本文主要是介绍如何利用数据分析提高英雄联盟的胜率,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文将利用外服的18w场英雄联盟(LOL)比赛的数据来进行数据分析,看看如何能帮助我们提升胜率。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warningswarnings.filterwarnings('ignore')
%matplotlib inline
plt.style.use('ggplot')首先读入我们的数据:
champs = pd.read_csv('./data/champs.csv')
matches = pd.read_csv('./data/matches.csv')
participants = pd.read_csv('./data/participants.csv')
stats1 = pd.read_csv('./data/stats1.csv')
stats2 = pd.read_csv('./data/stats2.csv')
teambans = pd.read_csv('./data/teambans.csv')
teamstats = pd.read_csv('./data/teamstats.csv')print(f'champs: {champs.shape}')
print(f'matches: {matches.shape}')
print(f'participants: {participants.shape}')
print(f'stats1: {stats1.shape}')
print(f'stats2: {stats2.shape}')
print(f'teambans: {teambans.shape}')
print(f'teamstats: {teamstats.shape}')
champs为英雄数据:

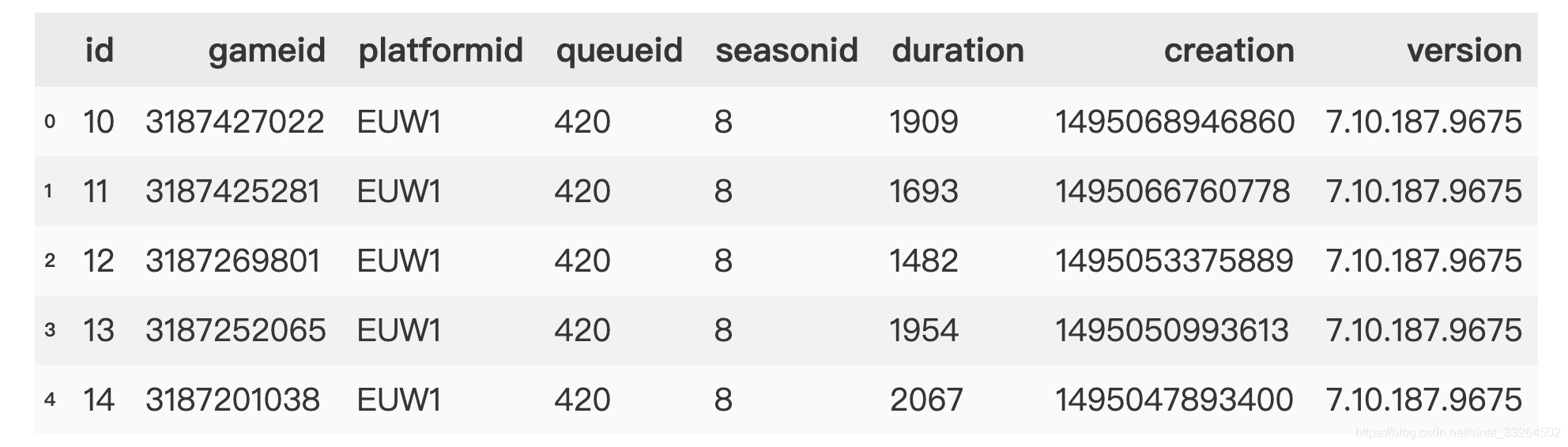
matches为比赛的信息:
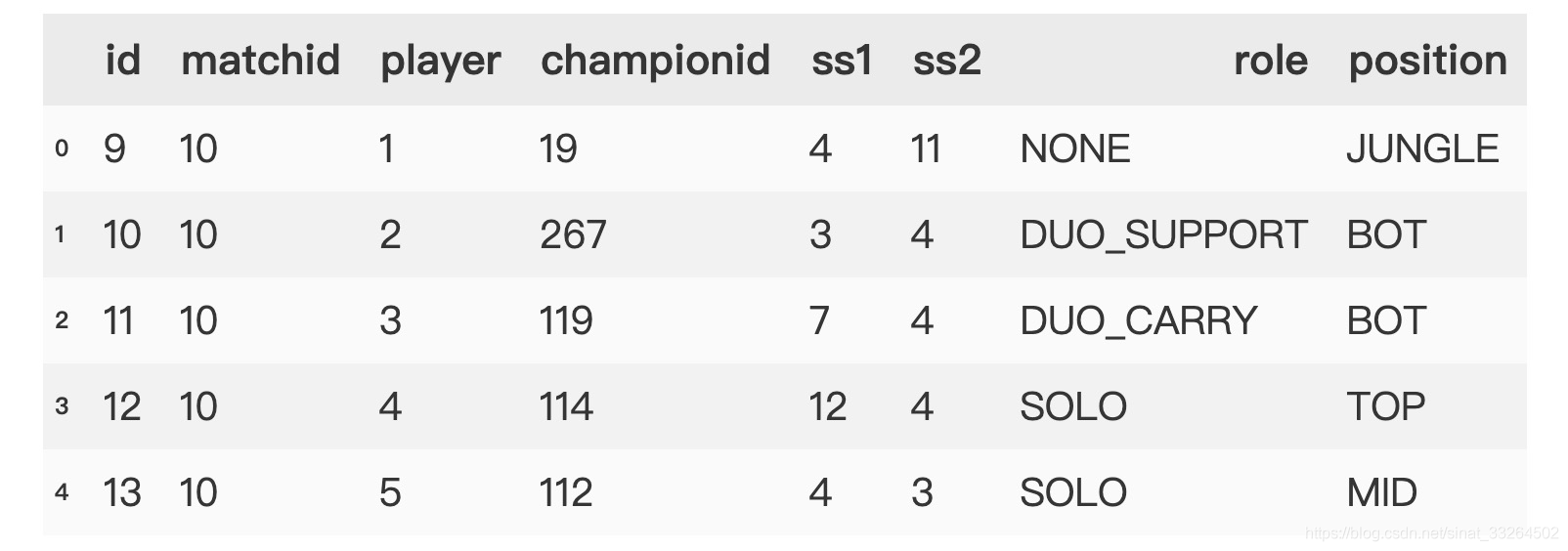
participants为选手的信息:
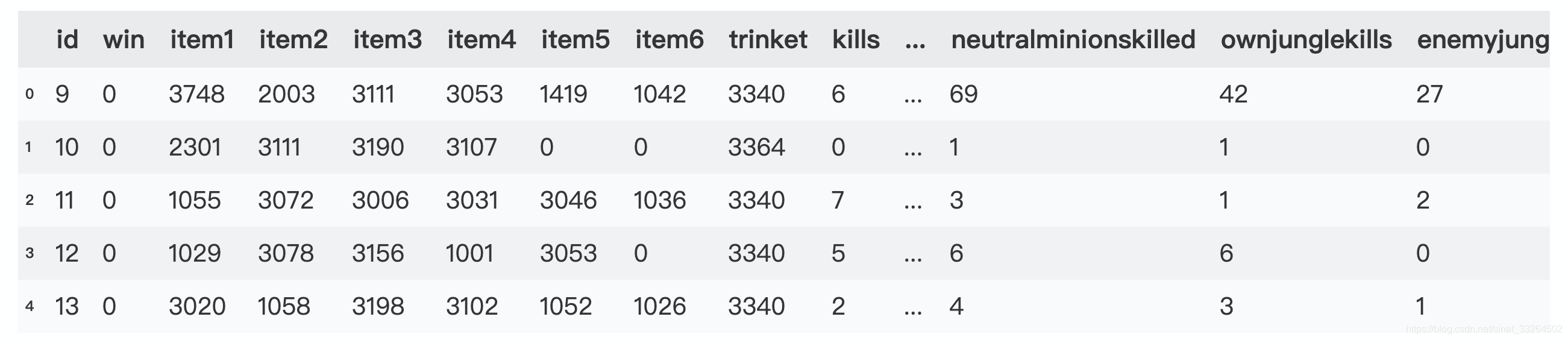
stats1与stats2为比赛中发生的数据,比如KDA、消费金钱、插眼次数、连杀次数等:
我们将stats1与stat2拼接在一起:
stats = stats1.append(stats2)
print(f'stats: {stats.shape}')![]()
将这些各种信息的表联结为一张表:
df = pd.merge(participants, stats, how='left', on=['id'])
df = pd.merge(df, champs, how='left', left_on='championid', right_on='id', suffixes=('', '_1'))
df = pd.merge(df, matches, how='left', left_on='matchid', right_on='id', suffixes=('', '_2'))pd.set_option('display.max_columns', None)
df.head()
建立一个函数,作用是将“role”与“position”特征合并,得到整齐的表示选手位置的特征(属性为“TOP”、“MID”、“JUNGLE”、“DUO_SUPPORT”、“DUO_CARRY”分别对应“上单”、“中单”、“打野”、“辅助”、“C位”):
