本文主要是介绍数据分析-19-Thera Bank信贷业务数据(包含数据代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0. 数据代码下载
- 1. 数据集介绍
- 1.1 原始数据集变量的含义:
- 1.2 原始数据的读入与清洗
- 1.3 数据清洗及预处理
- 2. 探索数据变量
- 2.1 数据相关系数的探索
- 2.2 分类变量与开通贷款的关系探索
- 2.2.1 银行存款证(CD)帐户与贷款之间的关系
- 2.2.2 教育水平与贷款之间的关系
- 2.2.3家庭人数与贷款之间的关系
- 2.3 数值变量与开通贷款的关系探索
- 2.3.1 收入与贷款之间的关系
- 2.3.2 信用卡还款与贷款之间的关系
- 2.3.3 房屋抵押值与贷款之间的关系
- 3. 结论
0. 数据代码下载
关注公众号:『AI学习星球』
回复:信贷业务数据 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我

本文是通过kaggle上的某银行对现有客户数据进行数据分析,并推行新产品的贷款问题,确定用户定位,使零售营销部门制定活动以更好地定位营销,以最小的预算提高成功率。该部门希望识别出更有可能购买贷款的潜在客户,提高转化成功率。
1. 数据集介绍
本数据集来源于Kaggle上的银行Thera Bank,其是一家拥有不断增长的客户群的银行。这些客户中的大多数是具有不同存款规模的存款用户。为了增加贷款业务的客户量,提升公司的利润,他们随机选取了5000名顾客进行了一次贷款业务的营销宣传尝试,并获得了9%左右的转化率。
本次数据分析的目的:
- 向银行客户销售更多的个人贷款产品。
- 设计营销活动,以更好的目标营销,以最低的预算提高成功率。
- 识别购买贷款可能性较高的潜在客户。
- 通过建立用户画像,确定目标销售人群,实现精准营销的目的。
1.1 原始数据集变量的含义:
