本文主要是介绍决策树DT:ID3、C4.5原理及python实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 决策树模型与学习
- 特征选择
- 信息增益
- 信息增益比
- ID3算法
- 决策树生成
- ID3算法的不足
- C4.5算法
- 连续值处理
- 缺失值处理
- C4.5算法的不足
- 决策树剪枝
- 程序实现ID3
决策树模型与学习
决策树分类: 从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到对应子节点;若子节点为特征的一个取值,则递归的对实例进行测试并分配,直到到达叶节点(类别)。
决策树与条件概率分布(判别式模型) 特征空间被划分为互不相交的区域,每个区域定义一个类的概率分布,从而构成了一个条件概率分布。
各区域(叶节点)上的条件概率偏向于一个类,决策树分类时,强行将节点的实例划分为条件概率较大的一类。
特征选择
特征选择在于选取具有分类能力的特征,使得每次分割之后,各分支节点所含样本尽可能属于同一类别。这样可加快决策树的生成。
信息增益
信息熵(Information Entropy)是表示随机变量纯度/不确定性的指标。设 X X X为有限取值的随机变量(类别),其概率分布(类别比例)
P ( X = x i ) = p i , ( i = 1 , 2 , ⋯   , ∣ Y ∣ ) P(X=x_i)=p_i, \quad (i = 1, 2, \cdots, \mathcal{|Y|}) P(X=xi)=pi,(i=1,2,⋯,∣Y∣)
则随机变量 X X X的信息熵记作 H ( X ) H(X) H(X),即
H ( X ) = − ∑ i = 1 ∣ Y ∣ p i log 2 p i H(X)=-\sum_{i=1}^{\mathcal{|Y|}}p_i\log_2p_i H(X)=−i=1∑∣Y∣pilog2pi
熵的取值与随机变量取值无关,仅与其概率分布有关。熵值越小,不确定性越低、数据集纯度越高。 0 ≤ H ( p ) ≤ log ∣ Y ∣ 0 \leq H(p) \leq \log \mathcal{|Y|} 0≤H(p)≤log∣Y∣。
设有随机变量 ( X , Y ) (X, Y) (X,Y),其联合概率分布
P ( X = x i , Y = y i ) = p i j P(X = x_i, Y = y_i)=p_{ij} P(X=xi,Y=yi)=pij
随机变量X和Y的条件熵
H ( Y ∣ X ) = − ∑ i = 1 n ∑ j = 1 m p ( x i , y i ) log 2 p ( y i ∣ x i ) = − ∑ i = 1 n ∑ j = 1 m p ( x i ) p ( y i ∣ x i ) log 2 p ( y i ∣ x i ) = ∑ i = 1 n p ( x i ) H ( Y ∣ X = x i ) \begin{aligned} H(Y|X) &= - \sum_{i=1}^n \sum_{j=1}^m p(x_i, y_i) \log_2 p(y_i | x_i) \\ & = - \sum_{i=1}^n \sum_{j=1}^m p(x_i)p(y_i|x_i) \log_2 p(y_i | x_i) \\ & = \sum_{i=1}^n p(x_i) H(Y|X=x_i) \end{aligned} H(Y∣X)=−i=1∑nj=1∑mp(xi,yi)log2p(yi∣xi)=−i=1∑nj=1∑mp(xi)p(yi∣xi)log2p(yi∣xi)=i=1∑np(xi)H(Y∣X=xi)
条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)表示已知 X X X的条件下 Y Y Y的不确定性,上式为已知 X X X的条件下 Y Y Y的条件概率分布的熵对 X X X的数学期望。当熵和条件熵由数据估计得到时,熵和条件熵分别称为经验熵和经验条件熵。
