本文主要是介绍用pandas轻松搞定数据探索性分析(pandas参数、pandas风格、pandas-profiling),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

对于每个从事和数据科学有关的人来说,大部分的时间都花在了前期的数据工作中,包括清洗、处理、探索性数据分析等。前期的工作不仅关乎数据的质量,也关乎最终模型预测效果的好坏。本文介绍一些比较冷门但效果不错的pandas方法来对数据进行初步探索,已经最后介绍一个非常方便实用的库pandas-profiling。
import pandas as pd
import numpy as np展示全部特征列
data = pd.read_csv('loans_2020.csv')
data.head()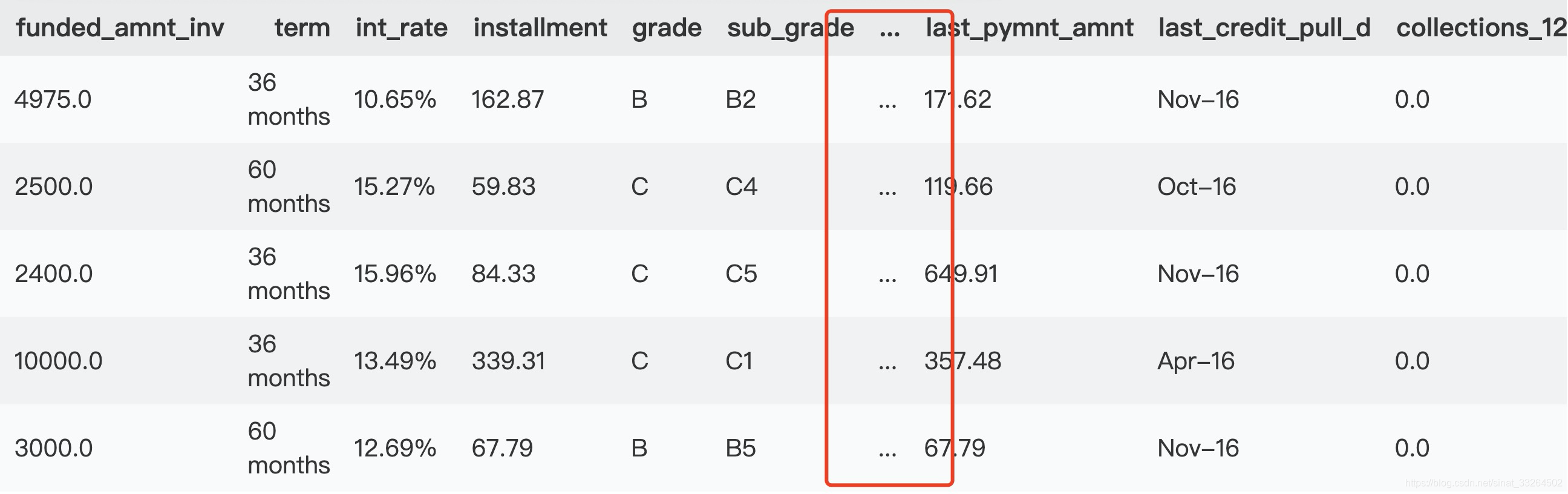
