本文主要是介绍ELFK日志收集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 第一章:ELK日志收集系统介绍
- 日志收集重要性
- ELK介绍
- EFK介绍
- ELFK介绍
- ES部署
- Kibana部署
- 第二章:Logstach日志收集
- Logstash介绍
- Logstash安装
- Logstash Input输入插件
- Logstash Filter过滤插件
- Logstash Output输出插件
- Input file
- Filter mutate
- split示例
- add_field示例
- remove_field示例
- Filter date
- 第三章:配置Kibana数据展示
- Kibana查看ES索引
- Kibana创建索引模式
- Kibana创建图形
- Kibana的Buckets
- Kibana创建Dashboard
第一章:ELK日志收集系统介绍
日志收集重要性
-
协作困难 :项目在测试和上线阶段,开发人员需要不断的查看日志来分析项目中是否存在问题,运维需要协助开发人员提取这些日志;
-
日志检索困难:生产环境的服务器、和应用会产生大量日志,一旦出现故障,运维人员通过手工方式检索日志,消耗大量时间和精力,难以快速定位问题;
-
报警机制不完善:传统的日志管理方式很难实现实时报警和通知,一旦出现故障,可能错过解决问题的最佳时机;
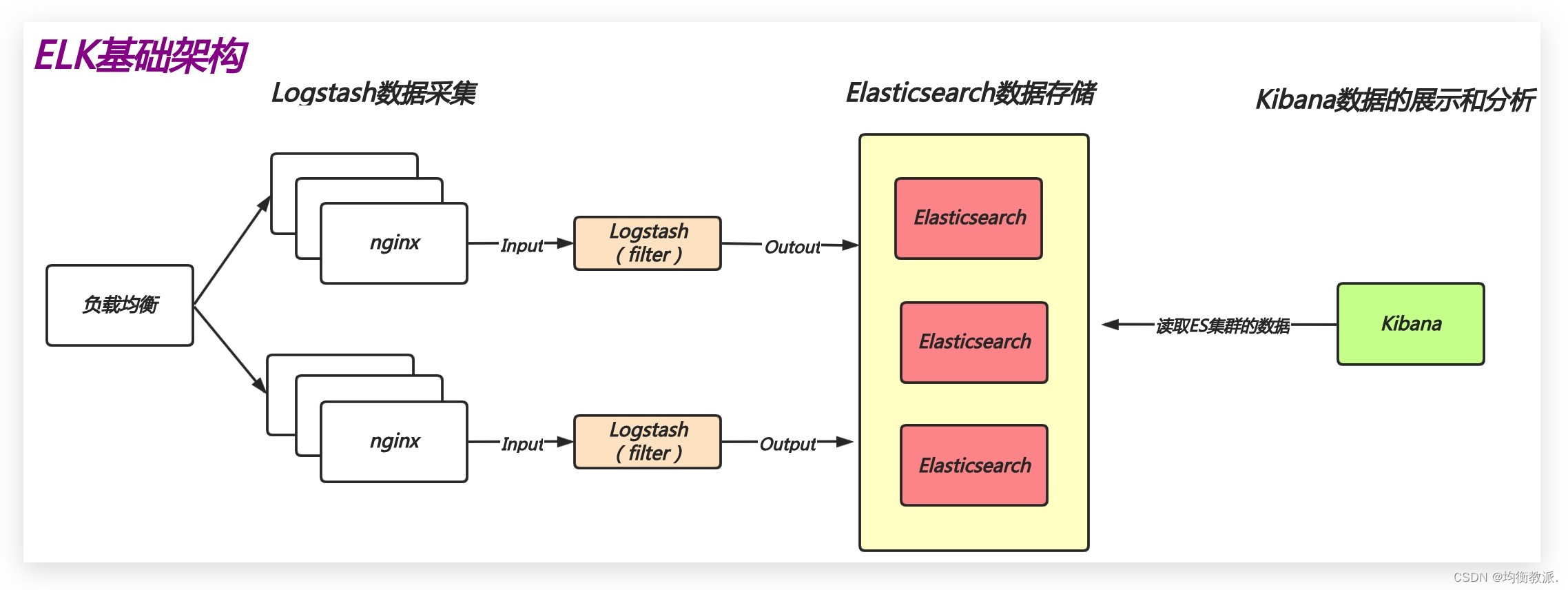
ELK介绍
ELK是一套开源免费、功能强大的日志分析管理系统,可以将系统日志、网站日志、应用日志等各种日志进行收集、过滤、清洗,然后进行集中存放并展示。
ELK不是一个单独的技术,而是由一套日志收集工具组合而成,包括:Elasticsearch、Logstash、Kibana组成。
- Elasticsearch(简称es):是由Java开发的一个非关系型数据库,提供日志的存储和搜索功能;
- Logstash:是一个日志采集工具,提供数据采集、数据清洗、数据过滤等功能;
- Kibana:是一个日志展示工具,提供web界面的数据图形分析、数据展示等功能;
- 官方地址:https://www.elastic.co/cn/
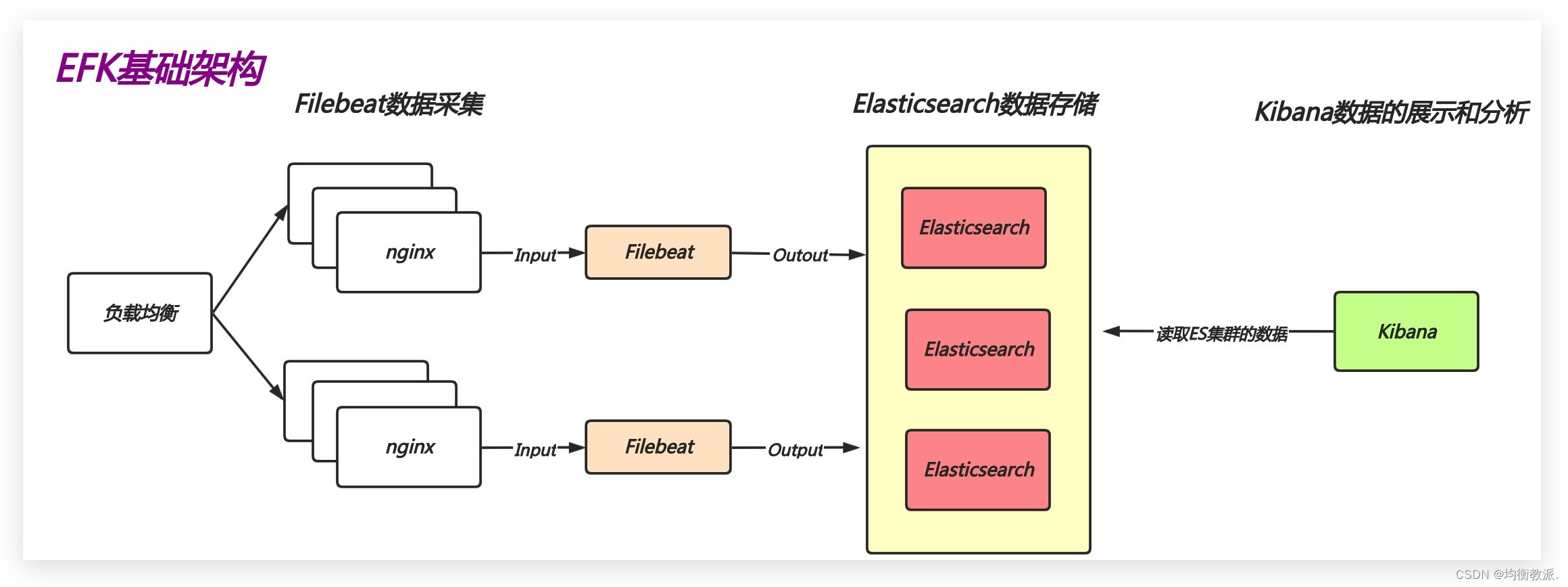
EFK介绍
简单来说就是将Logstash替换成了Filebeat,由于其强大的数据处理功能,Logstash需要较多的计算资源和内存来运行,在收集日志时会消耗系统大量资源,可能会影响到系统中运行的业务。