数据集为xlsx格式,文件大小343KB。数据共计14个字段,5000条。具体变量名与相应的变量含义如下:
| 字段名称 | 字段含义 |
|---|---|
| ID | 客户ID |
| Age | 客户年龄 |
| Experience | 客户工作经验 |
| Income | 客户年收入(单位:千美元) |
| ZIPCode | 家庭地址邮政编码 |
| Family | 客户的家庭规模 |
| CCAvg | 每月信用卡平均支出(单位:千美元) |
| Education | Education - 教育水平 1:未毕业;2:毕业生;3:高级/专业 |
| Mortgage | 房屋抵押价值(单位:千美元) |
| Personal Loan | 此客户是否接受上一次活动中提供的个人贷款?(1:是 0:否) |
| Securities Account | 客户在银行有证券账户吗?(1:是 0:否) |
| CD Account | 客户在银行有存款证(CD)帐户吗(1:是 0:否) |
| Online | 客户是否使用网上银行设施?(1:是 0:否) |
| CreditCard | 客户是否使用环球银行发行的信用卡?(1:是 0:否) |
1.2 原始数据的读入与清洗
导入完python相关的numpy、Pandas包后,我们先对数据进行读取,并有一个初步的概况了解,该数据集为xlsx文件下的Data表。读取后看一下数据集的前五行以及数据相关信息情况
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
sns.set(style="ticks")import warnings
warnings.filterwarnings('ignore')
df = pd.read_excel("Bank_Personal_Loan_Modelling.xlsx","Data")
df.head()

