本文主要是介绍HIVE udf、udaf、udtf函数定义与用法(最全!!!!!),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、定义
1、hive udf、udaf、udtf函数定义与用法
(1)UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数,字符串函数)
(2)UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产生一个输出数据行。(count,max)
(3)UDTF(表格生成函数 User-Defined Table Functions):接收一行输入,输出(explode)
总结:
UDF:返回对应值,一对一
UDAF:返回聚类值,多对一
UDTF:返回拆分值,一对多
参考链接:
- https://help.aliyun.com/document_detail/73359.html?spm=a2c4g.11186623.2.13.2b8a2cd5LReBVx#section-ipk-thf-xdb
- http://www.singlex.net/3442.html?kozafo=i5er4
二、在odps的实际应用(以python为例)
1、Odps写udf和调用实例:
参考链接:https://blog.csdn.net/Andy_shenzl/article/details/106328896
第一步:使用python代码创建udf
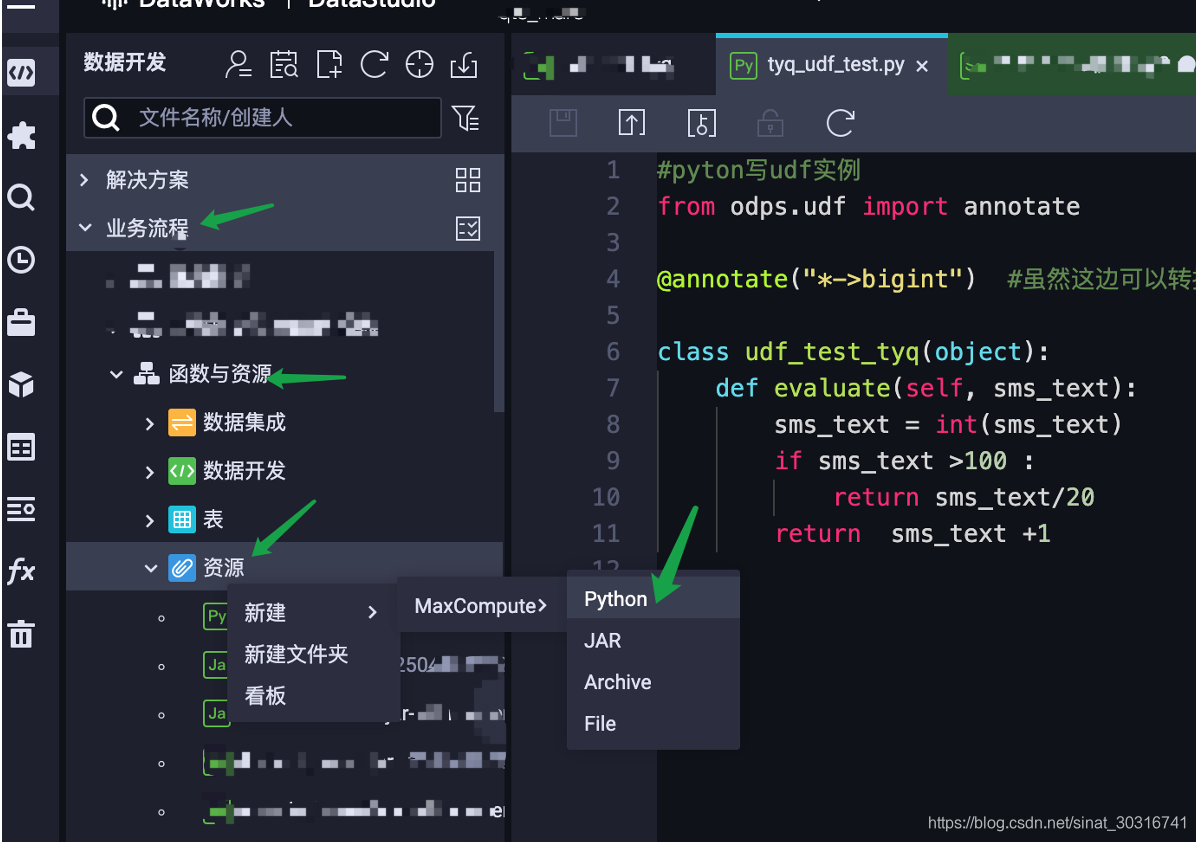
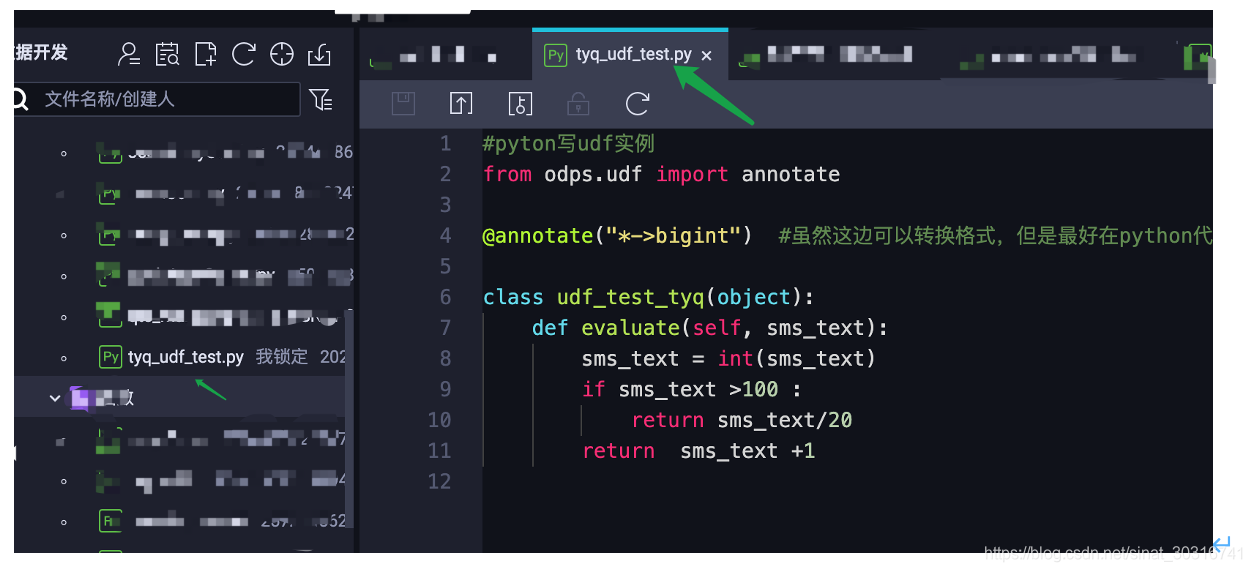
