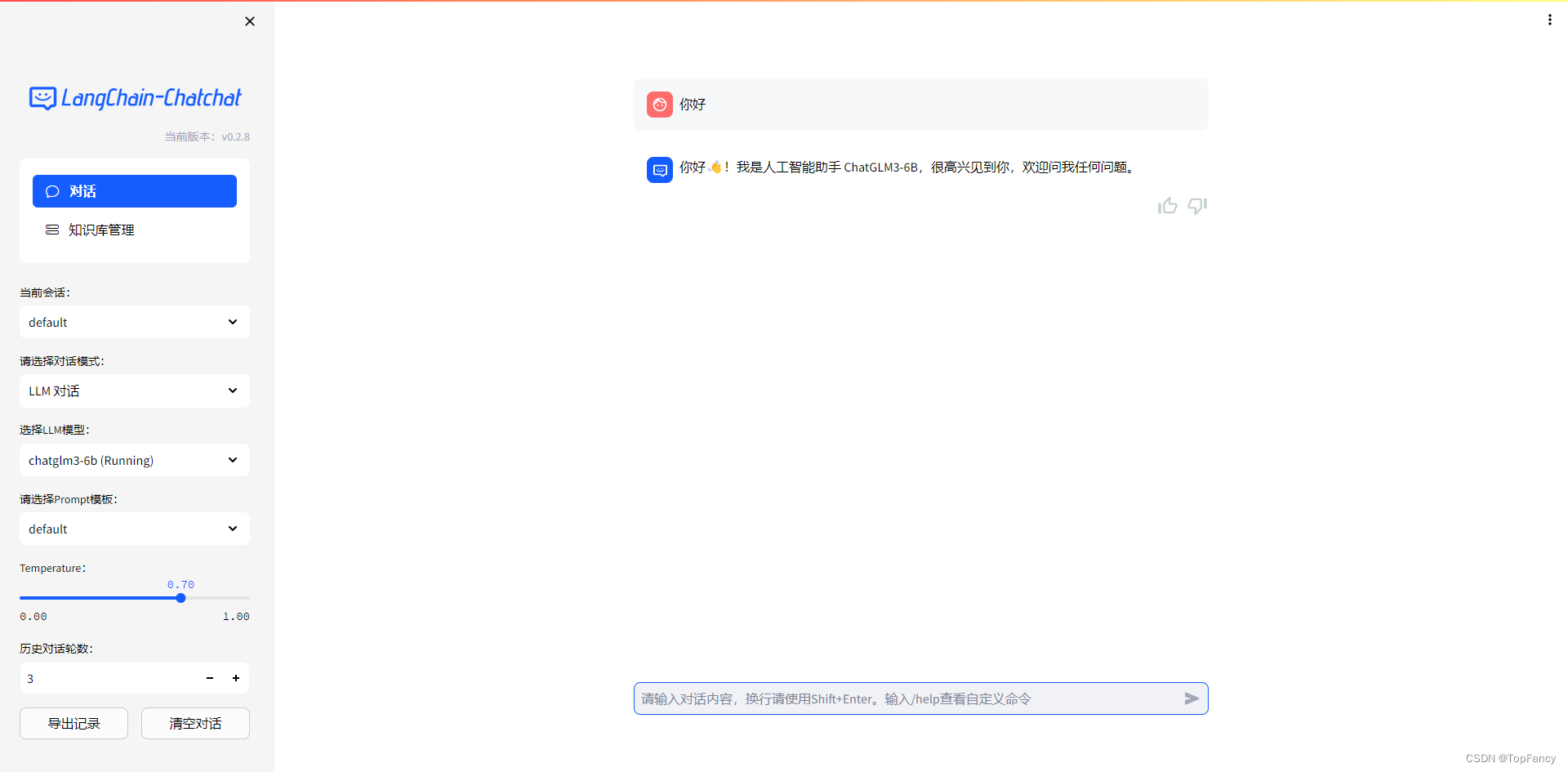
3.本地知识库
3.1 测试sample知识库
模型启动后自动创建了一个测试的知识库,我们可以用来测试一下知识库对话:
左侧侧边栏选择:
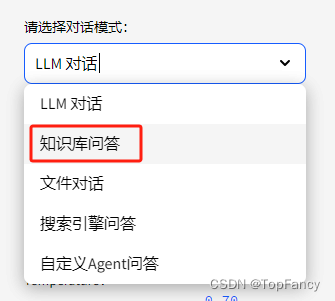
知识库这边默认就是sample知识库
