本文主要是介绍论文笔记:Neural Machine Translation by Jointly Language Learning to Align and Translate,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
Attention 机制在许多领域中都有应用,这些模型都被称为 Attention Based Model,而这篇论文则是将注意力机制应用在神经网络机器翻译中,论文的思路很清楚,首先介绍了传统NMT系统的缺陷,然后针对这一缺陷提出改进,最后实验证明,并进行定量以及定性分析。
首先我们要了解经典的Seq2Seq模型是如何进行翻译的:整体模型使用了一个 Encoder 和一个 Decoder 首先输入的序列经过 Encoder 的处理,压缩成为一个固定长度的向量(Fixed-length Vector),然后在 Decode 阶段,将这个向量中的信息还原成一个序列,从而完成翻译任务。
在这里我们需要尤其注意这个定长向量,可以想象,对于不同长度的句子,在模型中却要将提取的全部信息放在同样长度的向量中,这本身就是不太合理的,一个长度50的句子和一个长度5的句子信息量怎么会在同样长度的向量中合适地表达呢?这也是论文中提到的,在测试的时候,对于长度大于30的句子,RNN Encoder-Decoder 机制的模型就有些力不从心了,因此引入了注意力机制,在 Decode 过程中,仍然可以直接参考原始句子序列中相关的部分。
在学习过程中,看到了这样的说法,使用 Attention 机制进行翻译的过程,就像是人进行翻译的过程,我们在翻译一个长句子的时候,假设翻译到某一个时刻,忘了要翻译的内容,我们会回过头去,找到原始句子的那一部分,然后再决定如何让翻译,Attention 机制解释了这一过程,实验证明,这一方式是非常有效的。
之前参考了一些代码,学习了一下 Seq2Seq + Attention 的代码实现,只能说,即使是论文的模型构建方式懂了,真正落地到代码也还有很长的一段路要走,果然还是要再努力一点啊。
1. Abstract & Introduction & Background
这一部分简要介绍了NMT一些基础共性,论文中提到,目前(当时)的 NMT 模型都属于 Encoder-Decoders 家族,模型的思路本质上就是最大化条件概率: P ( o u t p u t _ s e n t e n c e ∣ i n p u t _ s e n t e n c e ) P(output\_sentence|input\_sentence) P(output_sentence∣input_sentence),而使用固定长度向量来存储信息的做法,就像之前所说的,固定长度的限制无法储存足够多的信息,这就成为了一个瓶颈(Bottleneck)。在生成输出序列的时候,每次模型都只生成一个单词,在生成的时候使用 (soft-)search 的方法搜索输入序列中与要翻译内容最相关的部分,其实也就是 Attention 的思想了。
文中对 Neural Machine Translation 进行了介绍,首先是介绍了概率角度的机器翻译任务(就是最大化那个条件概率),然后对 RNN Encoder-Decoders 模型进行了介绍,并提到,通过使用一些更优秀的循环单元(LSTM),是的这些模型相较之前都有了很大的提升,这里还简单提了 RNN Encoder-Decder 的公式之类的,推荐更深的了解直接看之前的论文,例如 《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
Learning to Align and Translate
第三部分切入正题,这里介绍的顺序是先 Decoder 然后是 Encoder (这算是自顶向下吗?)。首先来看这张图(论文中 Figure 1):
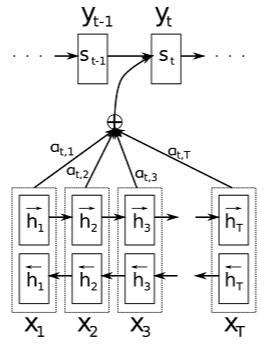
所有的信息都在这张图上了。
Decoder
首先来看 Decoder 部分,这里使用的就是一个简单的 RNN 单元, 只是要注意隐状态的改变:
s i = f ( s i − 1 , y i − 1 , c i ) s_{i}=f(s_{i-1},y_{i-1},c_{i}) si=f(si−1,yi−1,ci)
可以看到,某个时间点上输入的隐状态由三个因素共同决定:
- 第一个是上一步的隐状态输出 ( s i − 1 s_{i-1} si−1) 。
- 第二个是上一步的直接输出( y i − 1 y_{i-1} yi−1)。
- 第三个是来自 Encoder 部分所有输出的一个处理结果 ( c i c_{i} ci)。
这一步还是很好理解的,很显然, 问题就在于如何表示来自于 Encoder 部分的输出信息,因为之前提到过,对于输出环节的每一个词语,我们都要找到输入序列的部分信息,然后再决定输出什么。也就是如何表示向量C了。
c i = ∑ j = 1 T x α i j h j c_{i} = \sum_{j=1}^{T_{x}}\alpha_{ij}h_{j} ci=j=1∑Txαijhj