首先我们看到,对于一些比较大型的数据集导入时,会像上图这样将特征缩略,不能很好地直观看到所有的特征,那么此时可以将pandas的设置更改一下:
pd.set_option('display.max_columns', None)
data.head()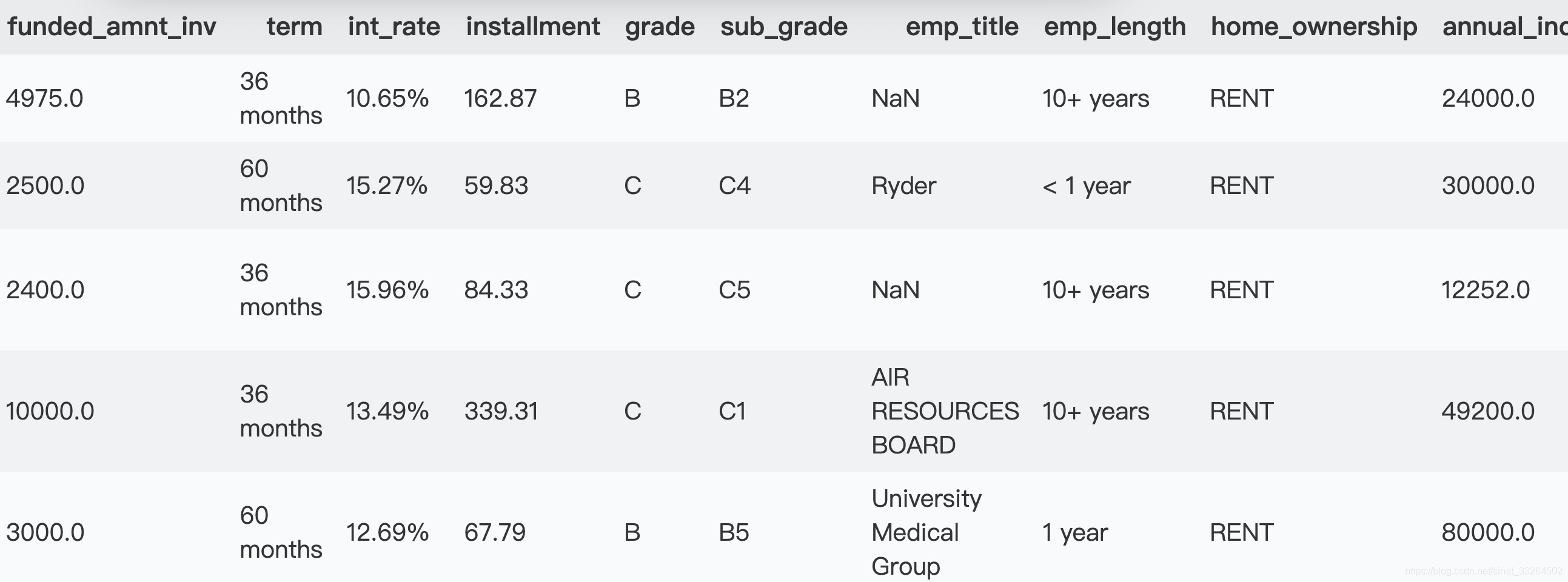
其中None可以改为你想要展示的具体最大列数。
展示单元格的全部内容
data1 = pd.DataFrame({'name': ['O'*80, 'X'*80]})
data1
像上图中如果一个单元格内的内容太多可能会缩略掉,若想展示全部内容的话也可以通过pandas设置来改变:
pd.set_option('display.max_colwidth', None)
data1
改变单元格中的浮点数位数
data2 = pd.DataFrame(np.random.randn(8, 5))
