本文主要是介绍指标体系构建-01-什么是数据指标,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考
四千字全面解析数据产品经理必知概念:标签、维度、指标
什么是数据指标
指标是指于其中打算达到的指数,规格,标准等,是用数据对事物进行描述的工具。通常指标对应是否有价值取决于这个指标的实际意义。同时关注指标对应的数值,主要关注其单位及波动性。
| 动态指标 | 半动态指标 | 静态指标 |
|---|---|---|
| 销量 | 年龄 | 性别 |
举个栗子🌰:
口头描述:这家店生意很好
数据描述:这家店昨天的营业额是16000元
数据指标:昨日营业额
数据指标,需要有清晰的定义,举个栗子🌰:
昨日营业额 这个数据指标怎么描述
数据指标:昨日营业额
统计时间:昨日00:00-23:59
数据来源:店铺POS机交易流水
数据计算:POS记录的交易订单(不含退货单) 的 金额汇总
再举个栗子🌰:
7日留存率 这个数据指标怎么描述
数据指标:7日留存率
统计时间:7天内的数据
数据来源:app登录数据
数据计算:留存率=某范围活跃用户数在第N日仍启动该App的用户数的占比
数据描述:比如8.2号新注册的用户在8.9号之前又再次登录的数据
数据指标、标签、维度的区别
数据指标 VS 标签 VS 维度
数据指标的作用上文已经说过,是数据对事物进行描述的工具
数据指标:昨日营业额(昨日营业额16000元)
标签是什么,举个栗子🌰:
是为了描述事物、区分事物的某种缩略代指。比如(百年)老店、新店(开业)中的老店和新店就是标签。
任何描述性的文本,都可以作为标签。它可以是成语,也可以是词语,也可以是不完整的句子。
甚至也可以是形象、图片、符号,也能是标签。一个笑脸、一个红心、一个太阳就能代表很多很多,一图胜千言。当然,每个人都有自己的解读。
标签和维度值的概念重叠度比较高。
数据指标:昨日营业额(昨日营业额16000元)
标签:店铺类型(旗舰店/社区店、老店/新店)
什么是维度,,举个栗子🌰:
物以类聚人以群分,一个自然而然的逻辑是:先有物和人,再有类和群。
