本文主要是介绍gem5 RubyPort: mem_request_port作用与连接 simple-MI_example.py,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
回答这个问题:RubyPort的口下,一共定义了六个口,分别是mem_request_port,mem_response_port,pio_request_port,pio_response_port,in_ports, interrupt_out_ports,他们分别有什么用,应该怎么接
overview是下面这个图。
以一个简单的l1 cache为例子
https://www.gem5.org/documentation/learning_gem5/part3/simple-MI_example/
首先是l1cache对子函数的连接
class L1Cache(L1Cache_Controller):。。。def connectQueues(self, ruby_system):。。。self.mandatoryQueue = MessageBuffer()self.requestFromCache = MessageBuffer(ordered = True)self.requestFromCache.master = ruby_system.network.slaveself.responseFromCache = MessageBuffer(ordered = True)self.responseFromCache.master = ruby_system.network.slaveself.forwardToCache = MessageBuffer(ordered = True)self.forwardToCache.slave = ruby_system.network.masterself.responseToCache = MessageBuffer(ordered = True)self.responseToCache.slave = ruby_system.network.master
然后是system对子函数的连接操作
step 1对一个RubySystem延伸的类,他的controller是python自己定义的。
step 2 这里它简化了一下,只有一个dir controller,也就是只有一个memory ctrl,但是 l1cache还是每个cpu都有一个的。
step3 创建了self.controller之后,并没有互联! 这个rubysystem调用了自己的子类的子函数连接了网络和controllers。
step4 显式的连接cpu 与ruby system的 sequencer。
#step 1
class MyCacheSystem(RubySystem):#step 2 self.controllers = [L1Cache(system, self, cpu) for cpu in cpus] + [ DirController(self, system.mem_ranges, mem_ctrls) ]#step 3self.network.connectControllers(self.controllers)#step 4# Connect the cpu's cache, interrupt, and TLB ports to Rubyfor i,cpu in enumerate(cpus):cpu.icache_port = self.sequencers[i].slavecpu.dcache_port = self.sequencers[i].slaveisa = buildEnv['TARGET_ISA']if isa == 'x86':cpu.interrupts[0].pio = self.sequencers[i].mastercpu.interrupts[0].int_master = self.sequencers[i].slavecpu.interrupts[0].int_slave = self.sequencers[i].masterif isa == 'x86' or isa == 'arm':cpu.itb.walker.port = self.sequencers[i].slavecpu.dtb.walker.port = self.sequencers[i].slave
然后我们看看每一步怎么连接的细节:
step3 network.connectControllers(self.controllers)
先看看前置的一些条件
这里的self.controllers 创建了64个L1缓存控制器,每个控制器对应一个CPU,加上一个目录控制器。因此,controllers 列表总共包含65个控制器。
这里有一个不是很常规的情况:每个router连接了一个controller,也就是有65个router。正常应该是64个router对应64个cpu的,这里为了简便,直接每个controller分配一个router。同时,router间的互连也简化为crossbar,每个router连接了剩下所有的64个 router
# Create one router/switch per controller in the systemself.routers = [Switch(router_id = i) for i in range(len(controllers))]#outer间的互连也简化为crossbar,每个router连接了剩下所有的router,例如64个routerfor ri in self.routers:for rj in self.routers:if ri == rj: continue # Don't connect a router to itself!link_count += 1self.int_links.append(SimpleIntLink(link_id = link_count,src_node = ri,dst_node = rj))
这些前置条件过后,看怎么连接controller和router的:
def connectControllers(self, controllers):"""Connect all of the controllers to routers and connect the routerstogether in a point-to-point network."""# Create one router/switch per controller in the systemself.routers = [Switch(router_id = i) for i in range(len(controllers))]# Make a link from each controller to the router. The link goes# externally to the network.self.ext_links = [SimpleExtLink(link_id=i, ext_node=c,int_node=self.routers[i])for i, c in enumerate(controllers)]# Make an "internal" link (internal to the network) between every pair# of routers.link_count = 0self.int_links = []for ri in self.routers:for rj in self.routers:if ri == rj: continue # Don't connect a router to itself!link_count += 1self.int_links.append(SimpleIntLink(link_id = link_count,src_node = ri,dst_node = rj))
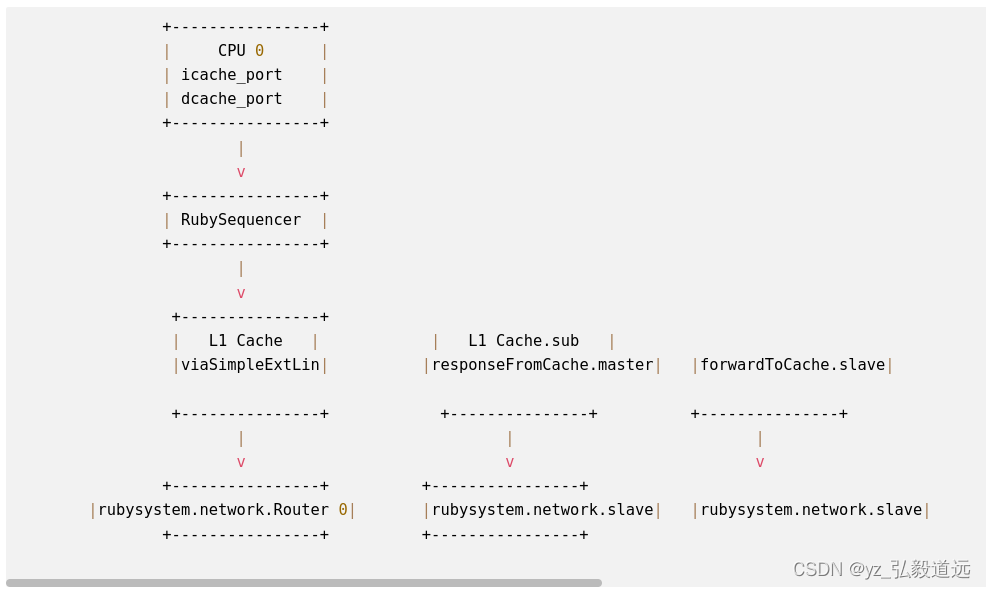
把这些代码画成图如下:
+----------------+| CPU 0 || icache_port || dcache_port |+----------------+|v+----------------+| RubySequencer |+----------------+|v+---------------+| L1 Cache | | L1 Cache.sub | |viaSimpleExtLin| |responseFromCache.master| |forwardToCache.slave| |responseToCache.slave|+---------------+ +---------------+ +---------------+ +---------------+ | | | |v v v v+----------------+ +----------------+ |rubysystem.network.Router 0| |rubysystem.network.slave| |rubysystem.network.slave| |ruby_system.network.master | +----------------+ +----------------+ ... (多个类似的组件重复上述连接关系) ...+----------------+| CPU 63 || icache_port || dcache_port |+----------------+|v+----------------+| RubySequencer |+----------------+|v+---------------+| L1 Cache |+---------------+|v+----------------+| Router 63 |+----------------+第65个router比较特殊,在这个简化的实例里没有连接l1而是连接了dircontroller.同时每个router之间都是连接的。+----------------+| Router 64 |+----------------+^ || v+----------------+| DirController|+----------------+
代码和图联合 分析
按照https://www.gem5.org/documentation/learning_gem5/part3/simple-MI_example/ 的顺序,
连接l1 cache与router
rubysystem 创建了一堆controller,随后创建了sequencer但是还没连,然后调用network。connectController连接了controlle和router,
# Create the network and connect the controllers.# NOTE: This is quite different if using Garnet!self.network.connectControllers(self.controllers)self.network.setup_buffers()
也就是 l1cache和network.router通过simpleextlink相连的。
l1cache和network.router通过simpleextlink相连的。
连接cpu 与sequencer
随后,rybysystem 显式的连接了之前创建的sequence和 cpu的interrupt 和itb.walker.port.