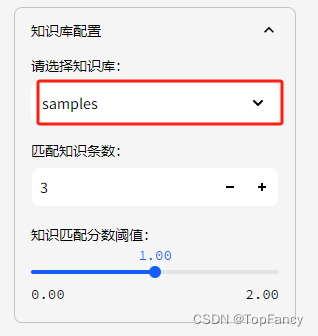
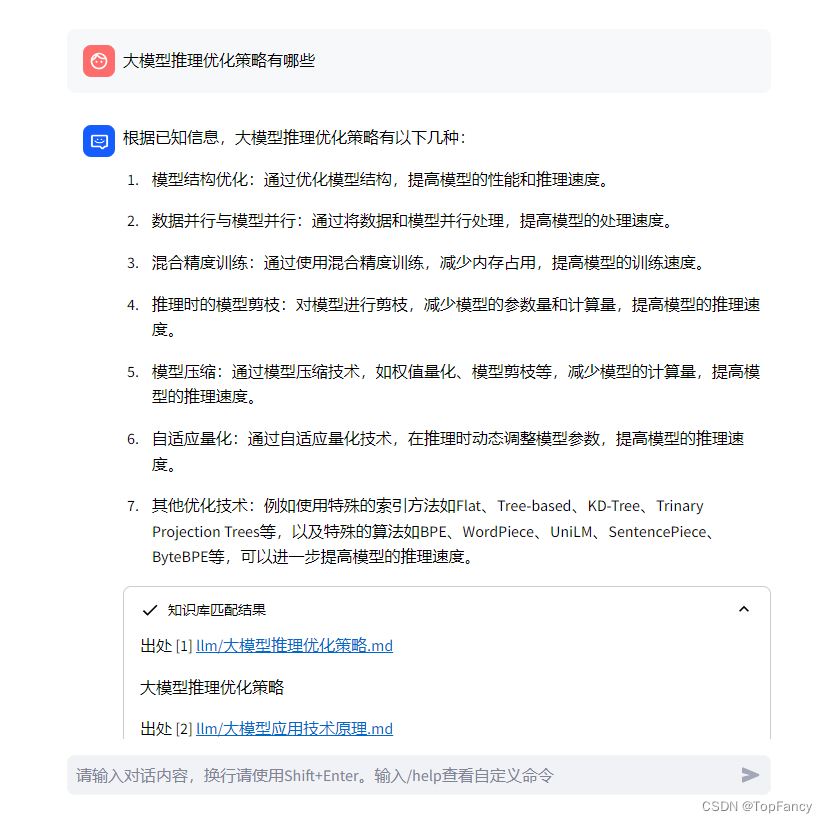
然后可以在右边的对话框中输入测试的问题了:
3.2 创建个人知识库
在知识库管理中选择新建知识库:
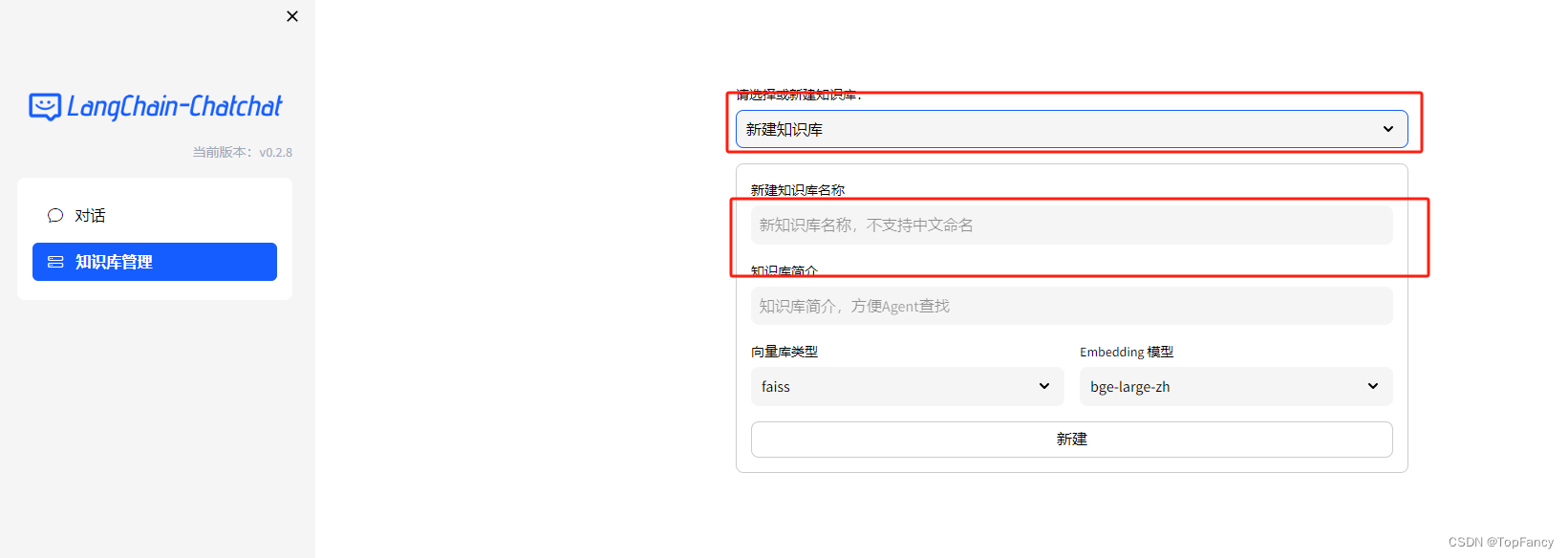
填入知识库的名字即可创建完成。
