本文主要是介绍爬虫加密算法浅入浅出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前提
搞爬虫的,最怕请求里有参数突然的加密。模拟Web操作的Selenium或模拟APP操作的Appium虽然能很好地规避这个问题,但采集成本的增加和采集效率的降低不容忽略。
本文介绍了JS中最常用的加密算法,旨在帮助爬虫人增加对加密参数的敏感性。俗话说得好:“枪在手,跟我走;杀四郎,抢碉楼”。

加密算法介绍
伪加密算法:Base64
Base64是一种用64个字符来表示任意二进制数据的方法。使用Base64将明文变成密文的操作最多算是混淆。没有密钥注入算法,所以只要拿到密文进行Base64解密就能得到对应的明文。
由于Base64的编码的特性,要编码的二进制数据如果不是3的倍数,最后会剩下1个或2个字节,Base64用“\x00”字节在末尾补足后,再在编码的末尾加上1个或2个“=”号,表示补了多少字节。根据这个特性,一般密文结尾处如果是“=”结尾的,可以先判断是Base64编码而成。
信息摘要算法:MD5、SHA
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。摘要算法不能被称为加密算法,因为它是单向操作明文的。单向操作的意思就是,将明文变成密文之后是无法再将密文变成明文。
基于这种单向操作的特性,摘要算法一般被用于确保信息传输完整一致。在实际JS逆向中,哈希函数的源码经常会被改写,成为定制版哈希函数;还有就是在哈希过程中,明文会被加盐值,遇到这种情况就需要认真分析源码。
无论明文数据的长度,经过哈希之后,长度都是固定的。MD5是32位十六进制数,SHA1是40位十六进制数,SHA224是56位十六进制数等等。在获得密文数据后,可先判断是否是十六进制数构成,再判断其长度是否是常见信息摘要位数。
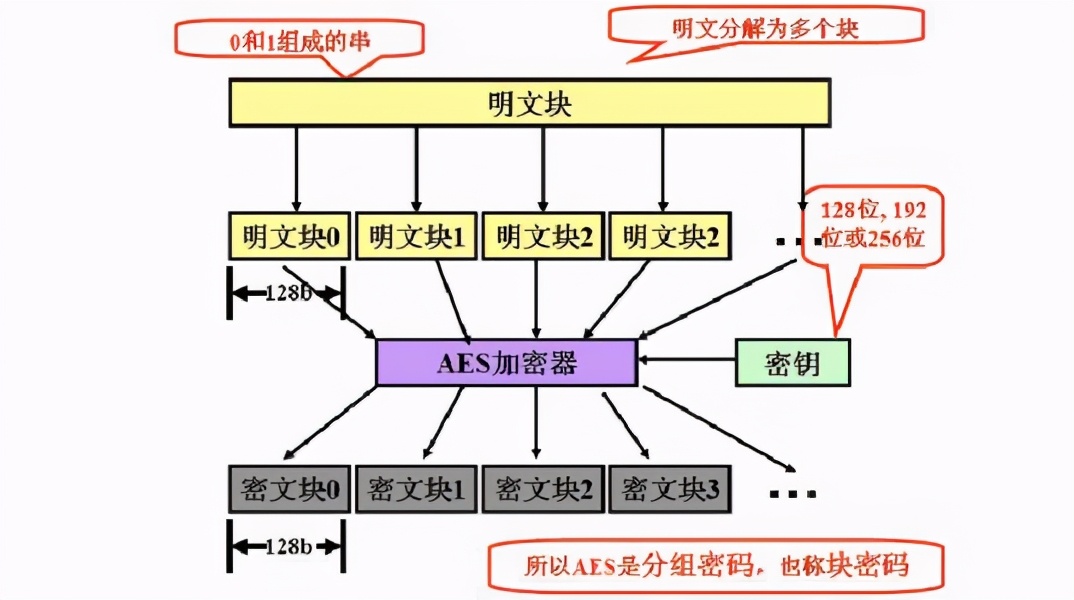
对称加密(加密解密密钥相同):DES、3DES、AES
对称加密的核心就是密钥,拿到密钥就等于拿到数据。密文数据的长度会随着明文数据的长度而变化。
非对称加密(分公钥私钥):RSA
对付像RSA这种非对称加密算法,我们心中应牢记十六字方针:“公钥加密,私钥解密。私钥加密,公钥解密”。在非对称加密算法中,加密与解密的密钥肯定是不一样的(一样的话,就不叫非对称加密算法了)。牢记十六字方针后,我们只要找到公钥和私钥就能解密了。
RSA公钥加密会进行类似MD5加盐的操作,所以相同的明文,用相同的公钥进行RSA加密会生成不同的密文。RSA的密钥对不仅可能存在JS代码中,还有很有可能会存在在HTML文件中。这时我们进行全局搜索关键词RSA、Key、Encrypt,一处处判别就会有意外收获。
补充
在实际逆向项目中,MD5、SHA、AES、RSA、自定义加密函数使用频率是最多的。而且极有可能会碰到多种不同加密算法混合使用,例如:网页数据先Base64再AES再进行Base64,或者解密明文的RSA的密钥对被AES加密了等等情况。
DES、3DES、AES、RSA、MD5、SHA传入的数据或者密钥都是bytes数据类型,不是bytes数据类型的需要先转换;密钥一般是8的倍数。
这篇关于爬虫加密算法浅入浅出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







