本文主要是介绍基于networkx的《人民的名义》人物关系图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# -*- coding: utf-8 -*-
"""
Created on Wed May 3 12:58:30 2017
https://zhuanlan.zhihu.com/p/24767513 参考链接
@author: chuc
"""
import networkx as nx
import matplotlib.pyplot as pltimport jieba
import codecs
import jieba.posseg as psegnames = {} # 姓名字典
relationships = {} # 关系字典
lineNames = [] # 每段内人物关系# count names
jieba.load_userdict("some/person.txt") # 加载字典
with codecs.open("some/people.txt", "r") as f:for line in f.readlines():poss = pseg.cut(line) # 分词并返回该词词性lineNames.append([]) # 为新读入的一段添加人物名称列表for w in poss:if w.flag != "nr" or len(w.word) < 2:continue # 当分词长度小于2或该词词性不为nr时认为该词不为人名lineNames[-1].append(w.word) # 为当前段的环境增加一个人物if names.get(w.word) is None:names[w.word] = 0relationships[w.word] = {}names[w.word] += 1 # 该人物出现次数加 1# explore relationships
for line in lineNames: # 对于每一段for name1 in line: for name2 in line: # 每段中的任意两个人if name1 == name2:continueif relationships[name1].get(name2) is None: # 若两人尚未同时出现则新建项relationships[name1][name2]= 1else:relationships[name1][name2] = relationships[name1][name2]+ 1 # 两人共同出现次数加 1with codecs.open("some/person_edge.txt", "a+", "utf-8") as f:for name, edges in relationships.items():for v, w in edges.items():if w > 20:f.write(name + " " + v + " " + str(w) + "\r\n")a = []
f = open('some/person_edge.txt','r',encoding='utf-8')
line = f.readline()
while line:a.append(line.split()) #保存文件是以空格分离的line = f.readline()f.close()
G = nx.Graph()
G.add_weighted_edges_from(a)
nx.draw(G,with_labels=True,font_size=12,node_size=1000,node_color='g')
plt.show()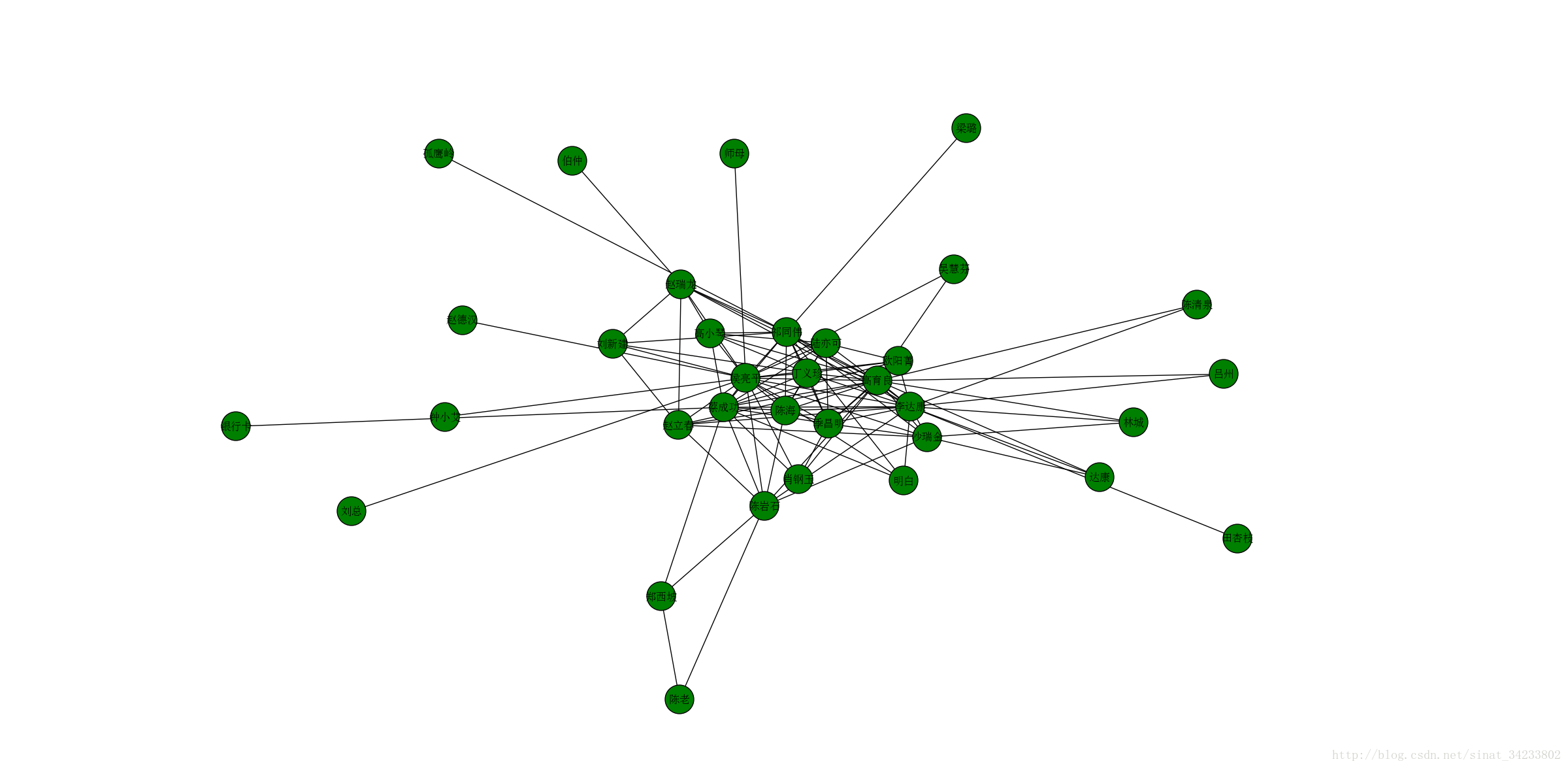
这篇关于基于networkx的《人民的名义》人物关系图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






