本文主要是介绍机器学习-逻辑回归(LogisticRegression)详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前言
PS:下面基本都是个人理解,肯定有不正确或者不严谨的地方,参考指正。
为了方便理解,不想加什么公式,就直接用白话文和举例说明。
机器学习的基本框架是:模型、目标和算法。不管做什么 都绕不开这个框架。
首先我们在拿到一份数据做预测的时候(暂且就做二分类预测),我们发现因变量(Y)是一个二分类(只有0和1),在我们不知道有其他模型的前提下,我们只会用LogisticRegression。随之而来的就是我们就要有一个解决问题的思路,来最后求出最优的结果,达到最好的输出。
首先,我们确定了模型就是LogisticRegression。
然后用这个模型去分类,让结果达到最优(除去理想情况,预测出来的结果跟实际肯定有误差的,就跟你写代码肯定会有BUG一样[狗头]),这个就是我们的目标,检验结果是否为最优的函数为目标函数,这个目标我们是通过极大似然估计出来的。举例:线性回归中我们的目标函数是最小二乘的问题,那么逻辑回归就是交叉熵,这个就是我们的目标。
最后当我们有了目标之后,我们需要一种算法了来实现这个目标,因为实现了目标之后我们就有了最优的结果,而在逻辑回归里面优化的算法就是梯度下降、牛顿法等等。而回归问题中我们可以用最小二乘法、梯度下降等等(为什么逻辑回归不能用最小二乘法,因为带入公式之后,然后在画个图你会发现出来个凸函数)。
在举个例子:就是你想出去旅游,地方比较远。那么你准备坐飞机(这个飞机就是个模型),确定好坐飞机之后,你得买飞机票把。买飞机票你得考虑时间、价格和航空公司等等。那么好,你研究出来了一套买票的方式方法,就是在价格合适,时间也合适,航空公司服务也不错,你想买这样的飞机票去旅游,这个就是目标。如果你实现了这个目标,那么最后你就会买到你认为最合适的飞机票对把,而实现了这个目标的过程,实现这个过程你肯定要货比三家,来回衡量对把,就是算法。当然实现这个过程肯定有很多种方式,但是这里面肯定有最优的方式,时间更短,效率更高,结果更好,这个就是最优算法。
这个就是不用sklearn调包,你自己想写个逻辑回归的大致思路,当然你如果调用sklearn你只需要调调参数,看看最后的指标你能不能接受就好了。
下面就简单介绍下逻辑回归,不对的地方请指正。
1.什么是逻辑回归
逻辑回归是监督学习,主要解决二分类问题。
逻辑回归虽然有回归字样,但是它是一种被用来解决分类的模型,为什么叫逻辑回归是因为它是利用回归的思想去解决了分类的问题。
逻辑回归和线性回归都是一种广义的线性模型,只不过逻辑回归的因变量(Y)服从伯努利分布(离散分布),而线性回归的因变量(Y)满足的是高斯分布(正态分布),因此他们两个是很相似的(PS:线性回归是拟合一条直线,而逻辑回归是根据sigmoid将线性变成非线性,所以去掉sigmoid,他们是一样的)。
所以理论上线性回归也可以用于做分类预测,但是准确率很低,效果很差,所以我们引用sigmoid函数将线性变成非线性来解决该类问题。
总结:辑回归假设数据服从伯努利分布,通过极大似然函数的方法,运用梯度下降来求解参数,最终达到数据二分类的目的。
2.逻辑回归适用场景
LogisticRegression 主要适用于二分类问题,如果因变量Y是二分类,可以考虑适用LogisticRegression模型求解。
3.sigmoid函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数。
sigmoid函数公式如下:
![]()
其中z是一个线性组合,比如z可以等于:b+![]() *
*![]() +
+![]() *
*![]() 或 z=
或 z=。通过代入很大的正数或很小的负数到g(z)函数中可知,其结果趋近于0或1。因此,sigmoid函数g(z)的图形表示如下(横轴表示定义域z,纵轴表示值域g(z))。
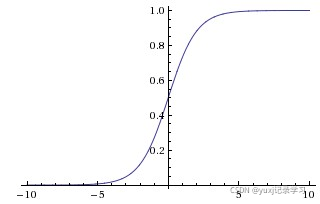
压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
4.选定阈值
其实使用逻辑回归来预测分类问题,最后结果不是0或者是1,而是0-1之间的数,sigmoid默认情况是将0.5以上的都归为正例,0.5以下都归为负例,但是这样是不准确的。因为0.49它还是有49%的概率为正例的。就算我们认为0.1是负类,0.1还是有10% 的可能是正类,所以无论怎么选择,都有误差的,我们要做的就是尽量的减少误差。
因为我们不管使用什么方式 求解,最后的结果都是0-1之间数,而不是0或1。有的人认为只需要确定好阈值那么我们就能找到最优解,但是实际上不应该这么想,我们要做的在这个方程中
