udaf专题

hive udaf 用maven打包执行create temporary function 时报错
用maven打包写好的jar,在放到hive中作临时函数时报错。 错误信息如下: hive> create temporary function maxvalue as "com.leaf.data.Maximum";java.lang.SecurityException: Invalid signature file digest for Manifest main att

hive中udf、udaf、udtf开发
Hive进行UDF开发十分简单,此处所说UDF为Temporary的function,所以需要hive版本在0.4.0以上才可以。 一、背景:Hive是基于Hadoop中的MapReduce,提供HQL查询的数据仓库。Hive是一个很开放的系统,很多内容都支持用户定制,包括: a)文件格式:Text File,Sequence File b)内存中的数据格式: Java Integer/

第一个Hive UDAF函数
hive提供了org.apache.hadoop.hive.ql.exec.UDF类和org.apache.hadoop.hive.ql.exec.UDAF类,我们可以通过继承这个类来实现不同功能的函数,在脚本中很方便的调用它。 第一步,在eclipse中创建一个java项目,命名为ConnectGroup 第二步,导入UDAF需要的jar包,hive-exec-???.jar(或者用f

104.Spark大型电商项目-各区域热门商品统计-开发自定义UDAF聚合函数之group_concat_distinct()
目录 代码 ConcatLongStringUDF.java GroupConcatDistinctUDAF.java AreaTop3ProductSpark.java 本篇文章记录各区域热门商品统计-开发自定义UDAF聚合函数之group_concat_distinct()。 代码 spark.product ConcatLongStringUDF.java packa