def adj_position(row):if row['role'] in ('DUO_SUPPORT', 'DUO_CARRY'):return row['role']else:return row['position']df['adjposition'] = df.apply(adj_position, axis = 1) 然后我们根据player特征将选手分队,1~5为第一队,6~10为第二队:
# 分队
df['team'] = df['player'].apply(lambda x: '1' if x <= 5 else '2')
df['team_role'] = df['team'] + '-' + df['adjposition']以'1-MID'为例,可以看到对于同一个'matchid'(即同一场比赛)会出现多个'1-MID',这是不合理的:
df_remove = df[df['team_role'] == '1-MID'].groupby('matchid').agg({'team_role':'count'})
df_remove[df_remove['team_role'] != 1].index.values![]()
移除这种同一场比赛出现多次相同位置的比赛数据:
remove_index = []
for i in ('1-MID', '1-TOP', '1-DUO_SUPPORT', '1-DUO_CARRY', '1-JUNGLE', '2-MID', '2-TOP', '2-DUO_SUPPORT', '2-DUO_CARRY', '2-JUNGLE'):df_remove = df[df['team_role'] == i].groupby('matchid').agg({'team_role':'count'})remove_index.extend(df_remove[df_remove['team_role'] != 1].index.values)'BOT'被细分为了'DUO_SUPPORT'和'DUO_CARRY',移除更新后仍是'BOT'的数据:
remove_index.extend(df[df['adjposition'] == 'BOT']['matchid'].unique())
remove_index = list(set(remove_index))print(f'清洗前的比赛场数: {df.matchid.nunique()}')
df = df[~df['matchid'].isin(remove_index)]
print(f'清洗后的比赛场数: {df.matchid.nunique()}')
在此次分析中,我们选取绝大部分的S8赛季的比赛:
df = df[['id', 'matchid', 'player', 'name', 'adjposition', 'team_role', 'win', 'kills', 'deaths', 'assists', 'turretkills','totdmgtochamp', 'totheal', 'totminionskilled', 'goldspent', 'totdmgtaken', 'inhibkills', 'pinksbought', 'wardsplaced', 'duration', 'platformid', 'seasonid', 'version']]
df = df[df['seasonid'] == 8]
print(f'Season 8的比赛场数: {df.matchid.nunique()}')
df.head(10)
'wardsplaced'特征为插眼的次数,移除次数过多的样本,先按累计百分比看看:
pd.set_option('display.max_rows', None)