而替换成Filebeat这种轻量级的日志收集工具后,由于Filebeat基于Go语言开发,本身占用资源少,启动速度快,也能够满足日常的日志收集需求,从而就诞生了EFK结构。
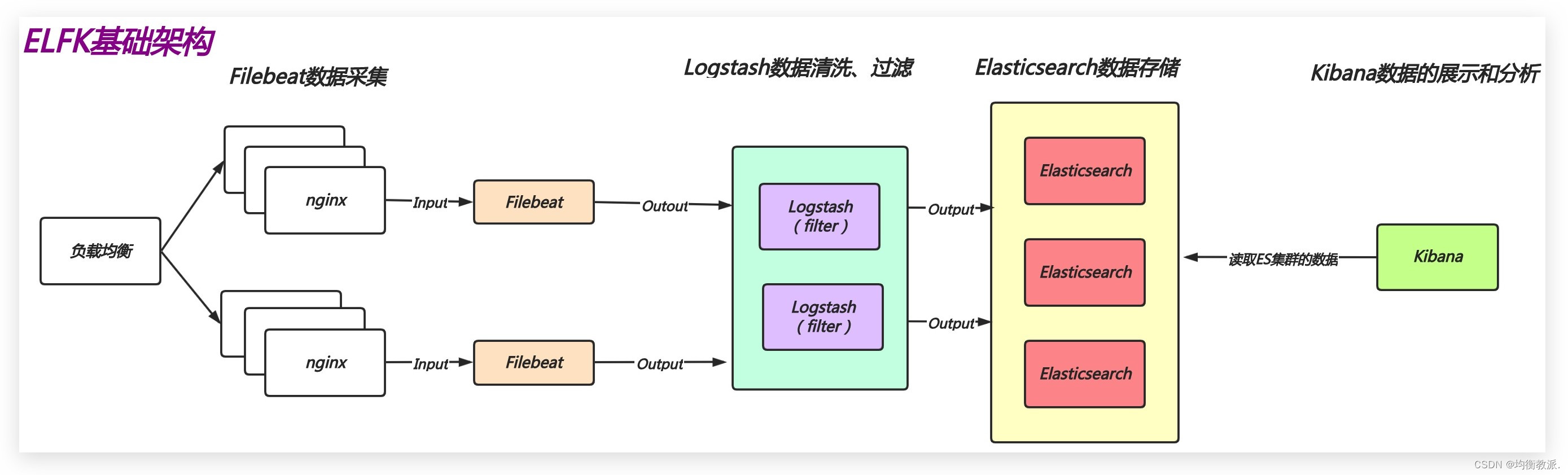
ELFK介绍
Logstash主要用于对数据进行复杂的处理,而Filebeat则专注于轻量级地收集和传输日志。在实际应用中,Logstash与Filebeat结合使用来提供更高效和强大的日志处理和分析功能,从而诞生了ELFK结构。
ES部署
ES集群为了实现高可用,通常至少由三台组成,在一个ES集群中,只能有一个Master节点(通过选举产生),Master节点用于控制整个集群。集群的数据在存储时,Master会将数据同步给其他的Node节点。
| 主机名 | IP地址 | 操作系统 | 硬件环境 |
|---|---|---|---|
| es01 | 192.168.0.91 | CentOS 7 | 2Core/4G Mem/50G disk |
es软件包可以从清华大学下载rpm包:https://mirrors.tuna.tsinghua.edu.cn/elasticstack/yum/elastic-7.x/7.8.1/
由于es7.8版本已经内置Java JDK,无需安装
rpm -ivh elasticsearch-7.8.1-x86_64.rpm
es01修改配置文件
[root@es01 ~]# egrep -v '^#|^$' /etc/elasticsearch/elasticsearch.yml ...#集群名称(名称自定义)
cluster.name: my-es#在集群中的节点名称(主机名称)
node.name: es01#数据存储路径(无需修改)
path.data: /var/lib/elasticsearch#日志存储路径(无需修改)
path.logs: /var/log/elasticsearch#本机IP地址
network.host: 192.168.0.91#http监听的端口号
http.port: 9200#集群主机列表
discovery.seed_hosts: ["192.168.0.91"]#仅第一次启动集群时参与选举的主机列表
cluster.initial_master_nodes: ["192.168.0.91"]
启动es并加入开机自启动
[root@es01 ~]# systemctl start elasticsearch
