本文主要是介绍WPF——样式和控件模板、数据绑定与校验转换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
样式和控件模板
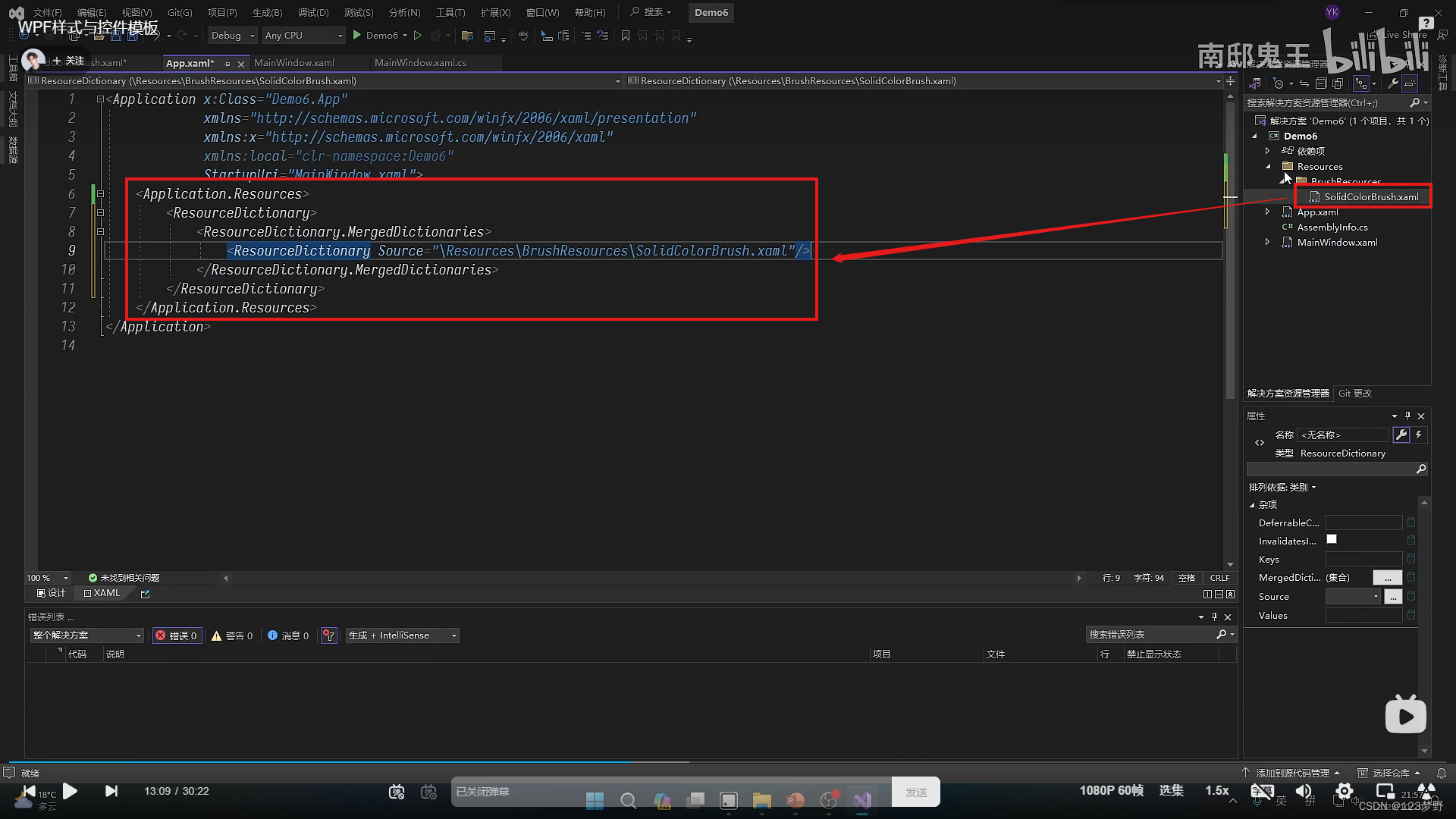
合并资源字典
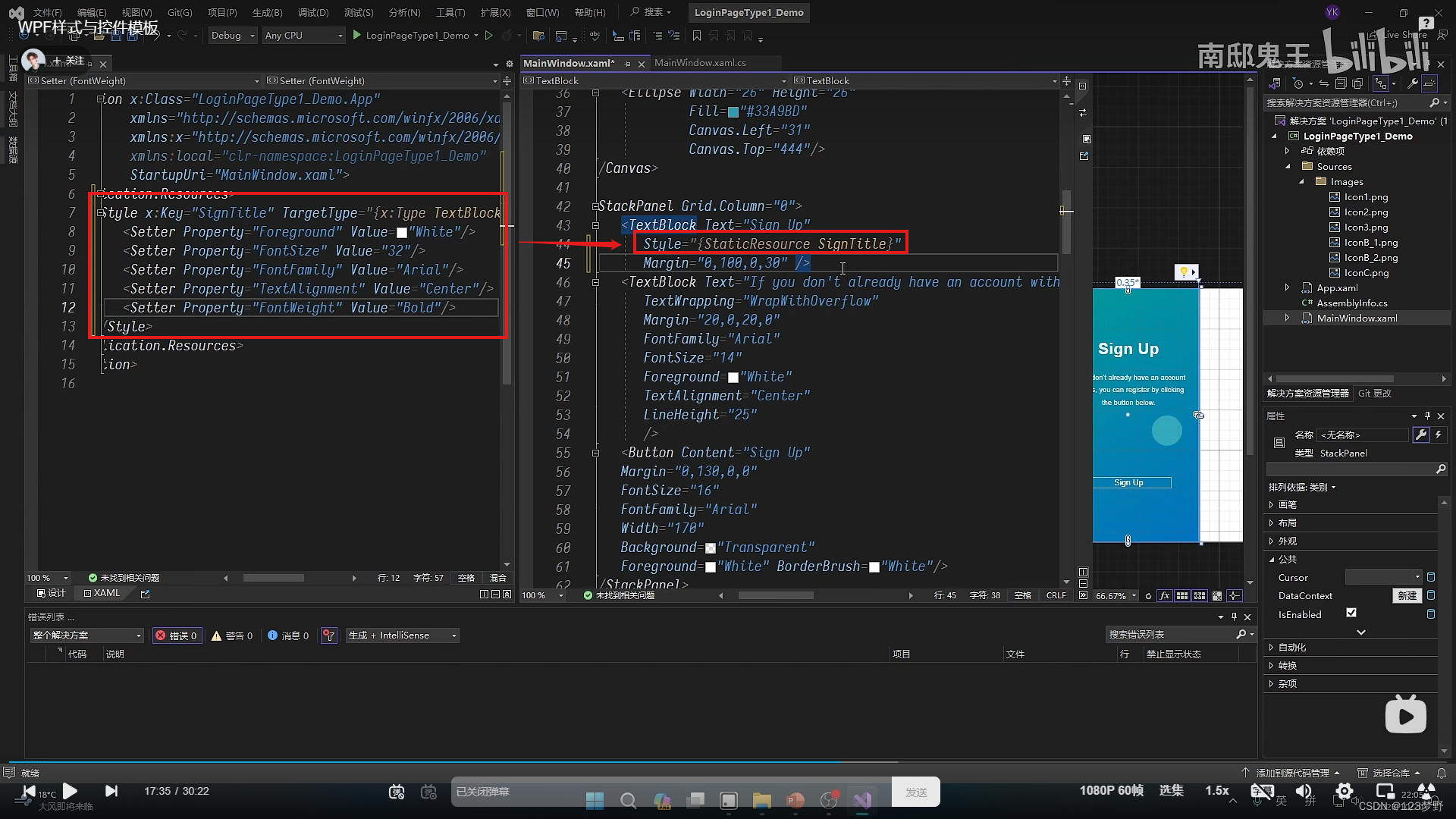
Style简单样式的定义和使用
ControlTemplate控件模板的定义和使用