pd.set_option('display.float_format', lambda x: '%.4f' % x)
wardsplaced = df['wardsplaced'].value_counts().sort_index() / len(df)
wardsplaced.cumsum()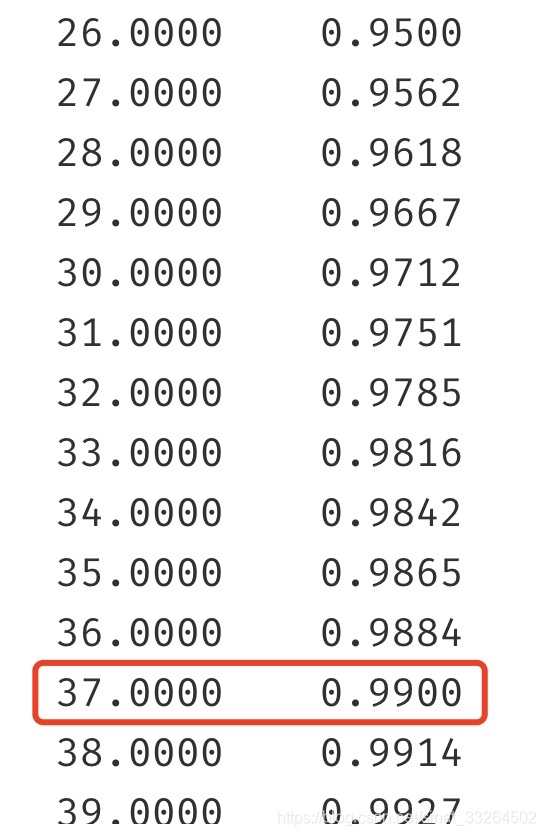
大约在37次的位置达到99%的累计百分比,就以这个数删去吧:
# 将最大值转为99%的样本值
df['wardsplaced'] = df['wardsplaced'].apply(lambda x: x if x<=37 else 37)让我们来看看不同位置对于插眼次数有什么不同:
plt.figure(figsize = (15, 10))
sns.violinplot(x="adjposition", y="wardsplaced", hue="win", data=df, palette='Set3', split=True, inner='quartile')
plt.title('Wardsplaced by adjposition: win vs loss')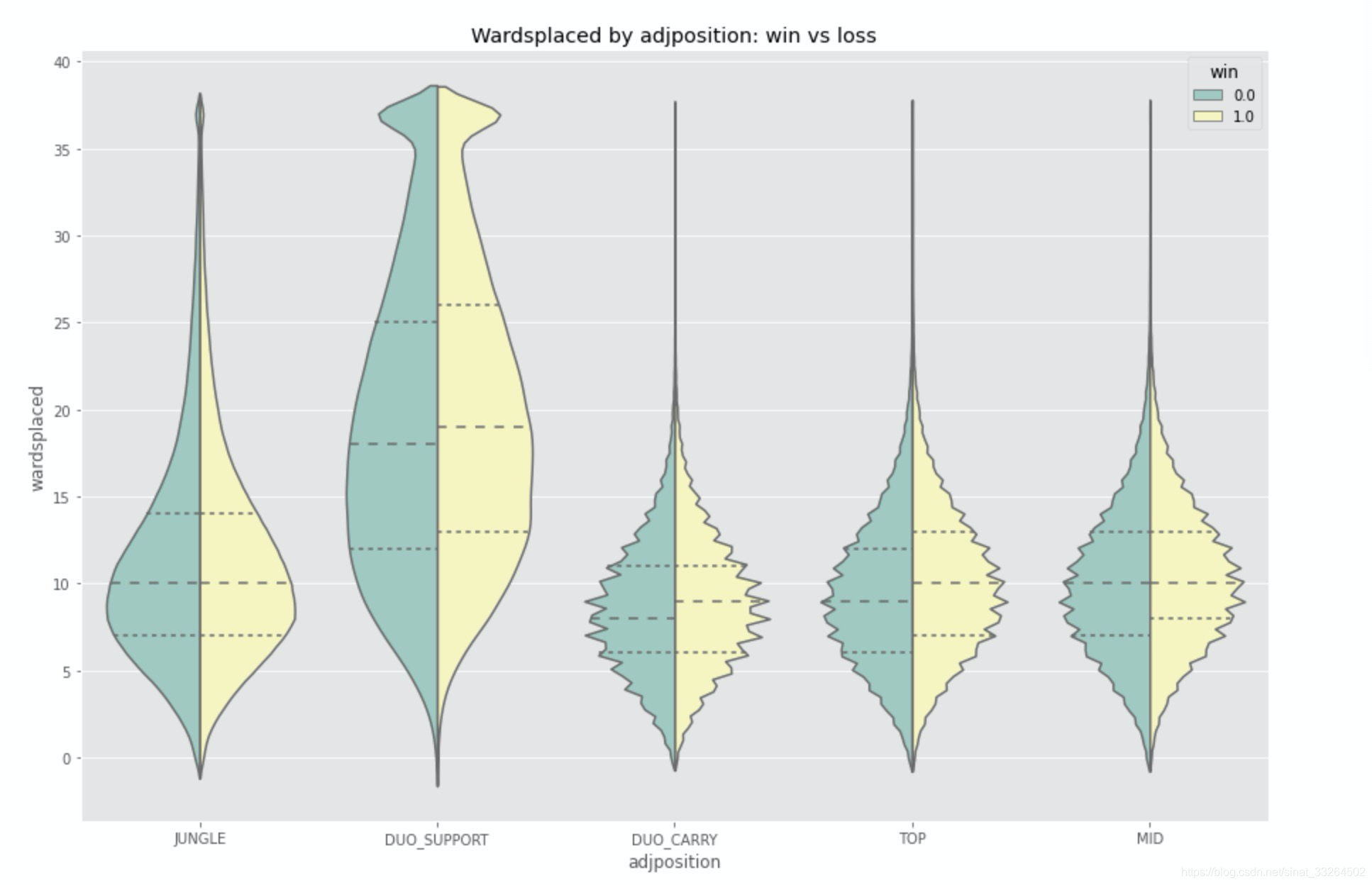
哈哈果然,辅助是主要负责插眼的~C位看起来比较不用插眼
接下来研究击杀数,首先也是删去一些离群值:
kills = df['kills'].value_counts().sort_index() / len(df)
kills.cumsum()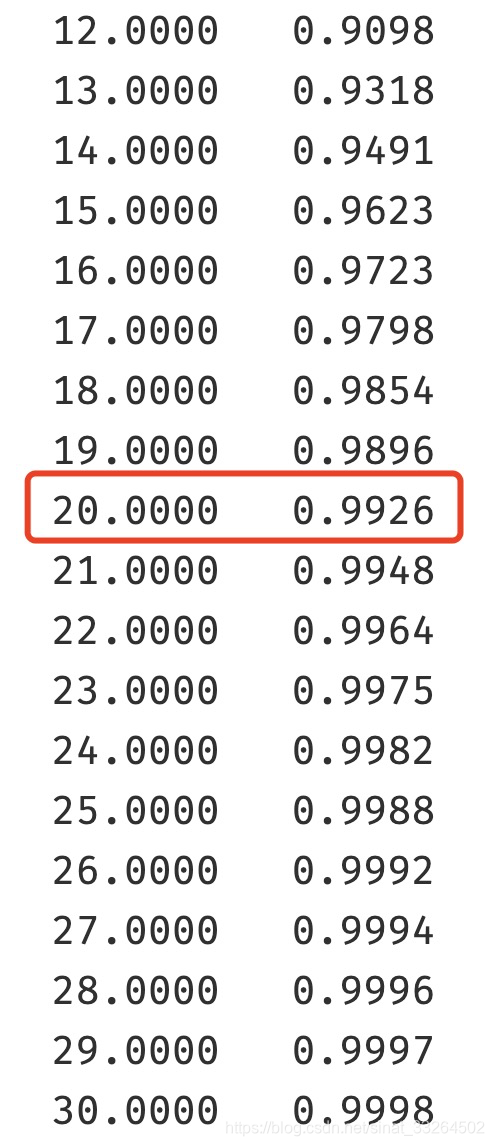
那么在20次差不多达到了99%累计百分比
df['kills'] = df['kills'].apply(lambda x: x if x<=20 else 20)看看不同位置对于击杀数的区别:
plt.figure(figsize = (15, 10))
sns.violinplot(x="adjposition", y="kills", hue="win", data=df, palette='Set3', split=True, inner='quartile')
plt.title('Kills by adjposition: win vs loss')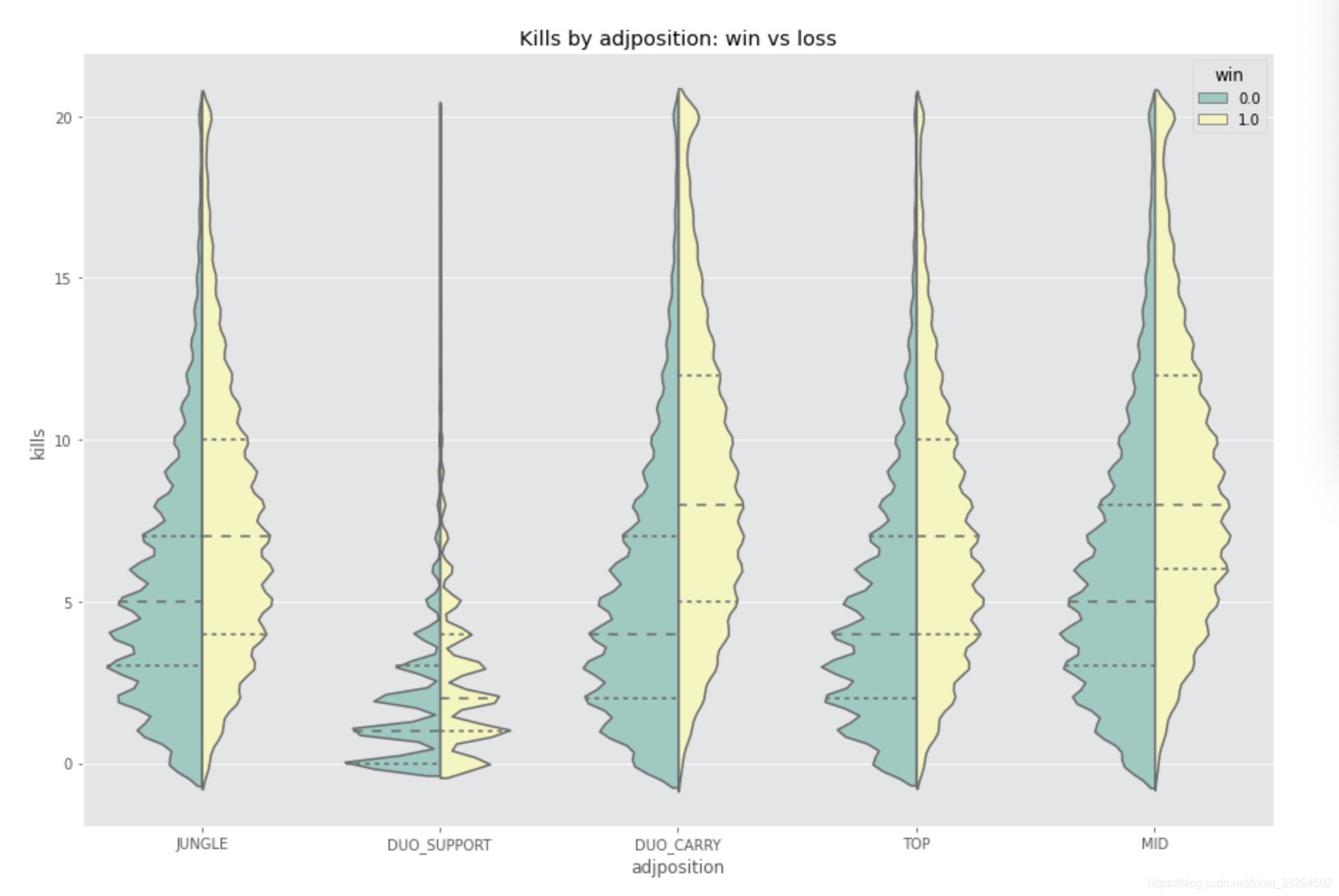
C位与中单是击杀数比较多的,而辅助明显是不太负责击杀的;而赢方的击杀数要明显高于输方~
再看看不同位置对于造成伤害量的区别:
plt.figure(figsize = (15, 10))
sns.violinplot(x="adjposition", y="totdmgtochamp", hue="win", data=df, palette='Set3', split=True, inner='quartile')
plt.title('totdmgtochamp by adjposition: win vs loss')
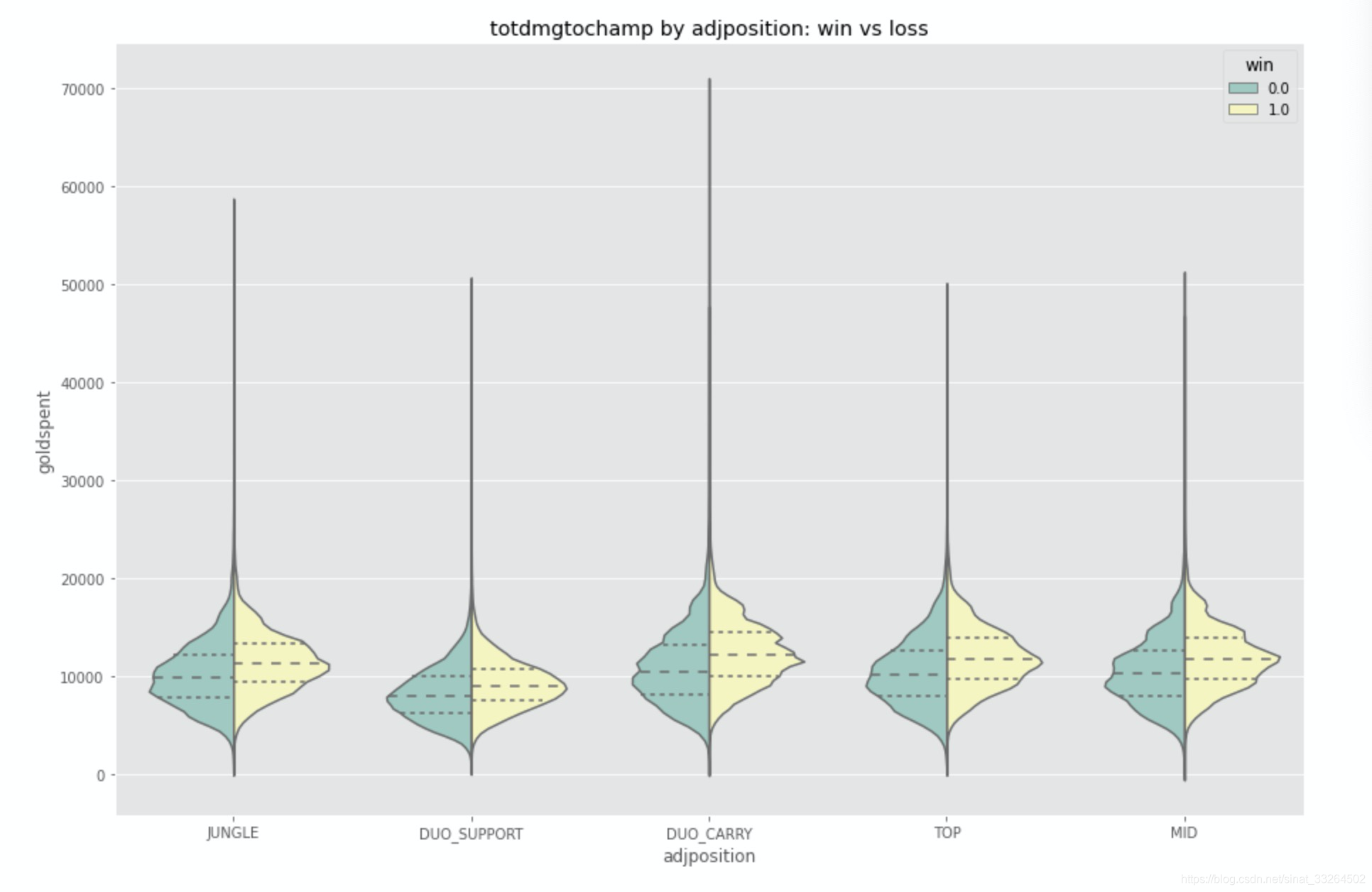
造成伤害量对于输赢的影响主要区分在“DUO_CARRY”,“TOP”,“MID”位置
我们开始对英雄分析,首先看看英雄的出场率:
f, ax = plt.subplots(figsize=(15, 12))
win_rate = df['name'].value_counts().sort_values(ascending=False)
ax = pd.concat((win_rate.head(10), win_rate.tail(10))).plot(kind='bar')
total_records = len(matches)