z=
求出最优的W值,然后在根据最优W值的方法来确定确定阈值。
5.似然函数
最大似然估计就是通过已知结果去反推最大概率导致该结果的参数。极大似然估计是概率论在统计学中的应用,它提供了一种给定观察数据来评估模型参数的方法,即 “模型已定,参数未知”,通过若干次试验,观察其结果,利用实验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。逻辑回归是一种监督式学习,是有训练标签的,就是有已知结果的,从这个已知结果入手,去推导能获得最大概率的结果参数,只要我们得出了这个参数,那我们的模型就自然可以很准确的预测未知的数据了。
6.梯度下降
当我们确定了目标之后,我们就需要一个算法来解决问题,现在最常用也比较好用的就是梯度下降。
我们先来看看官网是怎么介绍梯度下降的:梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
大白话理解:就是你现在蒙眼在山顶要下山。你肯定要顺着山的一侧一步一步的往下挪是把,山的一侧就是梯度的,你每往下挪一点,就是在下降,当你达到山底的时候就成功了。
稍微专业点的:我们对一个多元函数求偏导,会得到多个偏导函数.这些导函数组成的向量,就是梯度.我们用梯度下降是用来求解一个损失函数的最小值,所谓下降实际上是这个损失函数的值在下降。
PS:导数的概念:
y=ax+b,我们知道这个函数的图像是一条直线,每个不同的x对应着直线上一点y.那么当自变量x的值变化的时候,y值也会随之变化.数学中我们把x的变化量成为Δx,把对应的y的变化量成为Δy,自变量的变化量Δx与因变量的变化量Δy的比值称为导数.记作y'。y'=Δy/Δx
在梯度下降的算法中,还有两个比较重要的点叫做学习率和步数。
学习率是指你在下山的过程中每走的一步大小,你要是厉害能一步跨到山底也算是你厉害,当然你也有可能跨到对面山上,所以学习率我们在设置的时候就要设置的稍微小点,别让计算机在计算的过程中扯着蛋了,当然也别太小了,这样学习的会很慢。学习率是自己设定的,比如0.01。
迭代次数就是指你在下山过程中你要走多少步,小了的话你可能没有走到山底,多了的话可能你就会在山底来回的走。
学习率和迭代次数都是自定义的,需要通过经验和实际操作去验证和设置。最好在运行代码的时候打印出来,这个就会看到收敛的情况,当很长一段时间内,收敛的效果已经不明显了,基本就到头了。
下面简单说下推导过程:
我减少了推导的数学公式,只有几个比较重要点的公式:
首先第一个公式 就是sigmoid,上面也提到过,其中的z就是线程方程:
![]()
上面也说了逻辑回归的本质也是个线性方程,只不过被sigmoid给掰弯了,所以我们还是得求z也就是所谓的
b+![]() *
*![]() +
+![]() *
*![]()
其中我们只要求出最优b和w的值是不是就可以了,所以先定义目标函数。目标函数
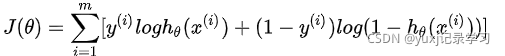
而梯度下降就是实现并求出最优的b和w值的其中一种算法,这个明白了把。
梯度下降有三种方法:
批量梯度下降BGD(Batch Gradient Descent):优点:会获得全局最优解,易于并行实现。缺点:更新每个参数时需要遍历所有的数据,计算量会很大并且有很多的冗余计算,导致当数据量大的时候每个参数的更新都会很慢。
随机梯度下降SGD:优点:训练速度快;缺点:准确率下降,并不是全局最优,不易于并行实现。它的具体思路是更新没一个参数时都是用一个样本来更新。(以高方差频繁更新,优点是使得sgd会跳到新的和潜在更好的局部最优解,缺点是使得收敛到局部最优解的过程更加的复杂)
small batch梯度下降:结合了上述两点的优点,每次更新参数时仅使用一部分样本,减少了参数更新的次数,可以达到更加稳定的结果,一般在深度学习中采用这种方法。
7.损失函数
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
通俗点讲,损失函数 = 代价函数 = 目标函数,它们三个是一个意思。
但是它们之间还是有细微的差别的。
损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
PS: 所以我理解的是损失函数和代价函数是一个意思。尤其是在深度学习中
目标函数:目标函数跟它俩有联系,但不是一个意思。目标函数是一个最优化函数,它是由经验风险+结构风险(也就是Cost Function + 正则化项)构成。