定义

使用

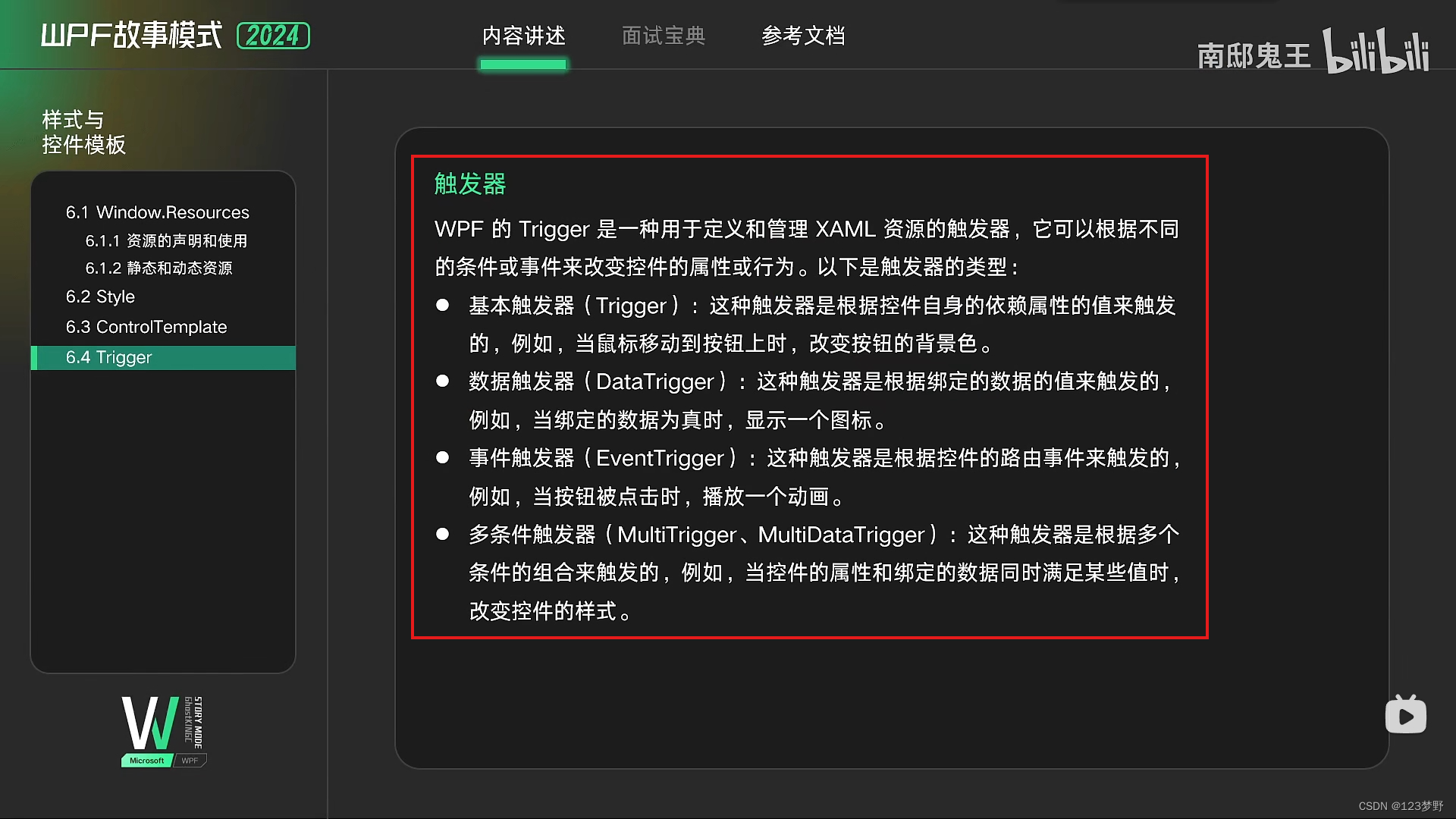
Trigger触发器

数据绑定与校验转换
数据绑定的设置

代码层实现绑定




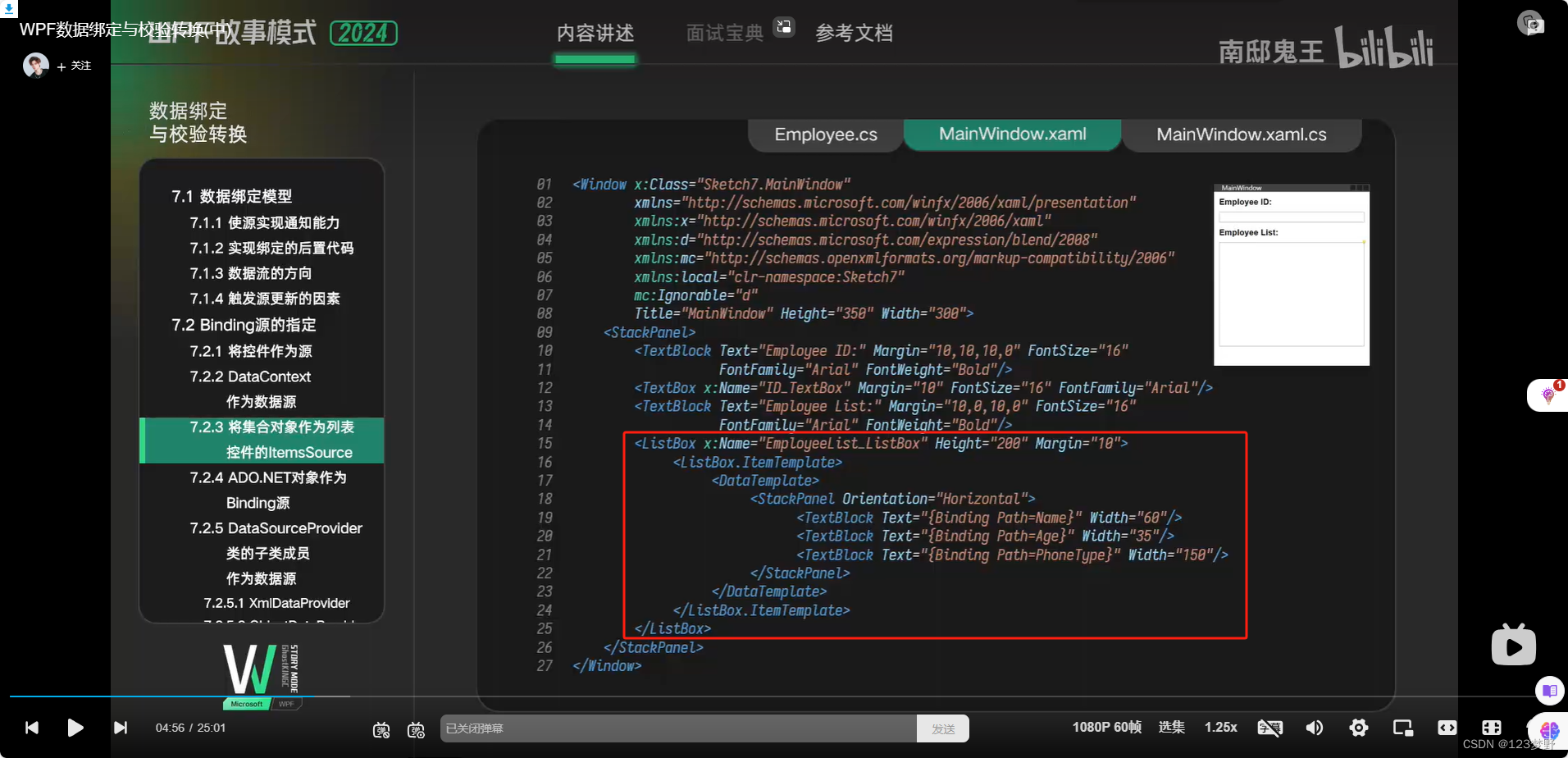
数据模板DataTemplate
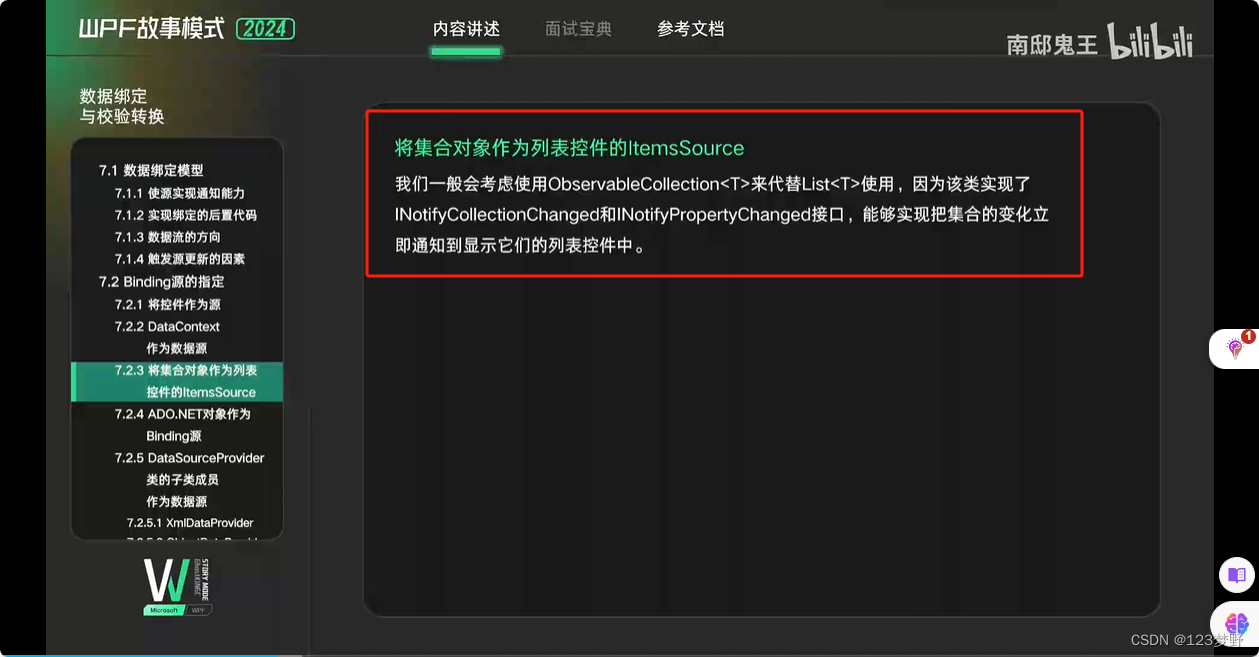
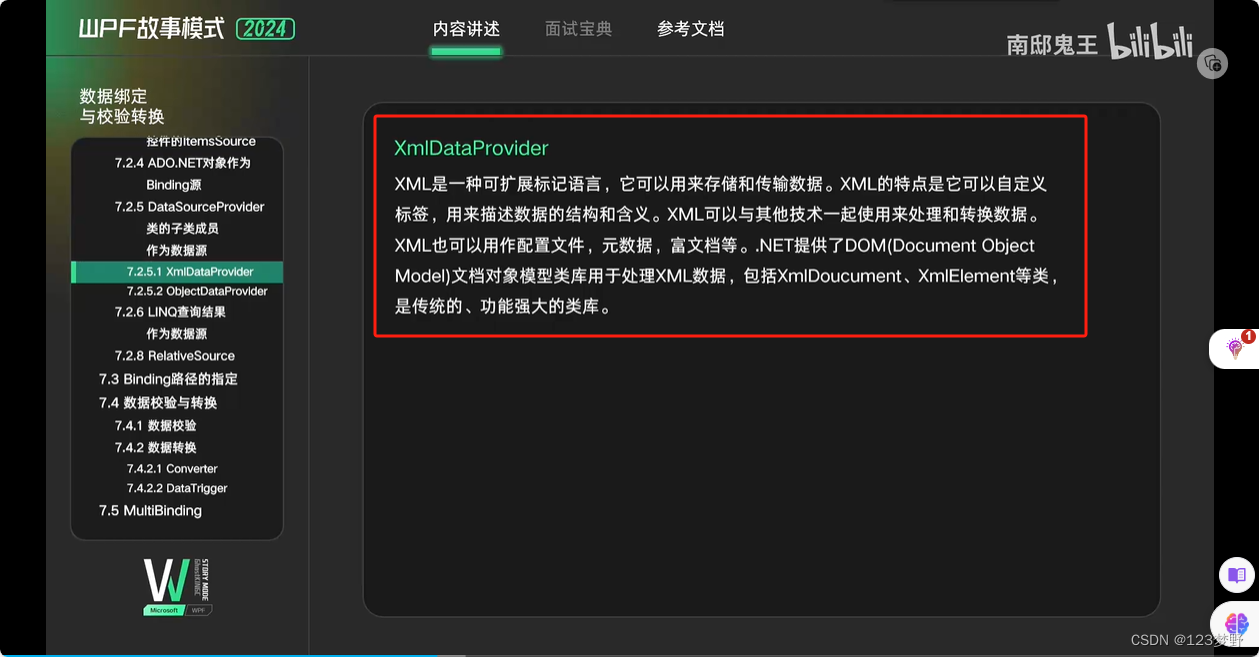