for p in ax.patches:height = p.get_height()ax.text(p.get_x() + p.get_width()/2.,height + 3,'{:.2f}%'.format(height/total_records*100),ha="center",rotation=0)plt.xticks(rotation=45)
plt.yticks([2000, 5000, 10000, 20000, 30000, 40000, 50000, 60000])
plt.title('Top 10 and Last 10 Hero Picks')
plt.show()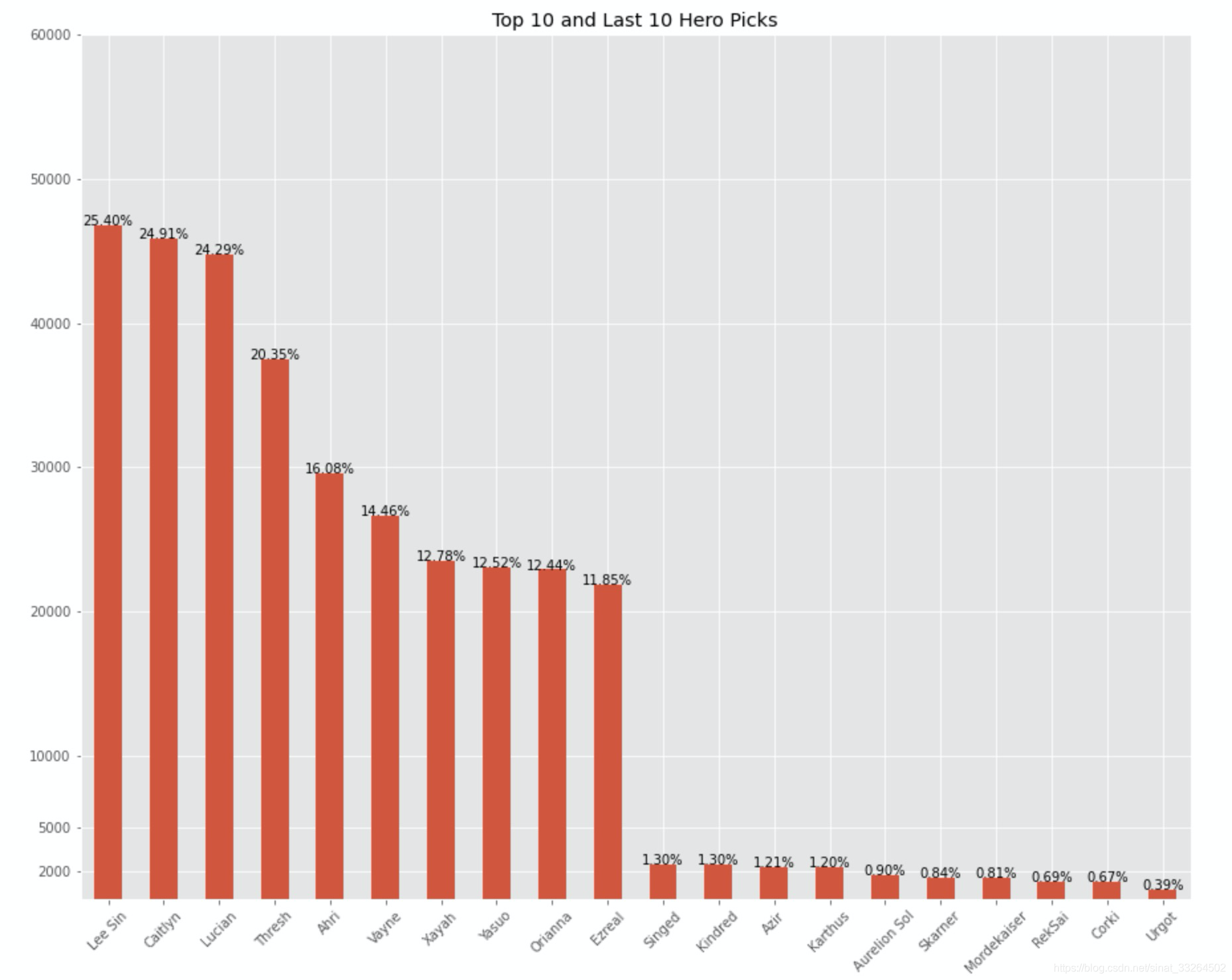
那么出场率最高的分别是盲僧、凯特琳、卢锡安、锤石、阿狸等;出场率最低的分别是厄加特、库奇、虚空掘地者、铁铠冥魂、斯卡纳等
接下来看看每个特征与输赢之间的相关性,以及特征之间的相关性:
df_corr = df._get_numeric_data()
df_corr = df_corr.drop(['id', 'matchid', 'player', 'seasonid'], axis=1)mask = np.zeros_like(df_corr.corr(), dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
cmap = sns.diverging_palette(10, 200, as_cmap=True)plt.figure(figsize=(15, 10))
sns.heatmap(df_corr.corr(), cmap=cmap, annot=True, fmt='.2f', mask=mask, square=True, linewidths=.5, center=0)
plt.title('Correlations - win vs factors (all games)')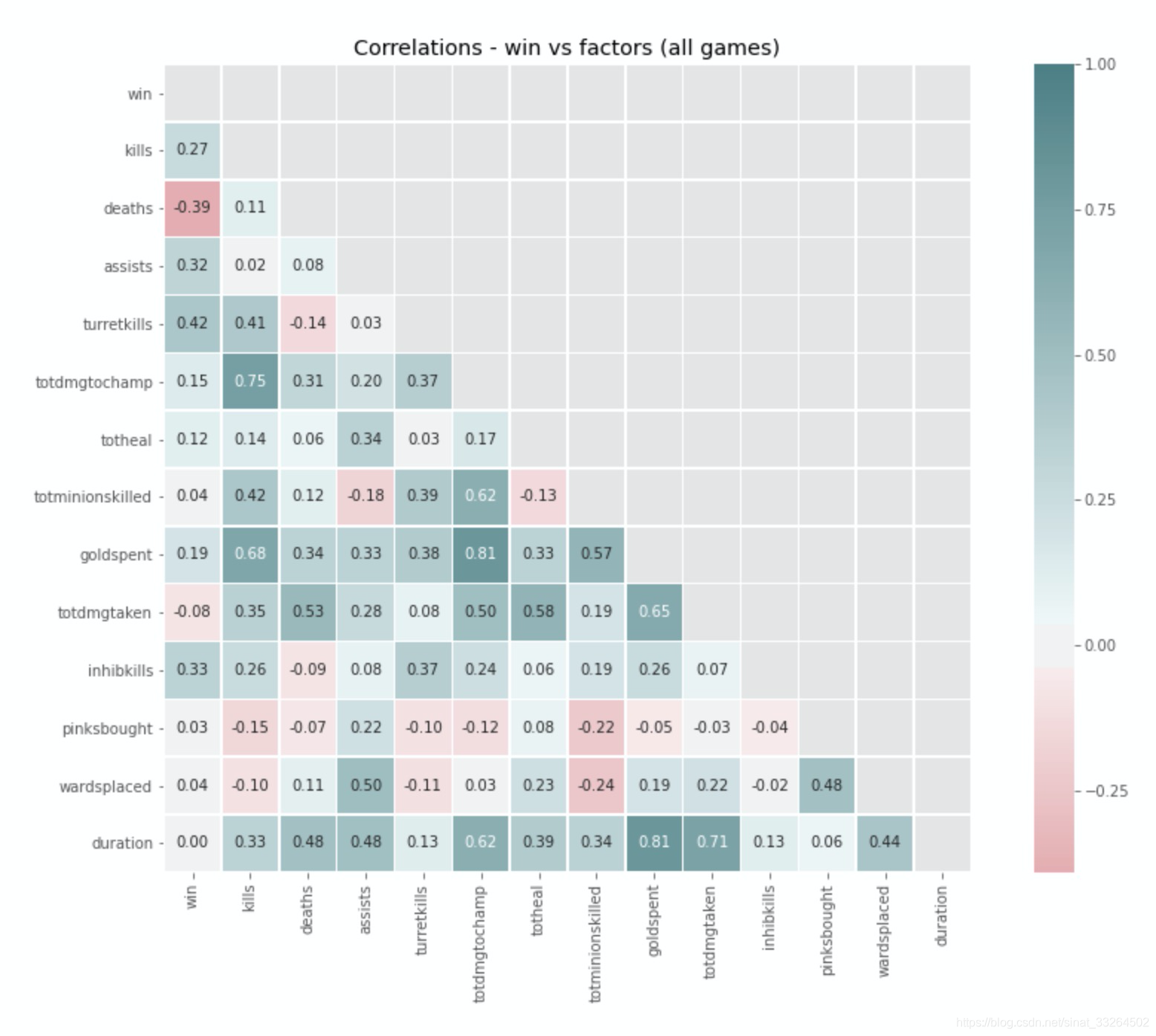
可以看到与输赢关系比较大的特征有:死亡数、助攻数、炮塔摧毁数(inhibkills是个啥???)
再来看看20分钟以内结束的比赛的情况:
df_corr_2 = df._get_numeric_data()
df_corr_2 = df_corr_2[df_corr_2['duration'] <= 1200]
df_corr_2 = df_corr_2.drop(['id', 'matchid', 'player', 'seasonid'], axis=1)mask = np.zeros_like(df_corr_2.corr(), dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
cmap = sns.diverging_palette(10, 200, as_cmap=True)plt.figure(figsize = (15, 10))
sns.heatmap(df_corr_2.corr(), cmap=cmap, annot=True, fmt='.2f', mask=mask, square=True, linewidths=.5, center=0)
plt.title('Correlations - win vs factors (for games last less than 20 mins)')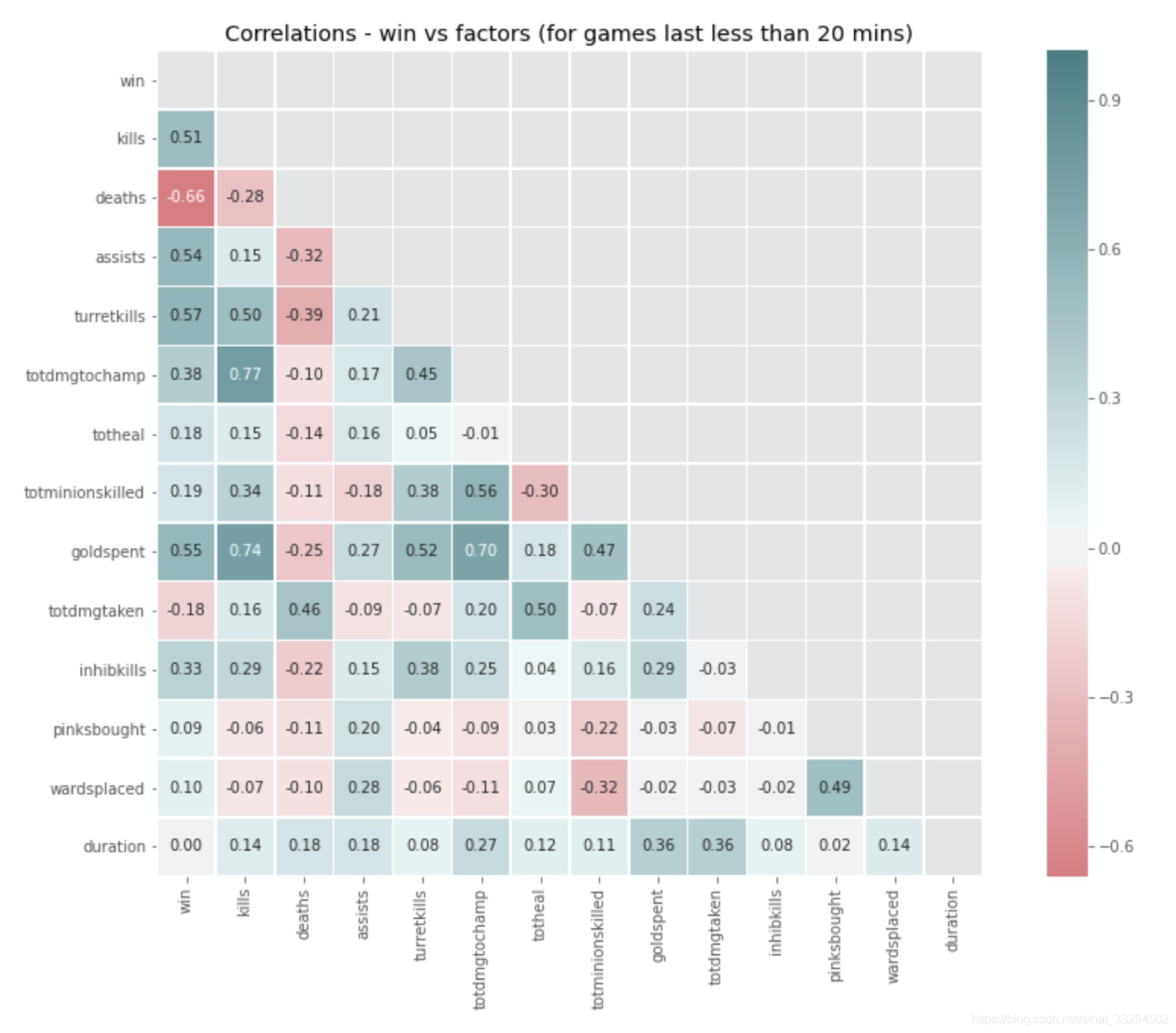
可以看到对于结束比较快的比赛,与输赢关系比较大的特征有:击杀数、死亡数、助攻数、炮塔摧毁数、消费金钱量
那么对于持续长时间的比赛呢?