data2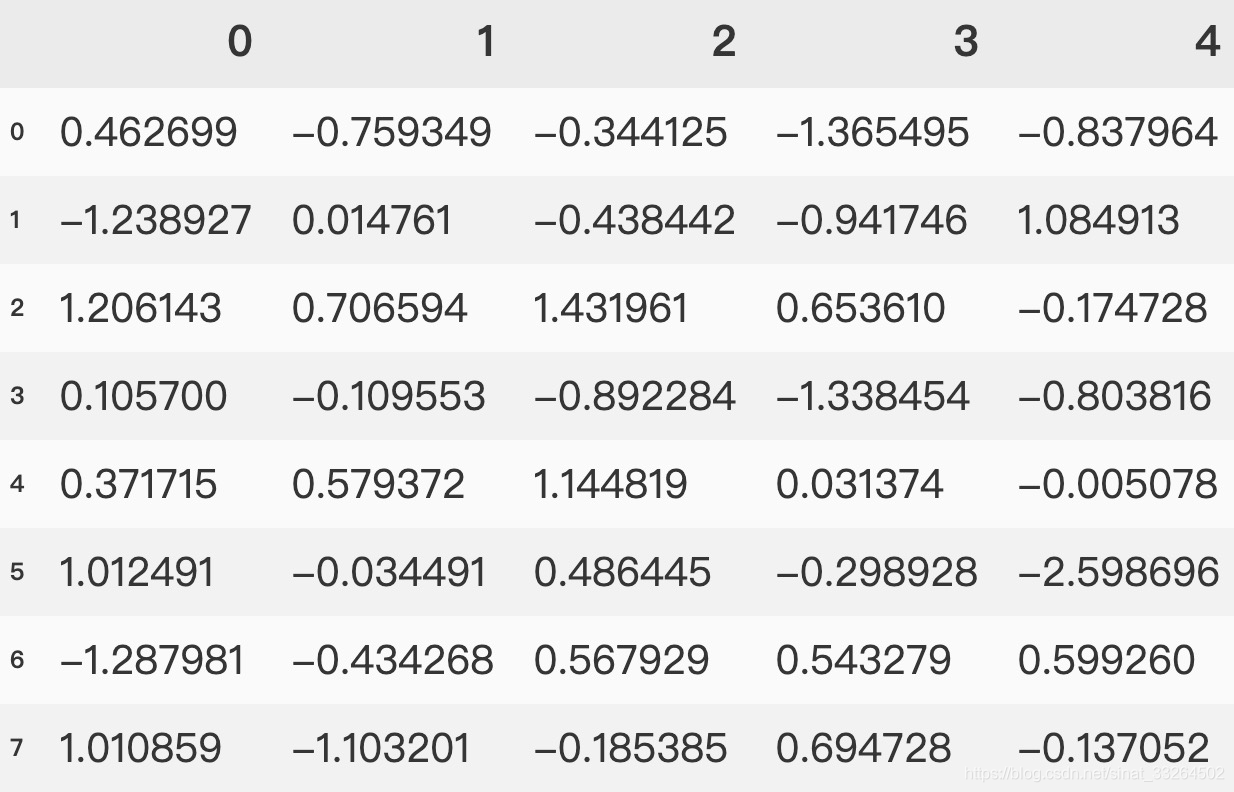
pandas的单元格内浮点数默认为六位,我们可以通过pandas的设置来改变浮点数的位数:
pd.set_option('display.precision', 3)
data2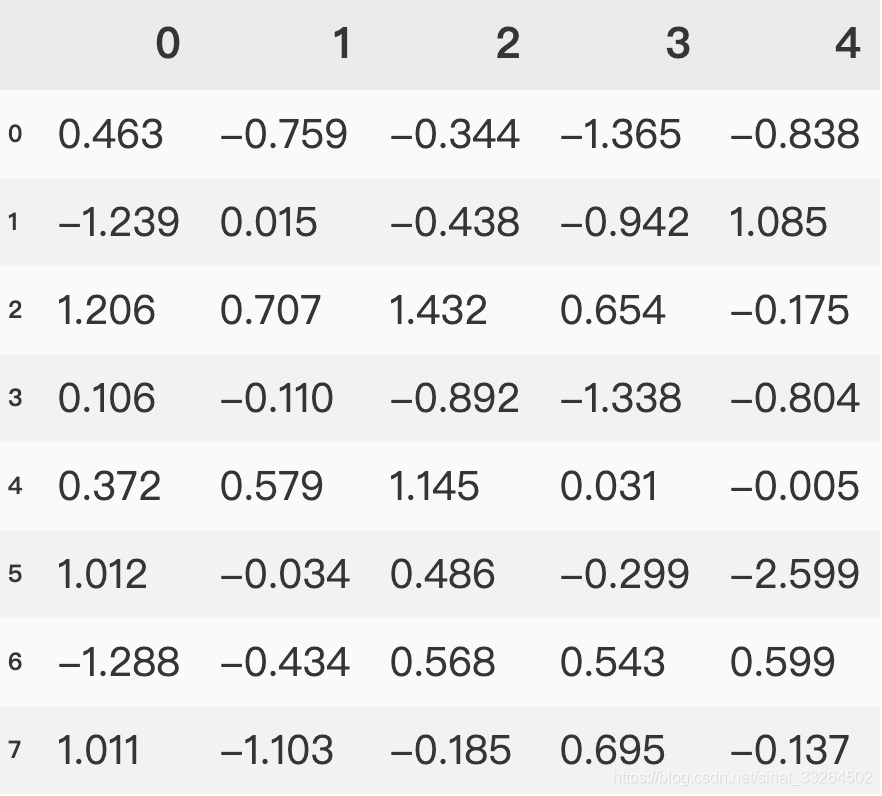
重置pandas设置
比如我们想要将上面的浮点数设置还原成原来的六位,那我们可以通过reset_option:
pd.reset_option('display.precision')
data2
改变单元格中浮点数的格式
pd.set_option('display.float_format', '{:.2%}'.format)
data2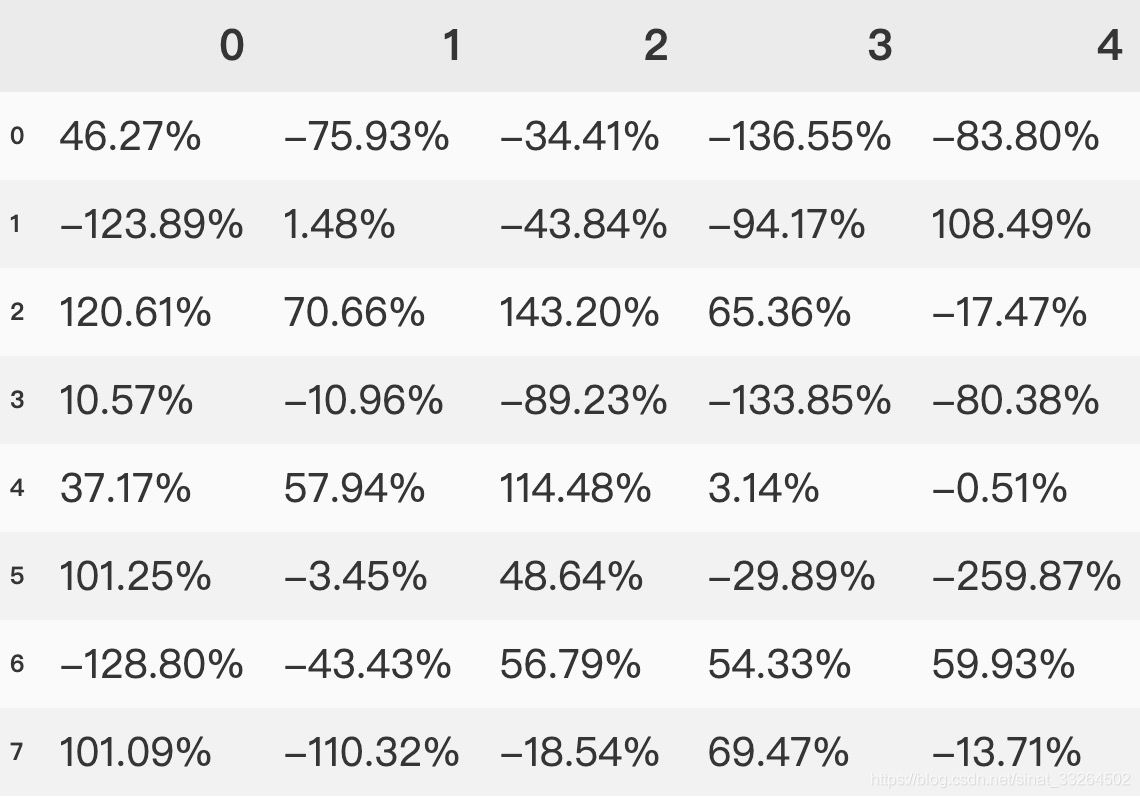