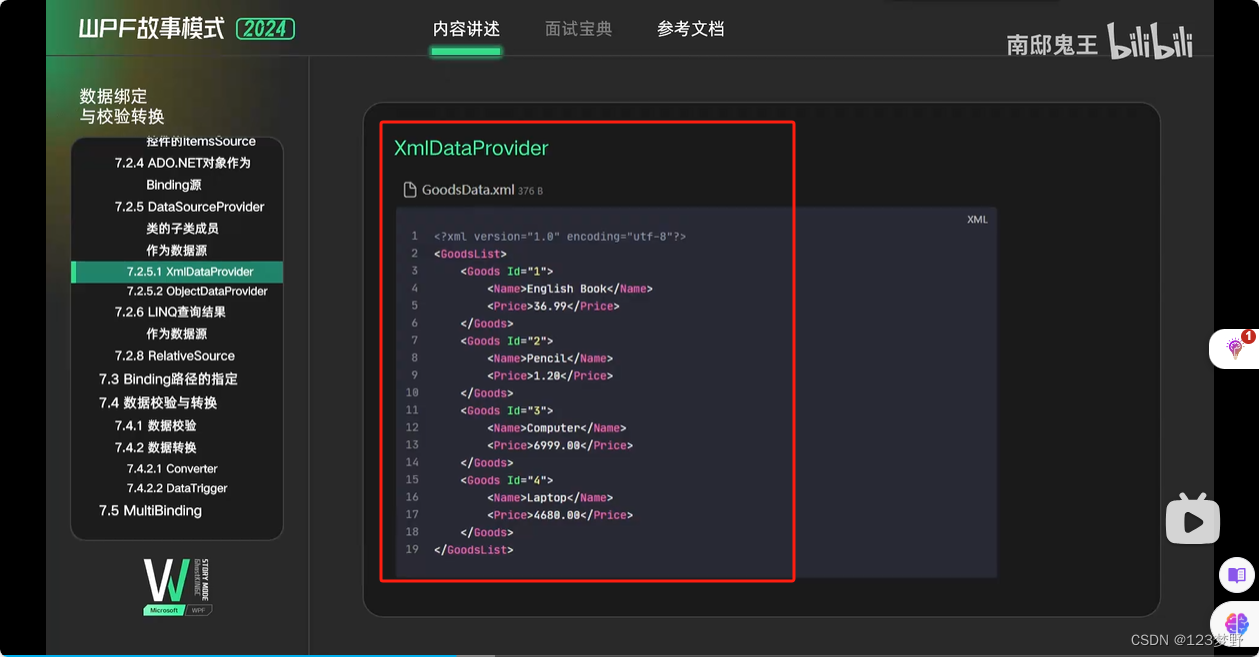
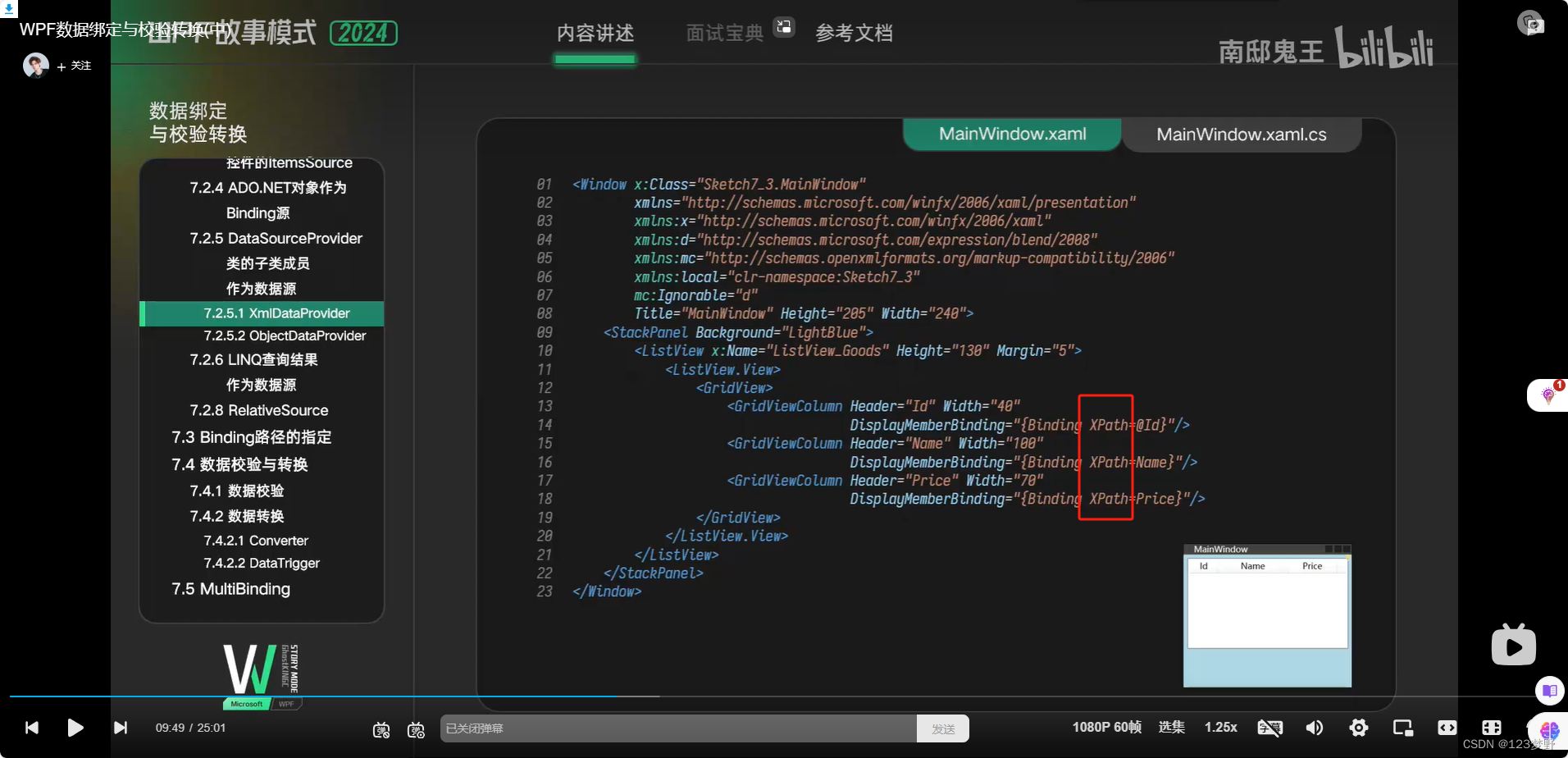
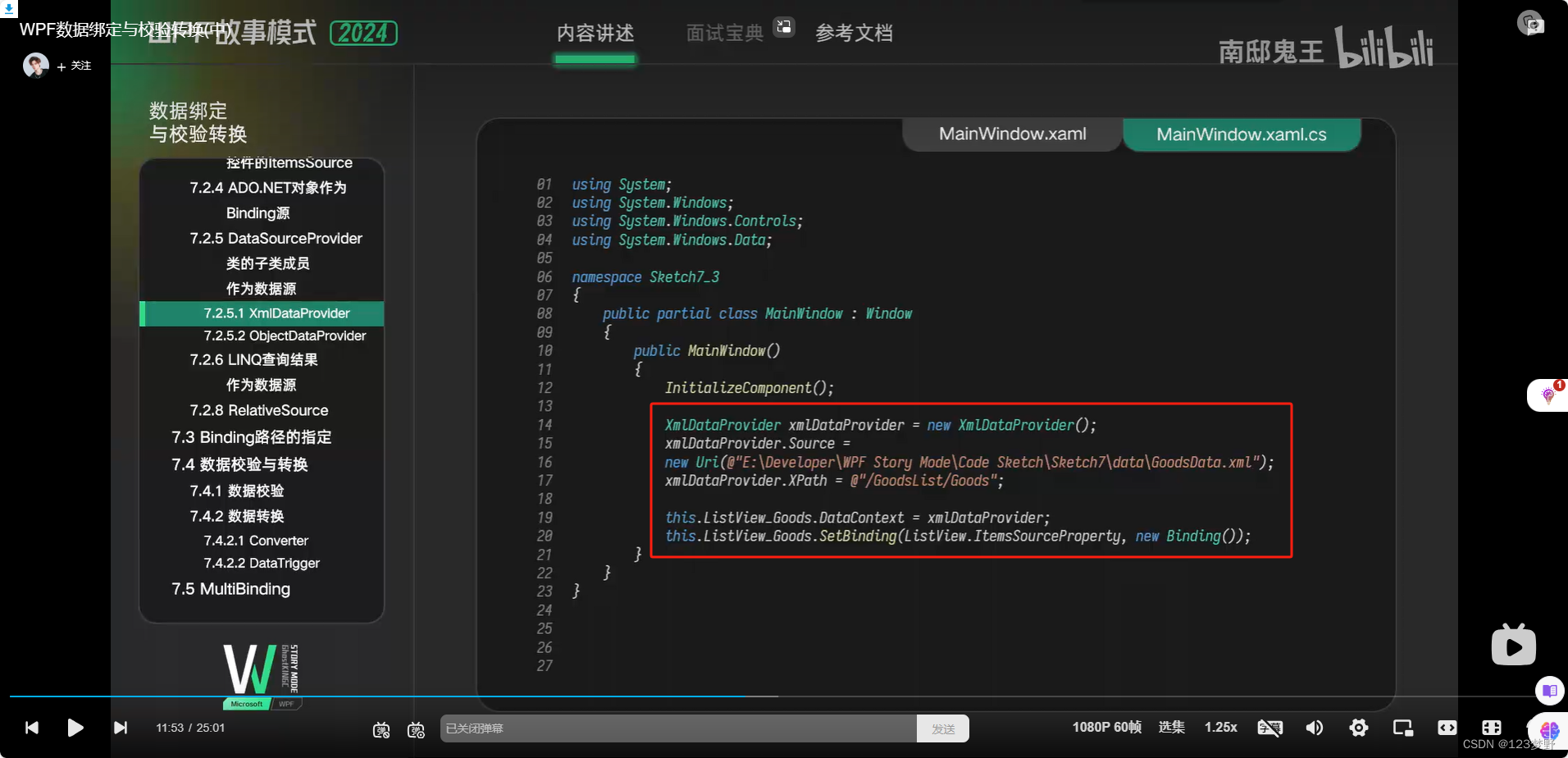
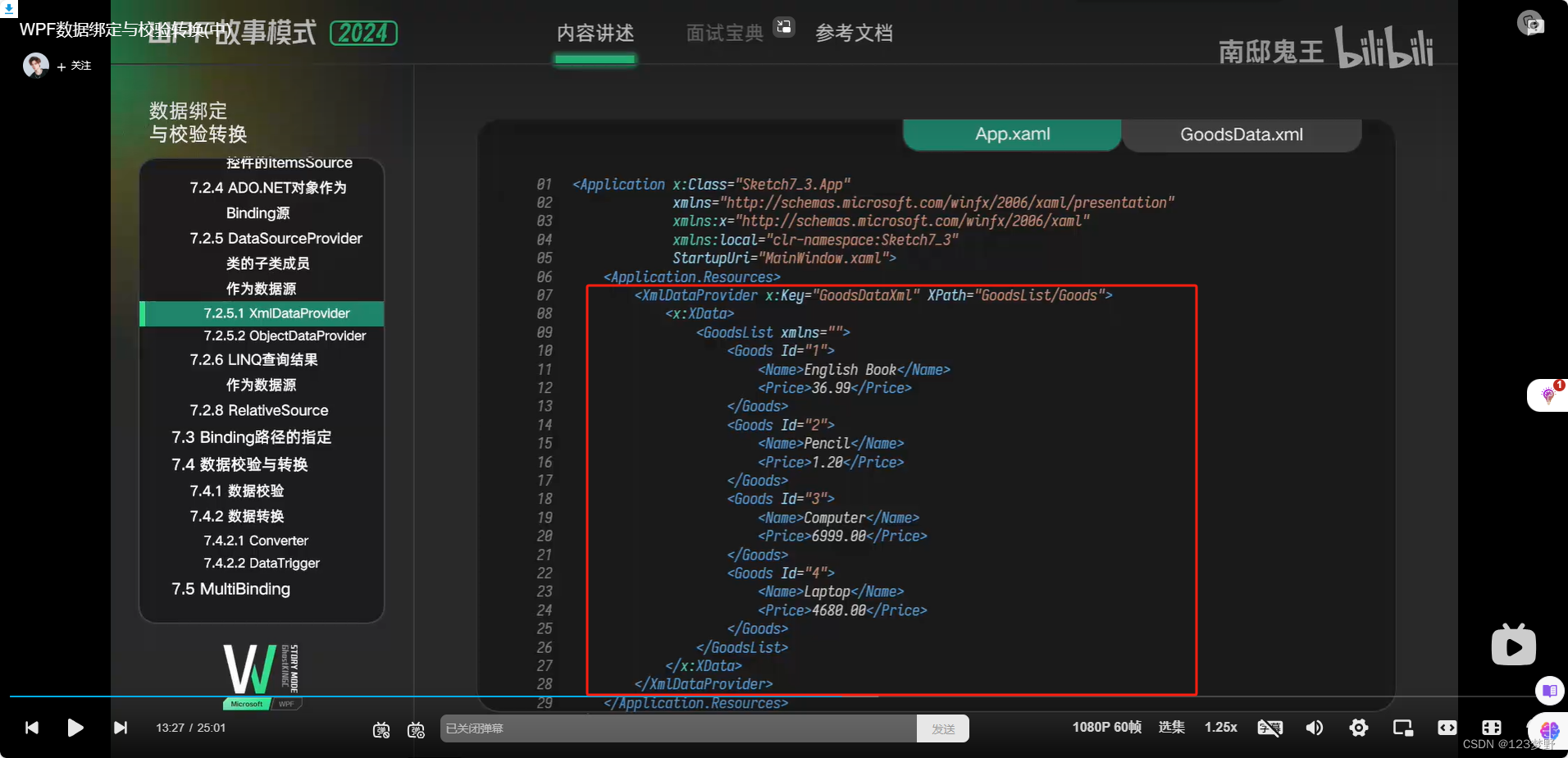
xml文件的读取与显示
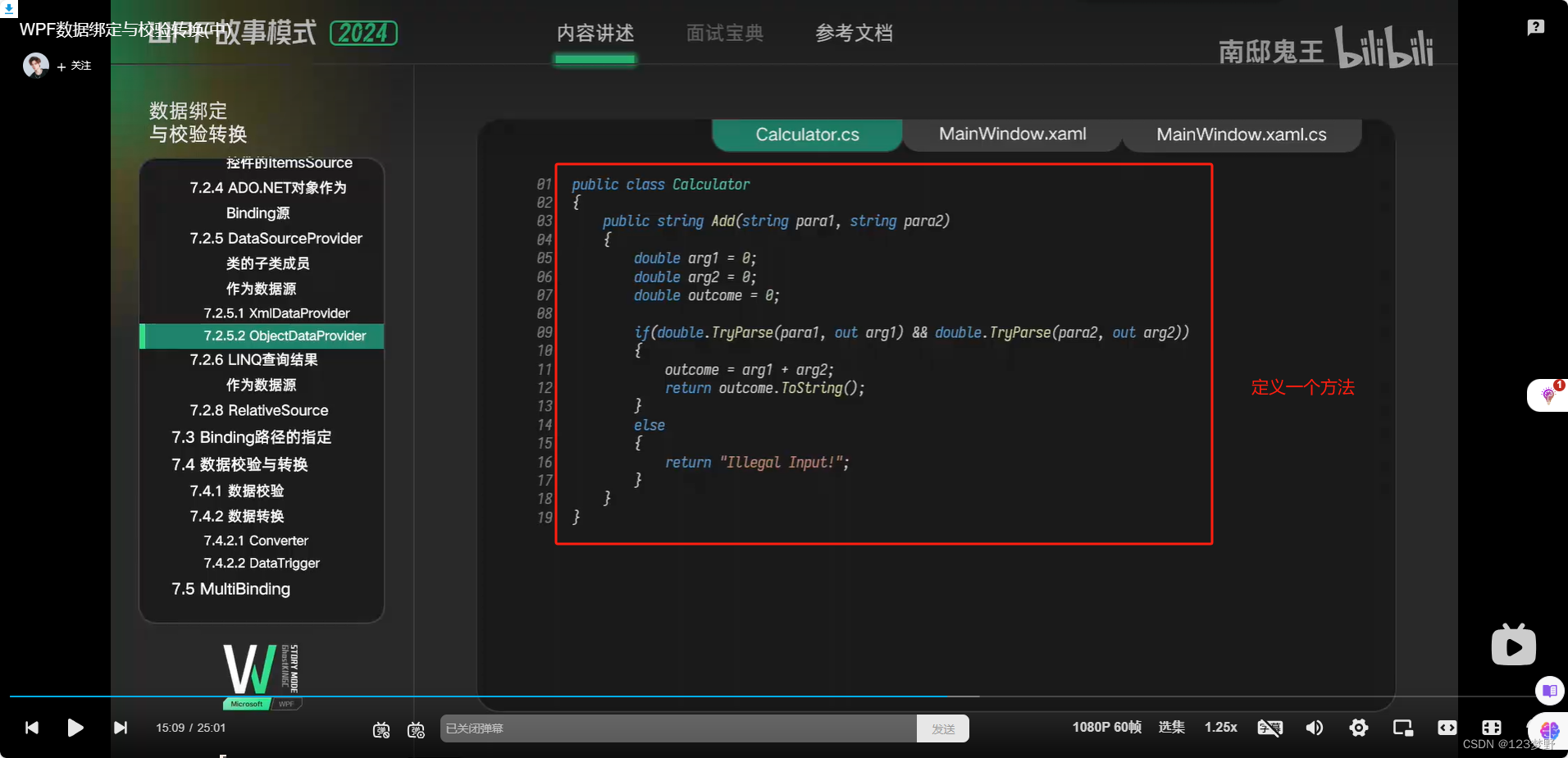