PS:比如说:我们需要优化模型,我们得有个目标把,比如说我们误差不能大于0.1 ,那这个0.1就是我们的目标函数,但是技术不行,最后只能把误差维持在0.2,那么0.1就是目标函数,0.2就是损失函数,当技术好的情况下,将误差降低在0.1 那么损失=目标。
下面介绍下 逻辑回归中常用的损失函数,逻辑回归主要是是分类模型,所以用的也都是分类方面的损失函数:
1)交叉熵损失:上面基本也都介绍了就不多说了。
2)Hinge Loss/多分类 SVM 损失:简言之,在一定的安全间隔内(通常是 1),正确类别的分数应高于所有错误类别的分数之和。因此 hinge loss 常用于最大间隔分类(maximum-margin classification),最常用的是支持向量机。尽管不可微,但它是一个凸函数,因此可以轻而易举地使用机器学习领域中常用的凸优化器。
8.Sklearn中LogisticRegression
现在开始介绍调包了,看这块的时候请忘记上面的流程,虽然内核一样,但是调包的话流程和思考的方式也是不同的。
上面1-7的说实在的,你如果数学和统计非常好,那么不建议你用sklearn,虽然结果可能会一样,但是你用sklearn可能会降低你的逼格,先说明,我就经常用sklearn。
from sklearn.linear_model import LogisticRegression
介绍下调包的流程:
数据准备:你拿了一堆数据,比如说预测肿瘤的,20个特征,特征中有连续和离散数据。
数据分析:主要是分析数据结构,需要处理的特征,变量衍生
数据处理:根据分析结果处理数据。
探索性分析:分析数据分布,主要以图表形式展示,自变量和因变量关系,相关性,共线性等等。
模型前特征处理,主要工作有
1.特征筛选
2.是否需要归一化或标准化,如果在前置数据的探索性分析中,我们知道特征变量满足正态分布,就是均值位0,标准差为 1 那么就标准化。在逻辑回归中应该是使用归一化数据。
3.拆分数据集,分成训练、测试和验证
训练模型:就开始整模型了,直接fit函数
模型诊断和调优:就是判断我们得出结果到底怎么样,比如分类问题我们可以通过一系列指标去验证,比如混淆矩阵、roc、auc和ks等等,如果不好调优模型
模型部署:最后没啥问题了 就上线模型。
9.Sklearn中LogisticRegression参数
为什么将参数,因为想模型调优有2个方面一个是数据,
记住一句话,数据是决定上限的,而模型算法只在让你更逼近这个上限。数据差,你的模型算法在牛,结果也不能好了。所以调优一方面调优数据,另一方面在sklearn中调优的就是参数了
官网网址:
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegressionLogisticRegression 方法
class sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None) 挑一些重要的说,不说的表示默认项就行了
penalty:惩罚项(也叫正则项),str类型,可选参数为l1和l2,默认为l2,用于指定惩罚项中使用的规范。penalty参数主要的作用有:解决过拟合,但是一般情况使用l2就够了,如果l2不行了在使用l1。
l1:规范假设的是模型的参数满足拉普拉斯分布,l1范式表现为参数向量中的每个参数的绝对值之和,如果选择l1那么solver参数只能选择liblinear和saga,因为L1正则化的损失函数不是连续可导的。而其他算法优化算法时都需要损失函数的一阶或者二阶连续导数。
l2:L2假设的模型参数满足高斯分布,l2范数表现为参数向量中的每个参数的平方和的开方值,如果选择l2那么solver参数都可以用。
所谓的范式就是加上对参数的约束,使得模型更不会过拟合(overfit),但是如果要说是不是加了约束就会好,这个没有人能回答,只能说,加约束的情况下,理论上应该可以获得泛化能力更强的结果。
C:正则化强度的倒数,必须是一个大于0的浮点数,不填写默认1.0,即默认正则项与损失函数的比值是1:1。C越小,损失函数会越小,模型对损失函数的惩罚越重,正则化的效力越强,参数会逐渐被压缩得越来越小。
solver:优化算法选择参数,有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear(在0.22版本之后默认的liblinear修改成了lbfgs)。solver参数决定了对逻辑回归损失函数的优化方法:
liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。小数据集效果比较好,Changed in version 0.22: The default solver changed from ‘liblinear’ to ‘lbfgs’ in 0.22.
lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅用一部分的样本来计算梯度,适合于样本数据多,数据集比较大的时候(PS:建议哈,超过10w的数据可以用,也最好用sag),样本少的话就不药用
saga:快速梯度下降法,线性收敛的随机优化算法的的变种,适合于样本数据多,数据集比较大的时候。0.19版本后才有的,L1也能用。
sag”和“saga”快速收敛仅在具有大致相同比例的要素上得到保证, 可以使用sklearn.preprocessing中的缩放器预处理数据。
从上面的描述,大家可能觉得,既然newton-cg, lbfgs和sag这么多限制,如果不是大样本,我们选择liblinear不就行了嘛!错,因为liblinear也有自己的弱点!我们知道,逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种。而MvM一般比OvR分类相对准确一些。郁闷的是liblinear只支持OvR,不支持MvM,这样如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能使用L1正则化了。
这个参数的设置是不是很眼熟,其实就上面的实现目标的算法,换句话说,你可以直接调包的过程中就使用优化算法,来实现目标函数,结果就是该算法下的最优解。
max_iter:算法收敛最大迭代次数,int类型,默认为100。仅在正则化优化算法为newton-cg, sag和lbfgs才有用,算法收敛的最大迭代次数。下山的步数。
dual:对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
tol:停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候,停止,认为已经求出最优解。
class_weight:用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为不输入,也就是不考虑权重,即为None。如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者自己输入各个类型的权重。举个例子,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9,1:0.1},这样类型0的权重为90%,而类型1的权重为10%。如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3]。
那么class_weight有什么作用呢?
在分类模型中,我们经常会遇到两类问题:
第一种是误分类的代价很高。比如对合法用户和非法用户进行分类,将非法用户分类为合法用户的代价很高,我们宁愿将合法用户分类为非法用户,这时可以人工再甄别,但是却不愿将非法用户分类为合法用户。这时,我们可以适当提高非法用户的权重。
第二种是样本是高度失衡的,比如我们有合法用户和非法用户的二元样本数据10000条,里面合法用户有9995条,非法用户只有5条,如果我们不考虑权重,则我们可以将所有的测试集都预测为合法用户,这样预测准确率理论上有99.95%,但是却没有任何意义。这时,我们可以选择balanced,让类库自动提高非法用户样本的权重。提高了某种分类的权重,相比不考虑权重,会有更多的样本分类划分到高权重的类别,从而可以解决上面两类问题。
multi_class:分类方式选择参数,str类型,可选参数为ovr和multinomial,默认为ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
OvR和MvM有什么不同*?*
OvR的思想很简单,无论你是多少元逻辑回归,我们都可以看做二元逻辑回归。具体做法是,对于第K类的分类决策,我们把所有第K类的样本作为正例,除了第K类样本以外的所有样本都作为负例,然后在上面做二元逻辑回归,得到第K类的分类模型。其他类的分类模型获得以此类推。
而MvM则相对复杂,这里举MvM的特例one-vs-one(OvO)作讲解。如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类。
可以看出OvR相对简单,但分类效果相对略差(这里指大多数样本分布情况,某些样本分布下OvR可能更好)。而MvM分类相对精确,但是分类速度没有OvR快。如果选择了ovr,则4种损失函数的优化方法liblinear,newton-cg,lbfgs和sag都可以选择。但是如果选择了multinomial,则只能选择newton-cg, lbfgs和sag了。
当确定了使用的模型,如果调整参数达到最优效果请看这里
10.模型指标
得出结果后,我们需要一些指标来验证你的结果怎么样,大致有混淆矩阵、R2、ROC、AUC、KS等等指标,以后会专门写这个,这个暂时就空着。
这篇关于机器学习-逻辑回归(LogisticRegression)详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