然后上传知识库文档,注意如果上传txt文档时,要注意文档编码是否是utf-8,否则容易出错
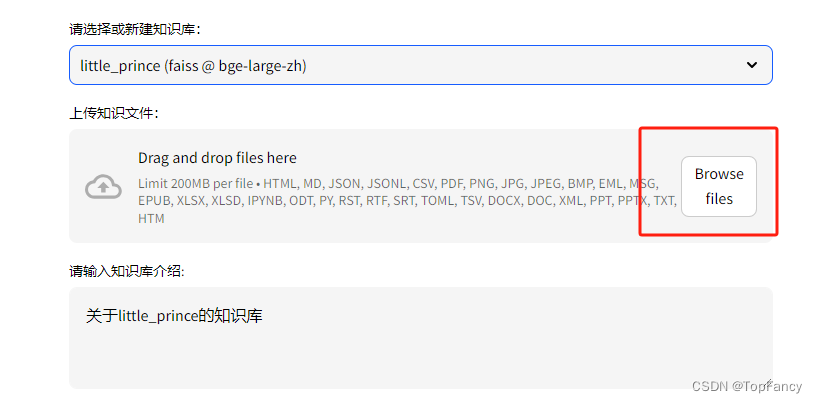
选中下图中的文档,然后点击添加至向量库,然后构建向量,点击依据源文件重建向量库完成知识库创建
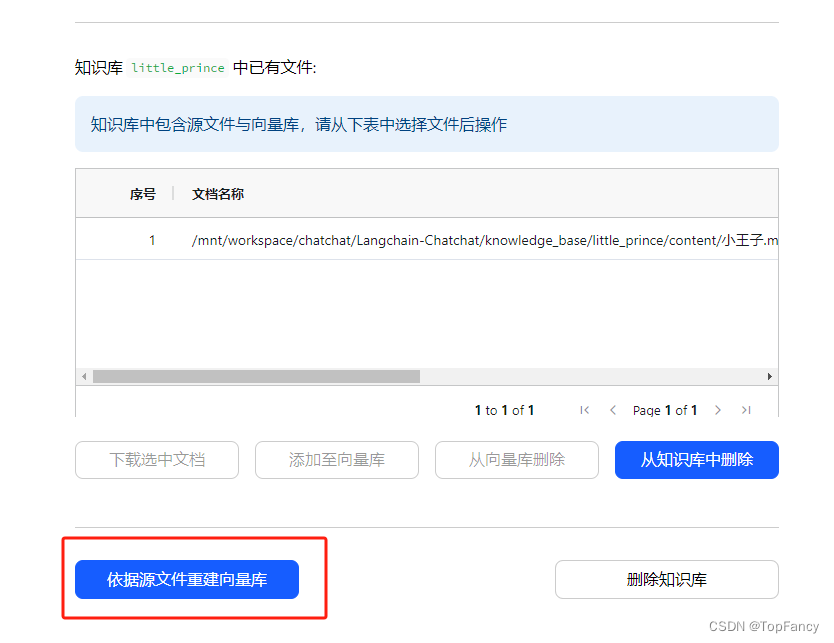