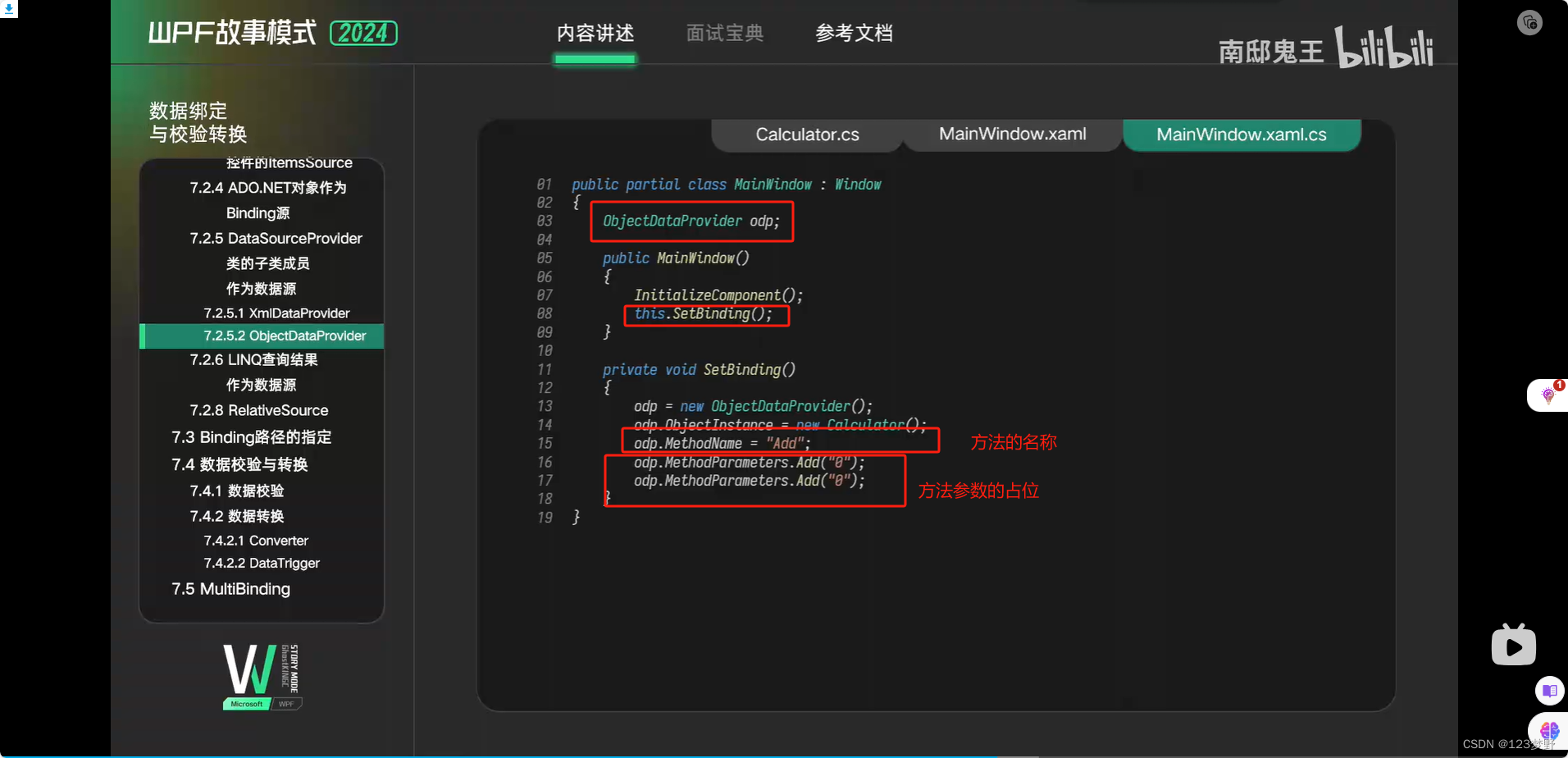
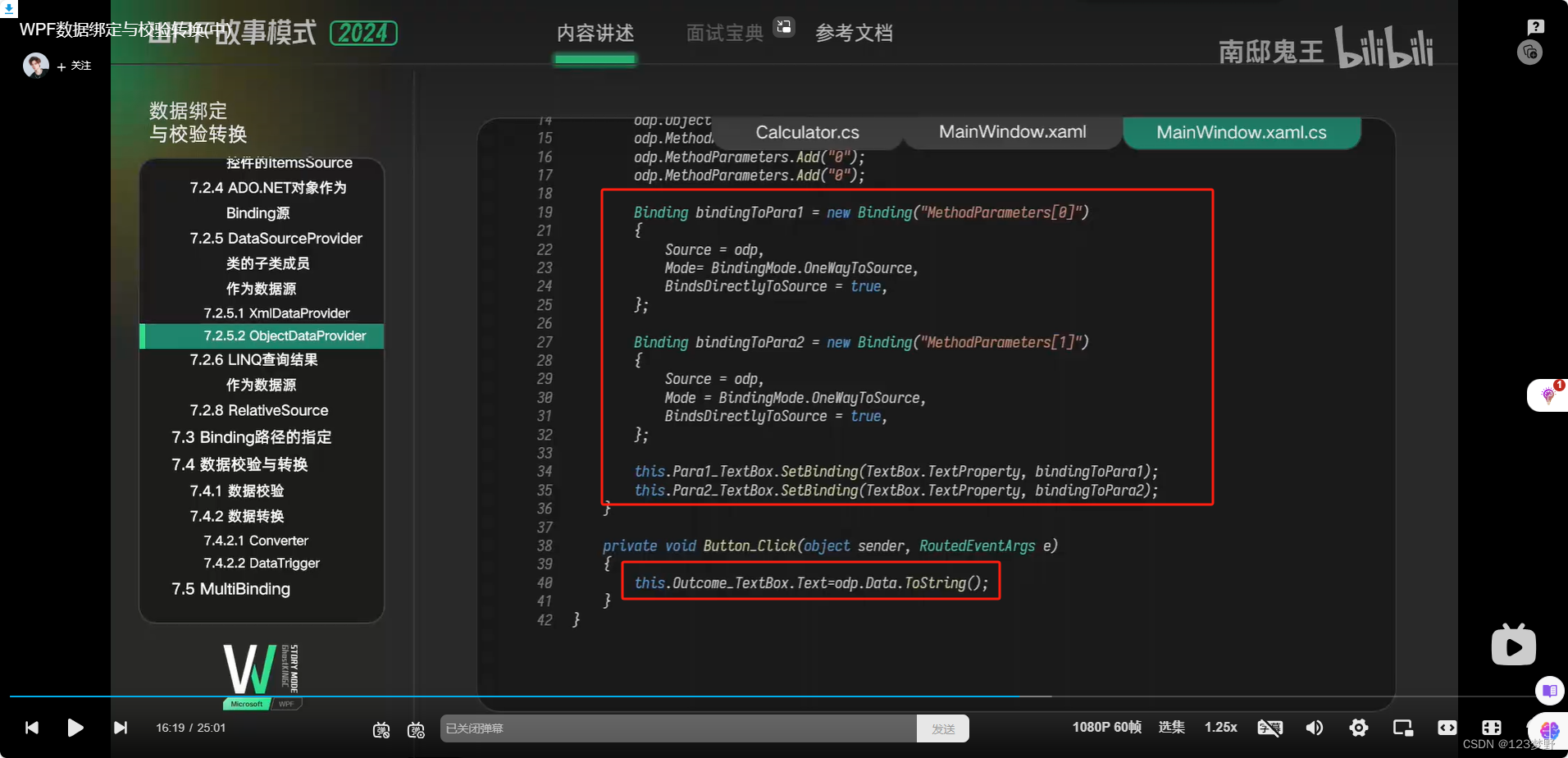
方法的返回值作为源绑定到控件中ObjectDataProvider
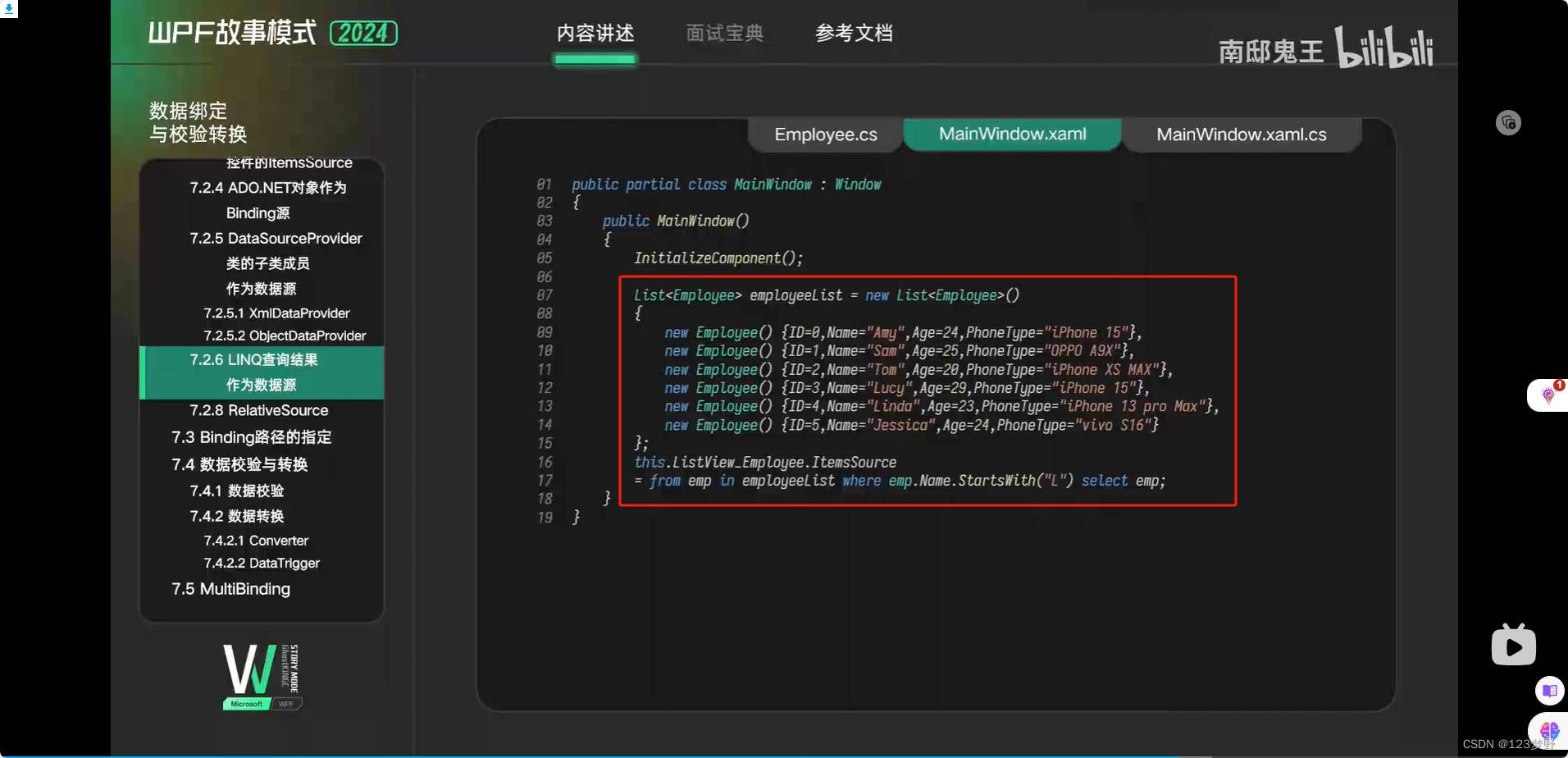
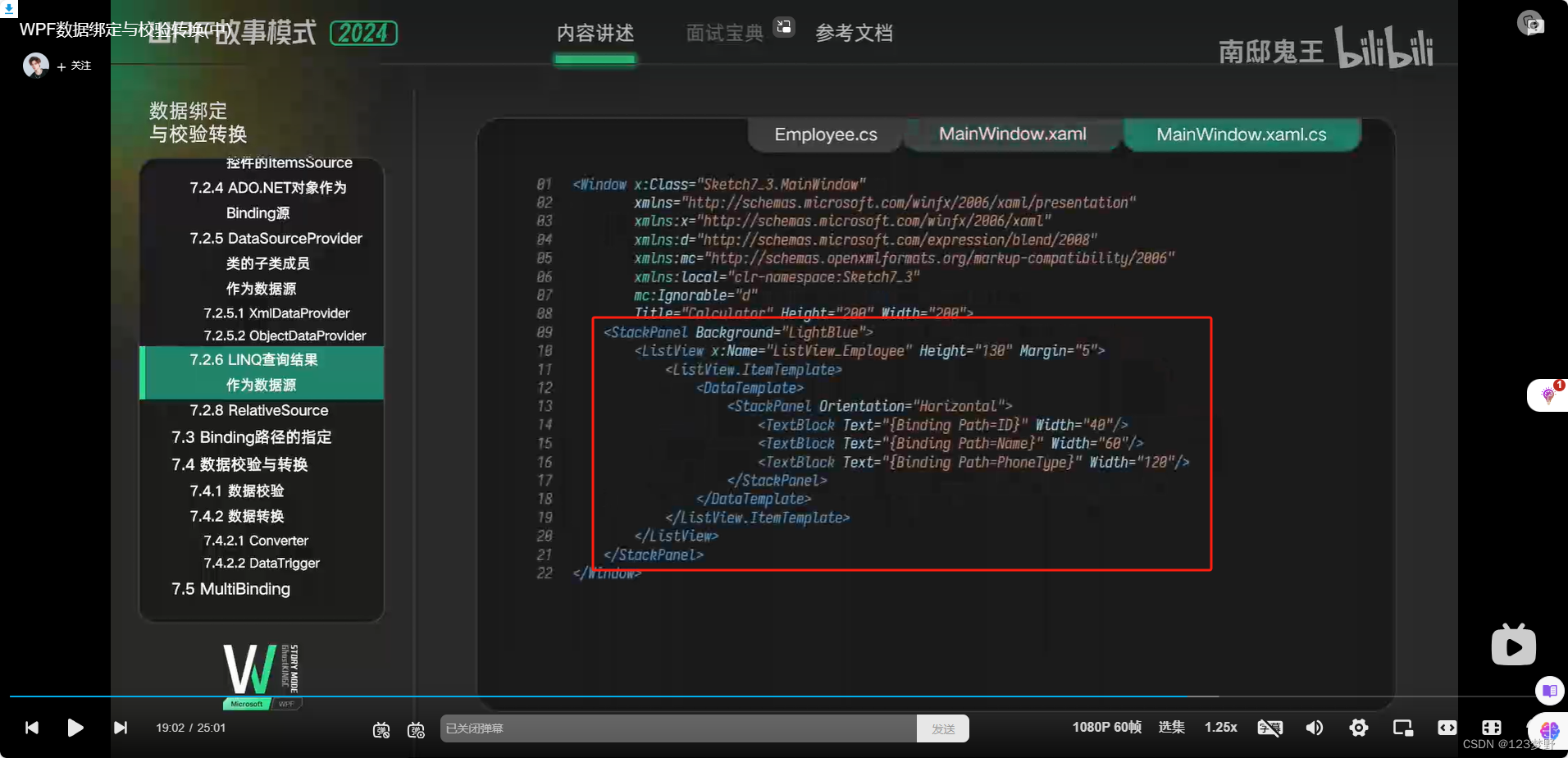
LINQ查询结果作为源