df.info()
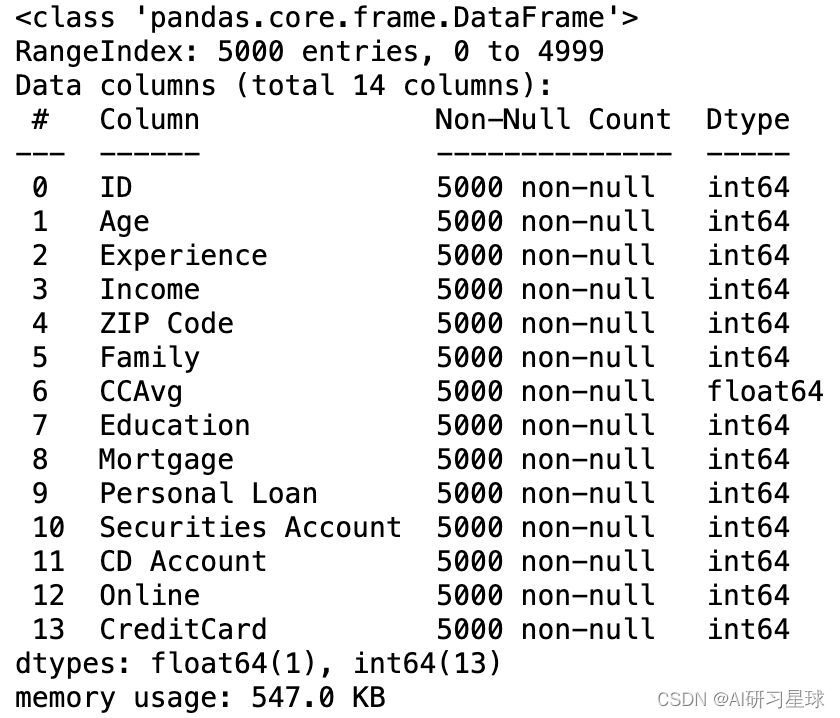
df.describe().T
1.3 数据清洗及预处理
在查看数据集的描述性统计后,我们可以看到在Experience这一栏上的最小值为-3,且因在工作经验上不会有负值的存在,因此可认为是异常值,我们对这部分工作经验小于0的数值进行处理,且又因工作经验和年龄及受教育程度是有一定联系关系的,我们将工作经验小于0的数值,转换成相同年龄和受教育程度的中位数值
dfExp_normal = df.loc[df['Experience']>=0]
dfExp_abnormal = df["Experience"]<0
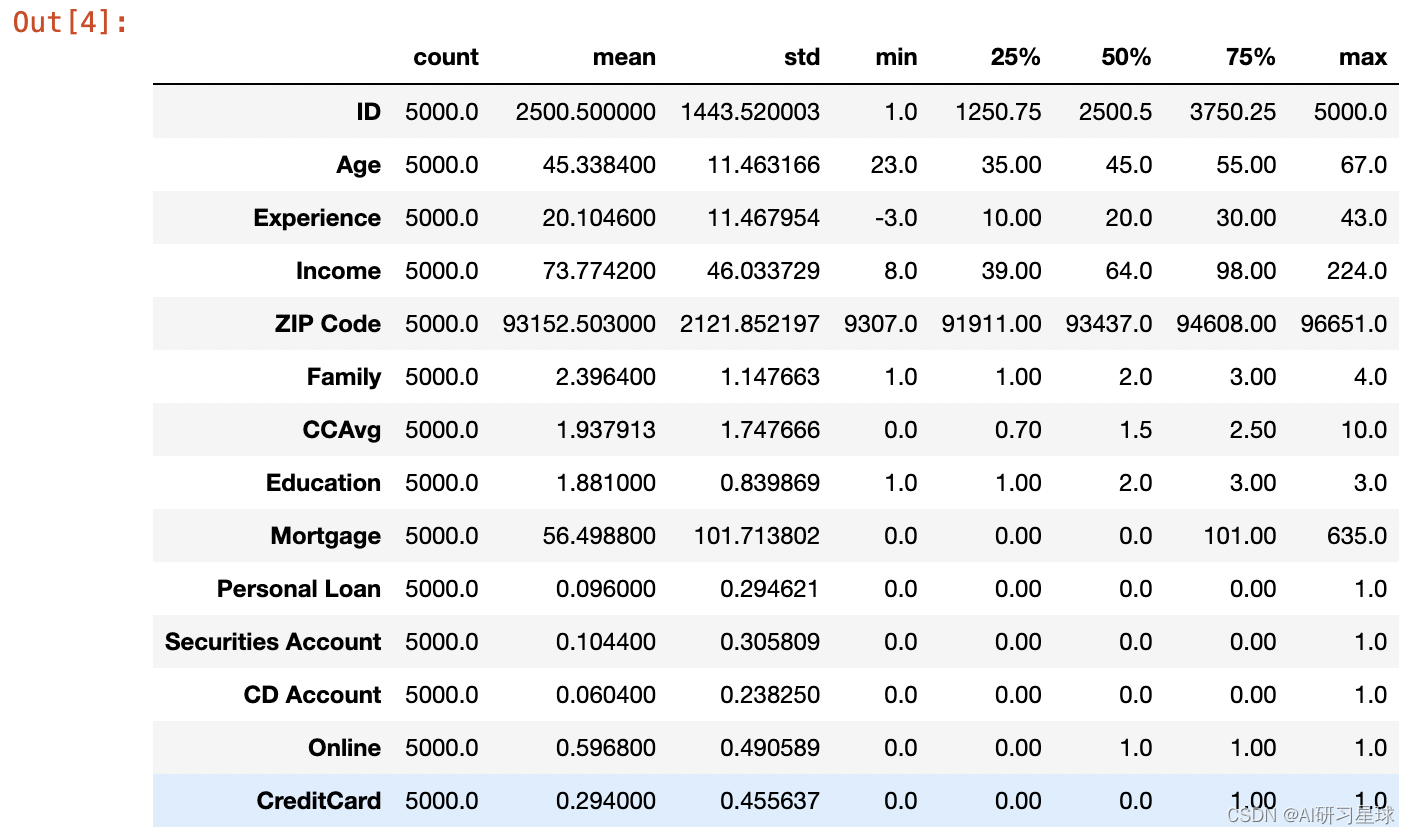
mylist = df.loc[dfExp_abnormal]['ID'].tolist()for id in mylist:age = df.loc[df['ID'] == id].Age.tolist()[0]education = df.loc[df['ID'] == id].Education.tolist()[0]df_filtered = dfExp_normal.query('Age==@age and Education==@education')exp=df_filtered['Experience'].median()if exp is np.nan:exp = df['Experience'].median()df.loc[df.query('ID==@id').index, 'Experience'] = expdf.describe().T
清洗后对再次查看数据集描述性统计信息,如下图
数据清洗完毕,没有缺失值,且没有明显的异常现象。
关注公众号:『AI学习星球』
回复:信贷业务数据 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我