这里的物和人就是 标签,但人又分为傣族人,汉族人,白种人,这个就是群,人按照群分就是维度。
建立维度,其实是归纳归类,继续做了一层抽象。
最简单的维度,是二元的:是/否。比如,测过核酸 / 没测过核酸。
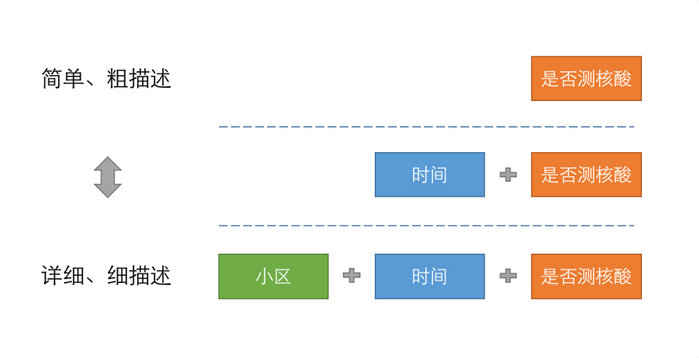
维度是灵活变通的,可以持续细化,不同维度可以相互组合的。
为了讲清楚维度,我不得不再引入一个相关的词,粒度。
粒度,其实就是描述事物、事情过程的细致程度。
为了更细粒度的分类描述,我们可以利用更多不同的前后缀修饰词创建新的维度。
就拿测核酸这个事情来举例。,举个栗子🌰:
假如一开始只区分是否测过核酸,后来病毒持续演进,抗疫成了持久战,后来开始区分时间:近30天、近7天、近3天是否测过核酸。
后续为了更加精细化防控,再加上来小区的维度,那就变成:A 小区近 7 天是否测过核酸、B 小区近 3 天是否测过核酸。
维度之间也可以合并和归总。
正向可以,反之亦然,我们也可以将细粒度的维度合并成更粗的维度。
如果一开始就高瞻远瞩,基于现实情况,设定了较为贴切的粒度,将统计的维度设置为近N天、小区、是否测核酸。
后续抗疫效果显著,粒度不需要再那么细,只需要按照月份、城市进行统计的时候,这些维度也可以归总:月份、城市、是否测过核酸。
维度的下钻和上卷
按照很多文章的说法,这个两个模块叫做维度的下钻和上卷。
但是,下钻和上卷比较抽象,我比较建议大家通过实际例子来构建自己的理解。
其实可以看到,维度和粒度之间相互影响、相互解释:维度越多,粒度越细。
为了方便,也可以将常见的特别细粒度的维度组合,合并成一个新的维度进行统称。
任何维度的设定,以及维度的下钻和上卷,都是基于我们想了解什么粒度的信息。
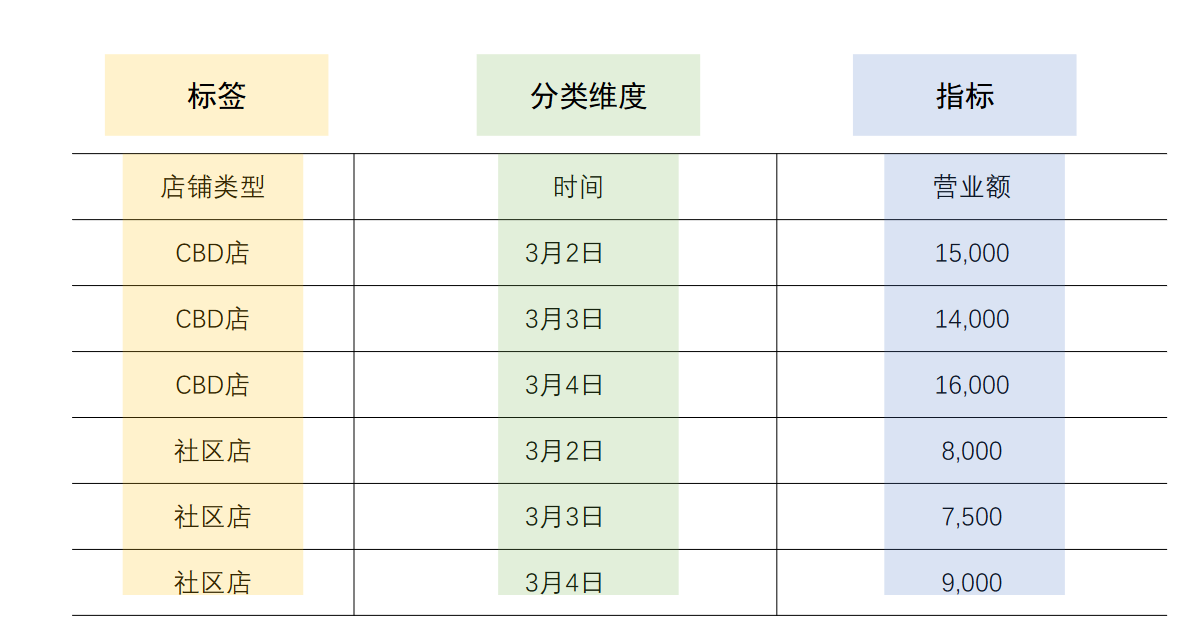
标签 分类维度 指标
一般指标指的是连续型的数据,
而标签指的是有业务含义的分类数据
标签可以通过指标计算得到,比如老店:开业时间>=24个月的店
标签是有强业务含义、强业务指向性的分类维度
如何得到数据指标
数据指标是事务的数据描述,所以……
1.对象是谁?
2.想描述他哪方面东西?
3.有没有数据记录?