还可以通过format的方法对不同的列进行不同的改变格式,首先创建一个分组数据:
pd.reset_option('display.float_format')
data.groupby('grade')['installment'].agg(['mean', 'sum', 'count']).reset_index()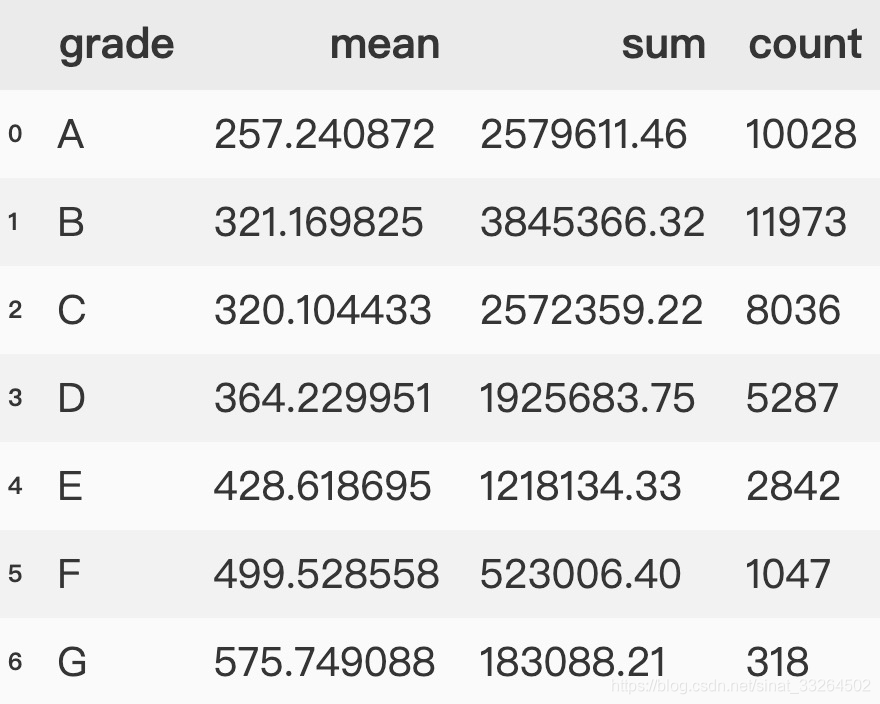
然后通过.style.format的方法:
data.groupby('grade')['installment'].agg(['mean', 'sum', 'count']).reset_index().style.format({'mean':'${0:,.2f}', 'sum':'${0:,.2f}'})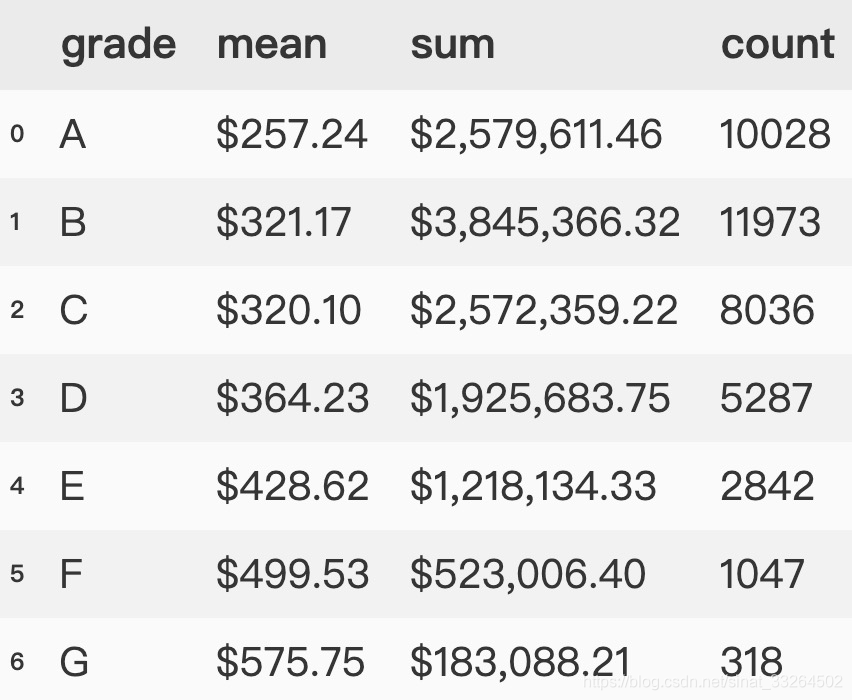