2. 探索数据变量
2.1 数据相关系数的探索
接下来我们对某些变量进行分析,由于我们的目标是以有没有贷款(Personal Loan)为测试,首先我们选择查看一下相关性:
df.corr()["Personal Loan"].sort_values(ascending = False)
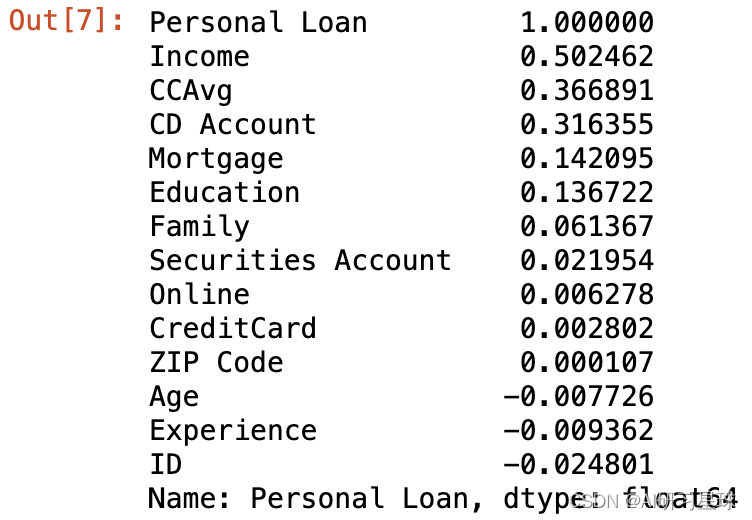
我们对与Personal Loan相关系数较高的Income(收入)、CCAvg(每月信用卡平均支出)、CD Account(是否有存款证(CD)帐户)、Mortgage(房屋抵押价值)、Education(教育水平)、Family(家庭人数)进行比较图
sns.pairplot(df,vars=['Income','CCAvg',"CD Account","Mortgage","Education","Family"],hue='Personal Loan',palette='muted')

总结:从上图我们可以粗略判断:
- 一般而言,收入越高的人群中,愿意贷款的会越多。
- 收入,信用卡还款额和房屋抵押租赁,接近于幂律分布。
- 相同收入下,信用卡还款额多的用户,也不愿意申请贷款;
我们接下来对各变量之间的相关性进行探索,并绘制出热力图
#计算各变量之间的相关性
corr = df.corr()
sns.set_context("notebook", font_scale=1.0, rc={"lines.linewidth": 2.5})
plt.figure(figsize=(13,7))
#设置一个mask,我们只看下半部分的相关性
mask = np.zeros_like(corr)
mask[np.triu_indices_from(mask, 1)] = True
a = sns.heatmap(corr,mask=mask, annot=True, fmt='.2f')