具体代码:
#pyton写udf实例
from odps.udf import annotate@annotate("*->bigint") #虽然这边可以转换格式,但是最好在python代码里还是再次转化下class udf_test_tyq(object):def evaluate(self, sms_text):sms_text = int(sms_text)if sms_text >100 :return sms_text/20return sms_text +1
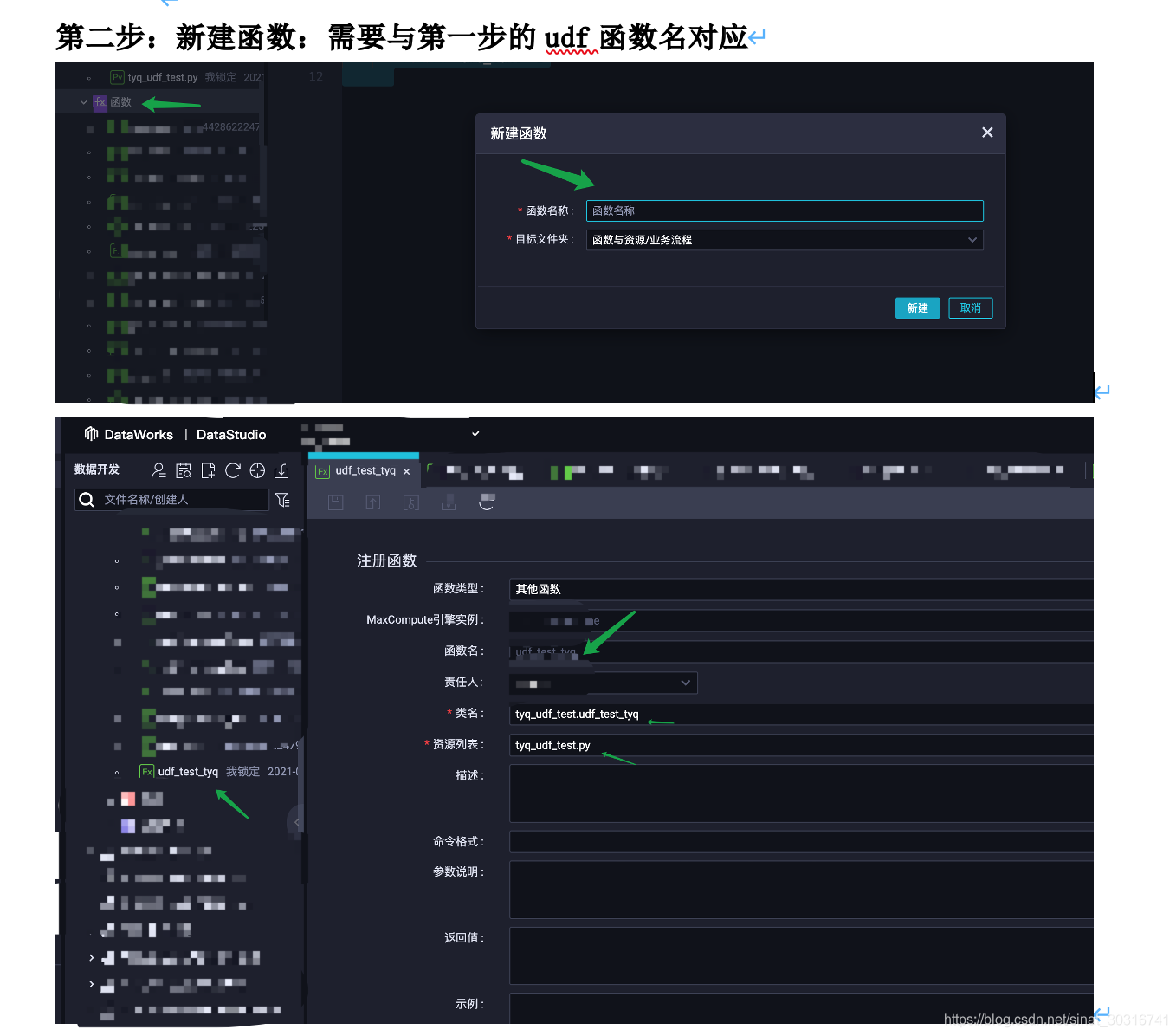
第二步:新建函数:需要与第一步的udf函数名对应
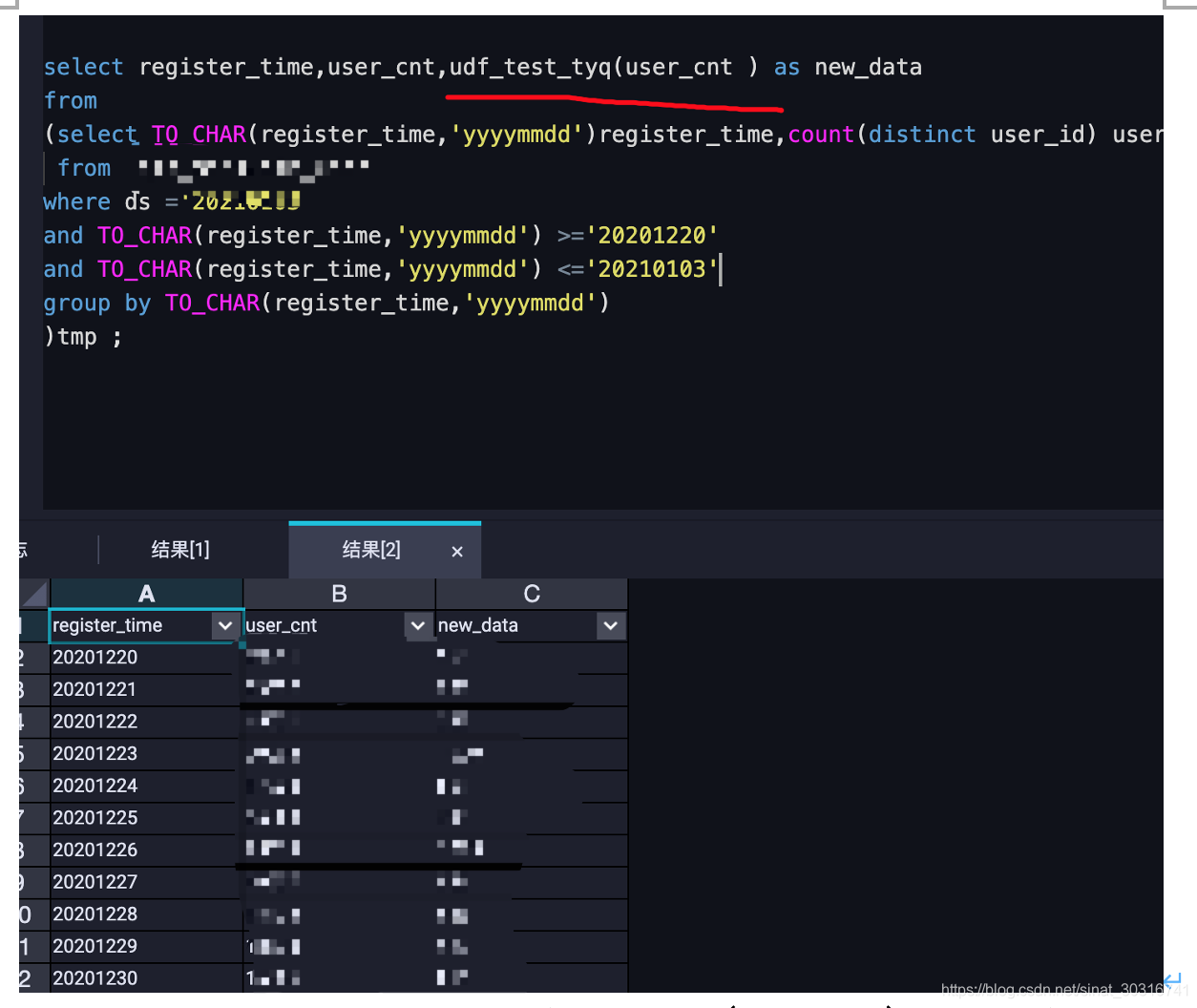
第三步:调用udf
注意:需要在同一空间调用