[root@es01 ~]# systemctl enable elasticsearch[root@es01 ~]# netstat -ntlp | grep java
tcp6 0 0 192.168.0.91:9200 :::* LISTEN 9656/java
tcp6 0 0 192.168.0.91:9300 :::* LISTEN 9656/java
ES端口:9200是对外部提供访问的端口,9300是对集群内部提供访问的端口。
可以使用curl或者浏览器访问IP:9200测试是否可以访问
[root@es01 ~]# curl http://192.168.0.91:9200
{"name" : "es01","cluster_name" : "my-es","cluster_uuid" : "B8BaoXbdSWKGMDt9AVmKyw","version" : {"number" : "7.8.1","build_flavor" : "default","build_type" : "rpm","build_hash" : "b5ca9c58fb664ca8bf9e4057fc229b3396bf3a89","build_date" : "2020-07-21T16:40:44.668009Z","build_snapshot" : false,"lucene_version" : "8.5.1","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}
Kibana部署
Kibana是由HTML和Javascript编写的一个开源的可视化平台,设计出来用于和Elasticsearch一起使用的,用于搜索、查看存放在Elasticsearch索引里的数据,使用各种不同的图表来展示日志中数据。
| 主机名 | IP地址 | 操作系统 | 硬件环境 |
|---|---|---|---|
| kibana | 192.168.0.96 | CentOS7.6 | 2Core/4G Mem/50G disk |
Kibana软件包与ES在同一个仓库中,可以从清华大学下载rpm包:https://mirrors.tuna.tsinghua.edu.cn/elasticstack/yum/elastic-7.x/7.8.1/
[root@kibana-cerebor ~]# rpm -ivh kibana-7.8.1-x86_64.rpm
修改kibana配置文件
[root@kibana-cerebor ~这篇关于ELFK日志收集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