rotx = a.set_xticklabels(a.get_xticklabels(), rotation=30)
roty = a.set_yticklabels(a.get_yticklabels(), rotation=30)
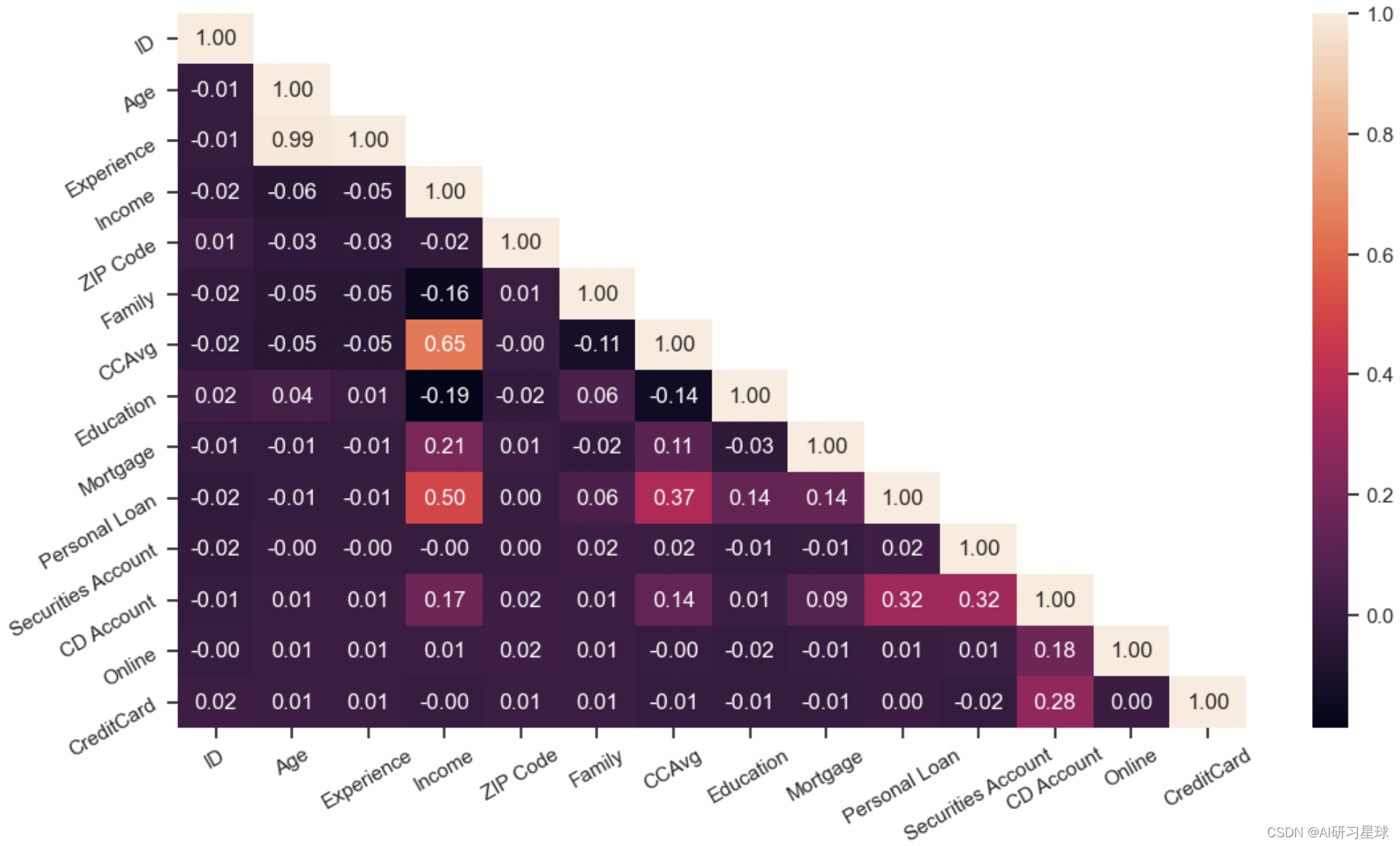
总结:从图中可看出:
- 和是否有开贷款有高度相关性的是:收入、信用卡还款额和是否有该银行存单账户。
- 和是否有开贷款有弱相关性的是:受教育程度,房屋抵押贷款数,家庭人数;
- 因为年龄、工作经验都是连续的数值变量,图中无法显示是否有相关性,我们将对其进行计数统计。
2.2 分类变量与开通贷款的关系探索
我们对分类变量中是否有该银行存单账户、受教育程度、家庭人数进行探究
2.2.1 银行存款证(CD)帐户与贷款之间的关系
print(df.groupby('CD Account')['Personal Loan'].agg([np.mean]))
sns.countplot(x="CD Account",data=df,hue='Personal Loan')
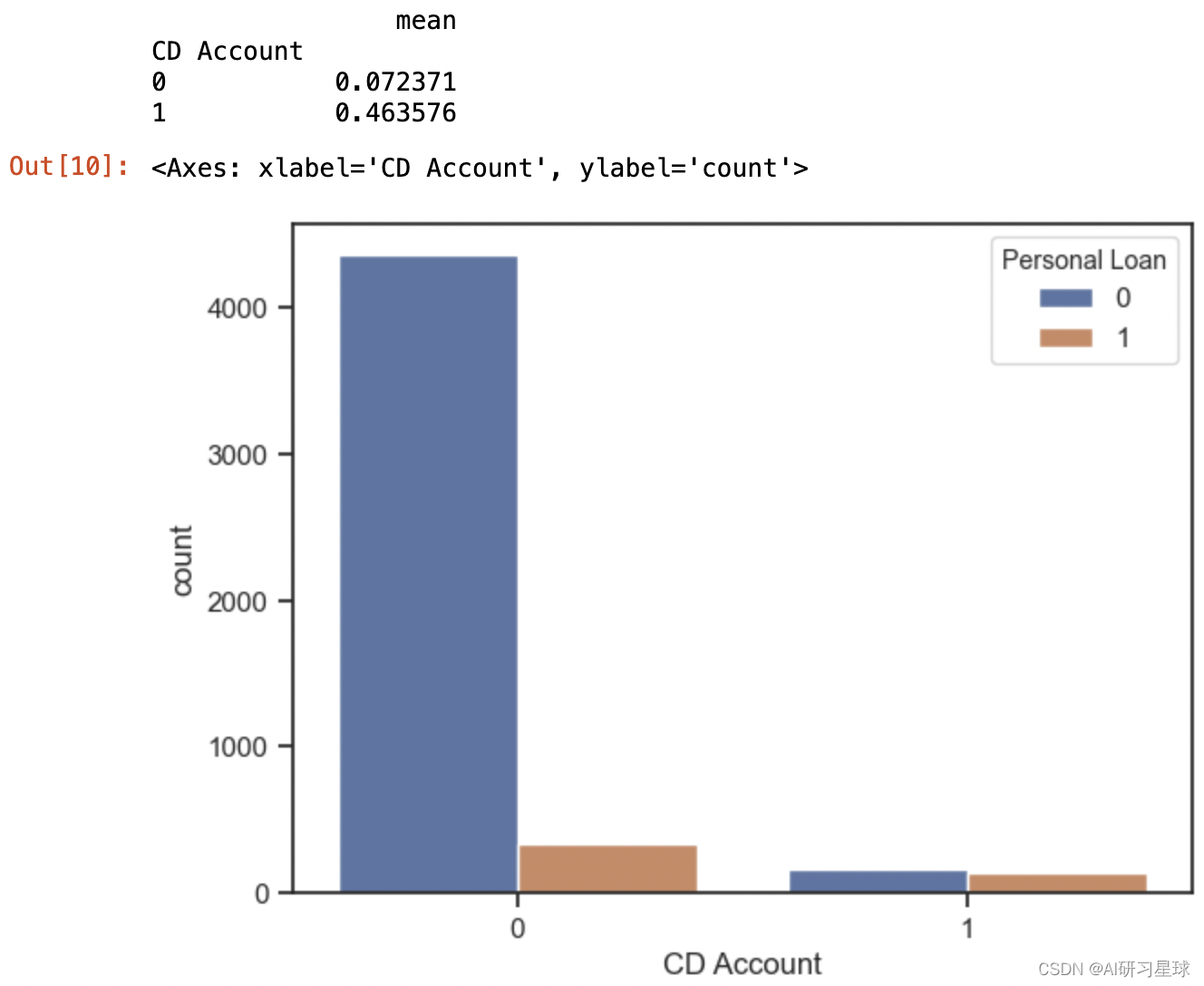
结论:
- 可见绝大部分没有没有银行存单账户的客户都没选择申请贷款;
- 而开通了银行存单账户的客户,申请贷款的可能性比没开通银行存单的客户多6倍
建议:
可重点着手于寻找更多的开通了银行存单账户的客户作为目标,或者让更多没有银行存单的客户开通银行存单是提高申请贷款的一个可能选项
2.2.2 教育水平与贷款之间的关系
print(df.groupby("Education")['Personal Loan'].agg([np.mean,'count']))
sns.countplot(x="Education",data=df,hue='Personal Loan')