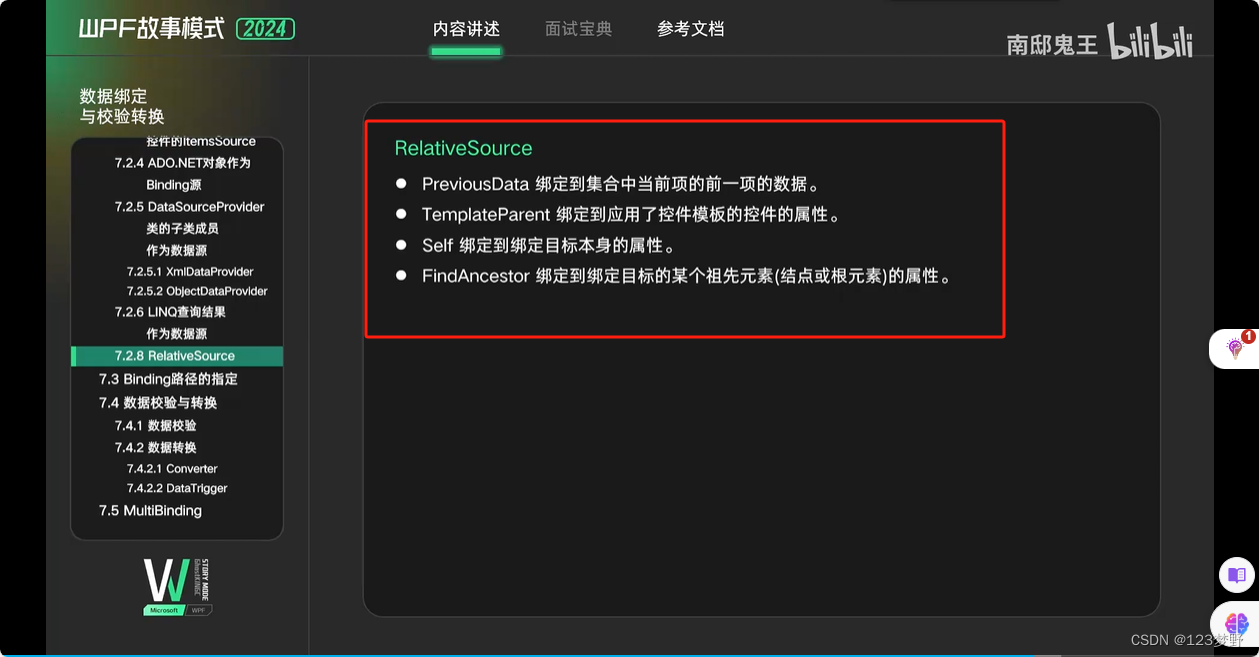
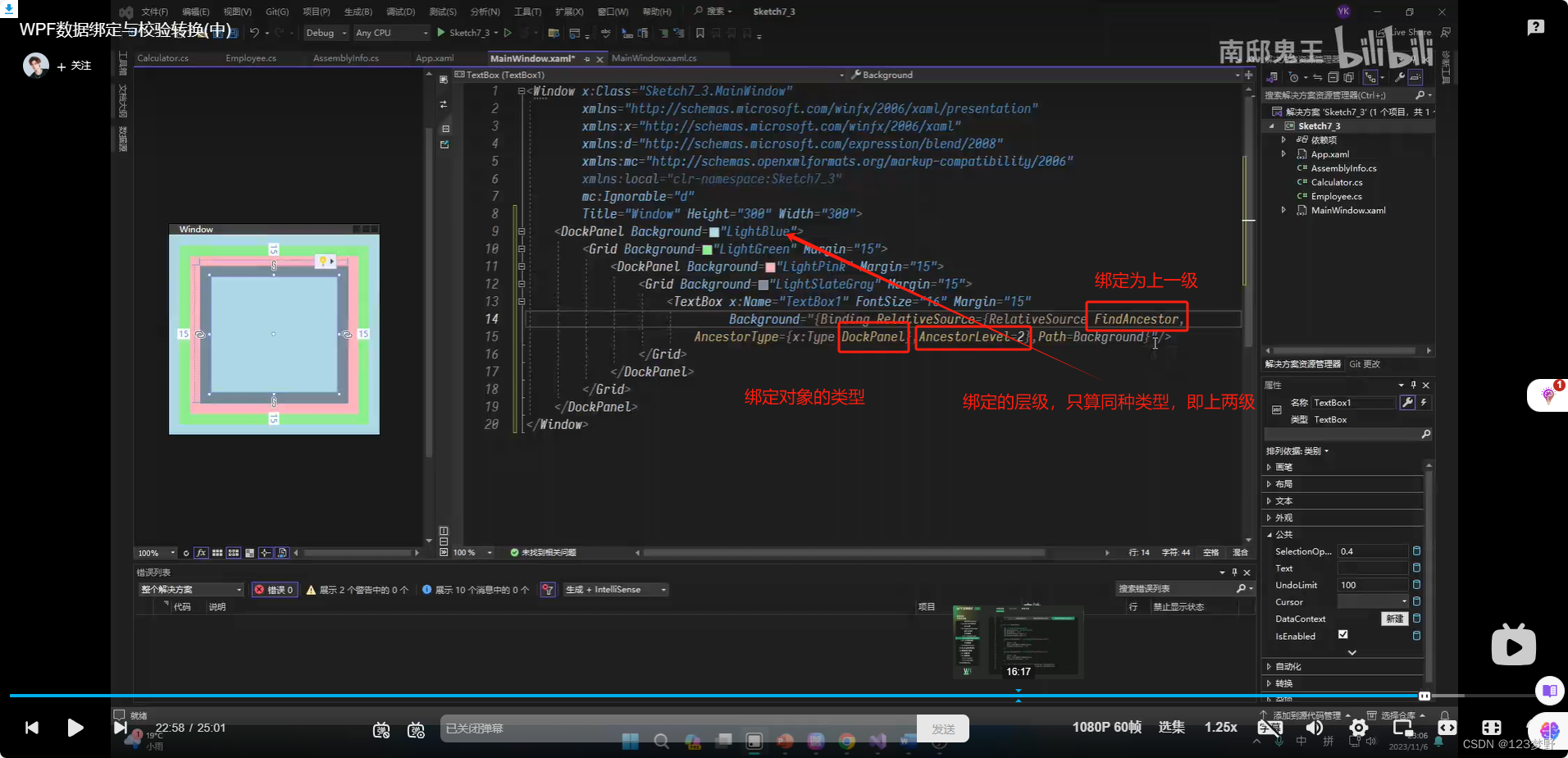
RelativeSource
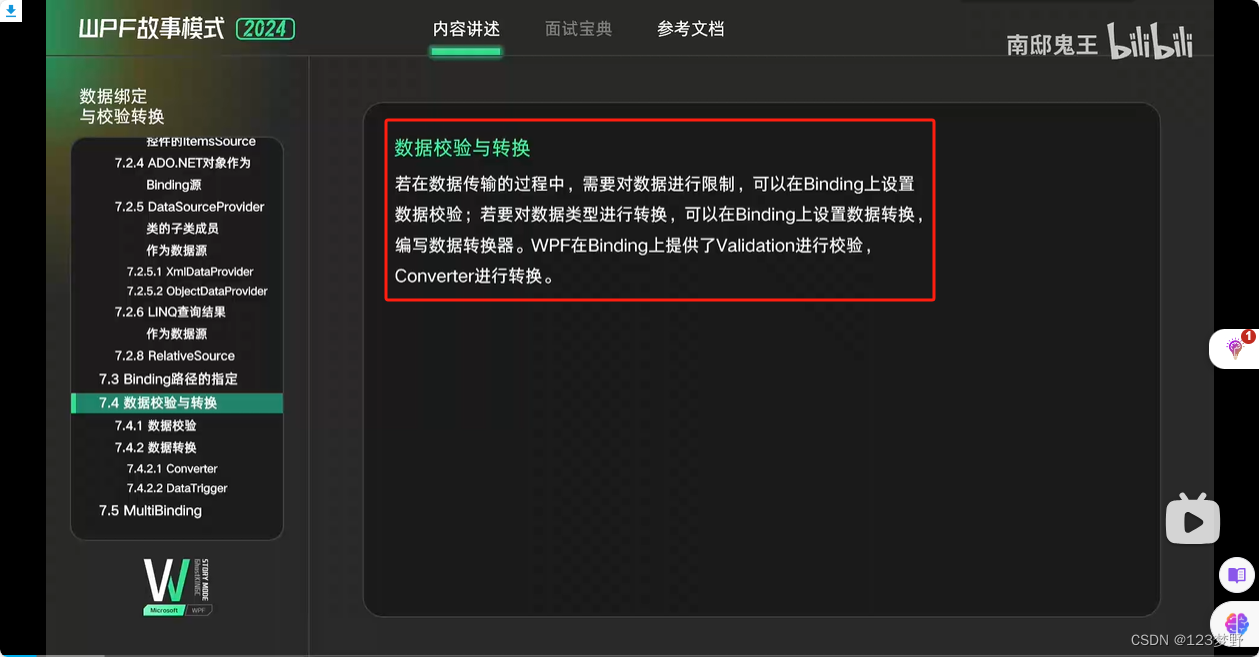
数据校验与转换
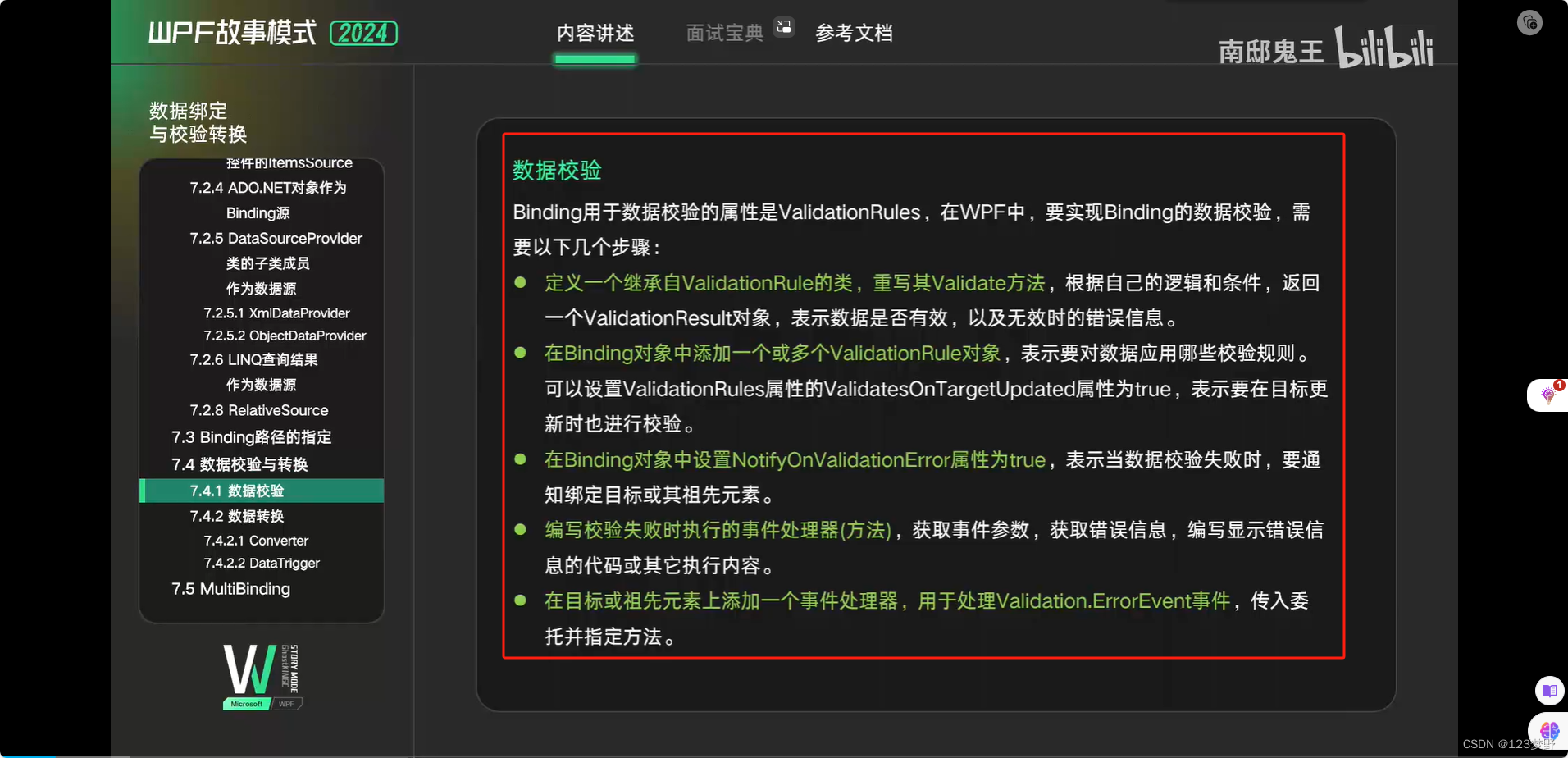
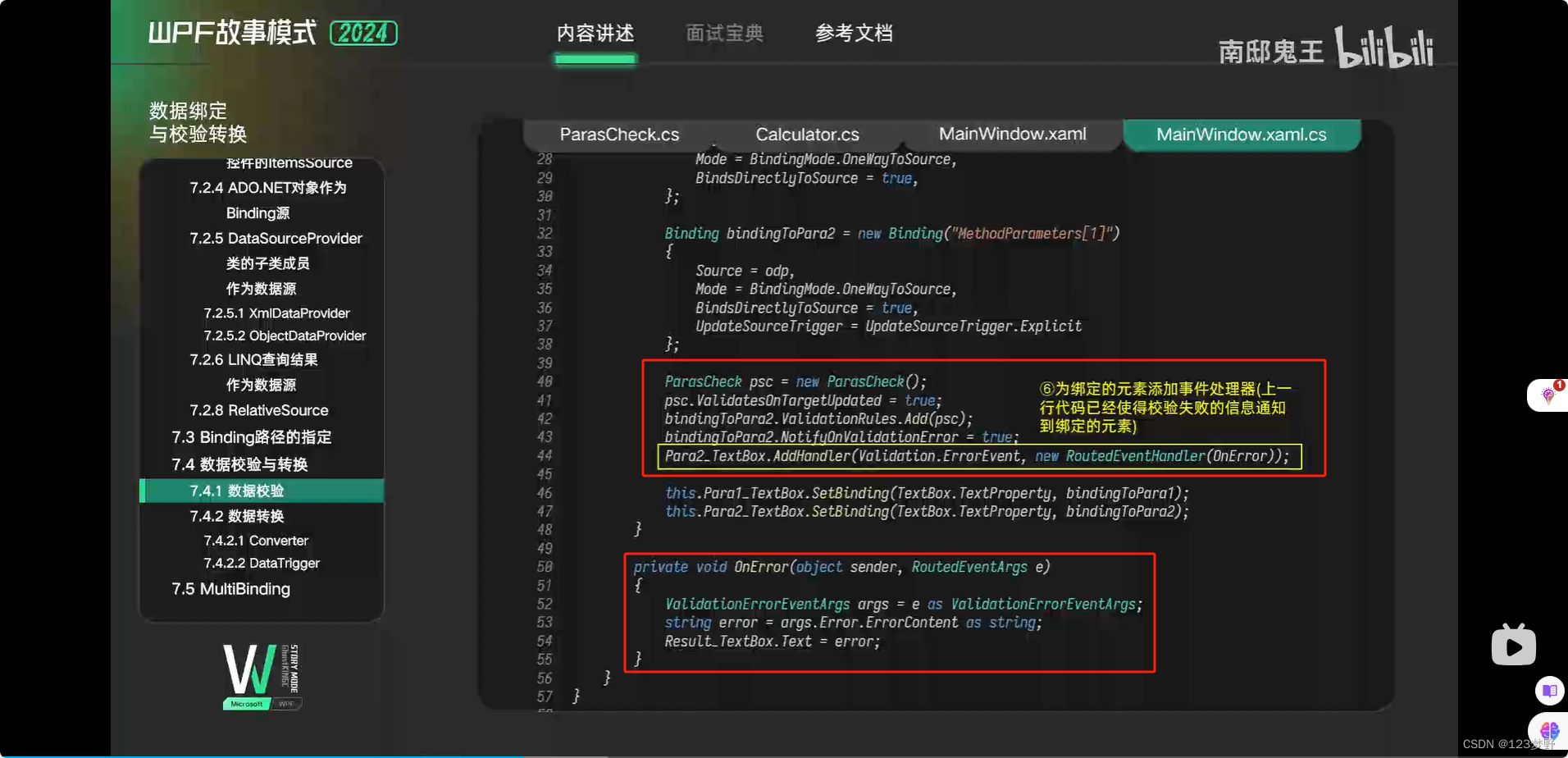