用色条显示出列中的最大值与最小值
然后我们再尝试加入新的一列:
group_data = data.groupby('grade')['installment'].agg(['mean', 'sum', 'count']).reset_index()
group_data['count_%'] = group_data['count']/data['installment'].count()
group_data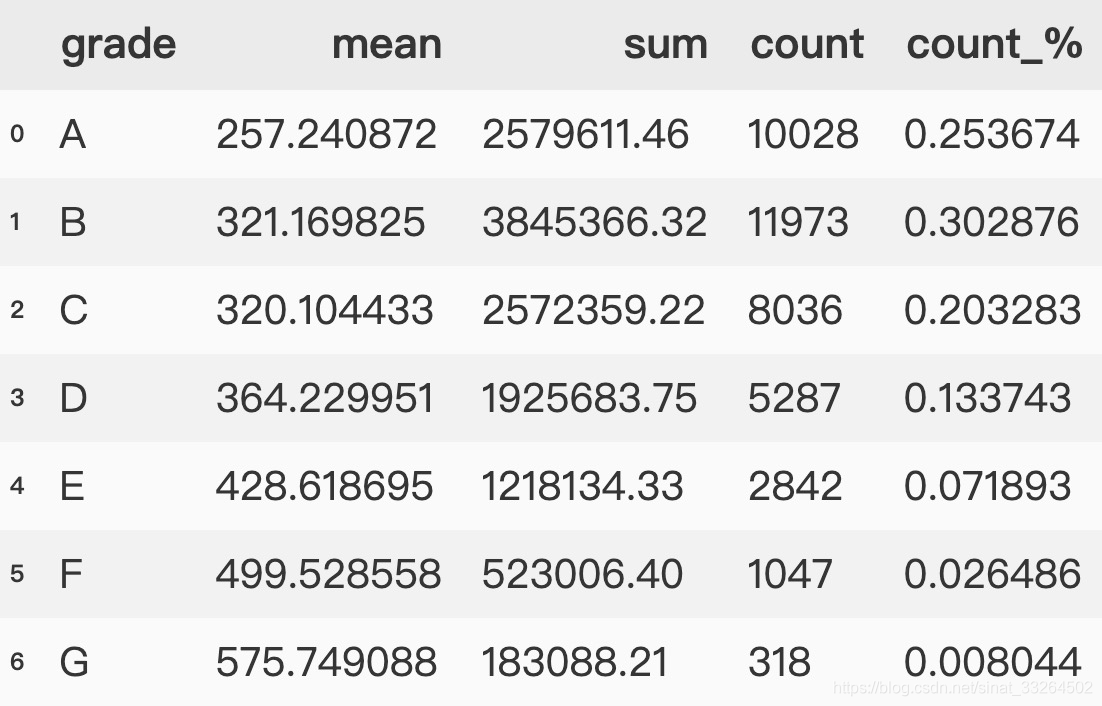
format_dict = {'mean':'${0:,.2f}', 'sum': '${0:,.0f}', 'count_%': '{:.2%}'}(group_data.style.format(format_dict).highlight_max(subset='count_%', color