udf专题

【硬刚Hive】Hive面试题(5)UDF,UDTF(二)UDTF
1.udtf介绍及编写 1.1.介绍 HIVE中udtf可以将一行转成一行多列,也可以将一行转成多行多列,使用频率较高。本篇文章通过实际案例剖析udtf的编写及使用方法和原理。 测试数据 drop table if exists test;create table test(ind int,col string,col1 string) ;insert into test values

【硬刚Hive】Hive面试题(4)UDF,UDTF(一)UDF
1 UDF的定义 UDF(User-Defined Functions)即是用户定义的hive函数。hive自带的函数并不能完全满足业务需求,这时就需要我们自定义函数了 2 UDF的分类 UDF:one to one,进来一个出去一个,row mapping。是row级别操作,如:upper、substr函数UDAF:many to one,进来多个出去一个,row mapping。是

MySQL之UDF提权复现
什么是UDF: UDF(Userfined function)用户自定义函数,是MySQL的一个扩展接口,用户通过自定义函数可以实现在 MySQL 中无法方便实现的功能,其添加的新函数都可以在 SQL 语句中调用。 提权条件: 知道MySQL用户名和密码,可以登录MySQL有写入文件权限,即 secure_file_priv 的值为空 注意:使用 UDF 提权是在没有获取到 webshel

pyflink中UDTF和UDF的区别
UDTF(User Defined Table-Valued Functions)和UDF(User Defined Functions)在Flink和其他数据处理系统中有着明显的区别,主要体现在以下几个方面: 输出类型: UDF: UDF是用户定义的标量函数。它接收一个或多个标量值作为输入,并返回一个标量值作为输出。 UDTF: UDTF是用户定义的表值函数。它接收一个或多个标量值作为输入,

spark udf传入复杂结构参数
笔者在使用LSH 获取相似文本时,遇到返回的Dataframe的结果比较复杂,如下: 现在想使用UDF函数处理datasetA和datasetB的内容,但是由于数据结构复杂,无法直接写参数,所以需要使用Row,代码如下: val getIdFun = udf((input:Row)=> {input(0).toString.toInt;});并且需要注意,在udf函数中,不

Hadoop详解(七)——Hive的原理和安装配置和UDF,flume的安装和配置以及简单使用,flume+hive+Hadoop进行日志处理
hive简介 什么是hive? ① hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转换加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive定义了简单的类似于SQL的查询语言称为QL,它允许熟悉SQL的用户查询数据。同时这种语言也允许熟悉MapReduce的开发者进行开发自定义的mapper和reducer来