df_corr_3 = df._get_numeric_data()
df_corr_3 = df_corr_3[df_corr_3['duration'] > 2400]
df_corr_3 = df_corr_3.drop(['id', 'matchid', 'player', 'seasonid'], axis=1)mask = np.zeros_like(df_corr_3.corr(), dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
cmap = sns.diverging_palette(10, 200, as_cmap=True)plt.figure(figsize = (15, 10))
sns.heatmap(df_corr_3.corr(), cmap=cmap, annot=True, fmt='.2f', mask=mask, square=True, linewidths=.5, center=0)
plt.title('Correlations - win vs factors (for games last more than 40 mins)')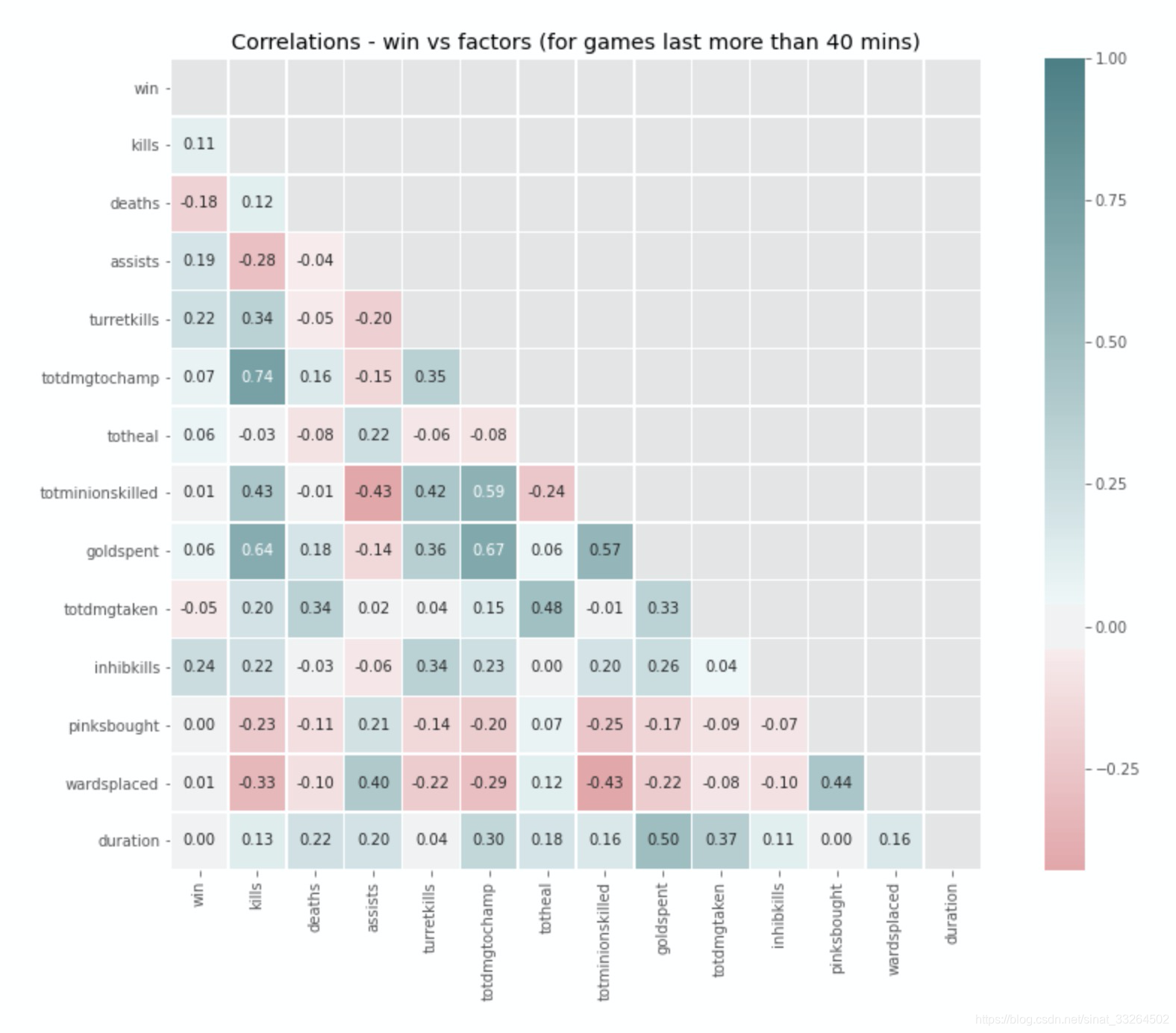
咦,好像关系都不是很大了......
然后再来分析分析KDA,不同英雄的胜率与平均KDA:
pd.set_option('display.precision', 2)df_win_rate = df.groupby('name').agg({'win': 'sum', 'name': 'count', 'kills': 'mean', 'deaths': 'mean', 'assists': 'mean'})
df_win_rate.columns = ['win matches', 'total matches', 'K', 'D', 'A']
df_win_rate['win rate'] = df_win_rate['win matches'] / df_win_rate['total matches'] * 100
df_win_rate['KDA'] = (df_win_rate['K'] + df_win_rate['A']) / df_win_rate['D']
df_win_rate = df_win_rate.sort_values('win rate', ascending=False)
df_win_rate = df_win_rate[['total matches', 'win rate', 'K', 'D', 'A', 'KDA']]df_win_rate.head(10)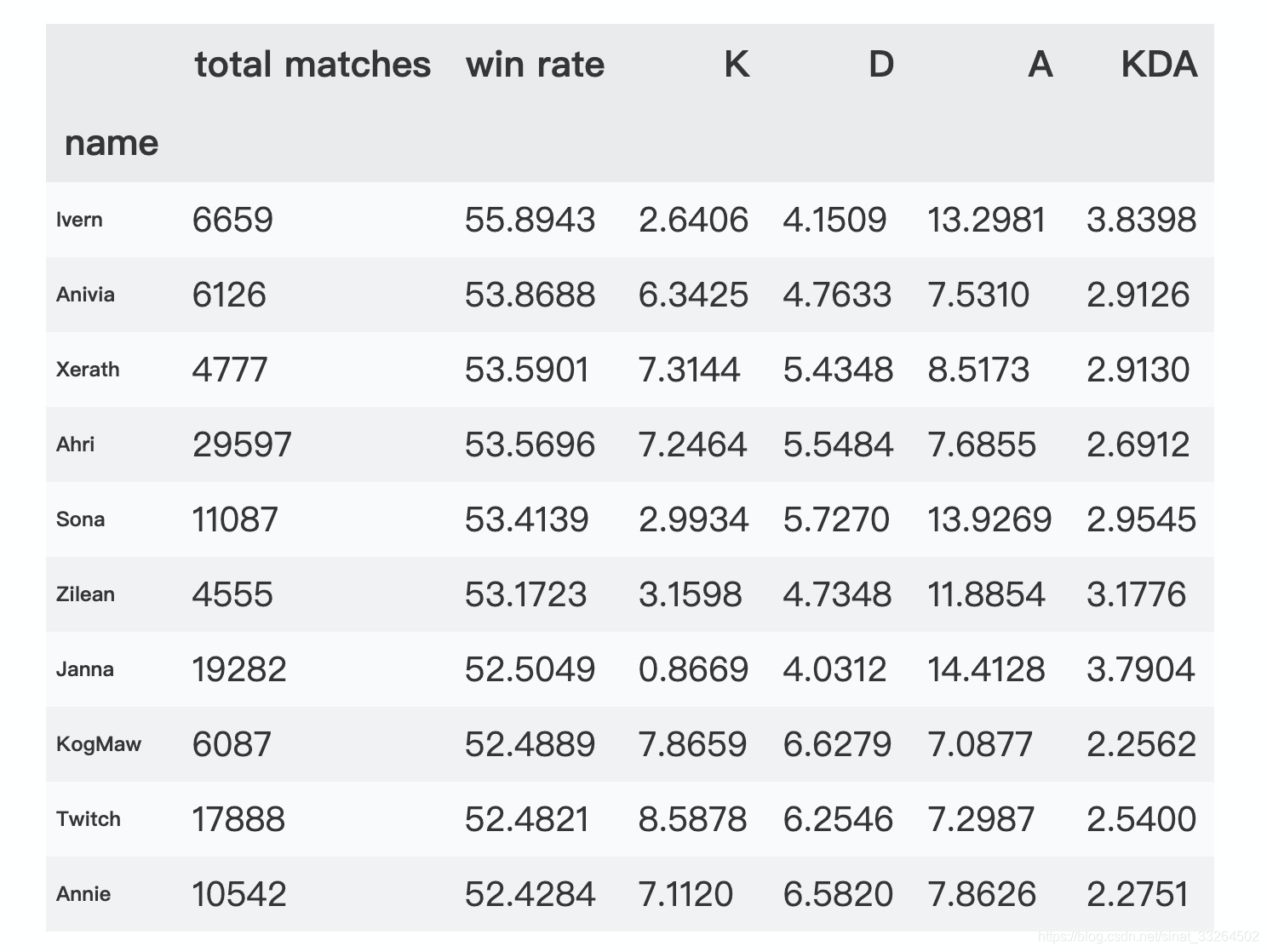
胜率最高的英雄为艾翁、冰晶凤凰、泽拉斯、阿狸、琴瑟仙女等
df_win_rate.tail(10)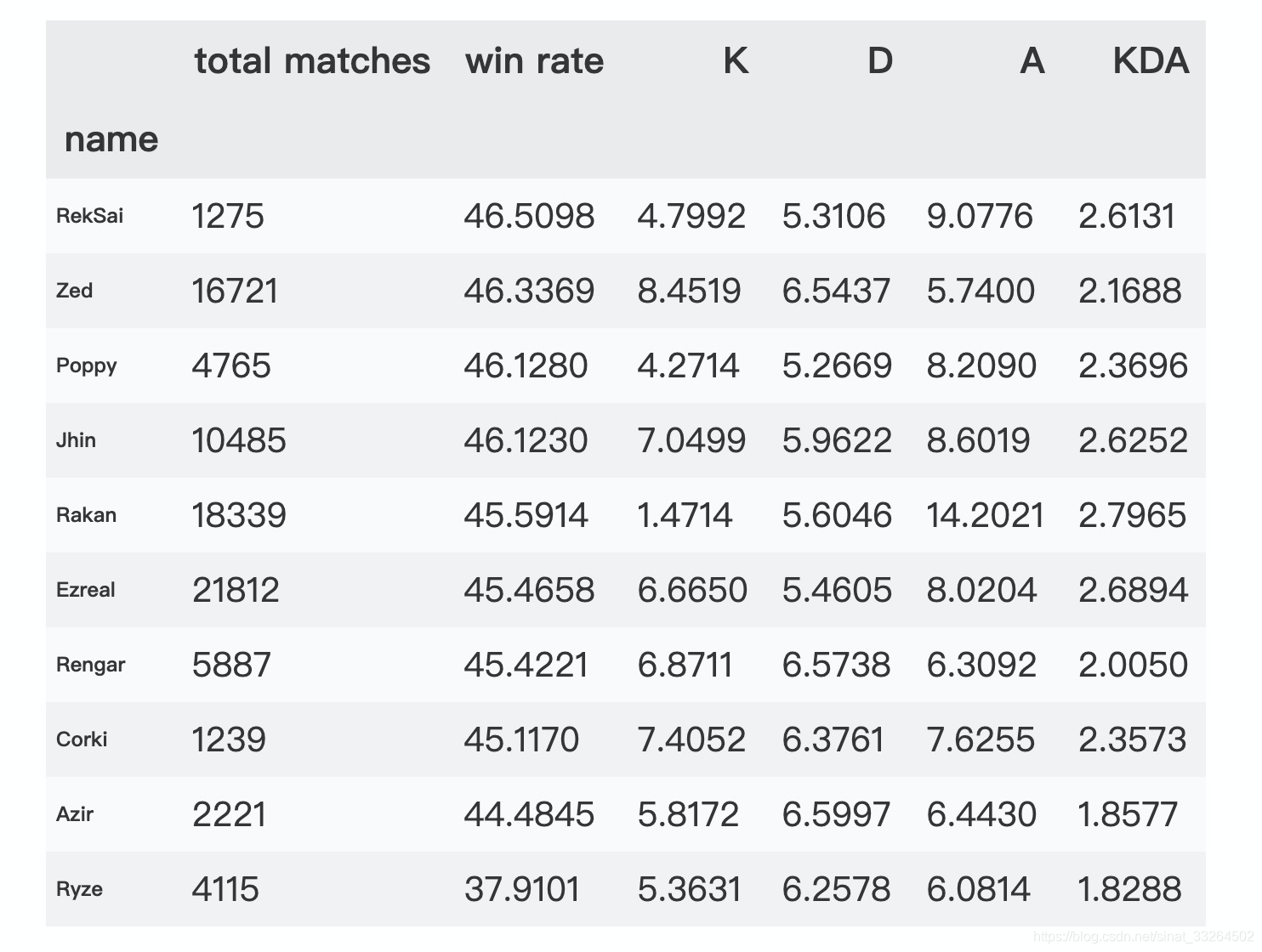
胜率最低的英雄为虚空掘地者、影流之主、钢铁大师、戏命师、芮肯等
出场场次与胜率的散点图:
df_win_rate.reset_index(inplace=True)def label_point(x, y, val, ax):a = pd.concat({'x': x, 'y': y, 'val': val}, axis=1)for i, point in a.iterrows():ax.text(point['x'], point['y'], str(point['val']))df_win_rate['color map'] = df_win_rate['win rate'].apply(lambda x: 'red' if x>50 else 