='red').highlight_min(subset='count_%' ,color='lightgreen'))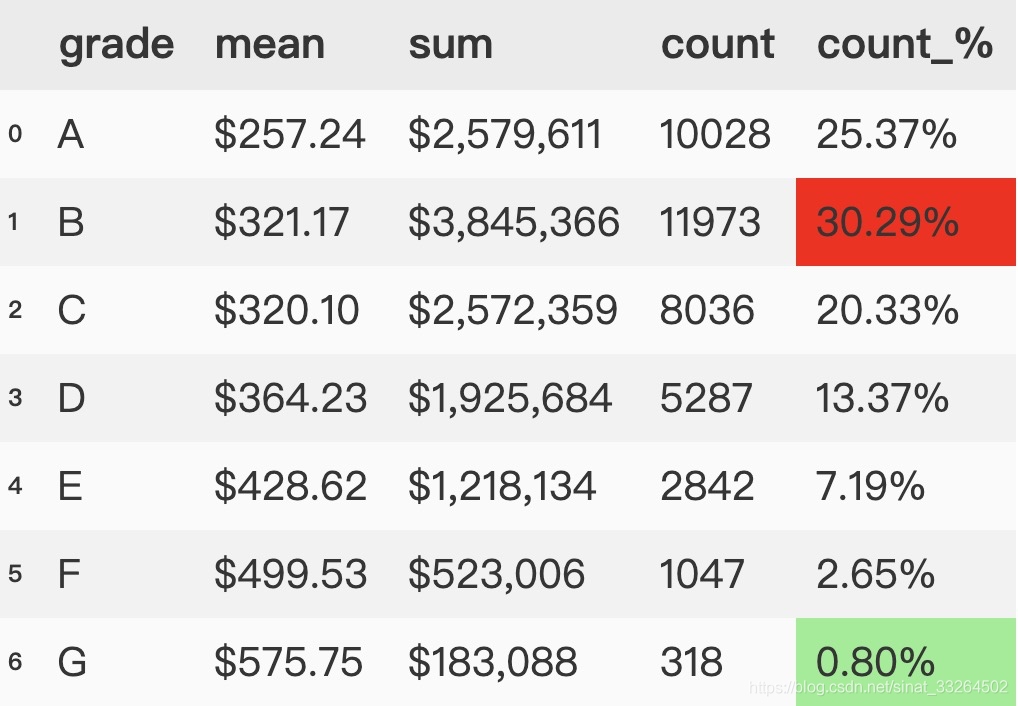
用渐变色块展示列中数值的大小
(group_data.style.format(format_dict).background_gradient(subset=['mean', 'sum'], cmap='BuGn'))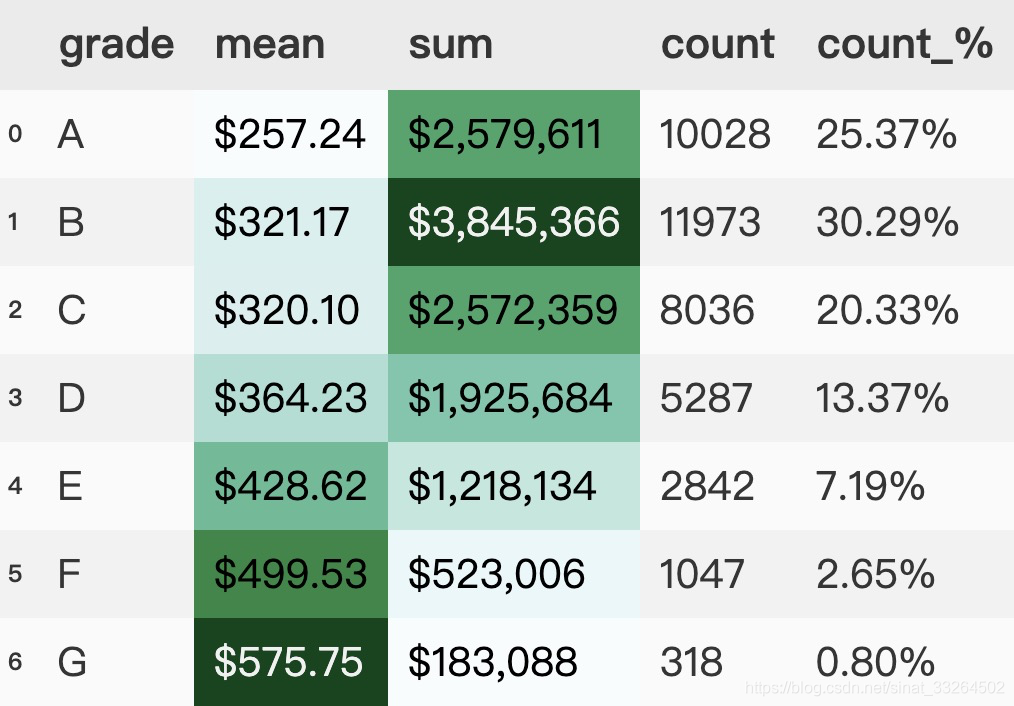
在dataframe中我们还可以使用柱状图来展示:
(group_data.style.format(format_dict).bar(color='lightblue', vmin=0, subset=['mean'], align='left').bar(color='lightgreen