flink udf 介绍
ScalarFunction:标量函数是实现将0,1,或者多个标量值转化为一个新值TableFunction:一个输入多个行或者多个列AggregateFunction:多个输入一个输出package org.fuwushe.sql;import com.alibaba.fastjson.JSONObject;import org.apache.flink.api.common.function
hive添加永久udf方法
添加临时方法 先把jar添加进hive add jar my_jar.jar; 添加临时方法 create temporary function my_lower as 'com.example.hive.udf.Lower'; 删除临时方法 DROP FUNCTION [IF EXISTS] my_lower; 添加永久方法 hive版本0.13版及之后可以添加永久方法 c
hive-1.1-CDH永久注册UDF
第1种、创建临时函数。如在hive CLI执行下面命令 hive> add jar ipudf.jar; hive> create temporary function iptocc as 'com.wct.hive.udf.IptoccUDF'; hive> select iptocc(t.col1) from t limit 10; hive> drop tem
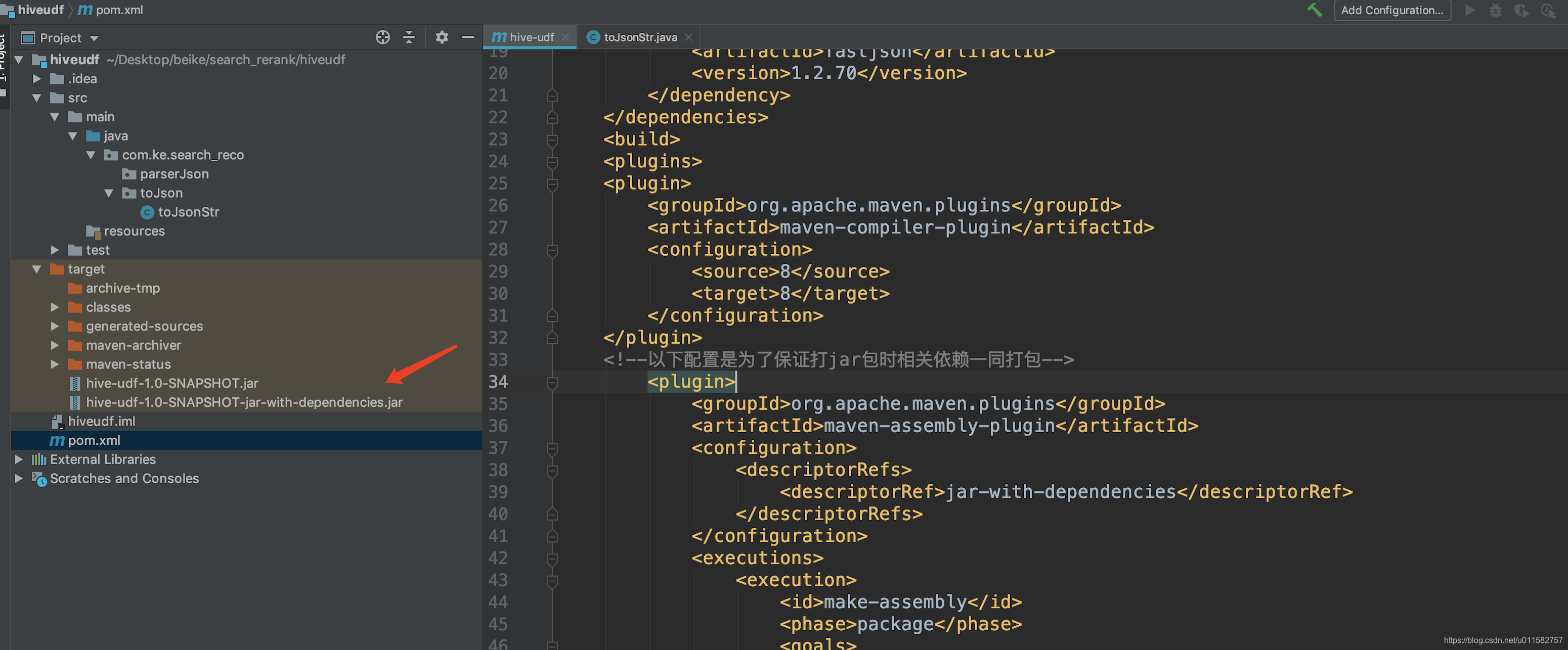
MySQL提权之UDF提权
1、前言 最近遇到udf提权,几经周折终于搞懂了。感觉挺有意思的,渗透思路一下子就被打开了。 2、什么是udf提权 udf 全称为'user defined function',意思是'用户自定义函数'。用户可以对数据库所使用的函数进行一个扩展(windows利用dll文件,linux利用so文件),那么我们就可以利用这个特点,往MySQL里面添加一个可以执行系统命令的函数即可。 3、提权
【Maxcompute】数据封装json、根据经纬度计算距离、根据证件号提取年龄段信息、判断是否在外包多边形内udf、udtf函数
1.梳理、总结经纬度处理在Maxcompute平台上的实战应用,如模型结果等封装json格式、根据经纬度计算距离udf、根据证件号提取年龄段信息、判断是否在外包多边形内udf、udtf、函数注册与使用。 2.欢迎批评指正,跪谢一键三连! 文章目录 1.参考代码1.1 模型结果等封装`json`格式`udf`函数1.2 根据经纬度计算距离`udf`函数1.3 根据证件号提取年龄段信息`
【Maxcompute】解析身份证、计算年龄、查看python版本、字段聚合、手机号校验udf函数
1.梳理、总结经纬度处理在Maxcompute平台上的实战应用,如通过Python实现解析身份证、计算年龄、查看python版本、字段聚合、手机号校验等UDF函数注册与使用。 2.欢迎批评指正,跪谢一键三连! 文章目录 1.参考代码样例1.1 提取、解析身份证`udf`函数1.2 查看`Maxcompute`底层`Python`版本`udf`函数1.3 根据证件号码计算年龄`udf`
hive自定义udf实现md5功能
Hive自定义UDF实现md5算法 Hive发展至今,自身已经非常成熟了,但是为了灵活性,还是提供了各种各样的 插件的方式,只有你想不到的,没有做不到的,主流的开源框架都有类似的机制,包括Hadoop,Solr,Hbase,ElasticSearch,这也是面向抽象编程的好处,非常容易扩展。 最近在使用hive1.2.0的版本,因为要给有一列的数据生成md5签名,便于查重数据使用,看了