'green')ax = df_win_rate.plot(kind='scatter', x='total matches', y='win rate', color=df_win_rate['color map'].tolist(), figsize=(15,10), title='win rate vs # matches by champions')label_point(df_win_rate['total matches'], df_win_rate['win rate'], df_win_rate['name'], ax)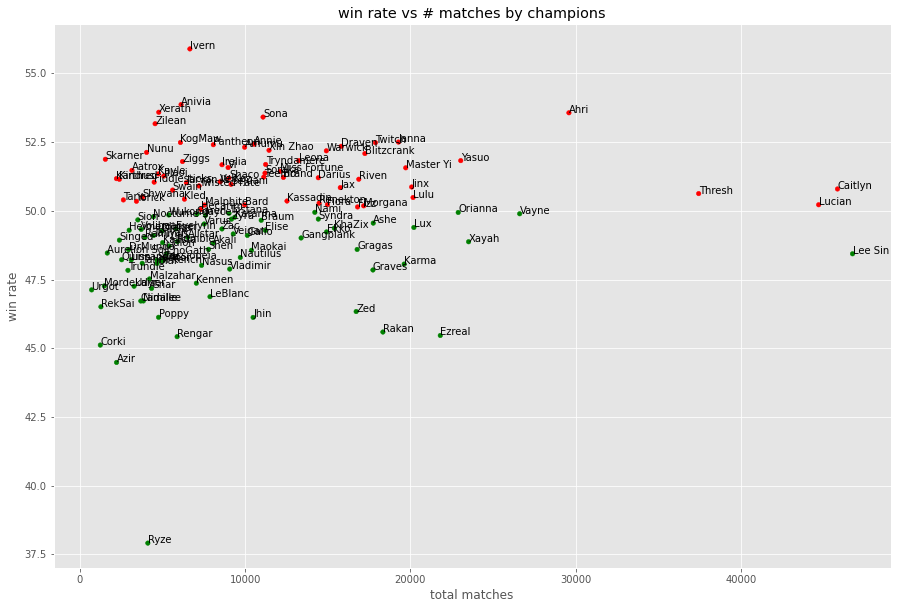
盲僧出场多但胜率较低,艾翁出场少但是胜率很高
让我们再来看看不同英雄与位置组合的胜率与KDA:
pd.options.display.float_format = '{:,.2f}'.formatdf_win_rate_role = df.groupby(['name', 'adjposition']).agg({'win': 'sum', 'name': 'count', 'kills': 'mean', 'deaths': 'mean', 'assists': 'mean'})
df_win_rate_role.columns = ['win matches', 'total matches', 'K', 'D', 'A']
df_win_rate_role['win rate'] = df_win_rate_role['win matches'] / df_win_rate_role['total matches'] * 100
df_win_rate_role['KDA'] = (df_win_rate_role['K'] + df_win_rate_role['A']) / df_win_rate_role['D']
df_win_rate_role = df_win_rate_role.sort_values('win rate', ascending=False)
df_win_rate_role = df_win_rate_role[['total matches', 'win rate', 'K', 'D', 'A', 'KDA']]# 只取出场占全部场次0.01%以上的
df_win_rate_role = df_win_rate_role[df_win_rate_role['total matches']>df_win_rate_role['total matches'].sum()*0.0001]df_win_rate_role.head(10)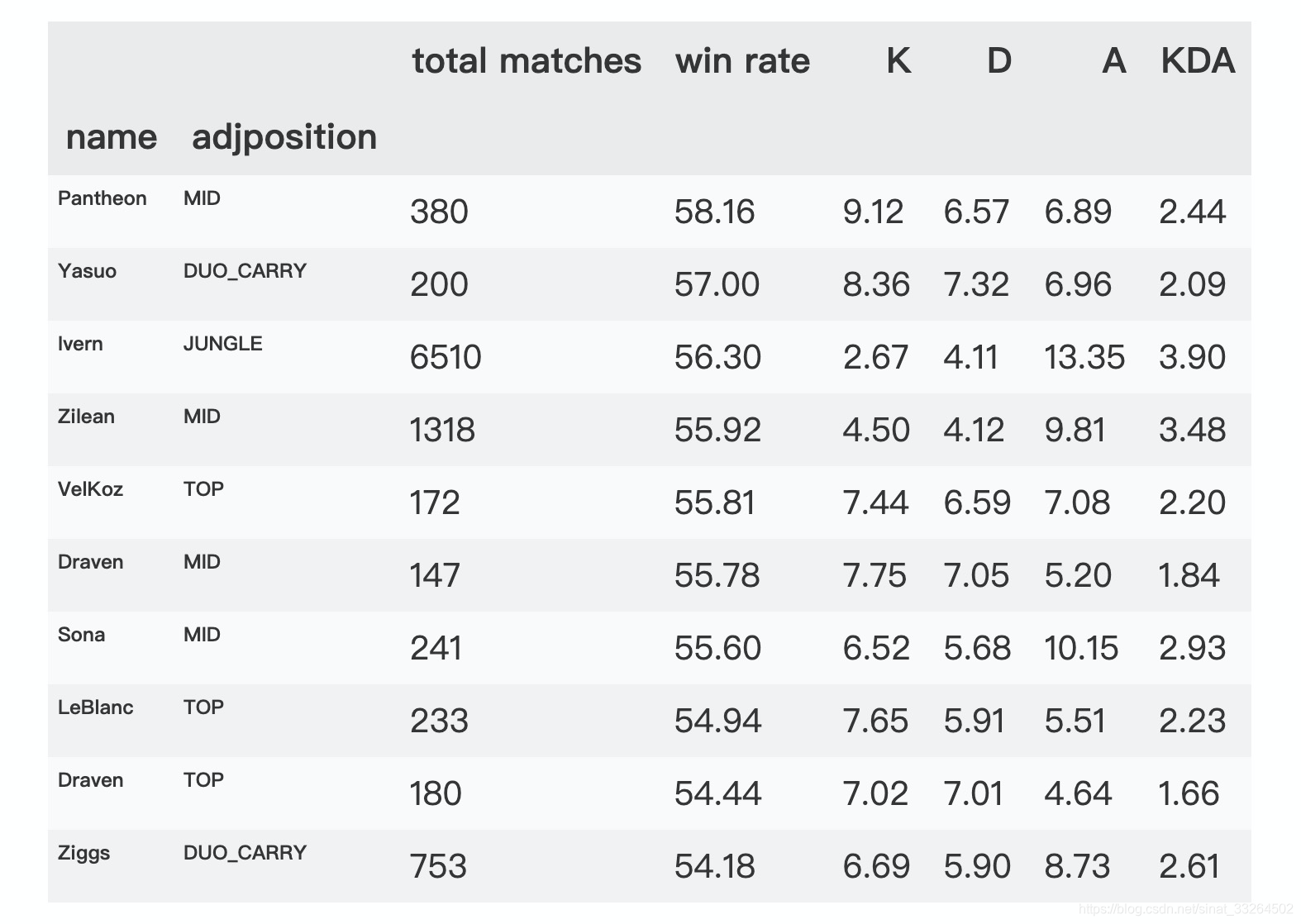
用潘森中单的胜率最高,亚索打C位胜率也很高
df_win_rate_role.tail(10)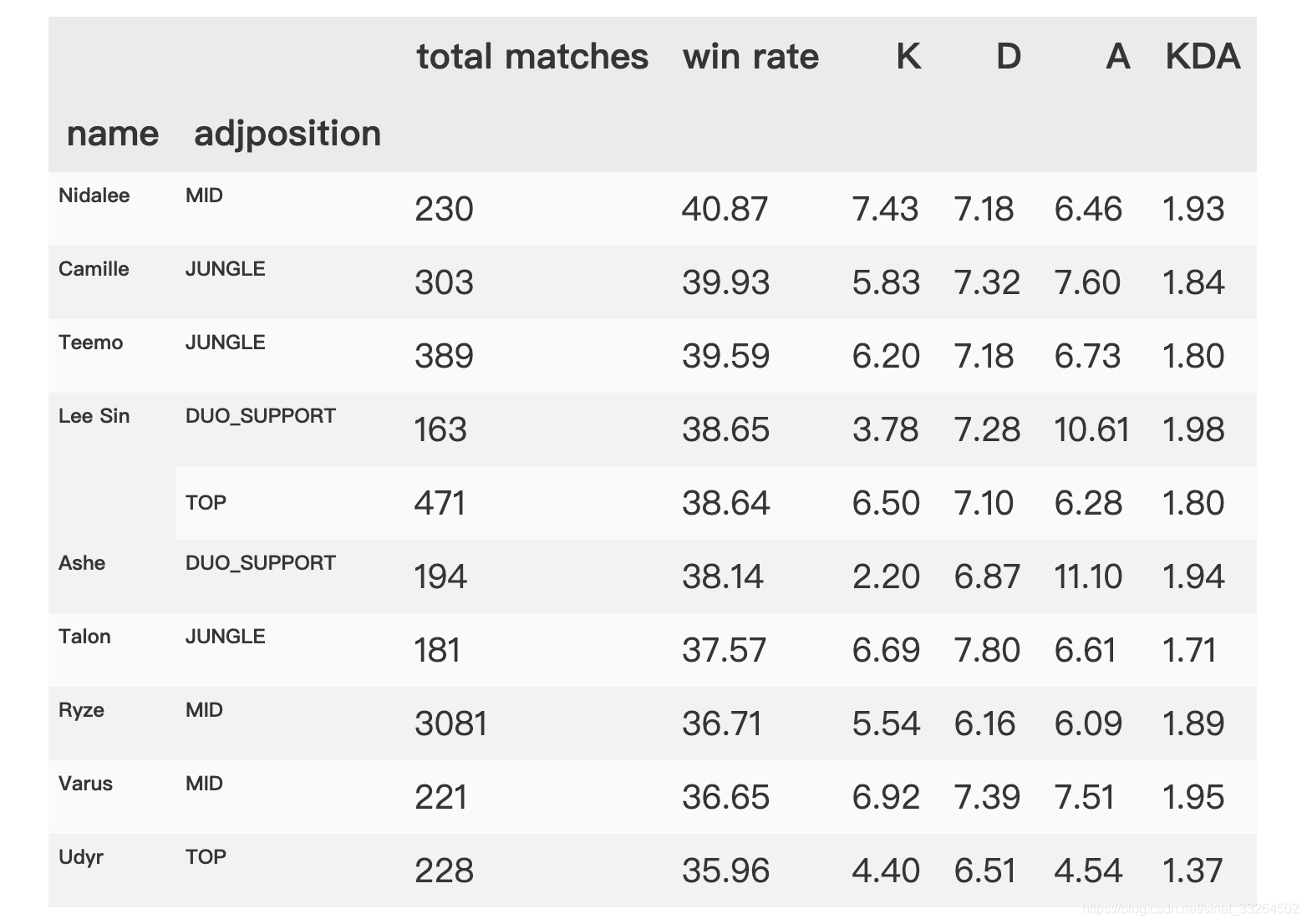
看一下整体的胜率图吧:
df_win_rate['win rate compared 50%'] = df_win_rate['win rate'] - 50.0f, ax = plt.subplots(figsize=(12, 30))
sns.barplot(y='name', x='win rate compared 50%', data=df_win_rate.sort_values(by='win rate', ascending=False),palette='pastel')
plt.title('Win Rate Map')
plt.show()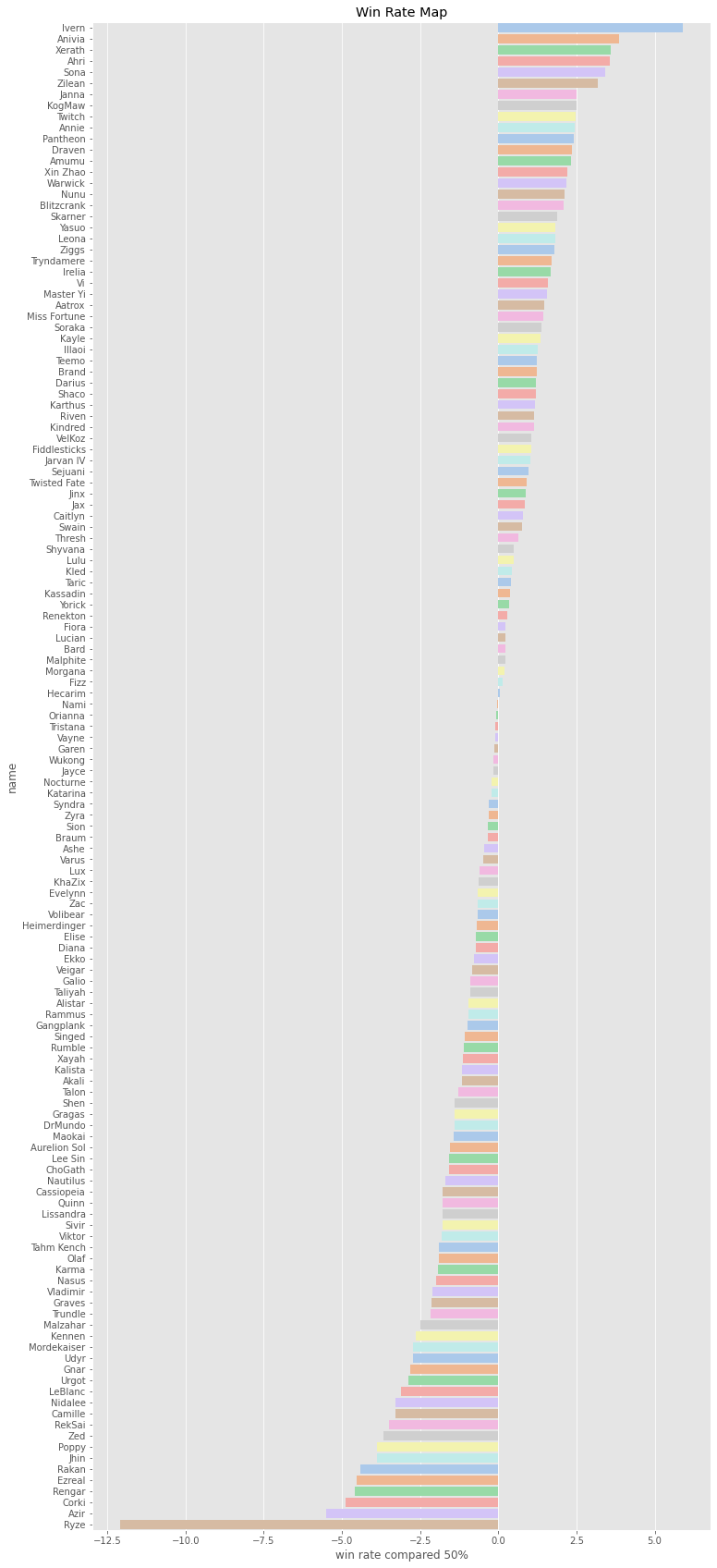
整体的KDA图:
df_win_rate['KDA compared mean'] = df_win_rate['KDA'] - df_win_rate['KDA'].mean()f, ax = plt.subplots(figsize=(12, 30))
sns.barplot(y='name', x='KDA compared mean', data=df_win_rate.sort_values(by='KDA', ascending=False),palette='pastel')
plt.title('KDA Map')
plt.show()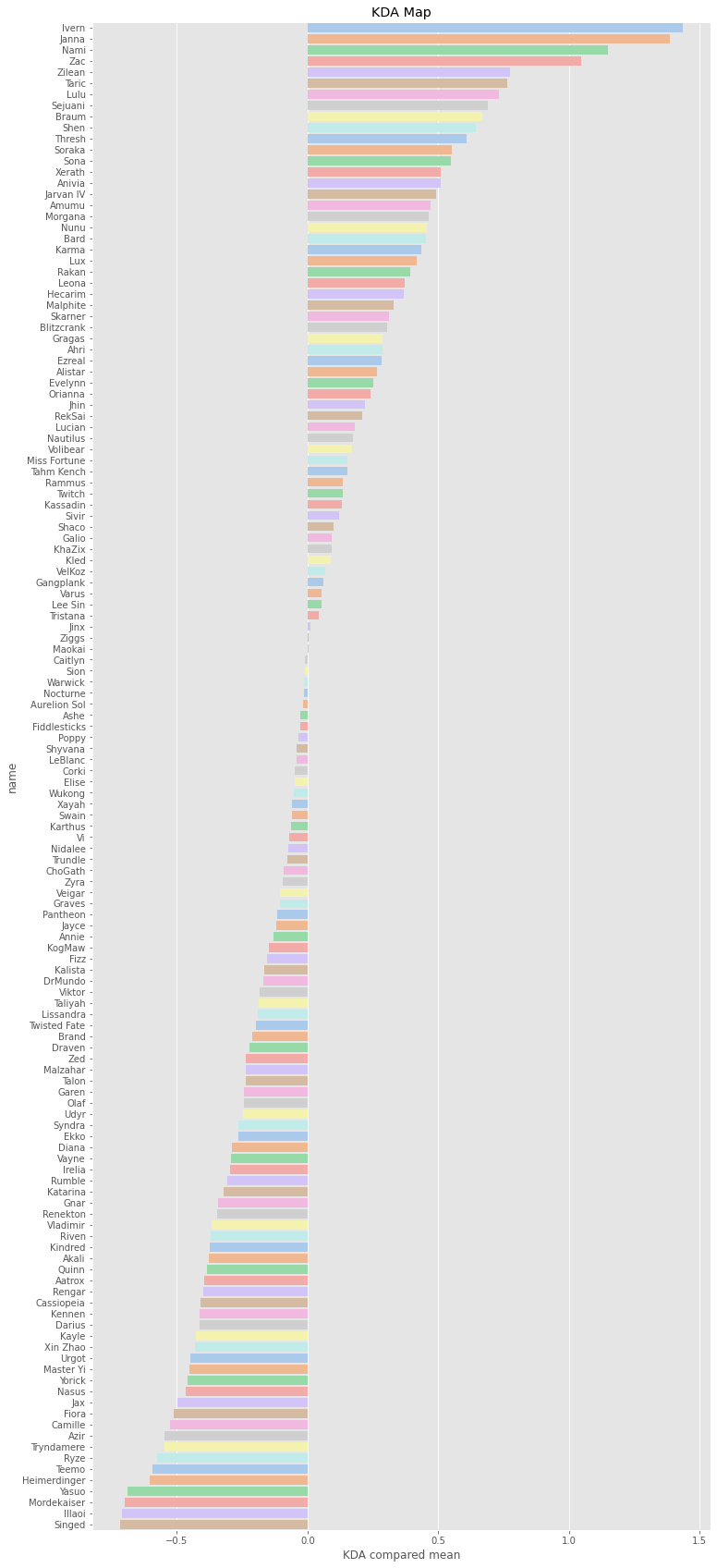
接下来将数据按比赛场次与位置整理,研究英雄对位相关的信息:
df_2 = df.sort_values(['matchid', 'adjposition'], ascending = [1, 1])df_2['shift 1'] = df_2['name'].shift()
df_2['shift -1'] = df_2['name'].shift(-1)#数据偏移一位,正好匹配到相同位置的对位英雄
def get_matchup(x):if x['player'] <= 5:if x['name'] < x['shift -1']:name_return = x['name'] + ' vs ' + x['shift -1']else:name_return = x['shift -1'] + ' vs ' + x['name']else:if x['name'] < x['shift 1']:name_return = x['name'] + ' vs ' + x['shift 1']else:name_return = x['shift 1'] + ' vs ' + x['name']return name_returnmatch_up = df_2.apply(get_matchup, axis=1)
df_2.insert(7, 'match up', match_up)
df_2.head(10)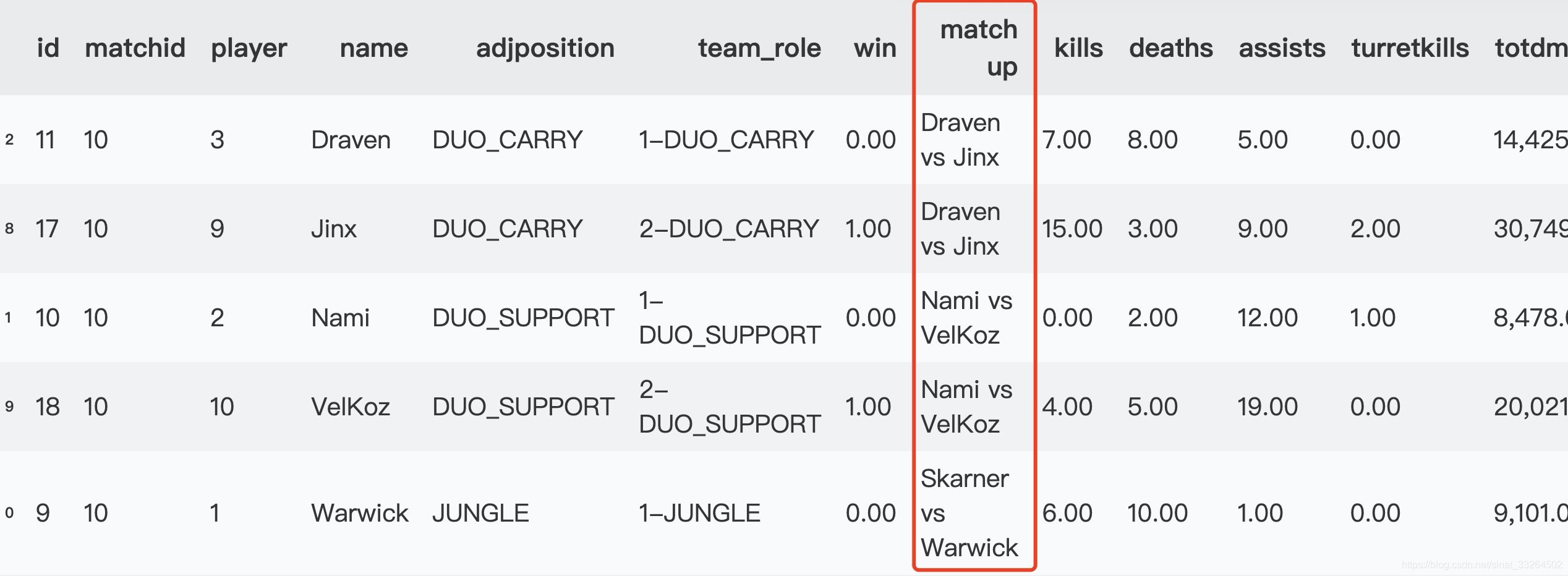
规定胜利方为左方,即为1,否则为0,比如Draven vs Jinx,Draven赢了就为1,Jinx赢了为0:
win_adj = df_2.apply(lambda x: x['win'] if x['name'] == x['match up'].split(' vs ')[0] else 0, axis = 1)
df_2.insert(8, 'win_adj', win_adj)df_2.head(10)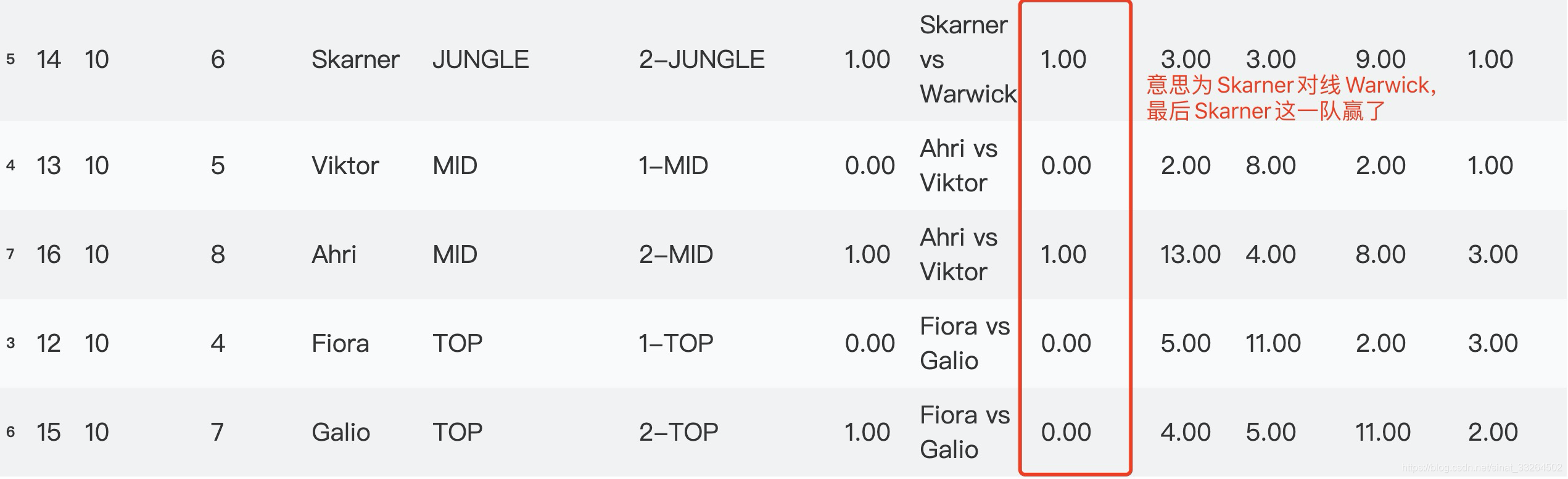
看一下中单的所有对位组合的胜负情况:
df_mid = df_2[df_2['adjposition']=='MID']counter_mid = df_mid.groupby('match up').agg({'win': 'count', 'win_adj': 'sum'})
counter_mid.reset_index(inplace=True)
counter_mid.columns = ['match up', 'total matchs', 'total first win']
counter_mid['total matchs'] = counter_mid['total matchs'] / 2
counter_mid['counter rate'] = counter_mid['total first win'] / counter_mid['total matchs']