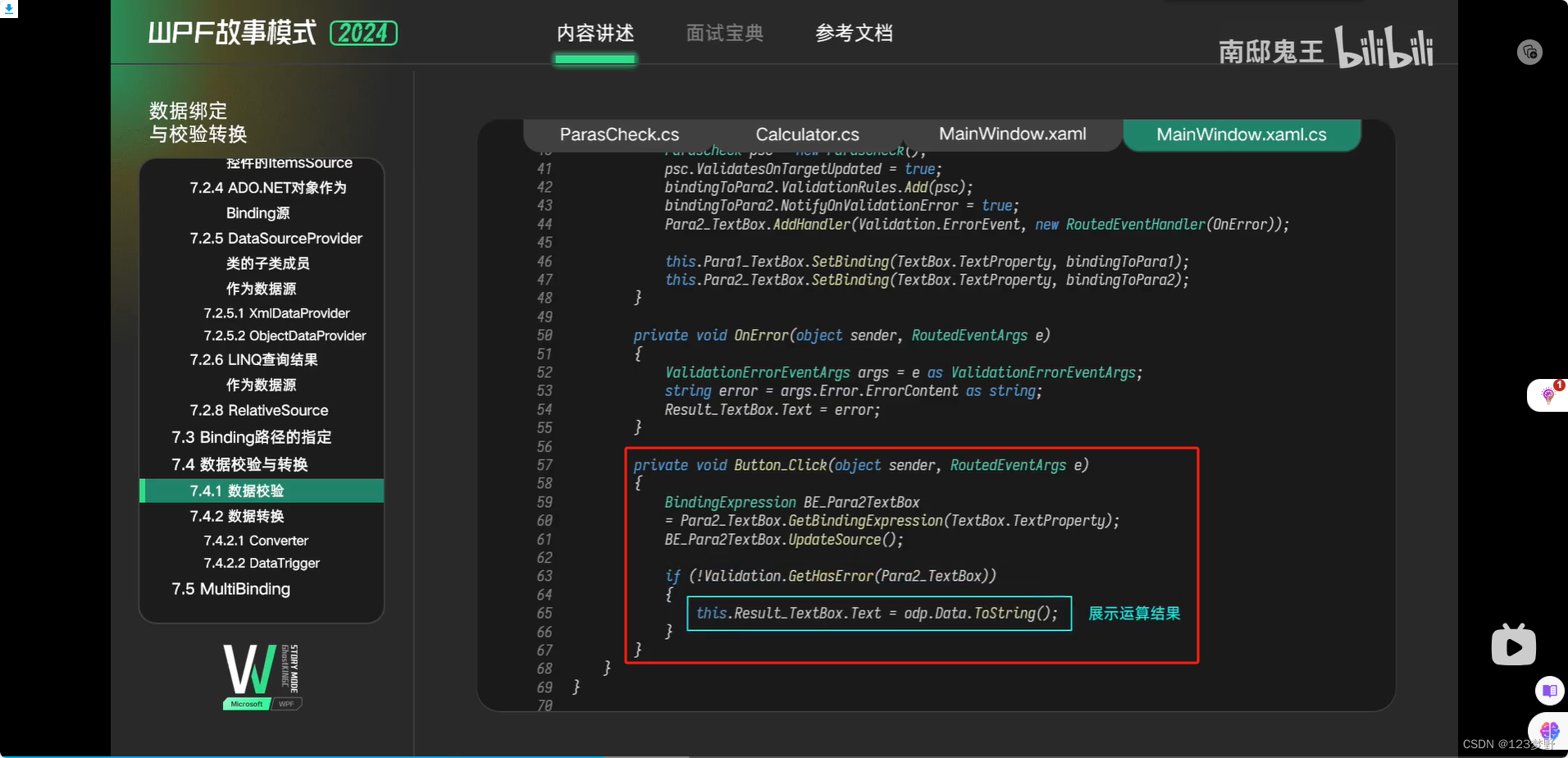
数据校验
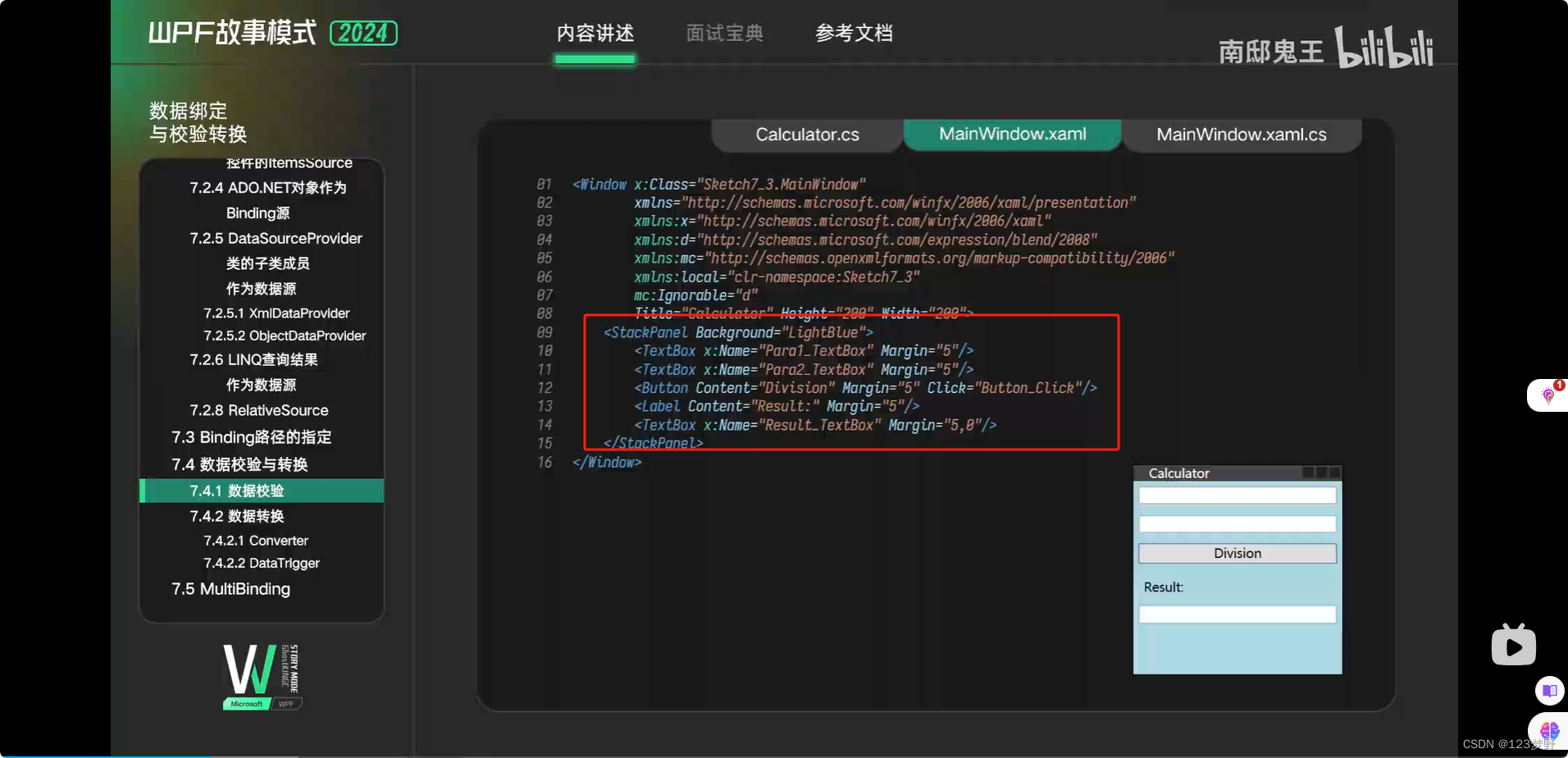
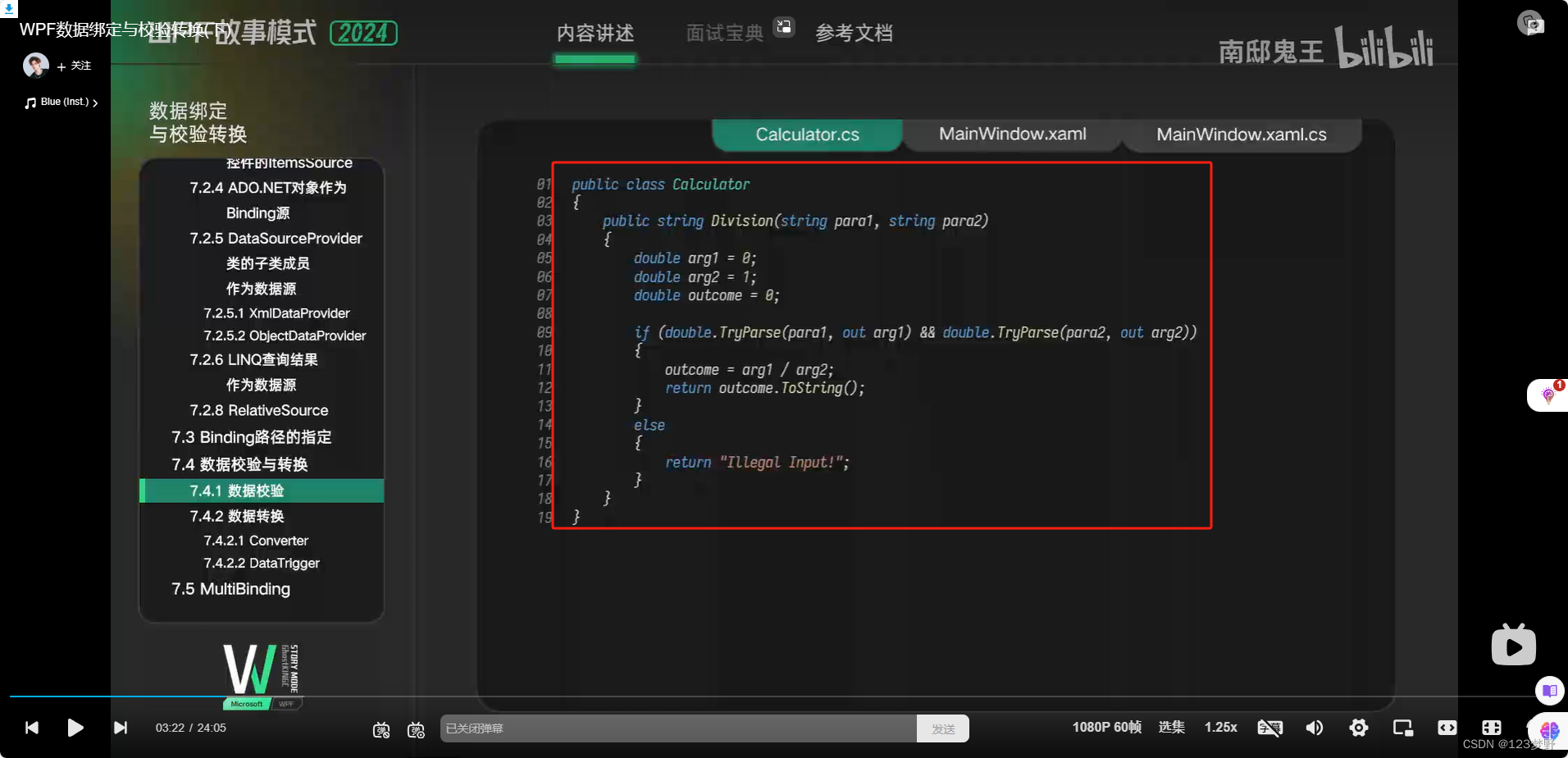
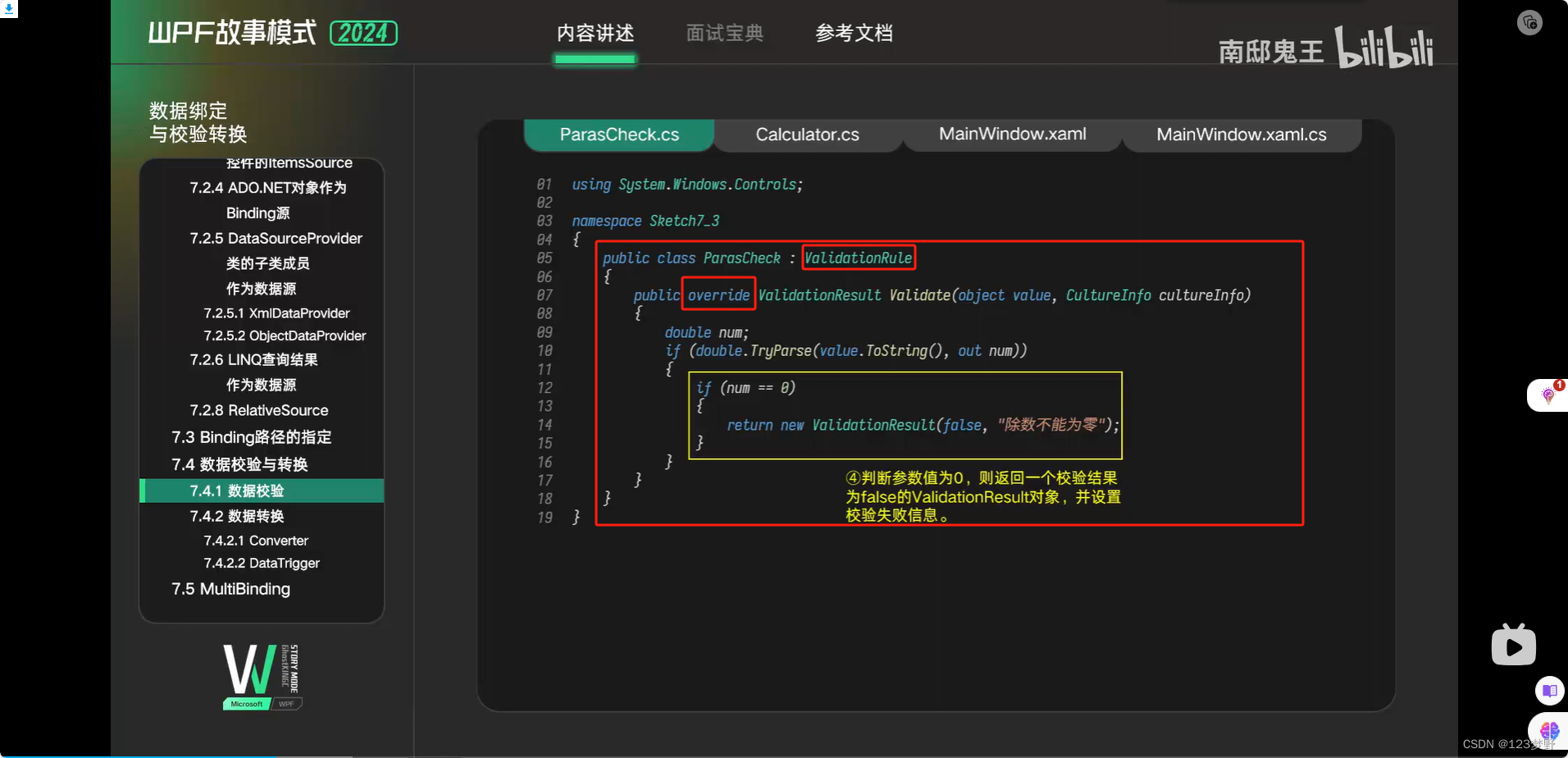
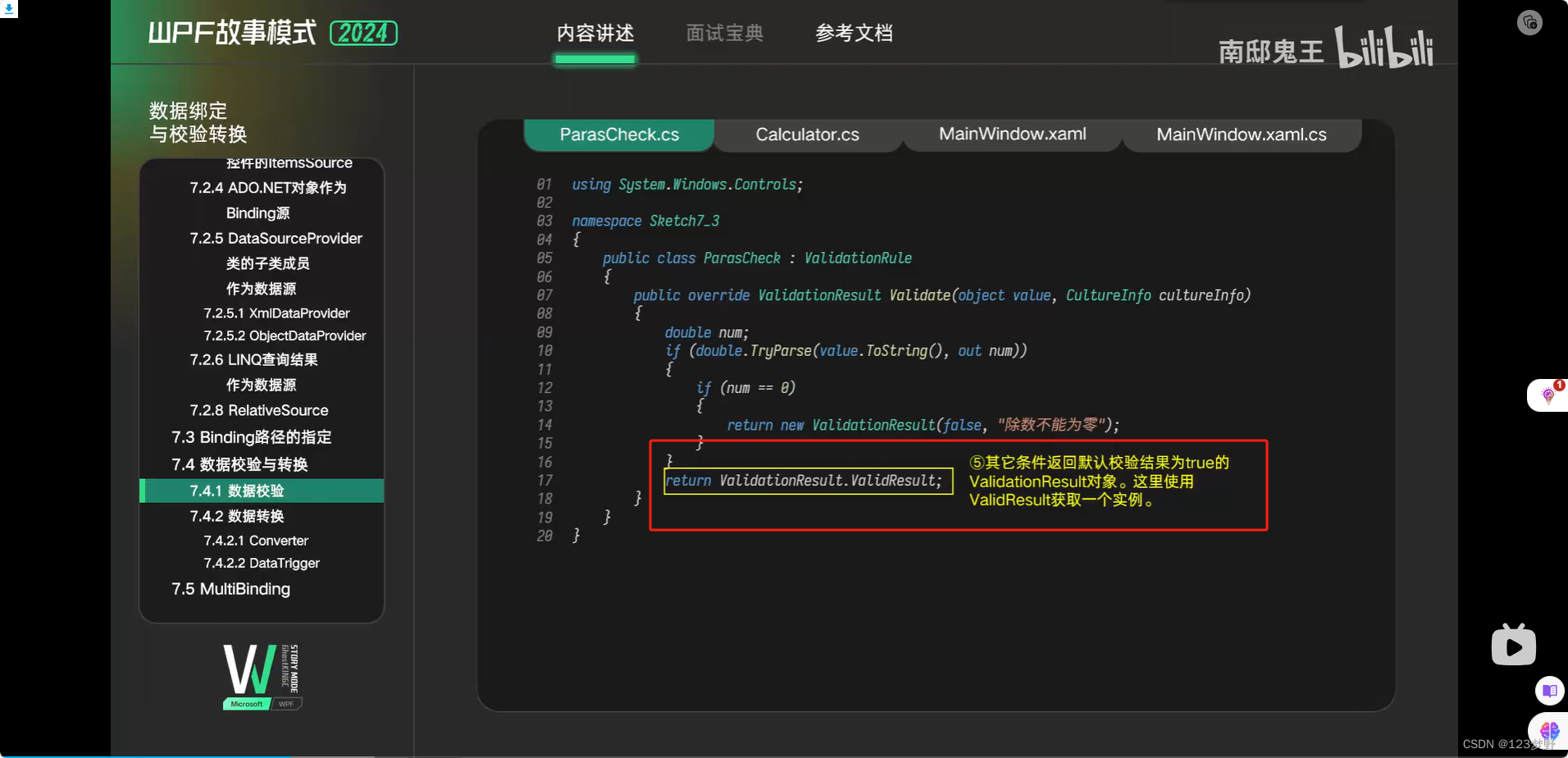