这里可以看到对于某一步 i i i,对应的 c i c_{i} ci 实际上是一个加权和的形式,与当前步相关大的部分权值大,不太相关的则权值小,这样的过程就是 Attention 的体现,在文中也称 (soft-)search。另一个问题的这个 α i j \alpha_{ij} αij 如何计算,在论文中公式(6)可以看出,每一个权值都是对当前步的隐状态(Decoder阶段)和所有步的隐状态(Encoder阶段)经过一个变换的结果这个变换有必要提一下,这里的变换,也就是公式(6)中的 a ( ) a() a() 有很多实现形式,例如计算余弦距离, 或者是通过一个简单全连接神经网络的形式,这时候也就是 e i j = s i − 1 W h j e_{ij}=s_{i-1}Wh_{j} eij=si−1Whj 了,等等。然后对这一批权值,做一个softmax处理,(处理成一个概率分布,相当于一个标准化,不然不同的权值第一步(1,2,3),第二步(100, 200, 300)显得太不平衡了)。
(PS:关于这里 Attention 的权值计算方式,在实现时候多有不同,我见的代码有不使用decoder阶段隐状态而是用decoder阶段输出与encoder所有的输出计算权值的,所以,我觉得理解这个意思就好了,一定程度上不必把所有的细节都完全与论文一样,当然,完全论文复现还是尽量这样的,我的意思只是学习的过程中。。)
另外,更具体的过程可以参考附录部分。
Encoder
Encoder阶段就非常好理解了,这里没有直接使用RNN,而是使用了一个 BiRNN 网络实现,双向循环网络可以更好地捕捉文本上下文信息嘛。这样的话,每一步上Encoder都会有两个输出,这里的处理很简单,直接把两个输出结果 concatenate,也就是论文3.2节中双向箭头那部分向量,把这个拼接后的向量作为我们上面提到的计算 Attention 权重的 h j h_{j} hj 部分。
Experiment Settings
这一部分介绍实验中的一些设置,主要包括两部分,第一部分介绍使用的数据集,第二部分展示了实验中模型的一些参数。
第一部分对于数据集的处理,文中表示对数据集并没有进行一些特殊的操作,首先是数据集选择,去掉了一些不合适的数据,第二步进行分词,然后选择其中最常见的30000词构建词典,这里强调了没有进行其他特殊操作,例如统一对数据小写处理,以及词干化等。
第二部分介绍了实验中的一些参数以及对比模型等。既然是对比试验,文中设计了两类模型,每一种模型又按照长度分为两种(长度不超过30、长度不超过50),分别是:
- RNN encdec-30
- RNN search-30
- RNN encdec-50
- RNN search-50
具体参数可以看论文这一部分,更具体的参数记录在附录中,这一部分最后也提到了,对于每一个模型,训练了大概5天。。。果然学习最后还是要靠硬件吗。。
Results
感觉这一部分才是论文的核心,对于实验数据的分析,这里分了两部分,第一部分是定量分析(quantitative analysis),第二部分是定性分析(qualitative analysis),这两种分析方法经常在论文中出现。
首先是定量分析,这一部分主要是摆数据,验证论文新模型的效果,第一个表展示了不同模型的 BLEU 分数,对比的基准模型是非常常见的传统模型 Moses,表中分了两类,第一类是只包含词典词语的结果,第二类是包含 unknown 词的结果,结果来看,在更普遍情况下(含 UNK),论文提出的 RNN search-50有最好的结果。第二个实验比较了句子长度增长对模型性能的影响,就像之前分析的结果,确实在最开始,所有模型的结果是差不多的,但是当句子长度增大到20~30以及之后时,采用传统 Encoder-Decoder 模式的模型效果迅速下降,当然 RNNsearch-50 保持了分数稳定。
第二部分进行的是定性分析,这里一开始提到了一个概念:对齐(Alignment),又提到了论文中提出的方法是对(soft-)alignment 的一种很直观的解释,关于这个对齐,我的理解就是输出序列中单词与输入序列中单词的对应关系,这里的 软对齐 ,我的理解是有两层意思吧,第一层是指输出序列中一个单词可能会对应输入序列中的多个单词或者相反,第二层意思是两个序列次序不同的问题,这一点在论文的这一部分有介绍。此外,论文中这一部分给出了两个序列的权重关系图,可以说是非常直接明了了,所以有种说法是 Attention 机制实际上是对翻译过程的形象展示(翻译任务),因为之前的模型方法我们并不清楚模型内部是如何进行转化的,但是 Attention 解释了这个。
在这一部分还直接使用长句子的例子展示了不同的模型的处理结果(具体句子可以看附录),也算是针对之前的介绍的具体解释吧。
Related Work & Conclusion
这一部分,论文中提到,之前使用神经网络的方式进行机器翻译的过程,往往都是作为现有的统计翻译模型的一个组件,例如提供额外特征,或者对候选翻译重新打分等等,但是,作者们提到,完全可以只依赖神经网络方式建立完整的翻译系统。
结论部分就是对之前的各部分工作做了一个总结。
这篇关于论文笔记:Neural Machine Translation by Jointly Language Learning to Align and Translate的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