counter_mid['counter rate compared 50%'] = counter_mid['total first win'] / counter_mid['total matchs'] - 0.5counter_mid['abs'] = abs(counter_mid['counter rate compared 50%'])
counter_mid = counter_mid[(counter_mid['total matchs']>100) & (counter_mid['total first win']>0)].sort_values(by='abs', ascending=False)
counter_mid.reset_index(inplace=True)counter_mid.head()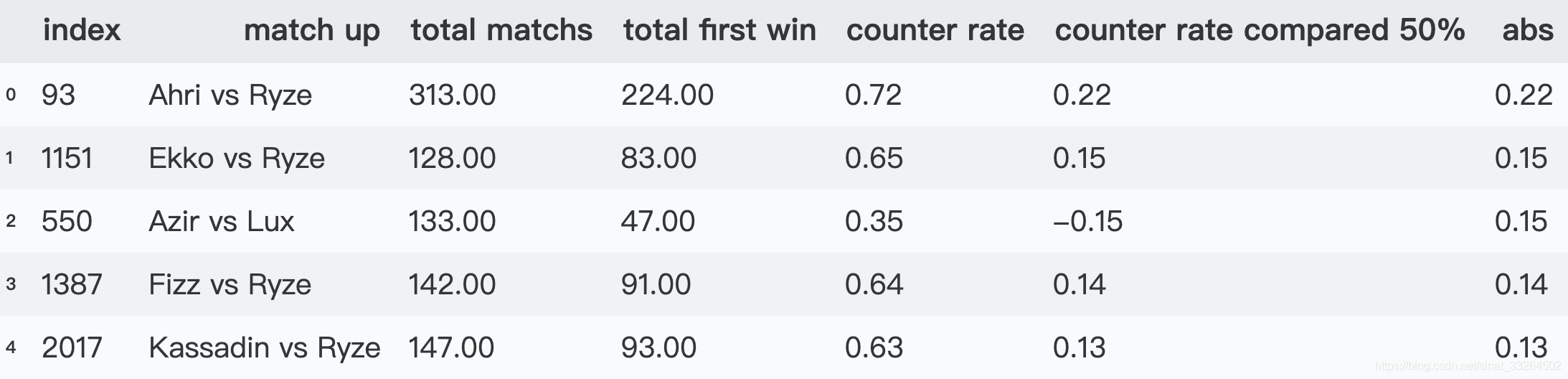
阿狸对线瑞兹,大部分是阿狸这一方赢;时间刺客对线瑞兹,大部分是时间刺客赢,瑞兹你......
plt.figure(figsize=(20, 150))
sns.barplot(x="counter rate compared 50%", y="match up", data=counter_mid, palette='pastel')
看一下上单的所有对位组合的胜负情况:
df_top = df_2[df_2['adjposition']=='TOP']counter_top = df_top.groupby('match up').agg({'win': 'count', 'win_adj': 'sum'})
counter_top.reset_index(inplace=True)
counter_top.columns = ['match up', 'total matchs', 'total first win']
counter_top['total matchs'] = counter_top['total matchs'] / 2
counter_top['counter rate'] = counter_top['total first win'] / counter_top['total matchs']
counter_top['counter rate compared 50%'] = counter_top['total first win'] / counter_top['total matchs'] - 0.5counter_top['abs'] = abs(counter_top['counter rate compared 50%'])
counter_top = counter_top[(counter_top['total matchs']>100) & (counter_top['total first win']>0)].sort_values(by='abs', ascending=False)
counter_top.reset_index(inplace=True)counter_top.head()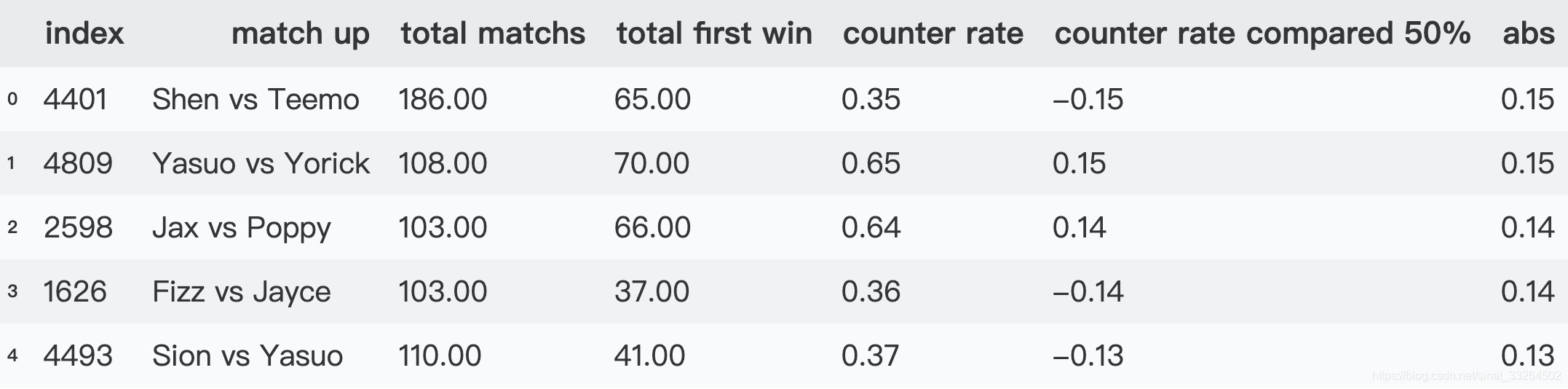
慎对线提莫大部分提莫这一方赢,亚索对线掘墓者大部分亚索这一方赢
plt.figure(figsize=(20, 150))
sns.barplot(x="counter rate compared 50%", y="match up", data=counter_top, palette='pastel')
好的,那么就先分析到这里吧!
关注微信公众号“数据科学与人工智能技术”发送“英雄联盟”可以得到数据集和代码~

这篇关于如何利用数据分析提高英雄联盟的胜率的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!