# Connect the cpu's cache, interrupt, and TLB ports to Rubyfor i,cpu in enumerate(cpus):cpu.icache_port = self.sequencers[i].slavecpu.dcache_port = self.sequencers[i].slaveisa = buildEnv['TARGET_ISA']if isa == 'x86':cpu.interrupts[0].pio = self.sequencers[i].mastercpu.interrupts[0].int_master = self.sequencers[i].slavecpu.interrupts[0].int_slave = self.sequencers[i].masterif isa == 'x86' or isa == 'arm':cpu.itb.walker.port = self.sequencers[i].slavecpu.dtb.walker.port = self.sequencers[i].slave
图里也就是连接这一部分:
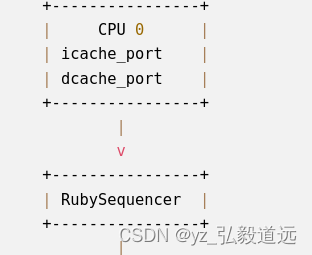
连接l1cache 和rubysystem.networ
这里是隐藏在l1初始化的时候,创建l1cache需要初始化,(对这个python文件)初始化的时候l1cache就传递进来了rubysystem这个对象。
self.connectQueues(ruby_system)
然后l1cache连接了rubyssytem的master和slaveport.现在叫out_port 和in_port 。
def connectQueues(self, ruby_system):"""Connect all of the queues for this controller."""self.mandatoryQueue = MessageBuffer()self.requestFromCache = MessageBuffer(ordered = True)self.requestFromCache.master = ruby_system.network.slaveself.responseFromCache = MessageBuffer(ordered = True)self.responseFromCache.master = ruby_system.network.slaveself.forwardToCache = MessageBuffer(ordered = True)self.forwardToCache.slave = ruby_system.network.masterself.responseToCache = MessageBuffer(ordered = True)self.responseToCache.slave = ruby_system.network.master#小插曲: master和slave的说法已经被弃用了 by src/mem/ruby/network/Network.py#in_port = VectorResponsePort("CPU input port")#slave = DeprecatedParam(in_port, "`slave` is now called `in_port`")#out_port = VectorRequestPort("CPU output port")#master = DeprecatedParam(out_port, "`master` is now called `out_port`")
图里是这一部分,描述的l1的cache的子成员直接和network相连。

关键问题:这些port结构连上了,但是属于哪些类型的rubyport?
rubyport。hh里有六种类型,这些结构上相连的port各自属于哪些类型? 我们一个个搜索从结构上看过来
RubySequencer
代码用的self.sequencers[i].master/slave,其中 self.sequencers = [RubySequencer(version = i,。。。
RubySequencer 从哪里来的呢?
在src/mem/ruby/system/Sequencer.py找到了 RubySequencer的定义:
class RubySequencer(RubyPort):type = "RubySequencer"cxx_class = "gem5::ruby::Sequencer"cxx_header = "mem/ruby/system/Sequencer.hh"
RubySequencer 不是Sequencer: python与c++的关系。
细看会发现,我们用的是 RubySequencer 不是Sequencer ,RubySequencer是python的class,他的type是cpp里的"gem5::ruby::Sequencer"。还告诉我们用的头文件是 “mem/ruby/system/Sequencer.hh”。
cpp Sequencer.hh 没有
先看src/mem/ruby/system/Sequencer.hh 中,
class Sequencer : public RubyPort
所以Sequencer 其实是继承自RubyPort的。而RubyPort继承自clockedobject.
这俩都没有.slave 子成员。 那我们的python代码调用的slave来自于哪里?