信息增益度量得知特征 X X X而使得类 Y Y Y不确定性减少的程度,定义为样本集 D D D的经验熵与已知特征 a a a条件下 D D D的经验条件熵之差,即
g ( D , a ) = H ( D ) − H ( D ∣ a ) g(D,a)=H(D)-H(D|a) g(D,a)=H(D)−H(D∣a)
注:信息增益亦称为类与特征的互信息。
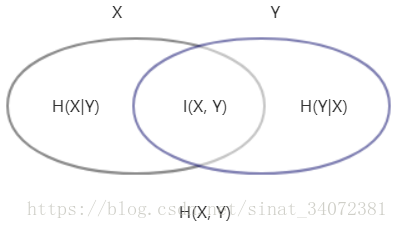
最优划分属性应使划分后的样本信息增益/纯度最大(不确定性降低),即条件熵取最小
a o p t = arg min A ∑ v = 1 V p v H ( Y ∣ X = x v ) a_{opt} = \arg \min_A \sum_{v=1}^Vp_vH(Y|X=x_v) aopt=argAminv=1∑VpvH(Y∣X=xv)
可见,信息增益准则偏好于取值较多的属性(V较大)。
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
由上表可知,类别 ∣ Y ∣ = 2 \mathcal{|Y|}=2 ∣Y∣=2,信息熵
H ( D ) = − 8 17 log 2 8 17 − 9 17 log 2 9 17 = 0.998 H(D)=-\frac{8}{17} \log_2\frac{8}{17} -\frac{9}{17} \log_2\frac{9}{17} = 0.998 H(D)=−178log2178−179log2179=0.998
若选择色泽作为划分属性,色泽包含的属性值有{青绿,乌黑,浅白},分别标记位 D 1 D_1 D1、 D 2 D_2 D2、 D 3 D_3 D3,则
g ( D , 色 泽 ) = H ( D ) − ( 6 17 H ( D 1 ) + 6 17 H ( D 2 ) + 5 17 H ( D 3 ) ) = 0.998 − 1 17 [ 6 ( − 3 6 log 2 3 6 − 3 6 log 2 3 6 ) + ( − 4 6 log 2 4 6 − 2 6 log 2 2 6 ) + ( − 4 5 log 2 4 5 − 1 5 log 2 1 5 ) ] = 0.109 \begin{aligned} g(D, 色泽) &= H(D) - \left(\frac{6}{17}H(D_1)+ \frac{6}{17}H(D_2) + \frac{5}{17}H(D_3)\right) \\ & = 0.998 - \frac{1}{17} \left[ 6\left( -\frac{3}{6} \log_2 \frac{3}{6} -\frac{3}{6} \log_2 \frac{3}{6} \right) + \left( -\frac{4}{6} \log_2 \frac{4}{6} -\frac{2}{6} \log_2 \frac{2}{6} \right) + \left( -\frac{4}{5} \log_2 \frac{4}{5} -\frac{1}{5} \log_2 \frac{1}{5} \right) \right] \\ & = 0.109 \end{aligned} g(D,色泽)=H(D)−(176H(D1)+176H(D2)+175H(D3))=0.998−171[6(−63log263−63log263)+(−64log264−62log262)+(−54log254−51log251)]=0.109
同理,可计算出其他特征的信息增益,其中具有最大信息增益的属性为 g ( D , 纹 理 ) = 0.381 g(D, 纹理)=0.381 g(D,纹理)=0.381。因此,使用纹理特征对样本集进行划分,所得样本的不确定性最小。
信息增益比
极端情况下,若样本集含n个样本,离散属性a含n个属性。若使用属性a分割样本集,则所得各分支节点的信息熵均为0,此时划分后的样本集纯度最大。但每个分支节点仅含1个样本,所得决策树无泛化能力。