Doris学习笔记-Java自定义UDAF
项目最近需要做一些数据统计方面的东西,发现数据字段都是很长一串数字的字符串,Doris自带的函数无法对其进行相应的运算操作,需要扩展实现相关的操作运算。 主要参考官方的文档资料完成相关的自定义扩展。需要注意的是在使用Java代码编写UDAF时,有一些必须实现的函数(标记required)和一个内部类State。 SUM求和运算函数 public class Sum {//Need an i
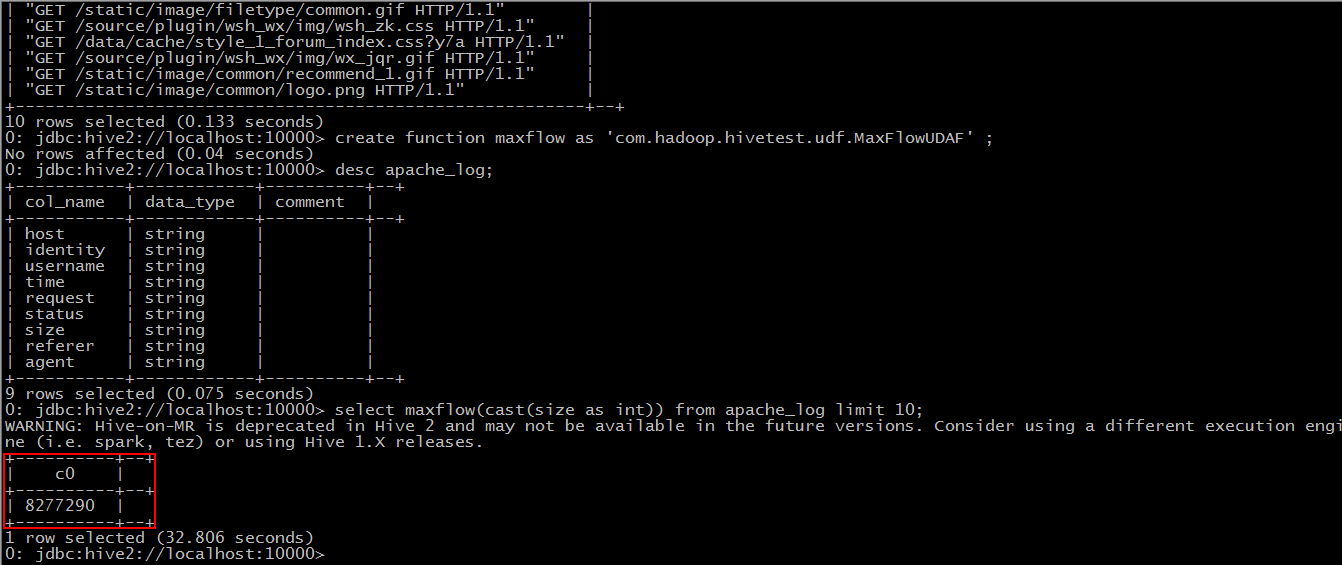
hive中UDF、UDTF、UDAF快速上手
在hive中新建表”apache_log” CREATE TABLE apachelog (host STRING,identity STRING,user STRING,time STRING,request STRING,status STRING,size STRING,referer STRING,agent STRING)ROW FORMAT SERDE 'org.apache.ha
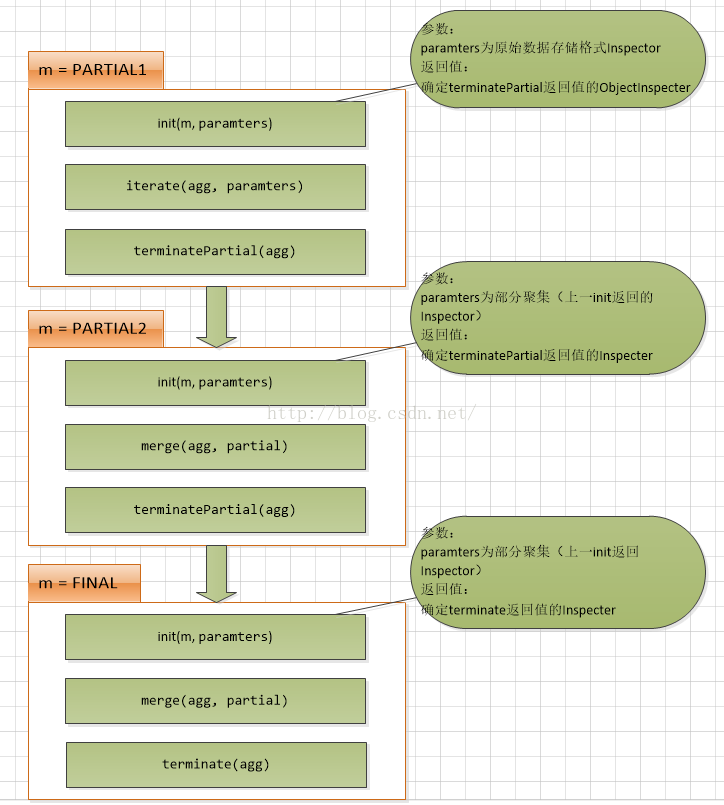
Hive UDAF开发详解
说明 这篇文章是来自 Hadoop Hive UDAF Tutorial - Extending Hive with Aggregation Functions:的不严格翻译,因为翻译的文章示例写得比较通俗易懂,此外,我把自己对于Hive的UDAF理解穿插到文章里面。 udfa是hive中用户自定义的聚集函数,hive内置UDAF函数包括有sum()与count(),UDAF实现有简单与
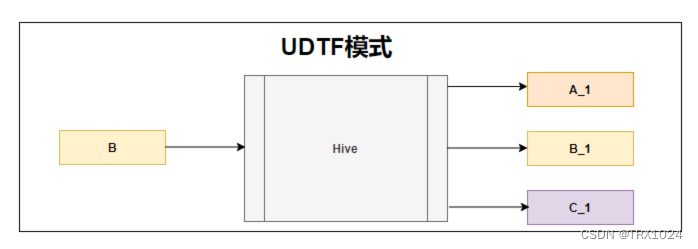
Hive/SparkSQL中UDF/UDTF/UDAF的含义、区别、有哪些函数