RubyPort的python定义
对rubyport最关键的代码出现了:src/mem/ruby/system/Sequencer.py
没错,竟然没有一个单独的python文件 RubyPort.py 而是在 Sequencer.py里。
step1 这个代码把c++和python联系起来了。
step2 这个代码创建了新的python里的名字
- in_port同时也是弃用的slave
- interrupt_out_port同时也是弃用的master
- pio_request_port同时也是弃用的 pio_master_port
- mem_request_port 同时也是弃用的mem_master_port
- pio_response_port 同时也是弃用的pio_slave_port
class RubyPort(ClockedObject):type = "RubyPort"abstract = Truecxx_header = "mem/ruby/system/RubyPort.hh"cxx_class = "gem5::ruby::RubyPort"version = Param.Int(0, "")in_ports = VectorResponsePort("CPU side of this RubyPort/Sequencer. ""The CPU request ports should be connected to this. If a CPU ""has multiple ports (e.g., I/D ports) all of the ports for a ""single CPU can connect to one RubyPort.")slave = DeprecatedParam(in_ports, "`slave` is now called `in_ports`")interrupt_out_port = VectorRequestPort("Port to connect to x86 interrupt ""controller to send the CPU requests from outside.")master = DeprecatedParam(interrupt_out_port, "`master` is now called `interrupt_out_port`")pio_request_port = RequestPort("Ruby pio request port")pio_master_port = DeprecatedParam(pio_request_port, "`pio_master_port` is now called `pio_request_port`")mem_request_port = RequestPort("Ruby mem request port")mem_master_port = DeprecatedParam(mem_request_port, "`mem_master_port` is now called `mem_request_port`")pio_response_port = ResponsePort("Ruby pio response port")pio_slave_port = DeprecatedParam(pio_response_port, "`pio_slave_port` is now called `pio_response_port`")
这些python的port和 c++port的定义
是python提供字符串描述,然后调用python通过名字找port的函数,然后cpp响应这个函数,返回对应的cpp对象。由此,python定义的port和c++的port联系起来。
下面是细节,分别是根据名字字符串 找port 的函数, c++对port名字的回应, 和这些port的对应关系。
根据名字字符串 找port 的函数
在src/python/m5/params.py中
class RequestPort(Port):# RequestPort("description")def __init__(self, desc):super().__init__("GEM5 REQUESTOR", desc, is_source=True)
c++对port名字的回应
Port &
RubyPort::getPort(const std::string &if_name, PortID idx)
{if (if_name == "mem_request_port") {return memRequestPort;} else if (if_name == "pio_request_port") {return pioRequestPort;} else if (if_name == "mem_response_port") {return memResponsePort;} else if (if_name == "pio_response_port") {return pioResponsePort;} else if (if_name == "interrupt_out_port") {// used by the x86 CPUs to connect the interrupt PIO and