2、Odps写udaf和调用实例
生成顺序和方法与udf一致,只有生成代码不一致。
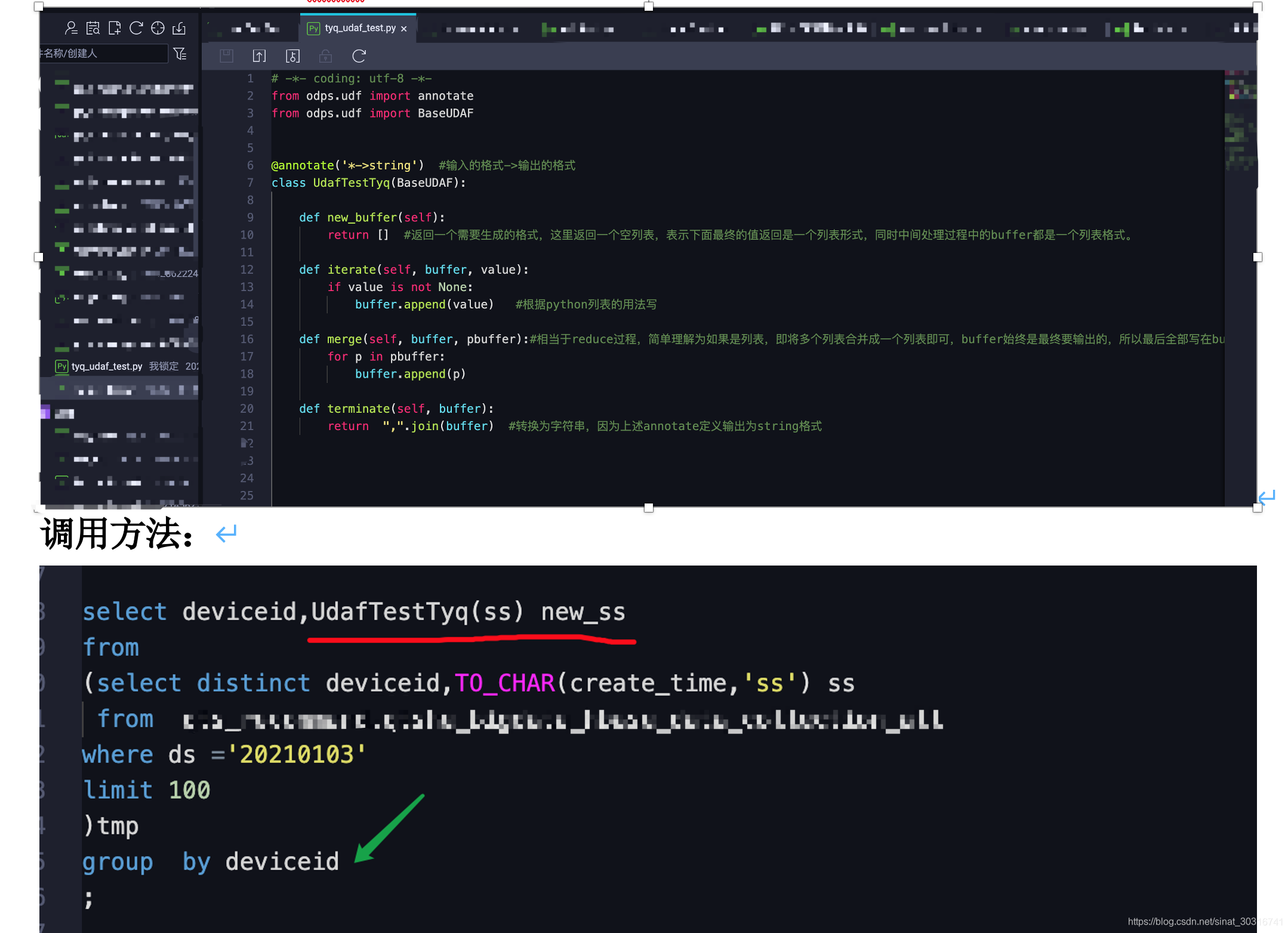
结果:
# -*- coding: utf-8 -*-
from odps.udf import annotate
from odps.udf import BaseUDAF@annotate('*->string') #输入的格式->输出的格式
class UdafTestTyq(BaseUDAF):def new_buffer(self):return [] #返回一个需要生成的格式,这里返回一个空列表,表示下面最终的值返回是一个列表形式,同时中间处理过程中的buffer都是一个列表格式。