定义增益率为特征 a a a的信息增益 g ( D , a ) g(D, a) g(D,a)与训练集 D D D关于特征 a a a的值的熵 H a ( D ) H_a(D) Ha(D)之比,即
g R ( D , a ) = g ( D , a ) H a ( D ) g_R(D, a) = \frac{g(D, a)}{H_a(D)} gR(D,a)=Ha(D)g(D,a)
其中分母项为特征a的信息熵 H a ( D ) = ∑ i = v V ∣ D v ∣ D ∣ log 2 D v D H_a(D) = \sum_{i=v}^V\dfrac{|D_v}{|D|} \log_2\dfrac{D_v}{D} Ha(D)=∑i=vV∣D∣∣Dvlog2DDv。
属性a的取值越多,分母可能越大,增益率准则偏好于较少取值多的属性。因此,最优分割属性应同时具有较高信息增益和增益比,如C.5算法先选择信息增益高于平均值的属性,再从中选择增益率高的属性。
ID3算法
决策树生成
输入:训练集 D D D,特征集 A A A,阈值 ε \varepsilon ε
输出:决策树 T T T
递归生成决策树算法,如下:
- 若数据集 D D D中所有实例均属于同一类 C k C_k Ck,则 T T T为单节点树(叶节点),将类别 C k C_k Ck作为节点类标记,返回 T T T;
- 若特征集 A A A为空,则 T T T为单节点树,将 D D D中含样本最多的类别 C k C_k Ck作为其类标记,返回 T T T;
- 计算 A A A中各特征的信息增益,选择信息增益最大的特征 a o p t a_{opt} aopt对样本集 D D D进行划分;
- 若 a o p t a_{opt} aopt的信息增益小于阈值 ε \varepsilon ε,则置 T T T为单节点树,将 D D D中含样本最多的类别 C k C_k Ck作为其类标记,返回 T T T;
- 否则,使用 a o p t a_{opt} aopt的 V V V个不同属性值将 D D D划分为 V V V个不同的子集 D v D_v Dv,每个子集均为节点的一个分支;
- 对所有分支节点,令 D = D v D=D_v D=Dv、 A = A − a o p t A=A-a_{opt} A=A−aopt,递归调用上述步骤,得到分支树并返回;
ID3算法的不足
- 未考虑具有连续值的属性;
- 极端情况下选择信息增益最大的属性(完全随机性变量)会使模型失去泛化能力;
- 未考虑缺失值处理与过拟合问题;
C4.5算法
C4.5对ID3算法进行了改进,使用信息增益比选择每次划分数据集的最优特征,并对缺失值和过拟合问题进行了处理。
连续值处理
- 将连续值离散化,如m个样本的特征 a a a有 m m m个不同的属性值,将属性值升序排列为 a 1 , ⋯   , a m a_1,\cdots,a_m a1,⋯,am;
- 取相邻属性值的均值作为划分点,共计 m − 1 m-1 m−1个,每个划分点 t t t可将 D D D分为子集 D t − D_t^- Dt−和 D t + D_t^+ Dt+;
- 分别计算 m − 1 m-1 m−1个划分点作为二元分类的信息增益,取信息增益最大的点作为分类点;
g R ( D , a ) = max t ∈ T a g R ( D , a , t ) = max t ∈ T a ( H ( D ) − ∑ λ ∈ { − , + } ∣ D t λ ∣ ∣ D ∣ H ( D t λ ) ) g_R(D, a) = \max_{t \in T_a} g_R(D, a, t) = \max_{t \in T_a} (H(D)- \sum_{\lambda \in \{-, +\}} \frac{|D_t^\lambda|}{|D|}H(D_t^\lambda)) gR(D,a)=t∈TamaxgR(D,a,t)=t∈Tamax(H(D)−λ∈{−,+}∑∣D∣∣Dtλ∣H(Dtλ)) - 以连续属性划分的节点,连续属性还可作为其后代节点的划分属性;
缺失值处理
如何在属性值缺失的情况下选择最优划分属性?