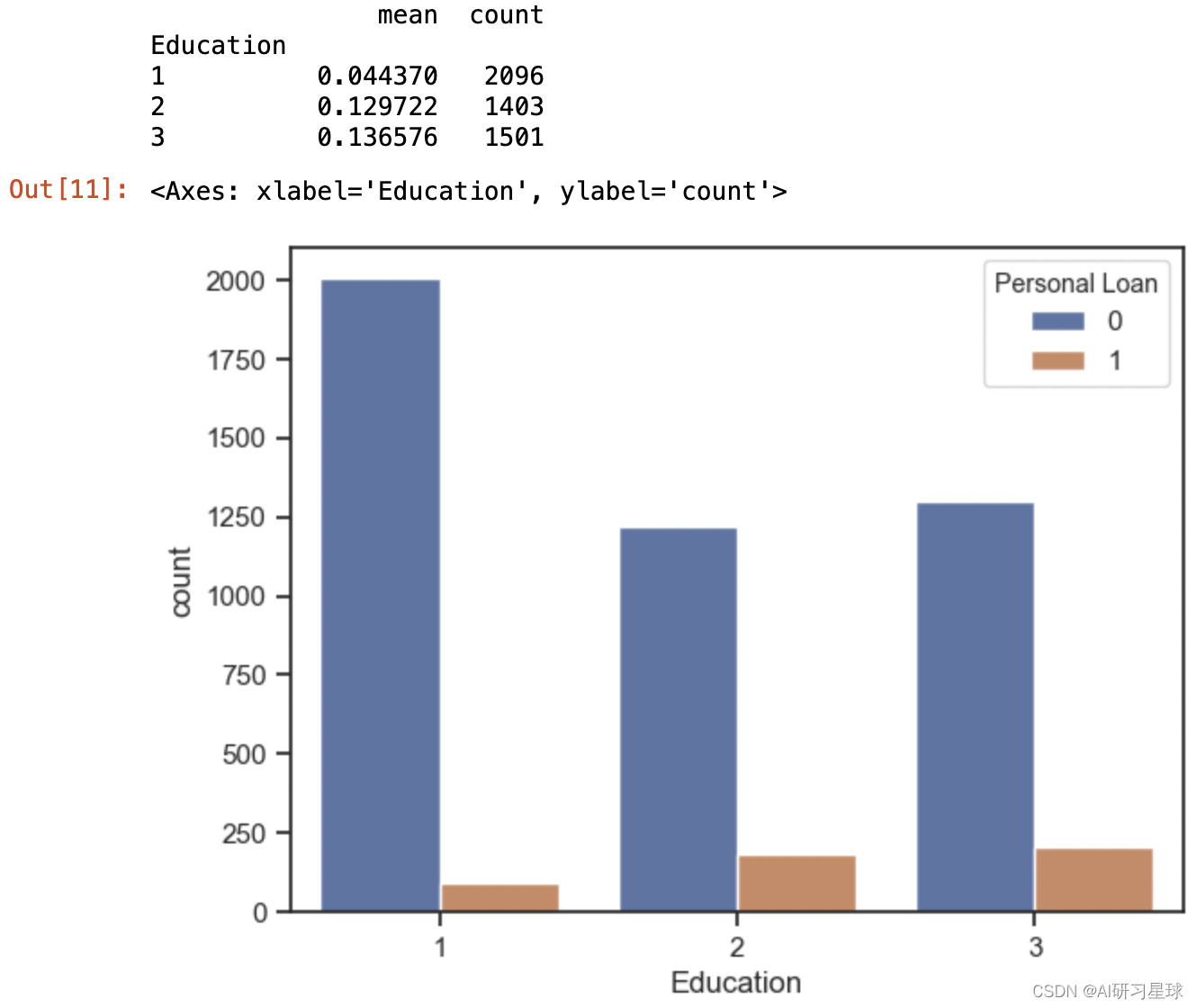
结论:
由图可见,在每个个学历段中,学历越高,贷款意愿的比率越多;
建议:
可从高学历客户人群中作为目标人群,这样贷款成功率会相对较高。
2.2.3家庭人数与贷款之间的关系
print(df.groupby("Family")['Personal Loan'].agg([np.mean]))
sns.countplot(x="Family",data=df,hue='Personal Loan')
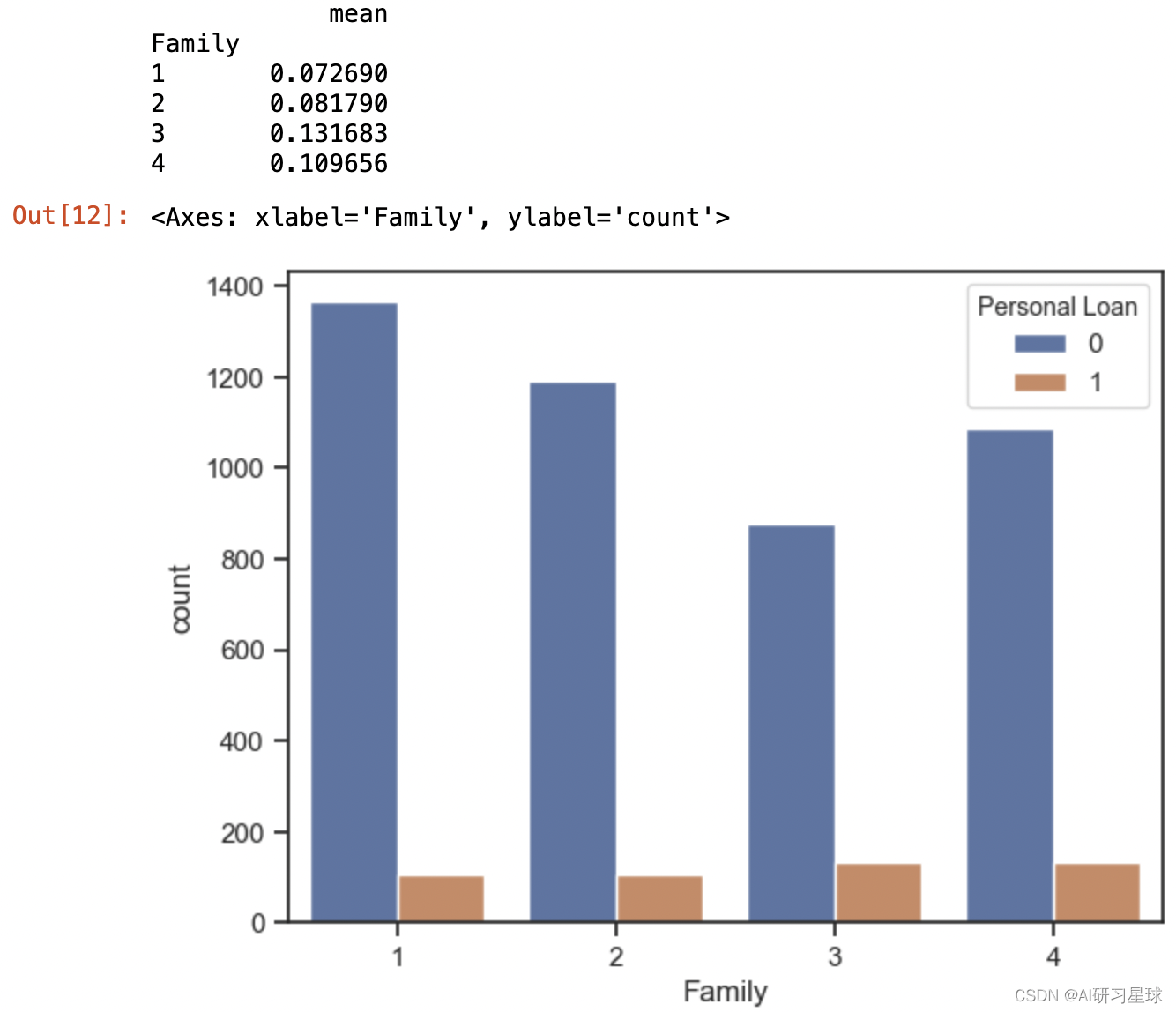
结论:
家庭人数为3的贷款申请最多,家庭人数为3和4时,贷款申请约是家庭人数1和2的两倍。
建议:
可从家庭人数3和4的客户人群中为目标人群。
关注公众号:『AI学习星球』
回复:信贷业务数据 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我
2.3 数值变量与开通贷款的关系探索
对数值变量中的收入、信用卡还款额和房屋抵押贷款进行探究
2.3.1 收入与贷款之间的关系
print(df.groupby('Personal Loan')['Income'].agg([np.mean,'count']))
sns.boxenplot(x='Personal Loan',y='Income',data=df,width=0.6)
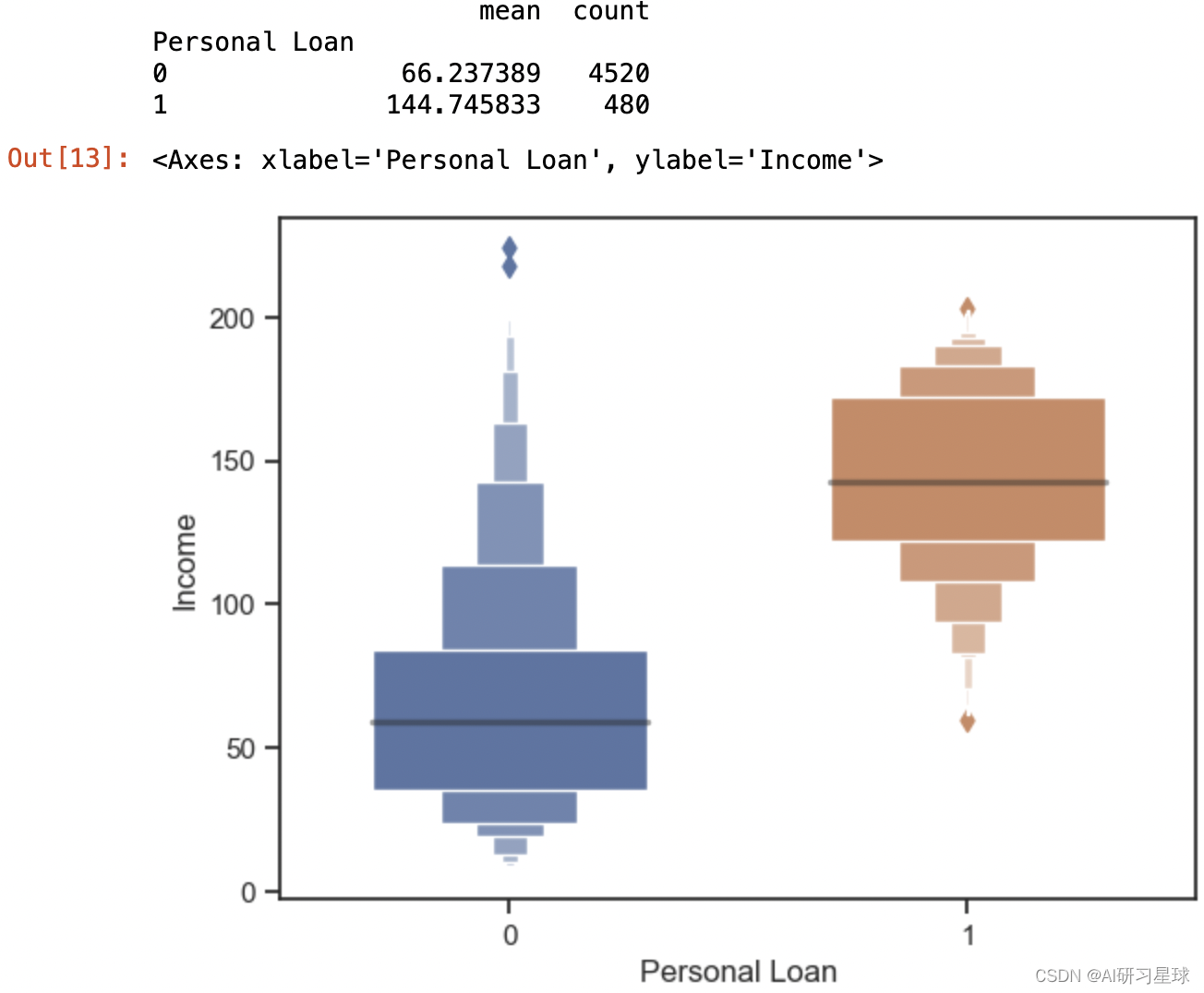
结论:高收入的人群会比低收入的人群更愿意申请贷款,但有部分很高收入的人群也是不愿申请贷款的,算是个例。
下面我们将细分哪个收入阶层会有较高的贷款意愿
df['Income Bins'] = pd.qcut(df.Income,20)
print(df.groupby('Income Bins')['Personal Loan'].agg([np.mean,'count']))