def iterate(self, buffer, value):if value is not None:buffer.append(value) #根据python列表的用法写def merge(self, buffer, pbuffer):#相当于reduce过程,简单理解为如果是列表,即将多个列表合并成一个列表即可,buffer始终是最终要输出的,所以最后全部写在buffer中,合并的用法只要正常根据python列表合并的方法即可for p in pbuffer:buffer.append(p)def terminate(self, buffer):return ",".join(buffer) #转换为字符串,因为上述annotate定义输出为string格式#---以下为列表中放字典的例子
#import json
#class UdafTestTyq(BaseUDAF):#def new_buffer(self):#return []#def iterate(self, buffer, value):#if value is not None:#buffer.append(json.loads(value))#def merge(self, buffer, pbuffer):#for p in pbuffer:#buffer.append(p)#def terminate(self, buffer):#return json.dumps(buffer ,ensure_ascii=False)#---以下为生成字典的例子
#class JsonUdaf(BaseUDAF):#def new_buffer(self):#return {}#def iterate(self, buffer, key, value):#if key is not None:#buffer[key] = value#def merge(self, buffer, pbuffer):#buffer.update(pbuffer)#def terminate(self, buffer):#return json.dumps(buffer ,ensure_ascii=False)
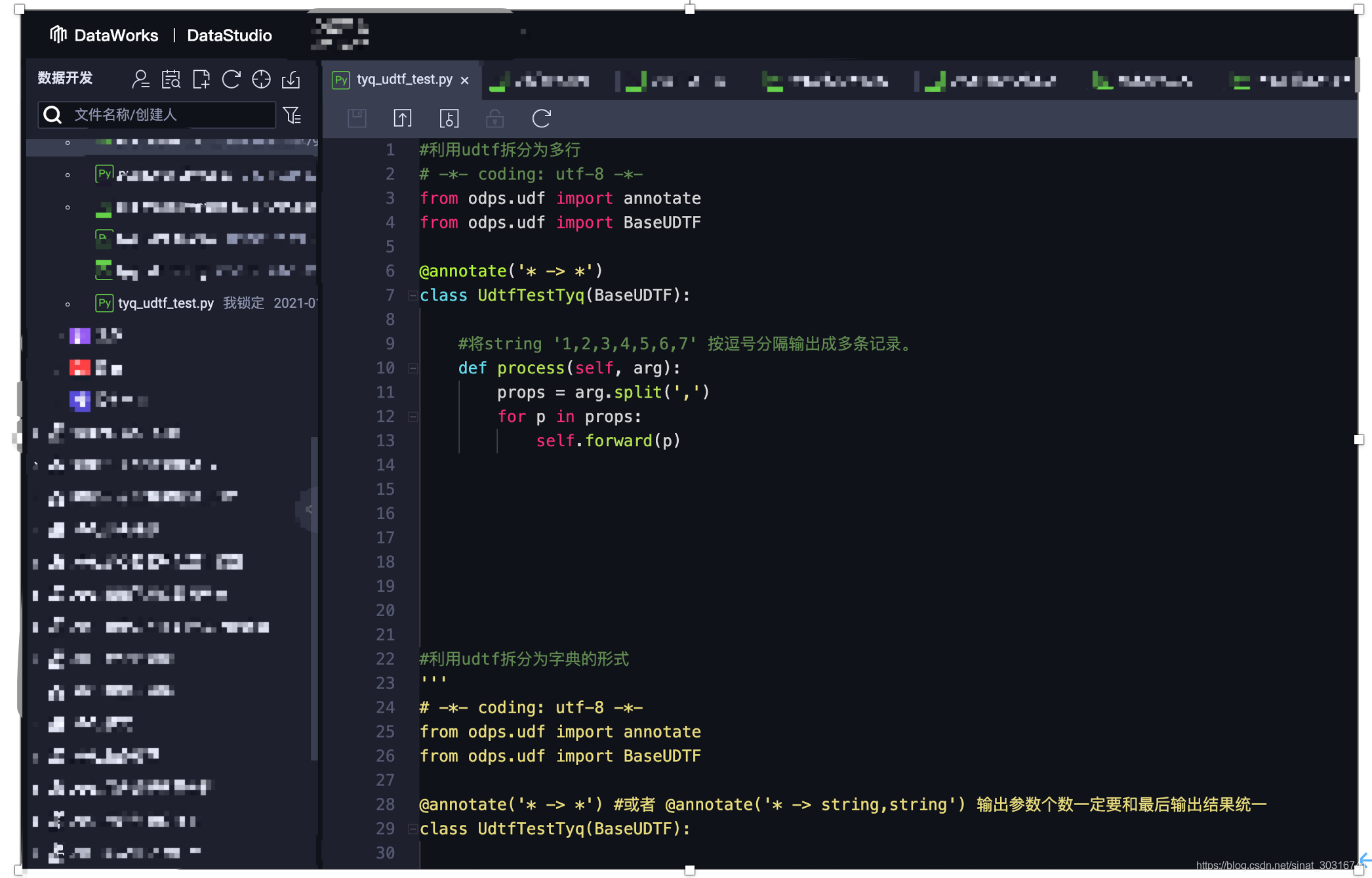
3、Odps写udtf和调用实例
生成顺序和方法与udf一致,只有生成代码不一致。
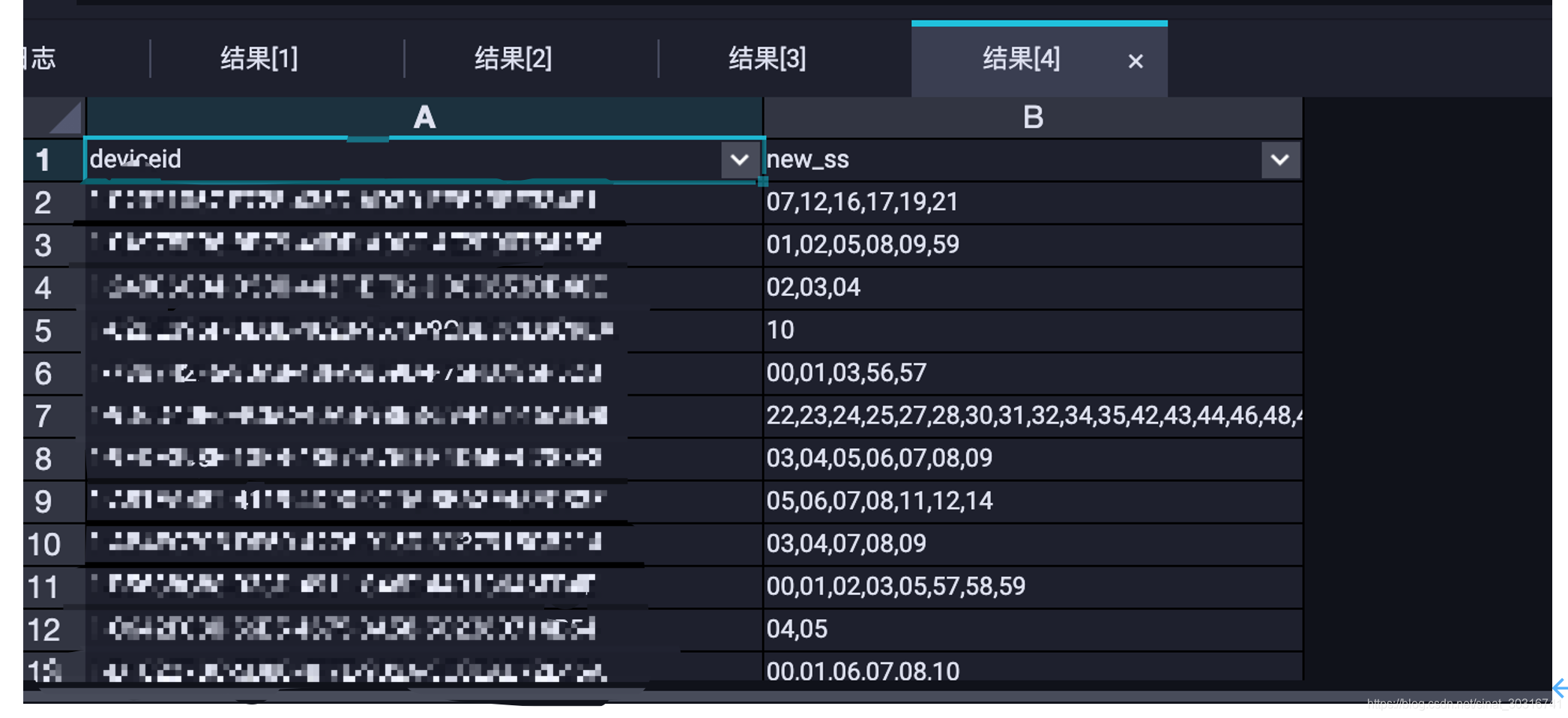
调用方法:
注意!!udtf的调用方法和其他两个不太一样。
UDTF有两种使用方法,一种直接放到select后面,一种和lateral view一起使用。