给定训练集 D D D和属性 a a a,令 D ~ \tilde D D~表示 D D D在属性 a a a上没有缺失值的样本子集,每个样本 x x x的权重为 w x w_x wx(初始为1),则
ρ = ∑ x ∈ D ~ w x ∑ x ∈ D w x   p ~ k = ∑ x ∈ D ~ k w x ∑ x ∈ D ~ w x ( 1 ≤ k ≤ ∣ Y ∣ )   r ~ v = ∑ x ∈ D ~ v w x ∑ x ∈ D ~ w x ( 1 ≤ v ≤ V ) \begin{aligned} \rho &= \frac{\sum_{x \in \tilde D} w_x}{\sum_{x \in D} w_x} \\ \,\\ \tilde p_k &= \frac{\sum_{x \in \tilde D_k} w_x}{\sum_{x \in \tilde D} w_x} \quad(1 \leq k \leq |\mathcal{Y}|) \\ \,\\ \tilde r_v &= \frac{\sum_{x \in \tilde D^v} w_x}{\sum_{x \in \tilde D} w_x} \quad (1 \leq v \leq V) \end{aligned} ρp~kr~v=∑x∈Dwx∑x∈D~wx=∑x∈D~wx∑x∈D~kwx(1≤k≤∣Y∣)=∑x∈D~wx∑x∈D~vwx(1≤v≤V)
式中, ρ \rho ρ表示未缺失值比例、 p ~ k \tilde p_k p~k表示 D ~ \tilde D D~中类别为 k k k的样本比例、 r ~ v \tilde r_v r~v表示 D ~ \tilde D D~中属性 a a a取值为 a v a_v av的样本比例。
因此缺失值属性a的信息增益推广为
g ( D , a ) = ρ × g ( D ~ , a ) = ρ × ( H ( D ~ ) − ∑ v = 1 V r ~ v H ( D ~ v ) ) , H ( D ~ v ) = − ∑ k = 1 ∣ Y ∣ p ~ k log 2 p k g(D, a) = \rho \times g(\tilde D, a) = \rho \times \left(H(\tilde D) - \sum_{v=1}^V \tilde r_v H(\tilde D^v) \right), \quad H(\tilde D^v) =-\sum_{k=1}^{|\mathcal{Y}|} \tilde p_k \log_2 p_k g(D,a)=ρ×g(D~,a)=ρ×(H(D~)−v=1∑Vr~vH(D~v)),H(D~v)=−k=1∑∣Y∣p~klog2pk
给定划分属性,若样本在该属性上值缺失,如何对样本进行分配?
若样本 x x x在划分属性 a a a上取值已知,则将 x x x划入其取值对应的子节点,样本权值保持不变;若取值未知则将样本 x x x划分到所有分支节点,样本权值在 a v a^v av的分支节点中调整为 r ~ v ⋅ w x \tilde r_v \cdot w_x r~v⋅wx。
直观上,同一样本以不同概率分配到不同的分支节点。
C4.5算法的不足
- 生成的决策树为多叉树(一个父节点含多个子节点),没有二叉树模型效率高;
- 只能用于分类,不能用于回归;
- 使用熵模型选取最优划分属性,计算复杂,尤其是处理连续值属性;
决策树剪枝
一般情况下递归产生的决策树对训练数据的分类很准确,但有可能对未知数据的分类表现很差。上述现象称为过拟合,一般通过简化决策树复杂度(剪枝)解决。
预剪枝
在划分之前,评估单节点树以及节点按属性值展开后的预测精度,若单节点树的预测精度不低于展开后树的预测精度,则将该节点作为叶节点。
后剪枝
定义决策树的损失函数如下:
C α ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ = C ( T ) + α ∣ T ∣ , H t ( T ) = − ∑ k N t k N t log N t k N t C_\alpha(T) = \sum_{t=1}^{|T|}N_tH_t(T)+\alpha |T| = C(T) + \alpha |T|, \quad H_t(T)=-\sum_k \frac{N_{tk}}{N_t} \log \frac{N_{tk}}{N_t} Cα(T)=t=1∑∣T∣NtHt(T)+α∣T∣=C(T)+α∣T∣,Ht(T)=−k∑NtNtklogNtNtk
式中, ∣ T ∣ |T| ∣T∣为叶节点数目(模型的复杂度), t t t是树 T T T的叶节点, N t N_t Nt为节点 t t t所含样本数, N t k N_{tk} Ntk为 t t t节点中类别为 k k k的样本数, k = 1 , 2 , ⋯   , K k=1,2,\cdots,K k=1,2,⋯,K, H t ( T ) H_t(T) Ht(T)为 t t t节点的经验熵,可变参数 a ≥ 0 a \geq 0 a≥0, C ( T ) C(T) C(T)为模型对训练数据的预测误差。
参数 α \alpha α的值可平衡模型复杂度和训练误差。 α = 0 \alpha=0 α=0时,表示不考虑模型复杂程度,只考虑训练误差。较大的 α \alpha α偏向于较简单的模型( T T T小,训练误差大),较小的 α \alpha α偏向于较复杂的模型( T T T大,训练误差小)。
决策树的生成只考虑拟合效果(局部模型),而决策树剪枝是通过优化损失函数。
程序实现ID3
from collections import Counter
from itertools import chain
from math import log2import numpy as npfrom_iterable = chain.from_iterabledef cal_entropy(array):"""计算信息熵"""total = 1. * len(array)ent = 0.0for value in Counter(array).values():prob = value / totalent -= prob * log2(prob)return entdef cal_gain(feat_values, categories):"""计算某特征的信息增益"""uniques = set(feat_values)nums = len(uniques)feat_dict = dict(zip(uniques, range(nums)))# 提取各特征值的子集sub_labels = [[] for _ in range(nums)]for value, category in zip(feat_values, categories):sub_labels[feat_dict[value]].append(category)# 计算条件熵cond_ent = 0.0total = len(categories)for