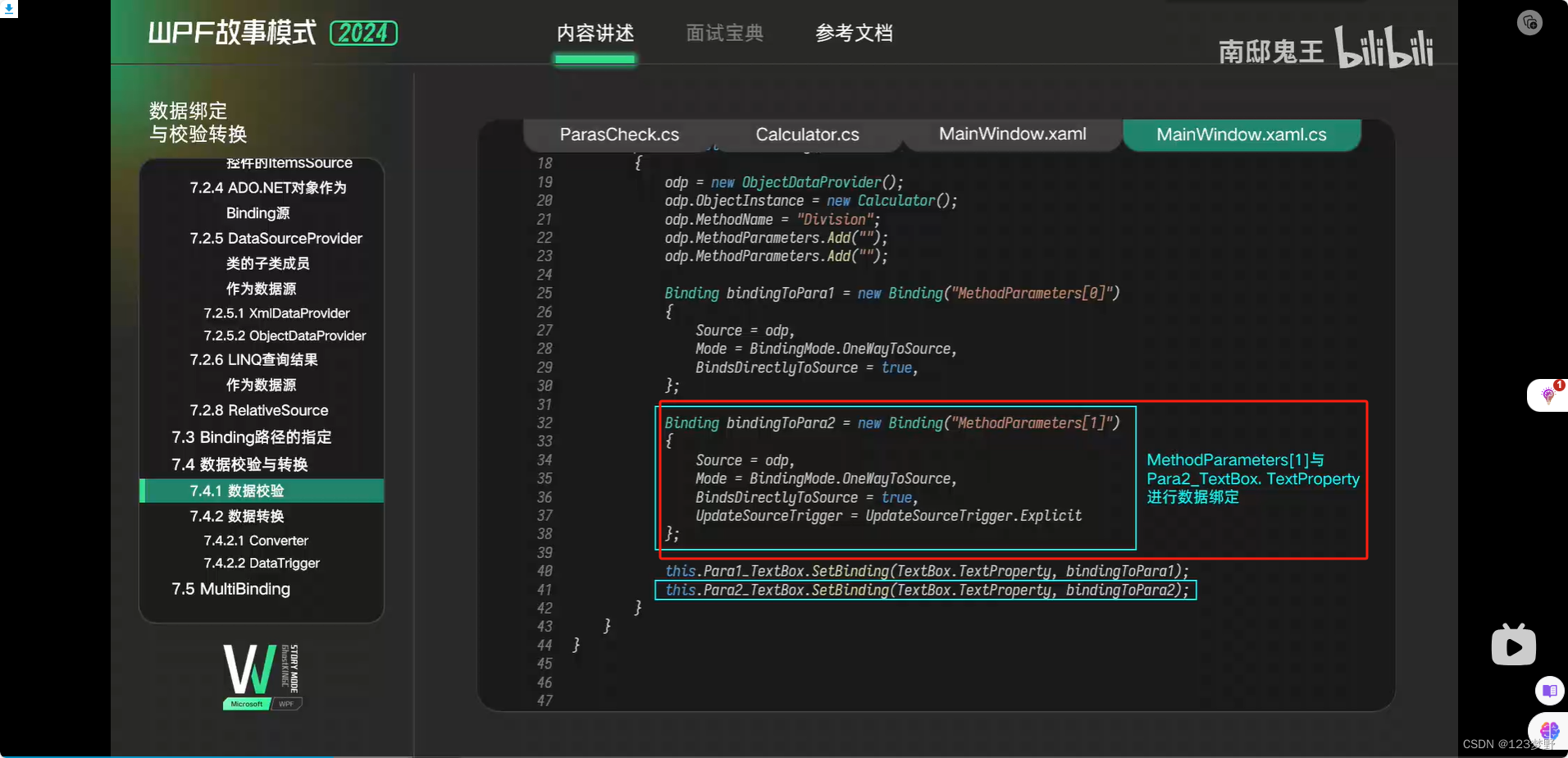
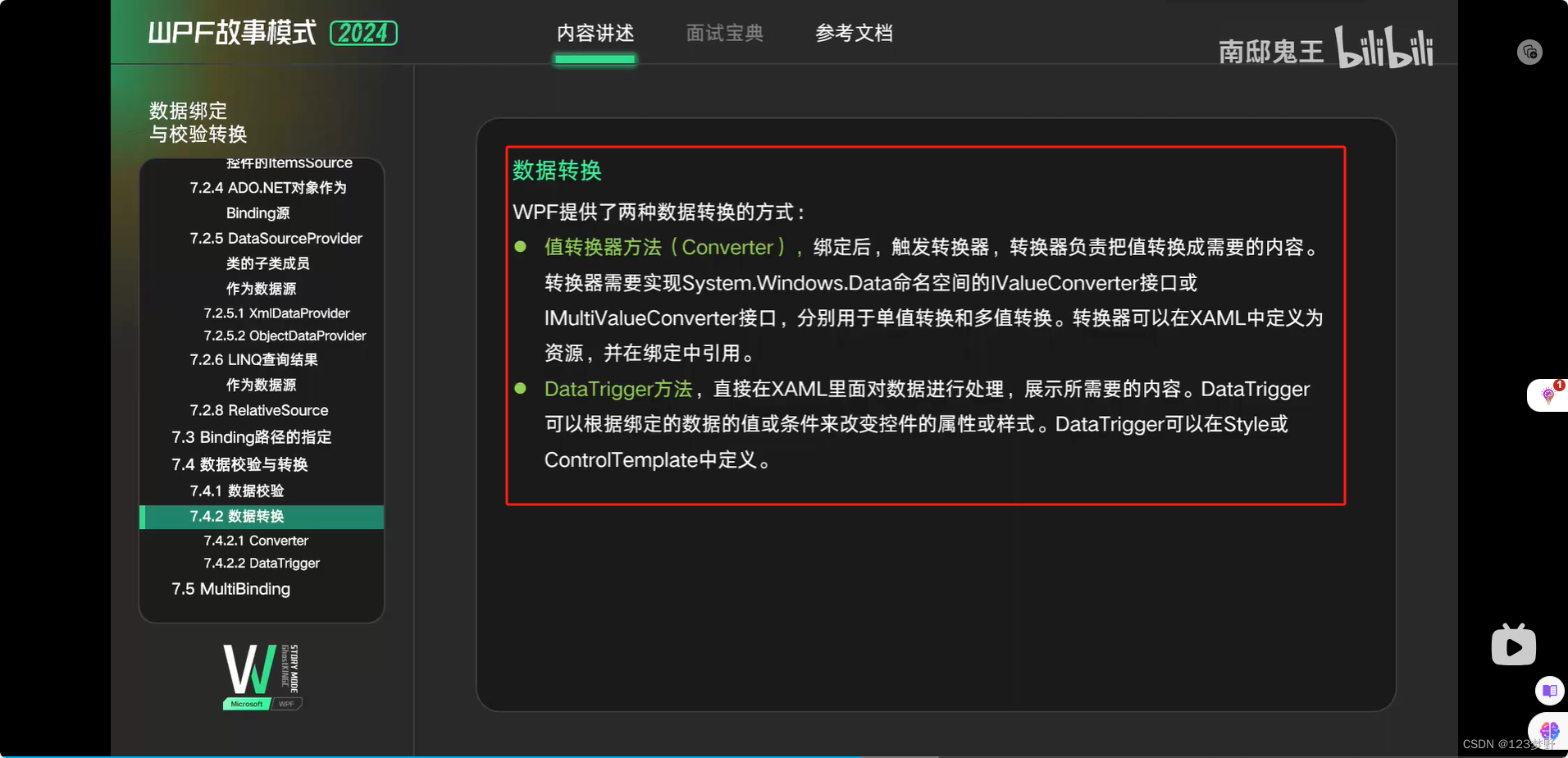
数据转换
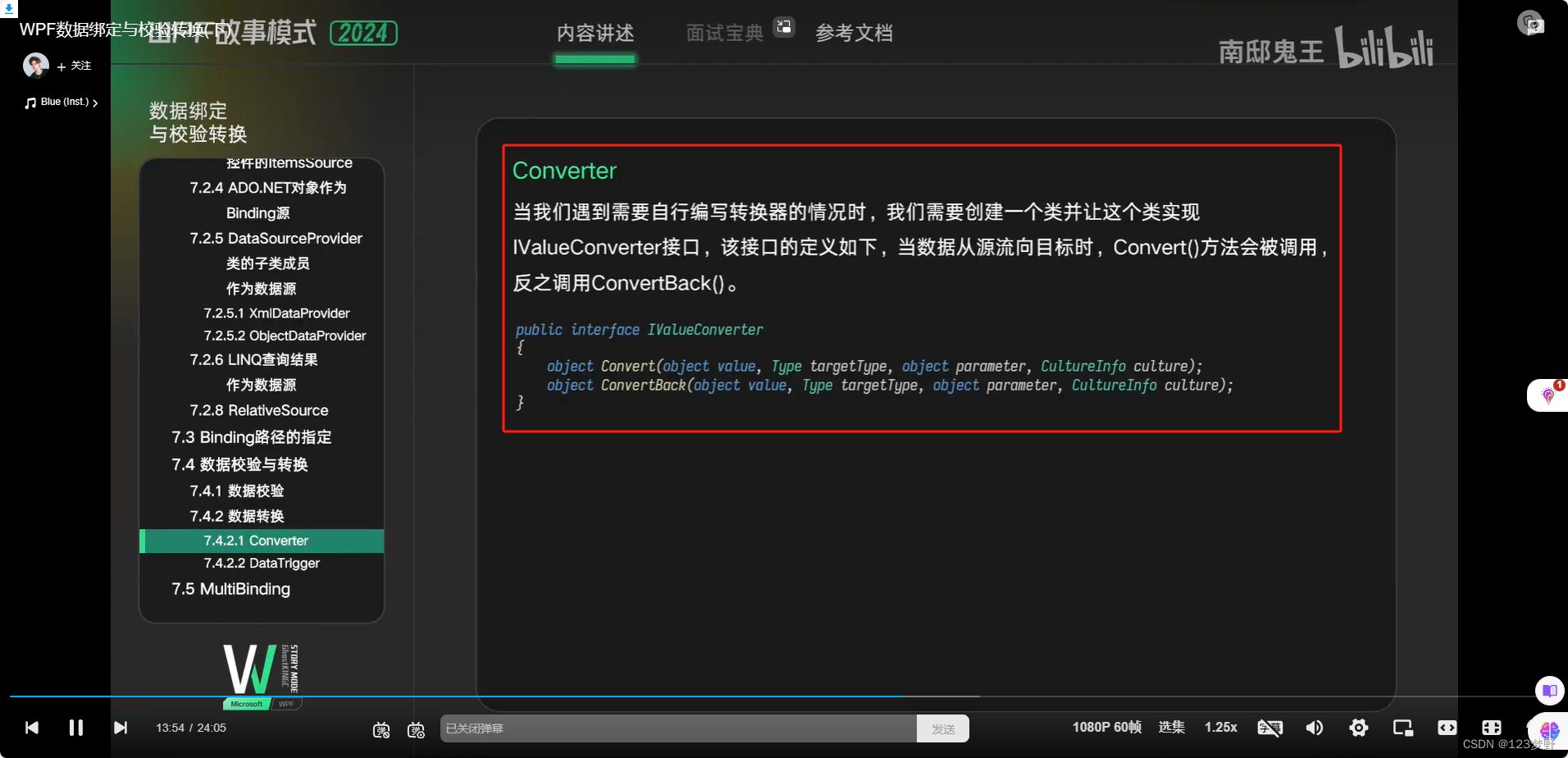
Converter
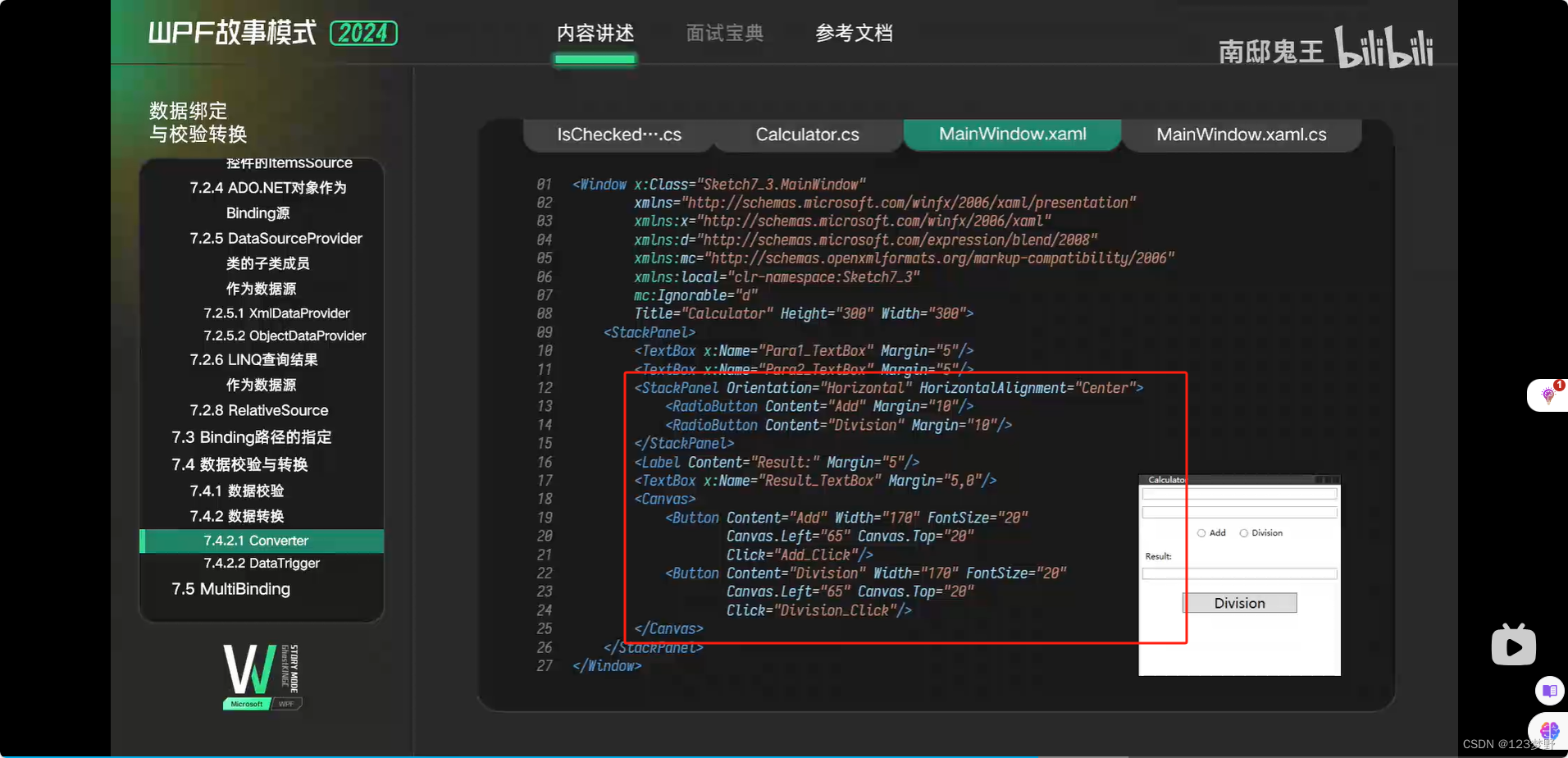
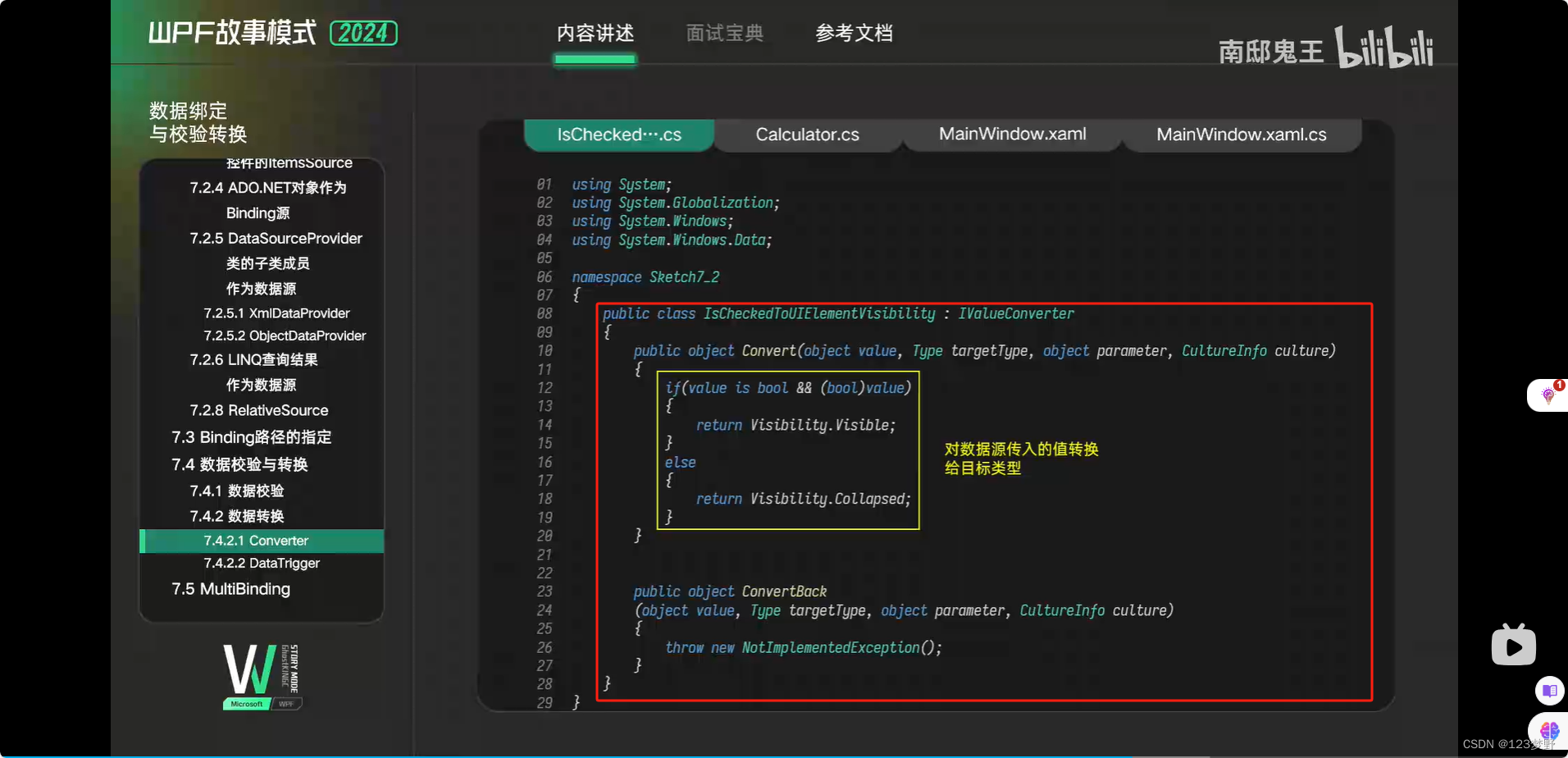