(UDTF不可以添加其他字段使用,不可以嵌套调用,不可以和group by/cluster by/distribute by/sort by一起使用)
(1)直接放在select 后面实例:
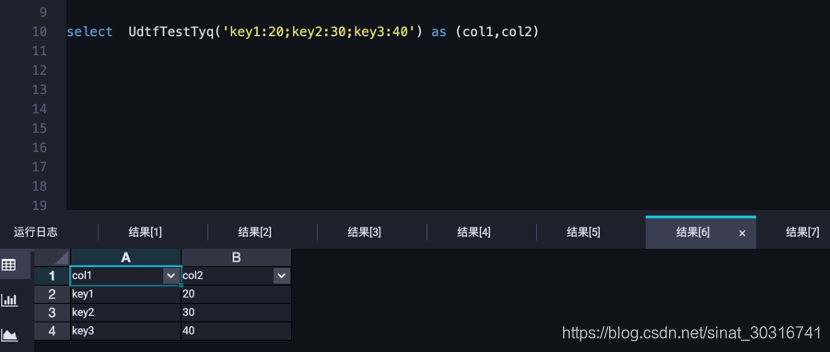
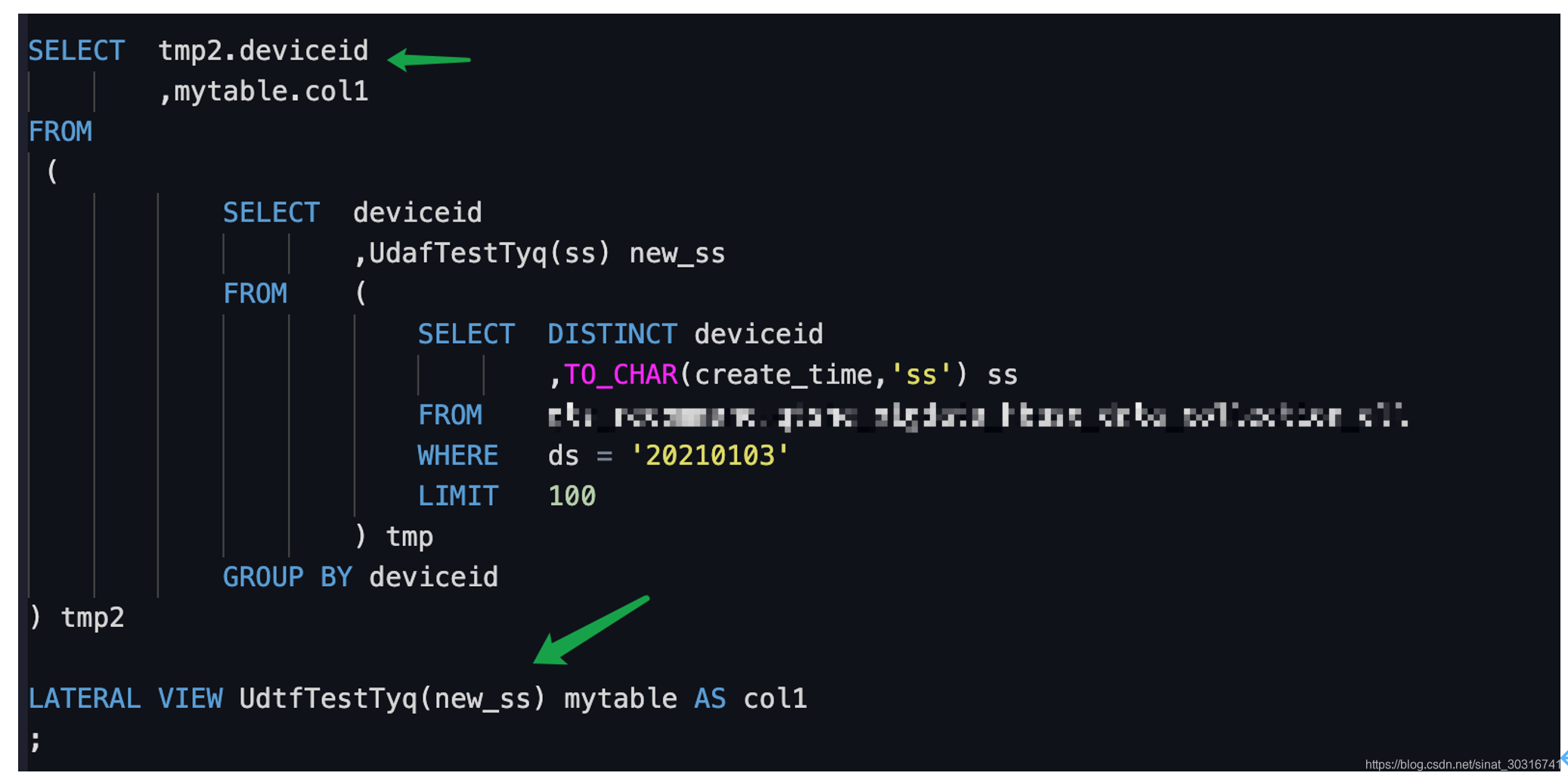
(2)和lateral view一起使用实例:
用lateral view 可以带上其他的字段,更符合实际应用场景。
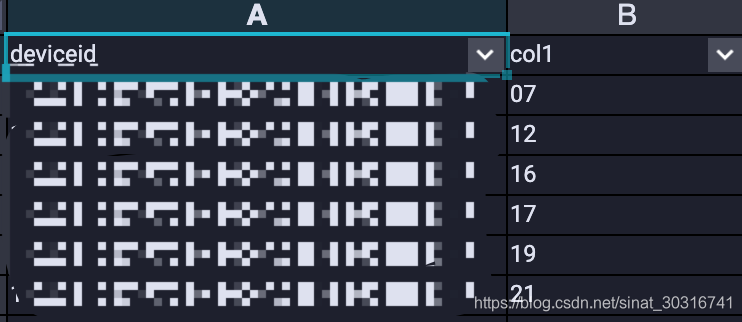
结果:截图为同一个deviceid
这篇关于HIVE udf、udaf、udtf函数定义与用法(最全!!!!!)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