df.groupby('Income Bins').agg(Loan_rate = ('Personal Loan',np.mean)).plot()
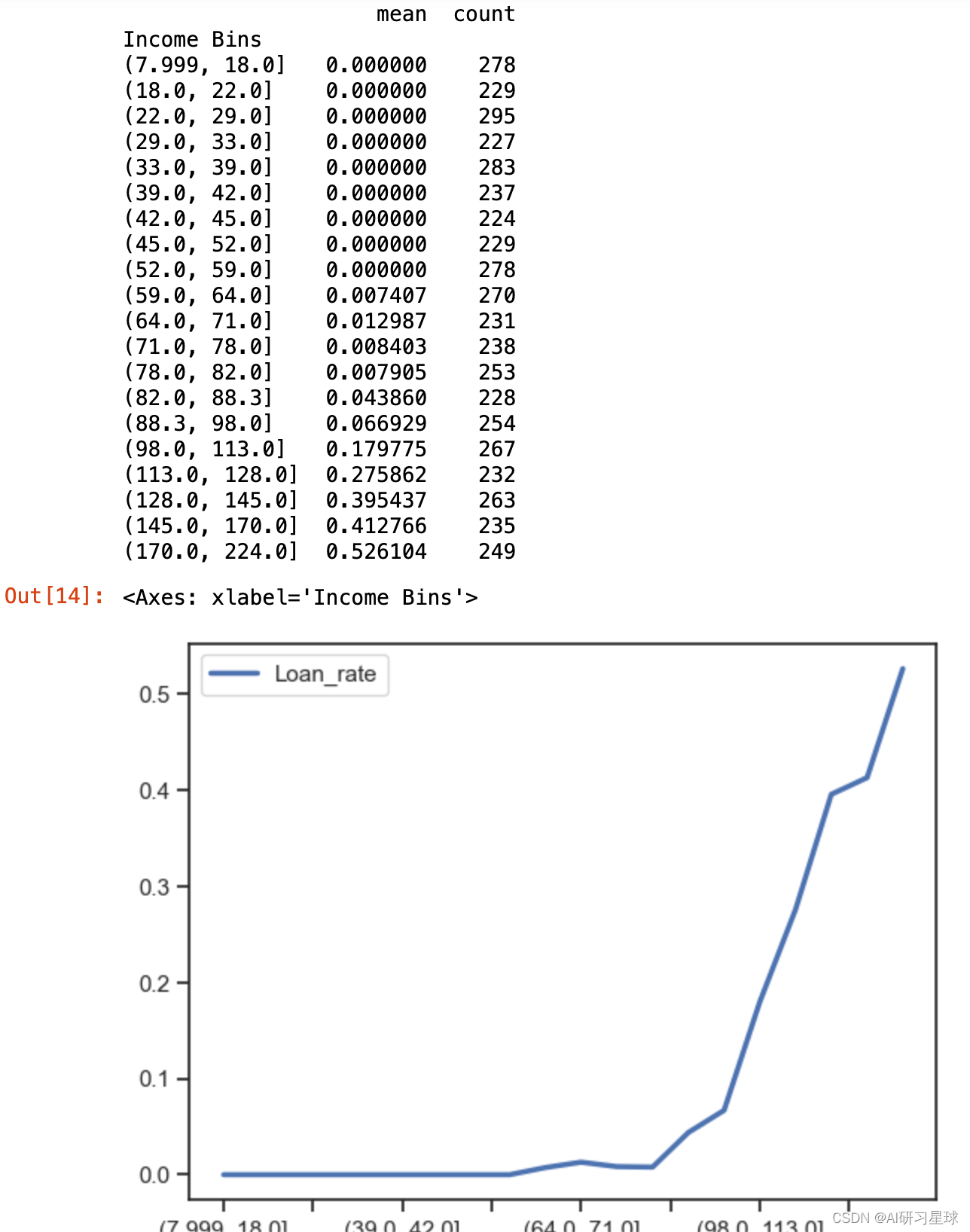
结论:
从图中可见,当年收入超过82千美元(即82000美元)时,贷款意愿会显著提升,而在98000美元到224000美元的年收入区间里,贷款意愿普遍在20%以上。
建议:
重点关注8000美元到224000美元的年收入的人群,贷款意愿最高。
2.3.2 信用卡还款与贷款之间的关系
print(df.groupby('Personal Loan')['CCAvg'].agg([np.mean,'count']))
sns.boxenplot(x='Personal Loan',y='CCAvg',data=df,width=0.6)
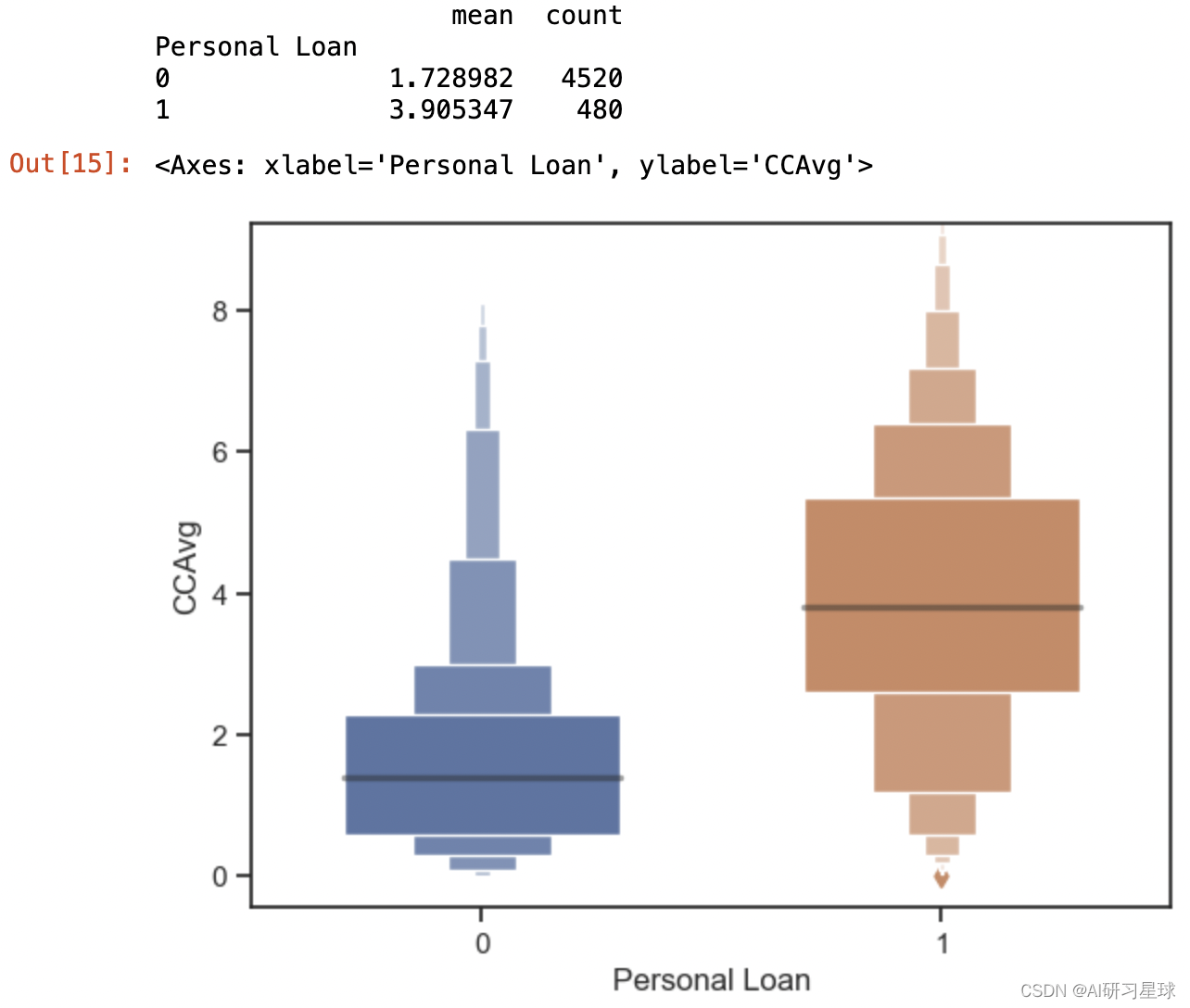
由上图可清晰看到大部分没有申请贷款的,信用卡还款额的均值只有1.7K的美元,而申请贷款的客户信用款还款额均值达到3.9K美元。
下面我们细分哪个信用卡还款额分段会有较高的贷款意愿
df['CCAvg Bins'] = pd.qcut(df.CCAvg,20)
print(df.groupby('CCAvg Bins')['Personal Loan'].agg([np.mean,'count']))
df.groupby('CCAvg Bins').agg(Loan_rate = ('Personal Loan',np.mean)).plot()
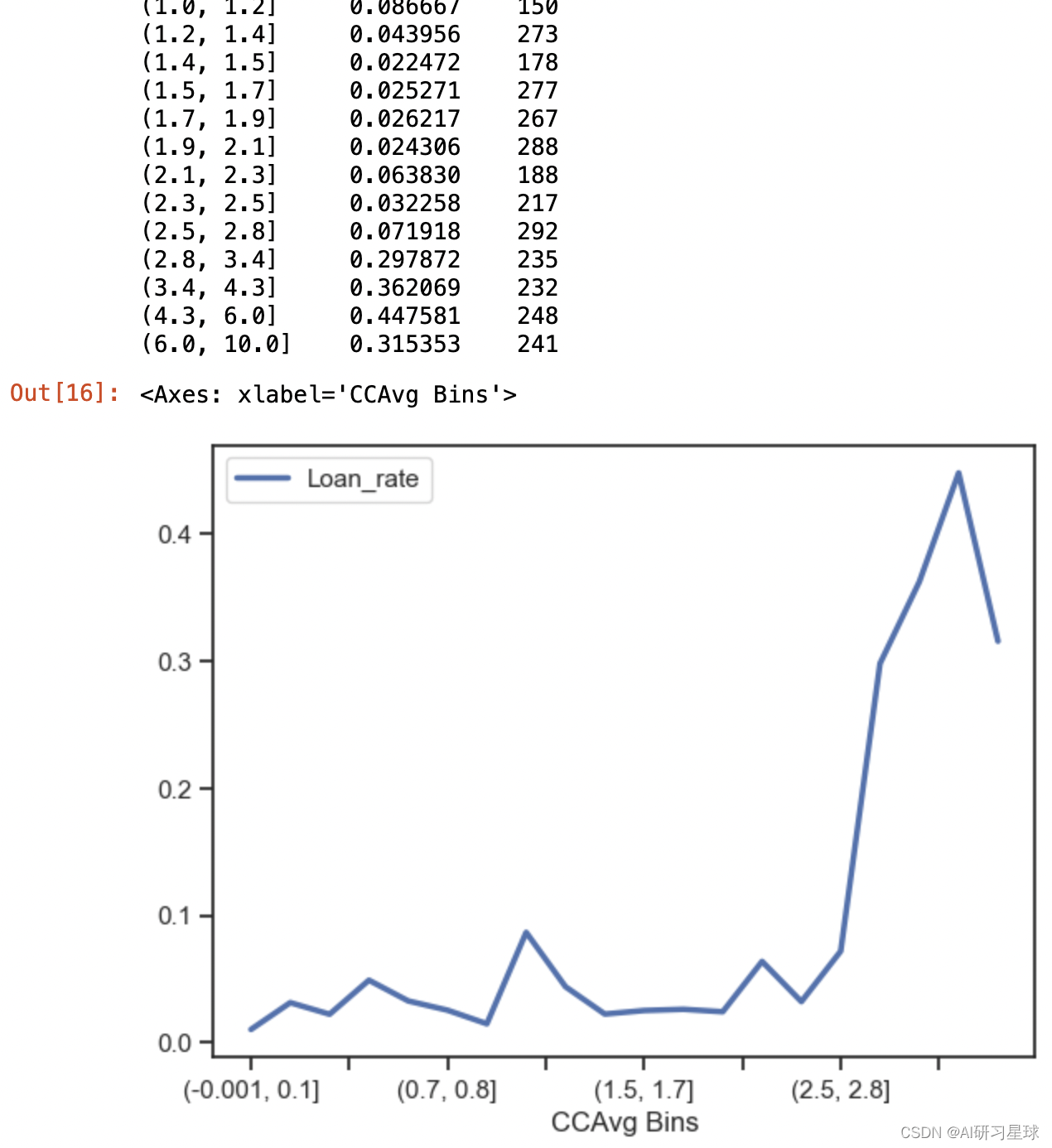
结论:
当信用卡还款额大于2.8K时,申请贷款会显著增加,普遍在30%的成功率
建议:
可以重点关注信用卡还款额在2.8K以上的客户中,成功率会更高。
2.3.3 房屋抵押值与贷款之间的关系