Hive的中函数,用户自定义函数(UDF)
Hive中的函数 Hive为了方便用户的操作,为我们提供了许多的内置函数, $hive>tab //使用键盘的Tab键可以查看 也通过以下命令可以只查看函数 $hive>show functions; //函数的使用方法如下: $hive>select array(1,2,3) ;
Hive写一个时间转换器的自定义函数(UDF)和创建hive自定义函数的两种方式
在前面一篇文章的日志表中,时间的格式的是这样的"31/Aug/2015:00:04:37 +0800";这样并不友好,为了好看点,我们自定义一个时间格式化的udf函数,hive应该也提供时间转换的函数。 自定义函数 代码 自定义函数还是继承UDF类 package com.madman.hive.function;import java.text.SimpleDateFormat;i
hive之UDF整理
Hive UDF整理 (可以直接在mysql上测试,hive中没有伪表,需要手动创建,反应慢) 字符串函数 字符串长度函数:length 语法: length(string A) 返回值: int 说明:返回字符串A的长度 举例: hive> select length(‘abcedfg’) from dual; 7 字符串反转函数:reverse 语法: reverse(s
Hive UDF使用
UDF:用户自定义函数,在java中写函数,打成jar,在hive中添加jar,在hql中使用该函数, UDF函数开发 标准函数(UDF):以一行数据中的一列或者多列数据作为参数然后返回解雇欧式一个值的函数,同样也可以返回一个复杂的对象,例如array,map,struct。 聚合函数(UDAF):接受从零行到多行的零个到多个列,然后返回单一值。例如sum函数。 生成函数(UDTF):接受
【Hive】自定义函数从编写到应用的整个流程(以UDF为例)
1. 编写UDF程序 以Java为例,编写一个字符串反转的函数(工程依赖部分略): package com.example;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.hive.ql.exec.Description;import org.apache.hadoop.hive.ql.udf.UDFTy
linux环境下的MySQL UDF提权
linux环境下的MySQL UDF提权 ##1. 背景介绍 ###UDF UDF(user defined function)用户自定义函数,是MySQL的一个扩展接口,称为用户自定义函数,是用来拓展MySQL的技术手段,用户通过自定义函数来实现在MySQL中无法实现的功能。文件后缀为.dll或.so,常用c语言编写。拿到一个WebShell之后,在利用操作系统本身存在的漏洞提权的时候发现

Hive中实现group concat功能(不用udf)
Sql代码 hive> desc t; OK id string str string Time taken: 0.249 seconds hive> select * from t; OK 1 A 1 B 2 C 2 D Time taken: 0.209 seconds hive>
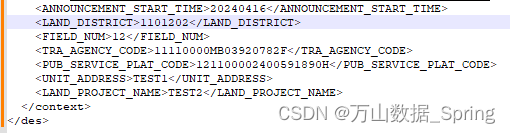
ClickHouse用UDF解析XML字符串和XML文件
一.如果是读取xml文件的时候,文件入库需要使用文件读取UDF 创建了1个测试文件 wsdFileRead(): 直接读取文件内容 SELECT wsdFileRead('/home/temp/wsd_test.xml')Query id: 09b6e5fe-7169-43f7-b001-90e2eeabb8da┌─wsdFileRead('/home/temp/wsd_test.xml

Hive 之 UDF 运用(包会的)
文章目录 UDF 是什么?reflect静态方法调用实例方法调用 自定义 UDF(GenericUDF)1.创建项目2.创建类继承 UDF3.数据类型判断4.编写业务逻辑5.定义函数描述信息6.打包与上传7.注册 UDF 函数并测试返回复杂的数据类型 UDF 是什么? Hive 中的 UDF 其实就是用户自定义函数,允许用户注册使用自定义的逻辑对数据进行处理,丰富了Hive

Spark SQL用UDF实现按列特征重分区 repatition
转:https://cloud.tencent.com/developer/article/1371921 解决问题之前,要先了解一下Spark 原理,要想进行相同数据归类到相同分区,肯定要有产生shuffle步骤。 比如,F到G这个shuffle过程,那么如何决定数据到哪个分区去的呢?这就有一个分区器的概念,默认是hash分区器。 假如,我们能在分区这个地方着手的话肯定能实现我们的目标
Spark重温笔记(五):SparkSQL进阶操作——迭代计算,开窗函数,结合多种数据源,UDF自定义函数
Spark学习笔记 前言:今天是温习 Spark 的第 5 天啦!主要梳理了 SparkSQL 的进阶操作,包括spark结合hive做离线数仓,以及结合mysql,dataframe,以及最为核心的迭代计算逻辑-udf函数等,以及演示了几个企业级操作案例,希望对大家有帮助! Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分