然后就可以进行本地知识库问答了。
测试中使用了ChatGLM3-6B模型和embedding模型bge-large-zh,由于显存问题,又出现了out of memory的问题,看来16g的显存也不足以满足模型运行需求。测试使用int8量化模型:
修改配置文件:
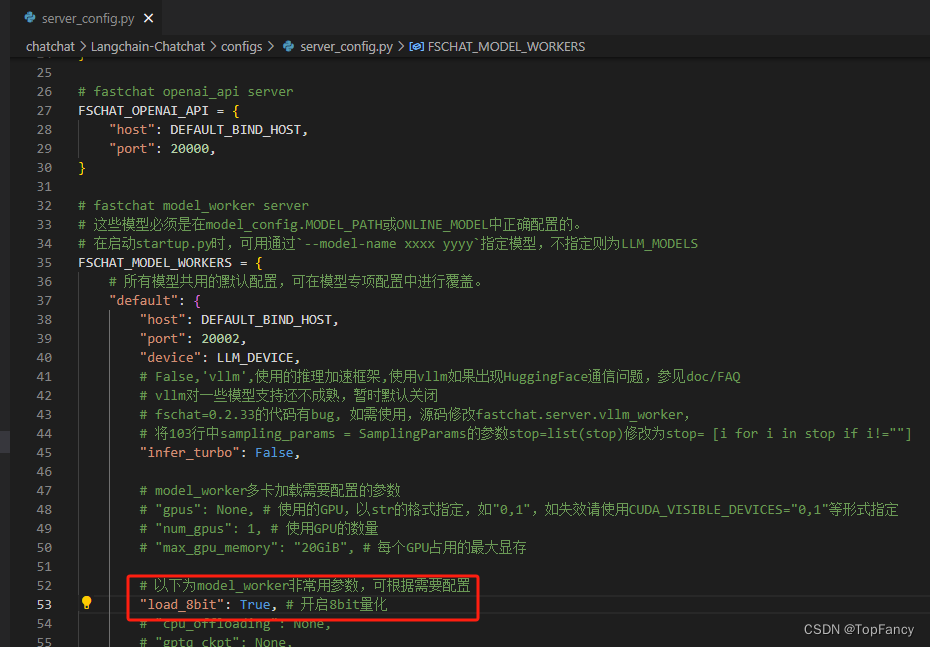