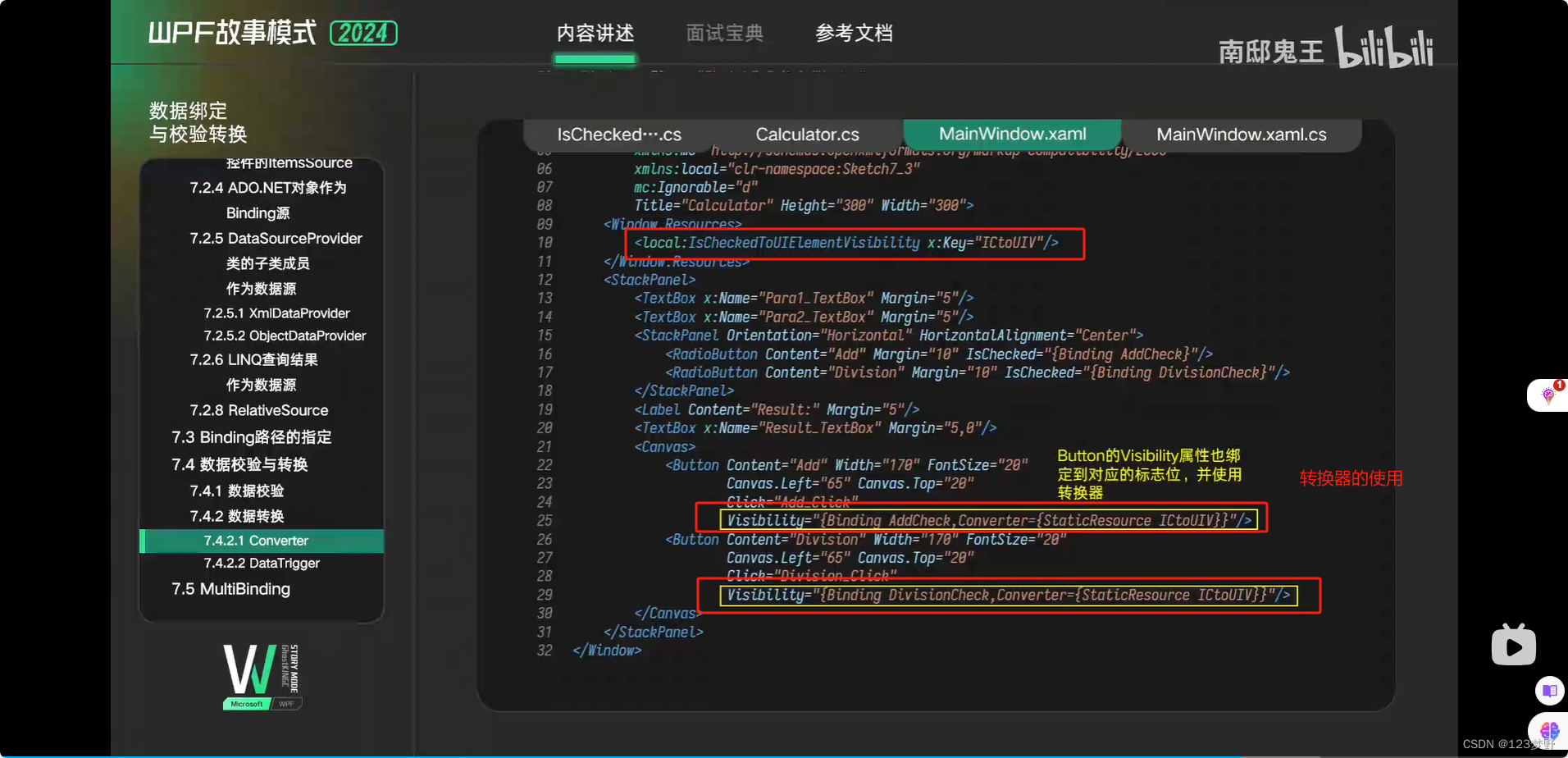
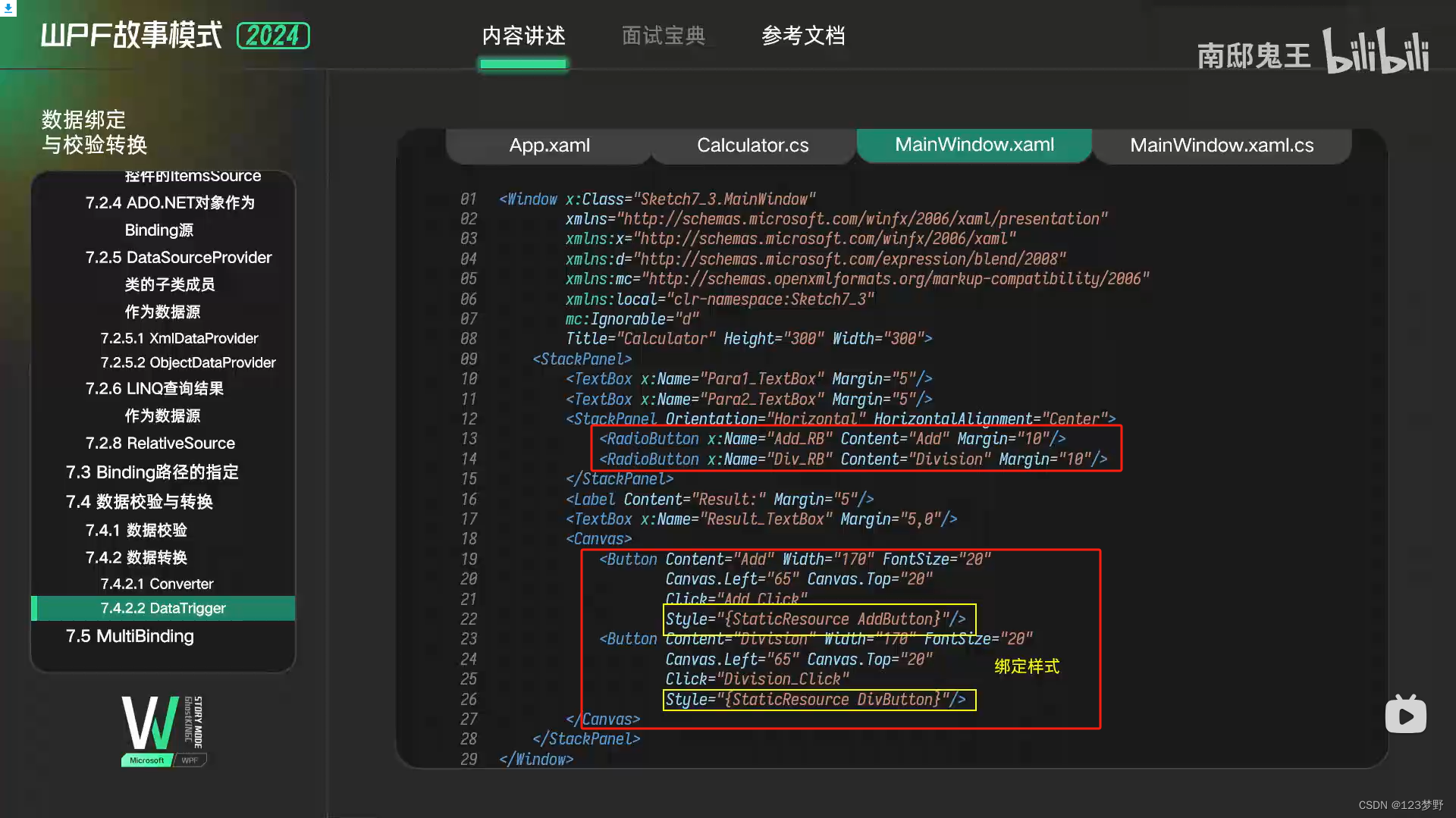
DataTrigger
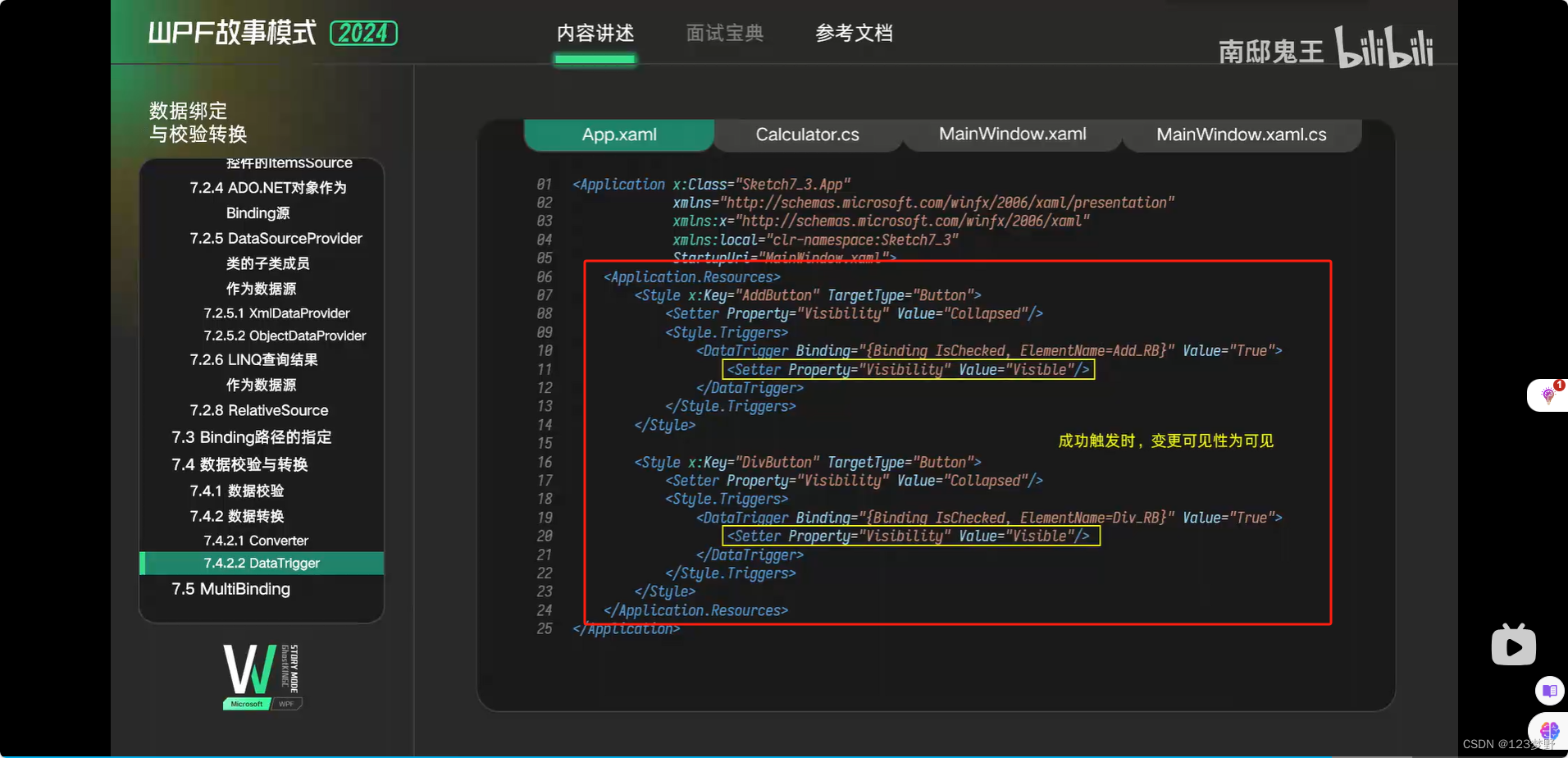

这篇关于WPF——样式和控件模板、数据绑定与校验转换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