Hive官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inTable-GeneratingFunctions(UDTF) 1.UDF(User-Defined Function) 含义 即用户定义函数,UDF用于处理一行数据并返回一个标量值(单个
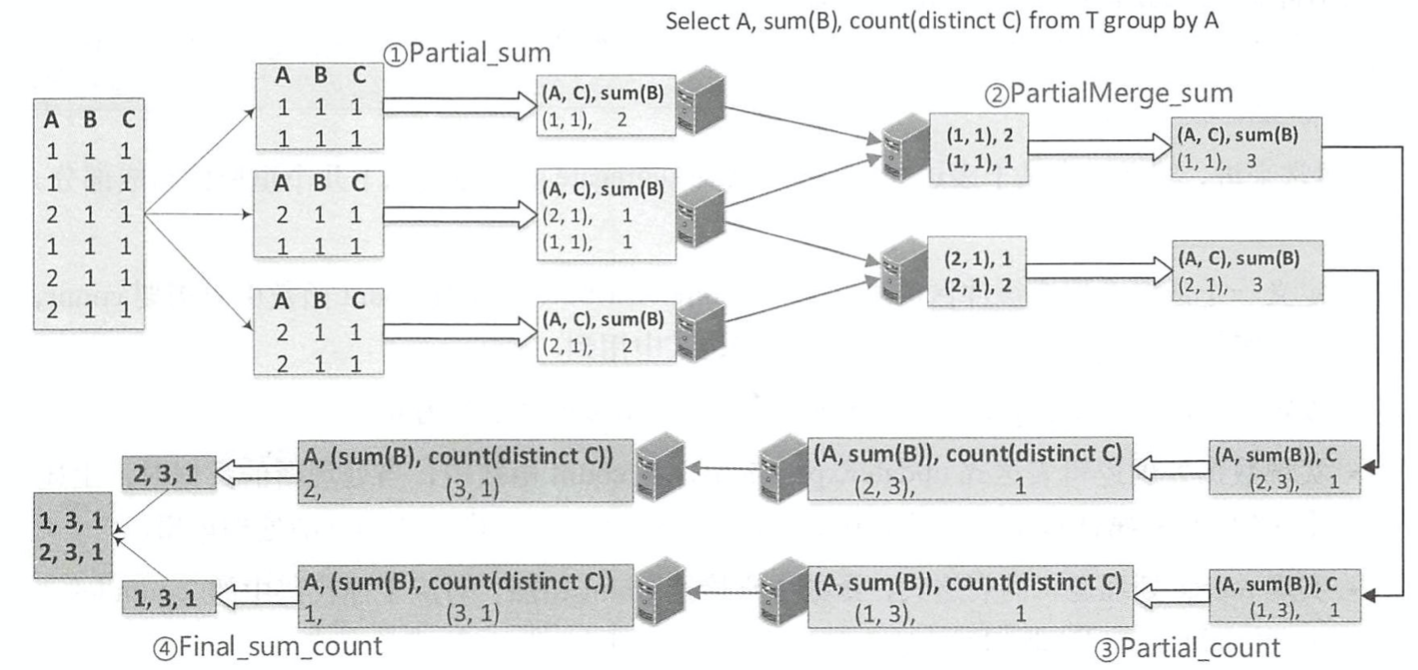
【Spark精讲】一文讲透SparkSQL聚合过程以及UDAF开发
SparkSQL聚合过程 这里的 Partial 方式表示聚合函数的模式,能够支持预先局部聚合,这方面的内容会在下一节详细介绍。 对应实例中的聚合语句,因为 count 函数支持 Partial 方式,因此调用的是 planAggregateWithoutDistinct 方法,生成了图 7.4 中的两个 HashAggregate (聚合执行方式中的一种,后续详细介绍)物理算子树节点,分别进行
HIVE udf、udaf、udtf函数定义与用法(最全!!!!!)
一、定义 1、hive udf、udaf、udtf函数定义与用法 (1)UDF(user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数,字符串函数) (2)UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产生一个输出数据行。(count,max) (3)UDTF(表格生成函

hive 用户自定义函数udf,udaf,udtf
udf:一对一的关系 udtf:一对多的关系 udaf:多对一的关系 使用Java实现步骤 自定义编写UDF函数注意: 1.需要继承org.apache.hadoop.hive.ql.exec.UDF 2.需要实现evaluete函数 编写UDTF函数注意: 1.需要继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF 2.实现
0基础学习PyFlink——用户自定义函数之UDAF