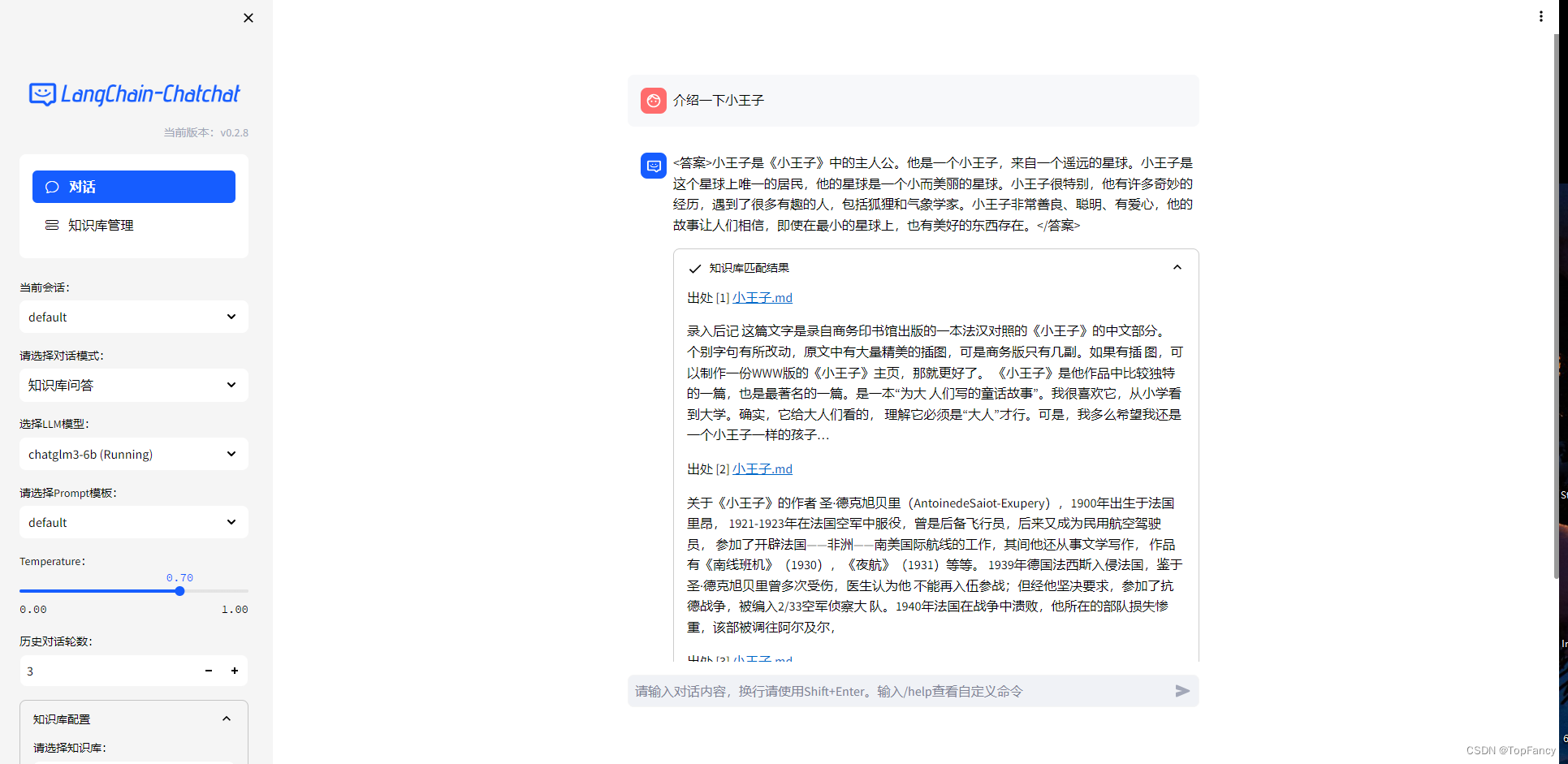
然后重新运行python startup.py -a,可以正常使用了。问答效果如下:
这篇关于【AI】使用阿里云免费服务器搭建Langchain-Chatchat本地知识库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