interrupt// response portif (idx >= static_cast<PortID>(request_ports.size())) {panic("%s: unknown %s index (%d)\n", __func__, if_name, idx);}return *request_ports[idx];} else if (if_name == "in_ports") {// used by the CPUs to connect the caches to the interconnect, and// for the x86 case also the interrupt request portif (idx >= static_cast<PortID>(response_ports.size())) {panic("%s: unknown %s index (%d)\n", __func__, if_name, idx);}return *response_ports[idx];}// pass it along to our super classreturn ClockedObject::getPort(if_name, idx);
}
python port和 cpp port的对应关系:根据name返回
mem_request_port 和 memRequestPort
python 文件中,mem_request_port 是来自于 RequestPort(“Ruby mem request port”)
mem_request_port = RequestPort(“Ruby mem request port”)
查找返回的是 if (if_name == “mem_request_port”) { return memRequestPort;
pio_request_port和 pioRequestPort
python 文件中, pio_request_port = RequestPort(“Ruby pio request port”)
查找的cpp返回的是 else if (if_name == “pio_request_port”) { return pioRequestPort;
pio_response_port 和 pioResponsePort
python 文件中 pio_response_port = ResponsePort(“Ruby pio response port”)
查找的cpp返回的是 else if (if_name == “pio_response_port”) { return pioResponsePort;
interrupt_out_port 和*request_ports[idx]
python 文件中 pio_response_port = ResponsePort(“Ruby pio response port”)
查找的cpp返回的是 else if (if_name == “interrupt_out_port”) { // used by the x86 CPUs to connect the interrupt PIO and interrupt // response port if (idx >= static_cast(request_ports.size())) { panic(“%s: unknown %s index (%d)\n”, func, if_name, idx); }
in_ports 和 *response_ports[idx]
python 文件中 in_ports = VectorResponsePort( "CPU side of this RubyPort/Sequencer. " “The CPU request ports should be connected to this. If a CPU " “has multiple ports (e.g., I/D ports) all of the ports for a " “single CPU can connect to one RubyPort.” )
查找的cpp返回的是 else if (if_name == “in_ports”) { // used by the CPUs to connect the caches to the interconnect, and // for the x86 case also the interrupt request port if (idx >= static_cast(response_ports.size())) { panic(”%s: unknown %s index (%d)\n”, func, if_name, idx); } return *response_ports[idx];
这些python port(同时也代表c++port) 怎么连接的
核心是这些连接是由python文件定义,我们还是以 simple-MI_example.py为例子:
cpu和sequencer