', vmin=0, subset=['sum'], align='left'))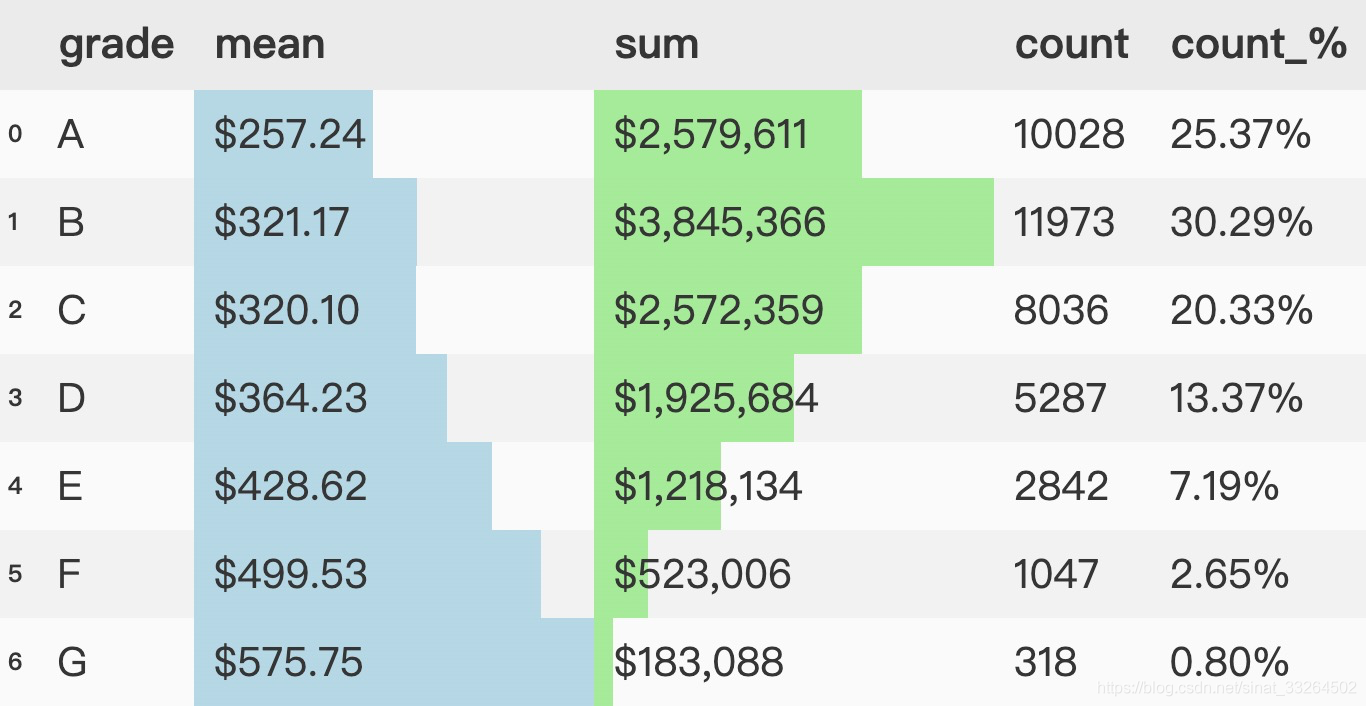
一行代码展示数据探索性分析
利用pandas-profiling库我们可以非常便捷有效地对pandas数据进行初步探索性分析。
首先是安装方法:
# 注意是“-”而不是“_”
pip install pandas-profiling
# 清华源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas-profilingfrom pandas_profiling import ProfileReport
# 两种方法,ProfileReport(data)或者下面这种
data.profile_report()经过片刻等待后,一份清晰完整的数据探索性分析报告就展示在我们面前了,包括每个特征的属性与分布,一些警告,特征之间的相关性,以及对缺失值的统计等。