print(df.groupby('Personal Loan')['Mortgage'].agg([np.mean,'count']))
sns.boxenplot(x='Personal Loan',y='Mortgage',data=df,width=0.6)

同样的, 我们将细分哪个分段的房屋抵押情况所对应的贷款意愿情况。
df['Mortgage Bins'] = pd.cut(df.Mortgage,10)
print(df.groupby('Mortgage Bins')['Personal Loan'].agg([np.mean,'count']))
df.groupby('Mortgage Bins')['Personal Loan'].agg({'Loan rate':np.mean}).plot()
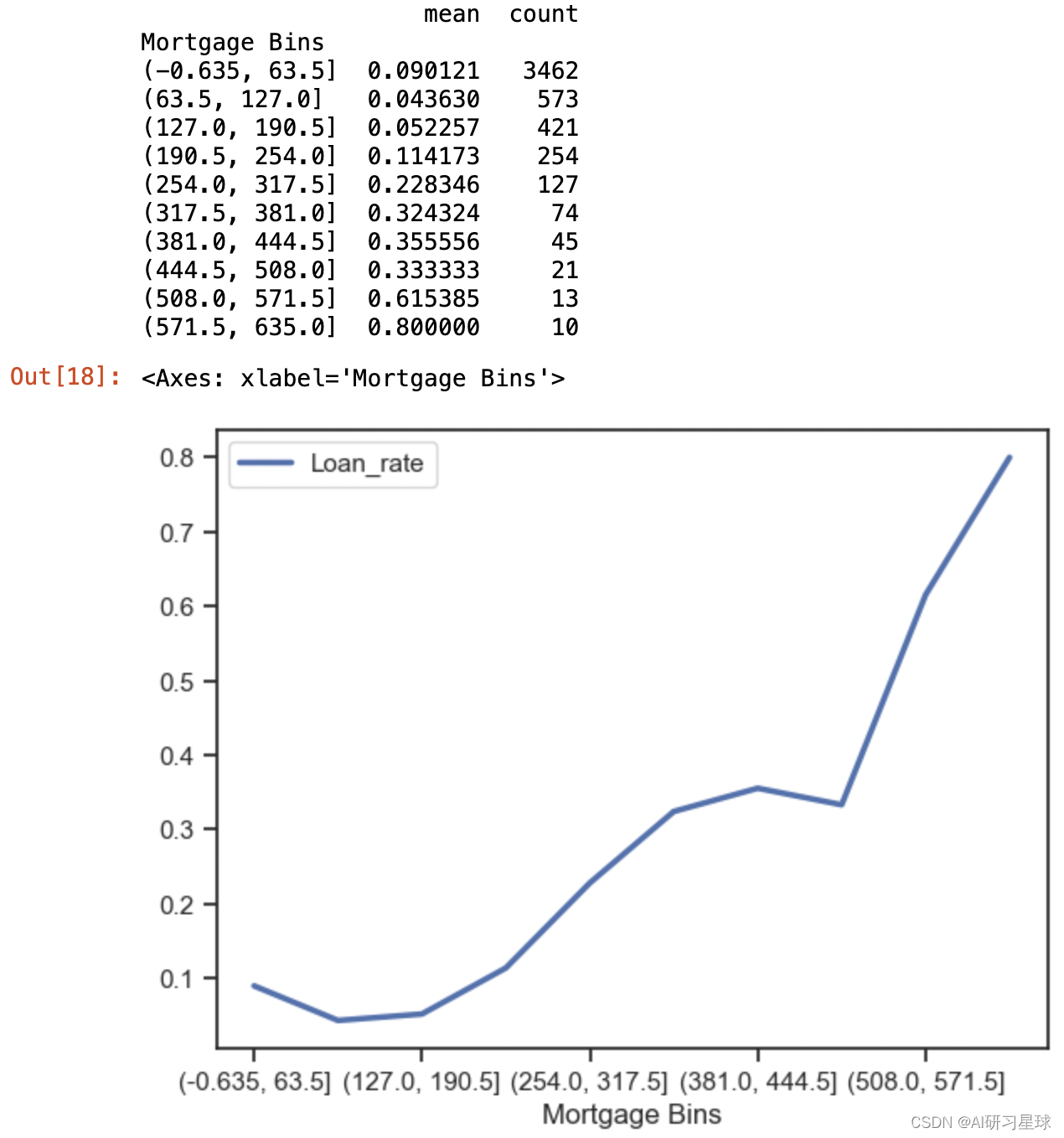
结论:
当房屋抵押额大于254000美元时,申请贷款率会显著增加,且房屋抵押额越高,申请贷款率越高
建议:
可以房屋抵押额大于254000美元的客户中,成功率会更高
3. 结论
- 开通了银行存单账户的客户是贷款营销的理想目标
- 教育水平越高,愿意接受贷款的意愿会更强烈
- 家庭人数在3到4或以上的客户人群更容易接受贷款
- 高收入人群比低收入人群更容易接受贷款,且8000美元到224000美元的年收入的人群,贷款意愿最高
- 信用卡还款额在2.8K以上的客户中,贷款的成功率会较高
- 房屋抵押额大于254000美元的客户更容易接受本次贷款营销
关注公众号:『AI学习星球』
回复:信贷业务数据 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我
这篇关于数据分析-19-Thera Bank信贷业务数据(包含数据代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