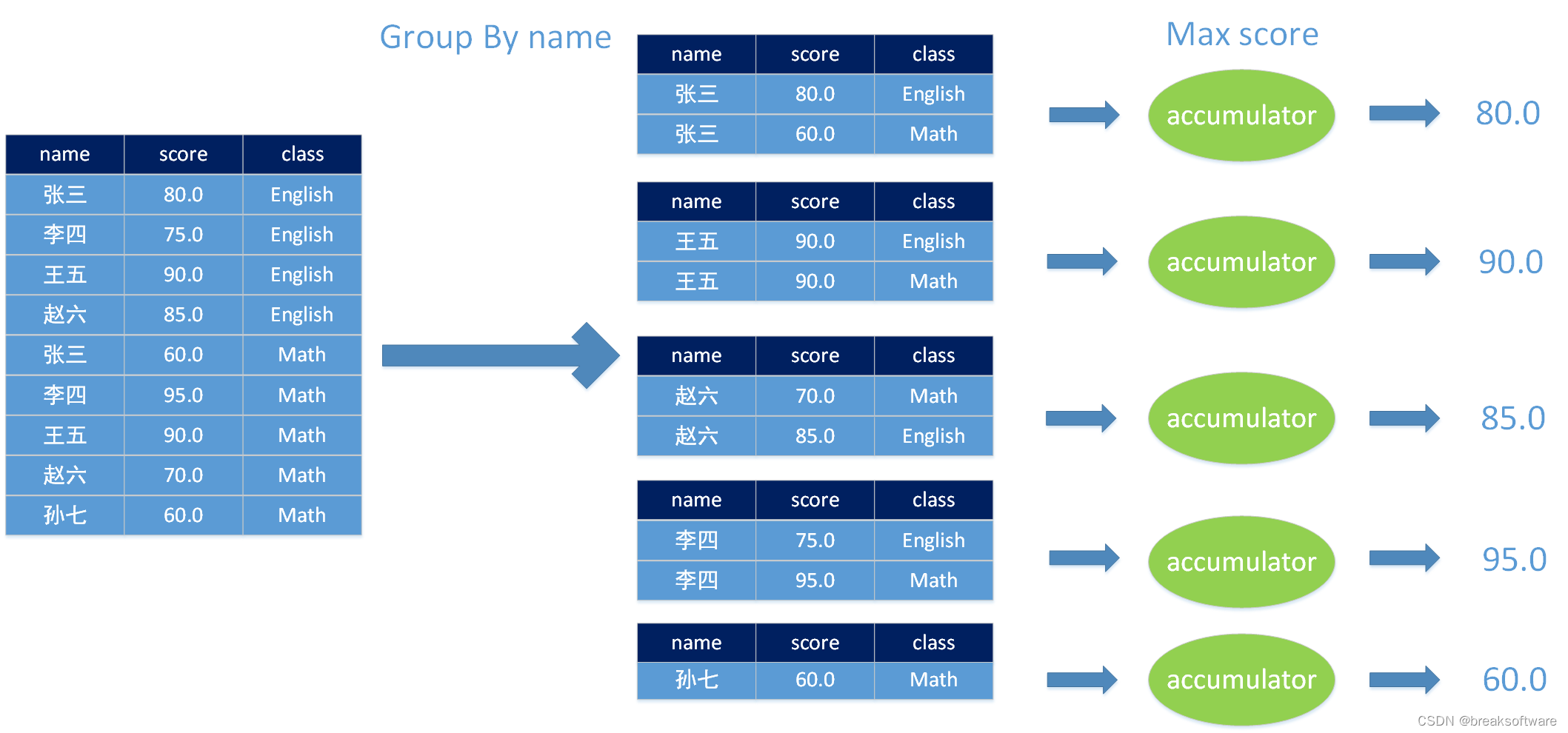
大纲 UDAF入参并非表中一行(Row)的集合计算每个人考了几门课计算每门课有几个人考试计算每个人的平均分计算每课的平均分计算每个人的最高分和最低分 入参是表中一行(Row)的集合计算每个人的最高分、最低分以及所属的课程计算每课的最高分数、最低分数以及所属人 完整代码入参并非表中一行(Row)的集合入参是表中一行(Row)的集合 在前面几篇文章中,我们学习了非聚合类的用户自定义
hive 自定义函数UDF,UDAF
自定义函数 在hive中,有时候一些内置的函数,和普通的查询操作已经满足不了我们要查询的要求,这时候可以自己写一些自定义函数来处理。自定义函数(user defined function =UDF) 由于hive本身是用java语言开发,所以udf必须用java来写才可以。 Hive中有三种UDF 1. 普通udf(UDF) 操作单个数据行,且产生一个数据作为输出。例如(数学函数
SparkSQL的两种UDAF的讲解
Spark的dataframe提供了通用的聚合方法,比如count(),countDistinct(),avg(),max(),min()等等。然而这些函数是针对dataframe设计的,当然sparksql也有类型安全的版本,java和scala语言接口都有,这些就适用于强类型Datasets。本文主要是讲解spark提供的两种聚合函数接口: 1, UserDefinedAggregateFu
UDAF实现一个自定义的求和函数
转自:http://richie-hu.blog.sohu.com/141308974.html Hive进行UDAF开发,相对要比UDF复杂一些,不过也不是很难。 请看一个例子 package org.hrj.hive.udf; import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;import org.apache.hado