array in sub_labels:cond_ent += cal_entropy(array) * len(array) / total# 返回信息增益return cal_entropy(categories) - cond_entdef tree_depth(tree):"""计算决策树深度,字典形式存储"""if isinstance(tree, dict):branches = [value for value in tree.values()][0]return max(tree_depth(node) for node in branches.values()) + 1else:return 1class DecisionTree_ID3:def __int__(self):self.tree = Nonepassdef train(self, X, y, names=None):self._feat_names = ['FEAT_{}'.format(i) for i inrange(len(X[0]))] if names is None else namesunique = list(set(y))category2num = dict((category, num) for category, num inzip(unique, range(len(unique))))self._names = uniquecategories = [category2num[i] for i in y]data_set = np.hstack((X, np.array([categories]).T))# 生成决策树self.tree = self._make_tree(data_set, self._feat_names)def _make_tree(self, data_set, feat_names):"""生成决策树"""categories = data_set[:, -1]# 当前节点包含的样本为同一类别category = categories[0]if np.all(categories == category):return self._names[int(category)]# 当前属性集为空,返回样本中频数最大的类别if len(data_set[0]) == 1:return Counter(categories).most_common(1)[0][0]best_num = self.best_feat(data_set)best_name = feat_names[best_num]# 以当前节点为根的树my_tree = {best_name: {}}node = my_tree[best_name]# 最优特征values = data_set[:, best_num]# 遍历各属性值data_set = np.delete(data_set, best_num, axis=1)feat_names = np.delete(feat_names, best_num)for value in set(values):sub_data_set = data_set[values == value]node[value] = self._make_tree(sub_data_set, feat_names)return my_treedef best_feat(self, data_set):"""计算最优特征,ID3算法每次选取信息增益最大的特征"""categories = data_set[:, -1]nums = len(data_set[0]) - 1gains = [cal_gain(data_set[:, i], categories) for i in range(nums)]# 找到最大信息增益特征的所在列位置num = 0max_gain = gains[0]for i, gain in enumerate(gains[1:]):if max_gain < gain:num = i + 1max_gain = gainreturn numif __name__ == '__main__':X = [['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑'],['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑'],['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘'],['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘'],['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑'],['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑'],['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘'],['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑'],['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘'],['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑'],['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑'],['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘'],['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑'],['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']]y = ['好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '好瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜','坏瓜', '坏瓜', '坏瓜', '坏瓜', '坏瓜']names = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']tree = DecisionTree_ID3()tree.train(X, y, names)print(tree.tree) # print(tree_depth(tree.tree))
这篇关于决策树DT:ID3、C4.5原理及python实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