举个栗子🌰:
| 我要找对象 | 我要找搬运工 | |
|---|---|---|
| 对象 | 男人 | 男人 |
| 哪方面 | 高富帅 | 信用卡、收费合理 |
| 数据记录 | 高:直接测量 富:信用卡?车?房产证 帅:主管评分 | 信用好:中介评分、完成订单数 收费合理:收费金额 |
注意!同一个目标,也会有不同判断,举个栗子🌰:
| 我要找对象 | 我要找对象 | |
|---|---|---|
| 对象 | 男人 | 男人 |
| 哪方面 | 高富帅 | 对我好 |
| 数据记录 | 高:直接测量 富:信用卡?车?房产证 帅:主管评分 | 给我钱用 帮我干活 |
从单个数据指标到指标体系
当一个指标,不足以描述事务的时候,需要指标体系
在指标体系中,数据之间有三种关系
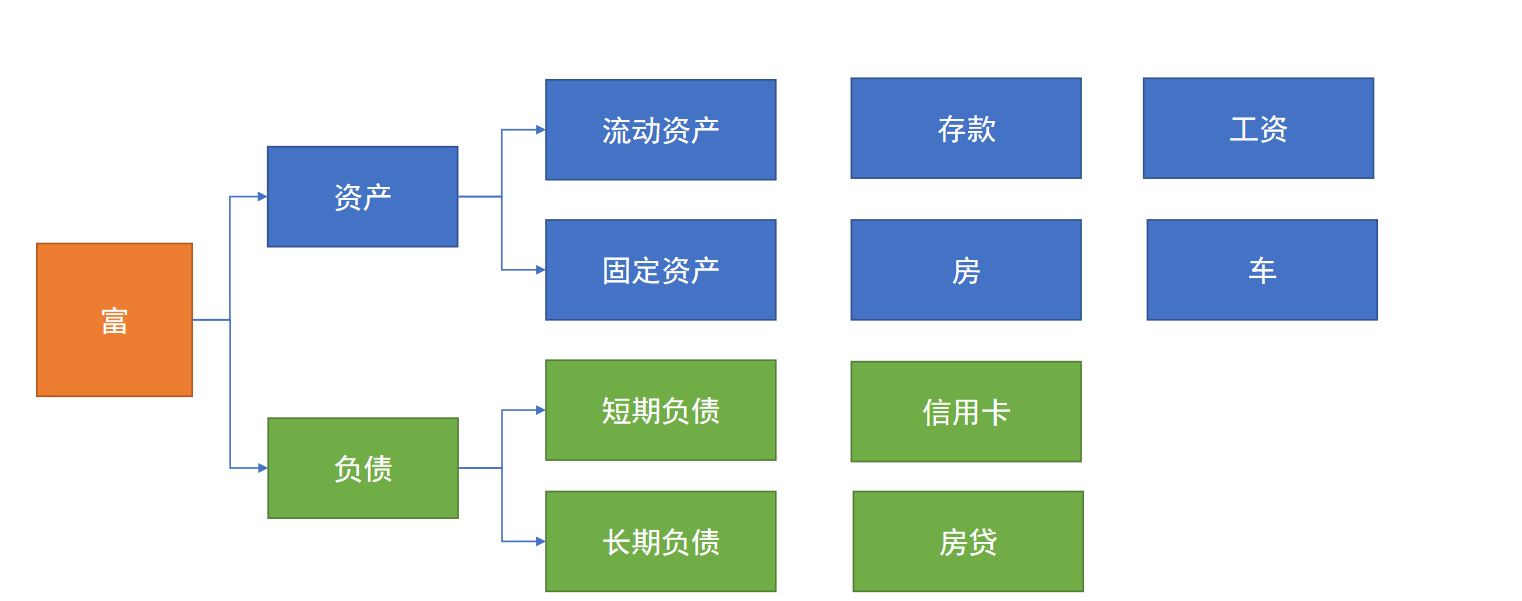