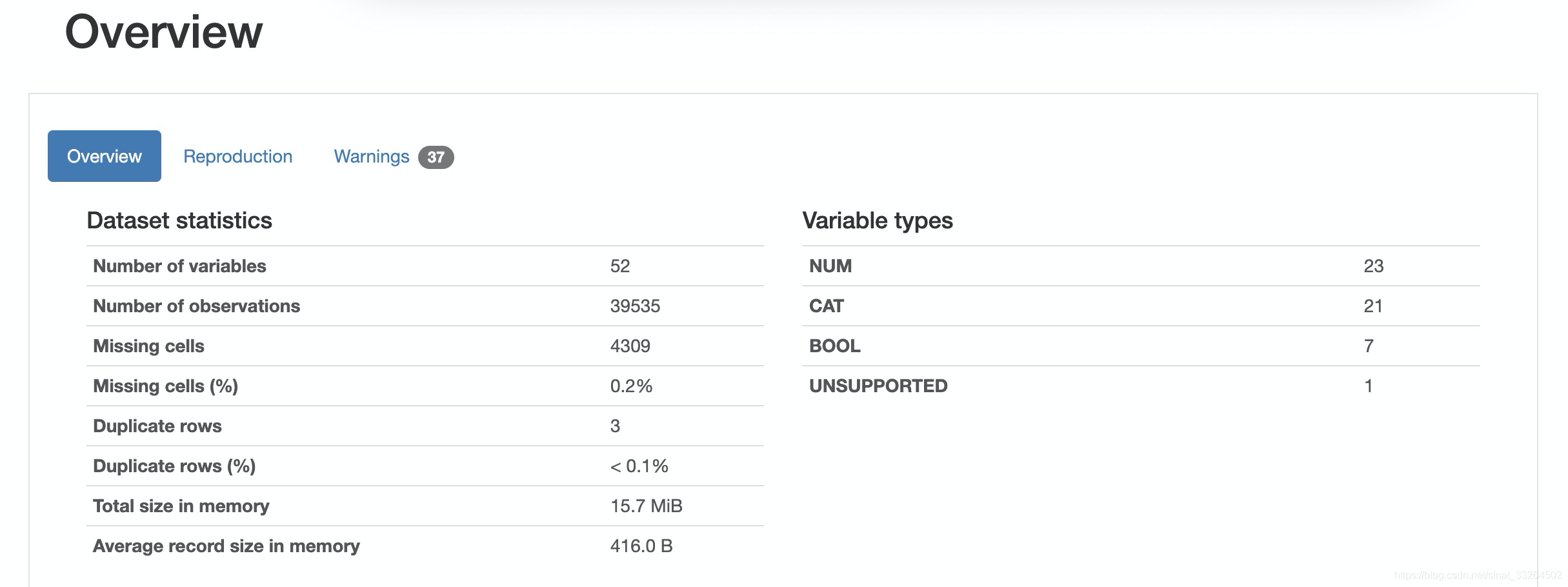
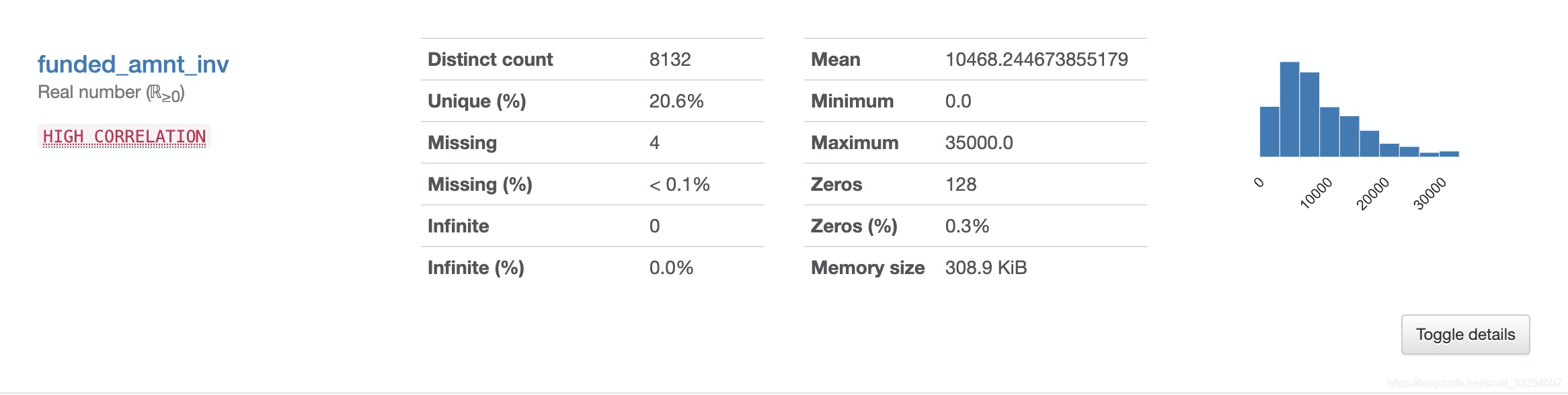


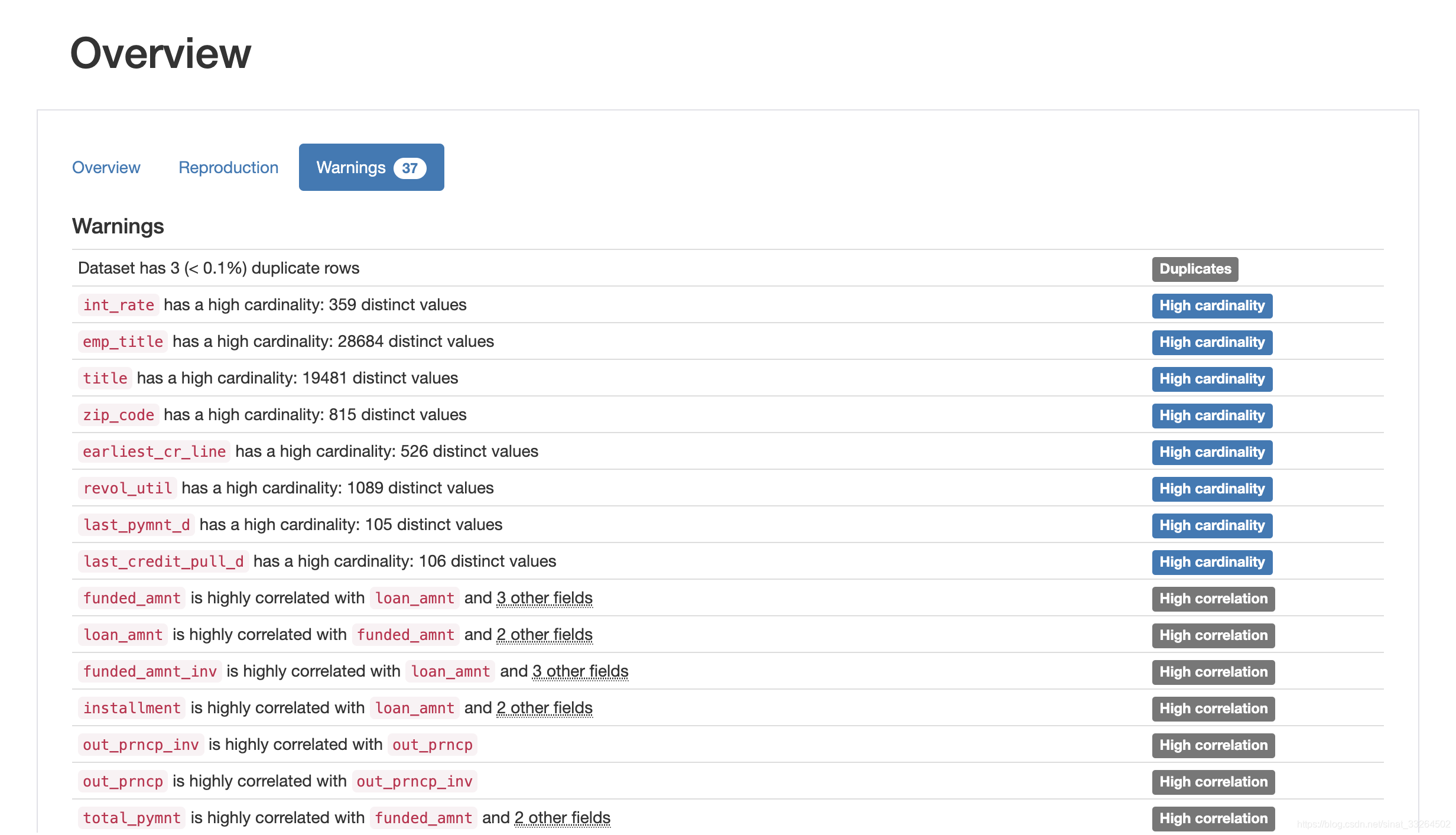
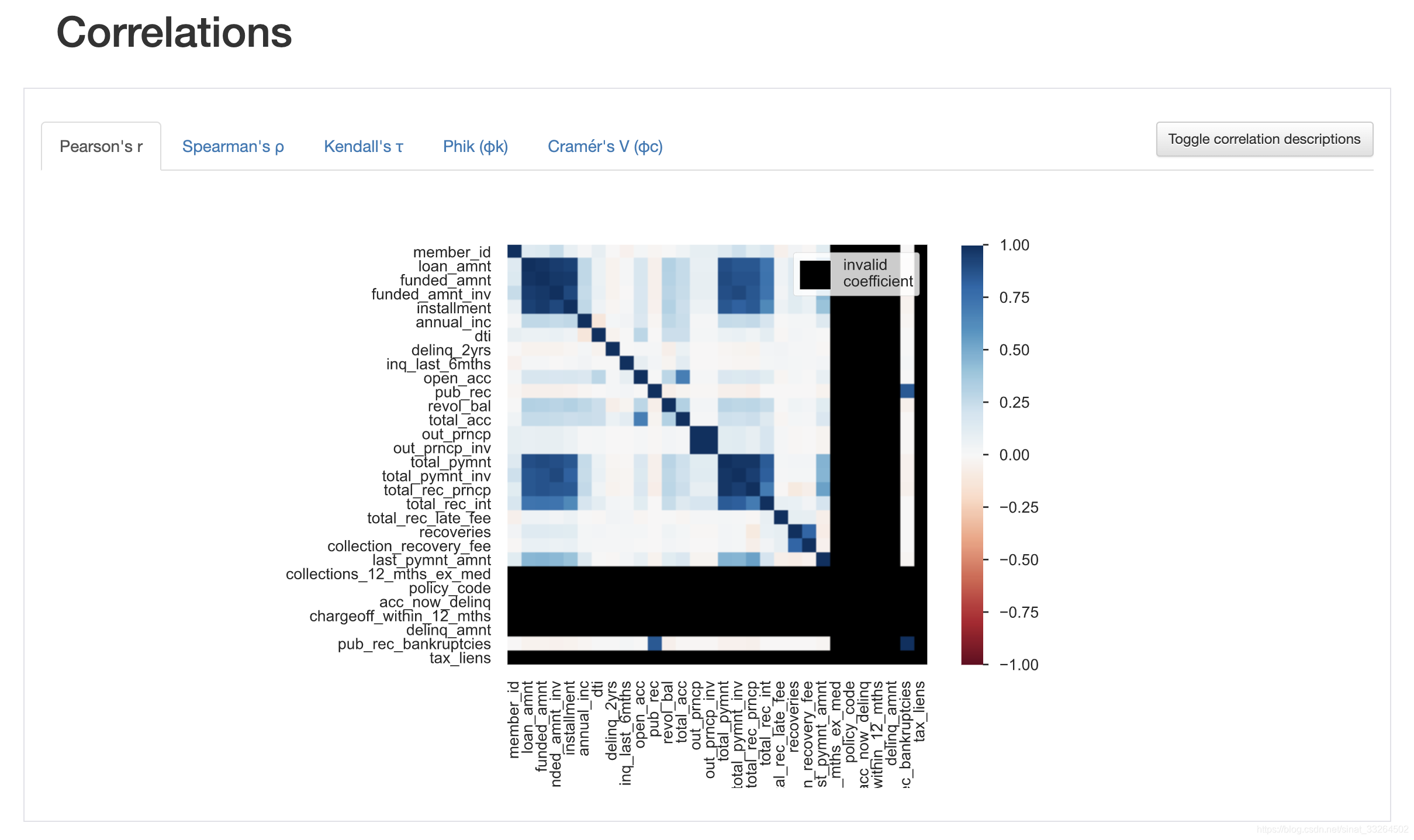
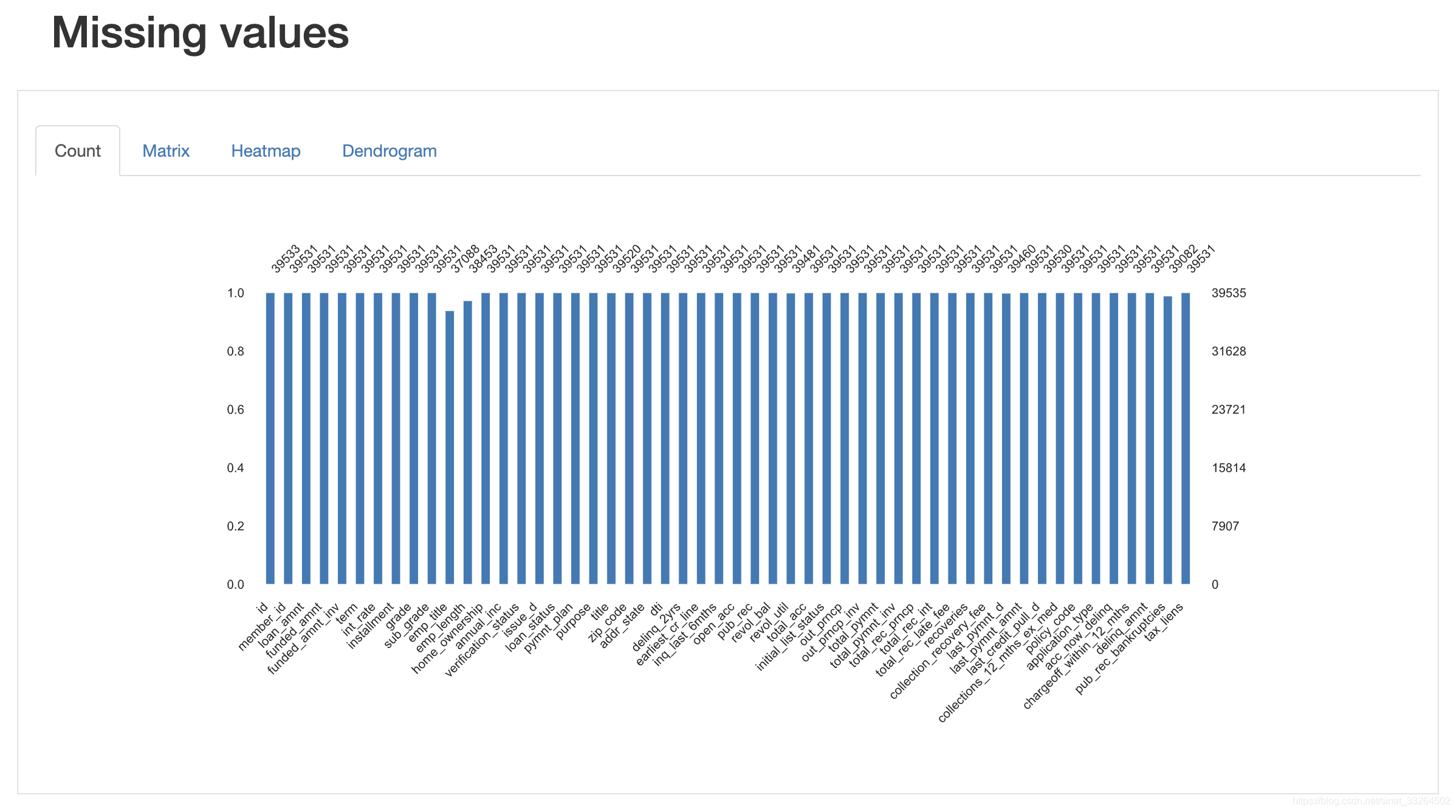
数据集与代码可关注公众号“数据科学与人工智能技术”并发送“探索性分析”获取。

这篇关于用pandas轻松搞定数据探索性分析(pandas参数、pandas风格、pandas-profiling)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