# Connect the cpu's cache, interrupt, and TLB ports to Rubyfor i,cpu in enumerate(cpus):cpu.icache_port = self.sequencers[i].slavecpu.dcache_port = self.sequencers[i].slaveisa = buildEnv['TARGET_ISA']if isa == 'x86':cpu.interrupts[0].pio = self.sequencers[i].mastercpu.interrupts[0].int_master = self.sequencers[i].slavecpu.interrupts[0].int_slave = self.sequencers[i].masterif isa == 'x86' or isa == 'arm':cpu.itb.walker.port = self.sequencers[i].slavecpu.dtb.walker.port = self.sequencers[i].slave
cpu 与sequencer 的连接图
画成图就是

network 和 l1 dir
l1 连接l1的port和network
def connectQueues(self, ruby_system):"""Connect all of the queues for this controller."""self.mandatoryQueue = MessageBuffer()self.requestFromCache = MessageBuffer(ordered = True)self.requestFromCache.master = ruby_system.network.slaveself.responseFromCache = MessageBuffer(ordered = True)self.responseFromCache.master = ruby_system.network.slaveself.forwardToCache = MessageBuffer(ordered = True)self.forwardToCache.slave = ruby_system.network.masterself.responseToCache = MessageBuffer(ordered = True)self.responseToCache.slave = ruby_system.network.master
DirController 里,连接dir 的port和network
def connectQueues(self, ruby_system):self.requestToDir = MessageBuffer(ordered = True)self.requestToDir.slave = ruby_system.network.masterself.dmaRequestToDir = MessageBuffer(ordered = True)self.dmaRequestToDir.slave = ruby_system.network.masterself.responseFromDir = MessageBuffer()self.responseFromDir.master = ruby_system.network.slaveself.dmaResponseFromDir = MessageBuffer(ordered = True)self.dmaResponseFromDir.master = ruby_system.network.slaveself.forwardFromDir = MessageBuffer()self.forwardFromDir.master = ruby_system.network.slaveself.responseFromMemory = MessageBuffer()
## network 里,连接router和 l1以及dir
```pythonself.ext_links = [SimpleExtLink(link_id=i, ext_node=c,int_node=self.routers[i])for i, c in enumerate(controllers)]
network 里连接network.router 和conrollers
# Make a link from each controller to the router. The link goes# externally to the network.self.ext_links = [SimpleExtLink(link_id=i, ext_node=c,int_node=self.routers[i])for i, c in enumerate(controllers)]
network with routers 与l1, dir 的连接图
画成图就是
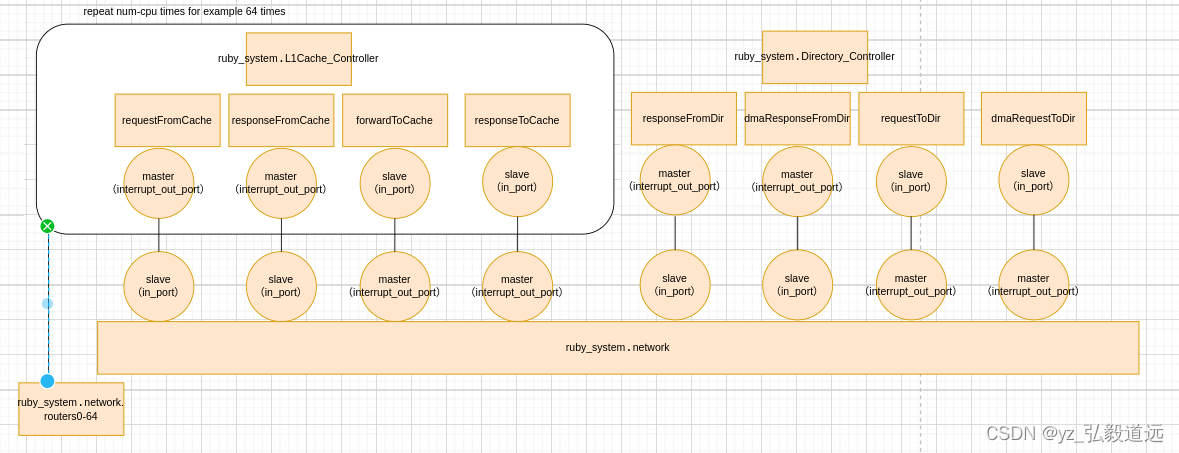
#小结
再把sequencer中的cacher和l1相连起来就全部串起来了
最后的总结图:
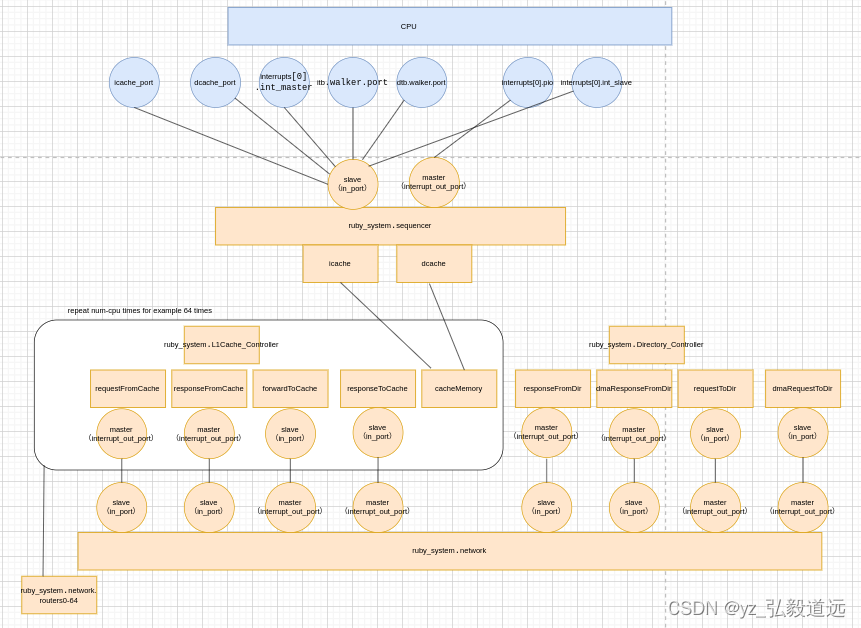
这篇关于gem5 RubyPort: mem_request_port作用与连接 simple-MI_example.py的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