并列关系(没有关系):高、富、帅
包含关系:财产= 流动财产+固定财产,流动财产=收租房间数*租金
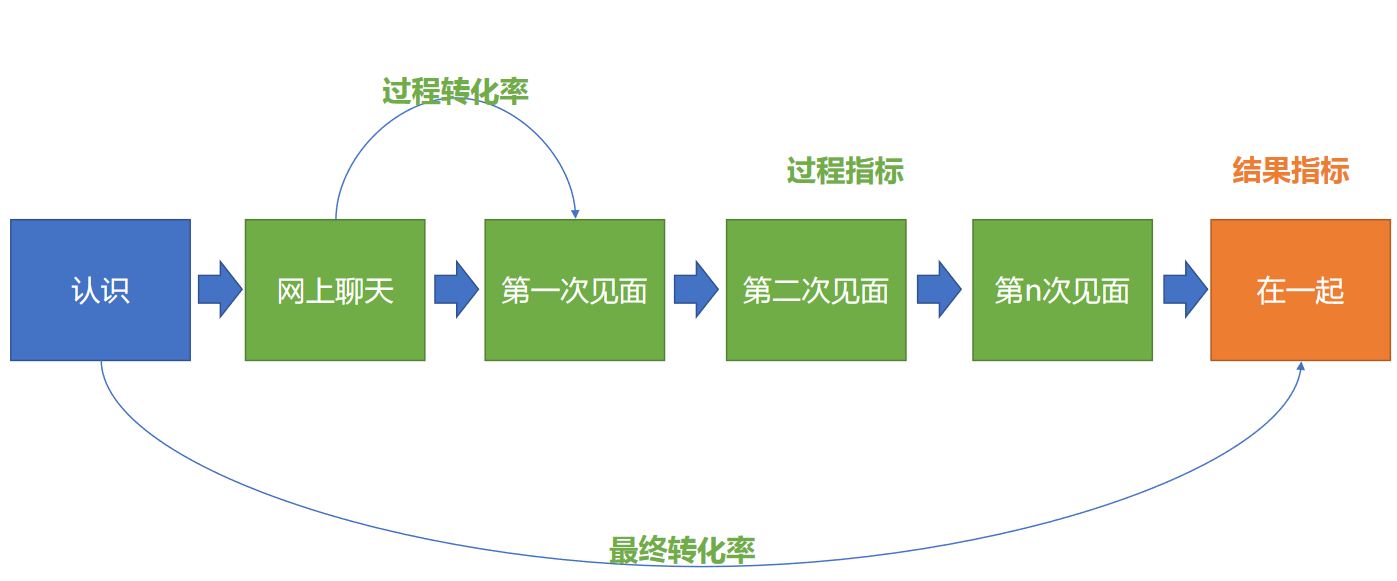
流程关系:他对我感兴趣 → 聊天 → 约会 → 表白 →结婚
包含关系

在流程关系中,有过程/结果指标的区别
所谓建立指标体系,就是……
1.锁定一个观察对象
2.明确一个目标:我想了解它的XX
3.收集相关指标,确认有数据可采集
4.按并列、包含、流程,把指标组织好
5.进行观察,得到我想要的结论
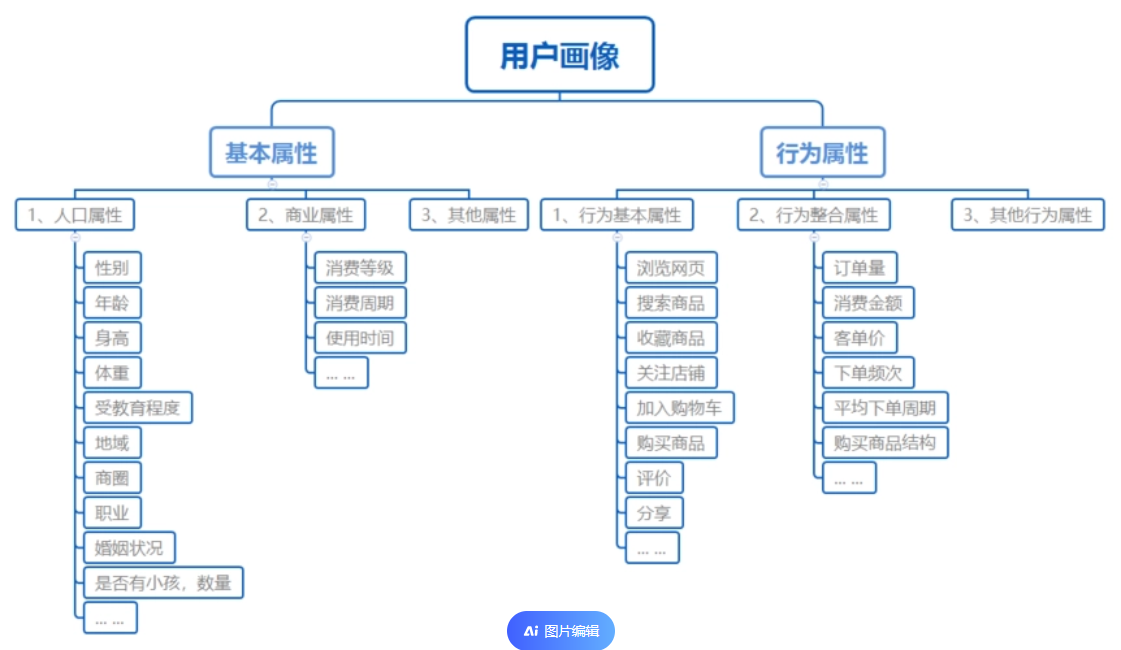
用户画像指标体系
这篇关于指标体系构建-01-什么是数据指标的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






