本文主要是介绍【K8s】3# 使用kuboard管理K8s集群(NFS存储安装),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.NFS是什么
- 2.配置NFS服务器
- 2.1.执行以下命令安装 nfs 服务器所需的软件包
- 2.2.执行命令 vim /etc/exports,创建 exports 文件,文件内容如下
- 2.3.执行以下命令,启动 nfs 服务
- 2.4.检查配置是否生效
- 3.在客户端测试NFS
- 3.1.执行以下命令安装 nfs 客户端所需的软件包(所有客户端节点)
- 3.2.执行以下命令检查 nfs 服务器端是否有设置共享目录
- 4.在Kuboard中创建 NFS 存储类
- 4.1.设置存储类
- 4.2.填写表单输入表单
- 4.1.在场景中使用存储类
1.NFS是什么
最完整的学习文档莫过于官网:直达地址:Kuboard for K8S
Kubernetes 对 Pod 进行调度时,以当时集群中各节点的可用资源作为主要依据,自动选择某一个可用的节点,并将 Pod 分配到该节点上。在这种情况下,Pod 中容器数据的持久化如果存储在所在节点的磁盘上,就会产生不可预知的问题,例如,当 Pod 出现故障,Kubernetes 重新调度之后,Pod 所在的新节点上,并不存在上一次 Pod 运行时所在节点上的数据。
为了使 Pod 在任何节点上都能够使用同一份持久化存储数据,我们需要使用网络存储的解决方案为 Pod 提供 数据卷。
常用的网络存储方案有:
- NFS
- cephfs
- glusterfs`。
本文介绍一种使用 centos 搭建 nfs 服务器的方法。此方法仅用于测试目的,请根据您生产环境的实际情况,选择合适的 NFS 服务。
2.配置NFS服务器
2.1.执行以下命令安装 nfs 服务器所需的软件包
yum install -y rpcbind nfs-utils
2.2.执行命令 vim /etc/exports,创建 exports 文件,文件内容如下
/root/nfs_root/ *(insecure,rw,sync,no_root_squash)
ro: 只读访问rw:读写访问sync 所有数据在请求时写入共享sync: nfs在写入数据前阻塞响应请求insecure: nfs通过1024以上的端口发送no_root_squash:不讲root用户及所属用户组映射为匿名用户或用户组,默认root是被映射为匿名用户的nfsnobody,所有即使开了rw写权限,客户机也使无法写入的,这个不映射为匿名用户,还保留原来的用户权限就可以读写了,因为一般都是用root用户登录的。注意:当客机是否有写权限时,还要看该目录对该用户有没有开放写入权限
2.3.执行以下命令,启动 nfs 服务
# 创建共享目录,如果要使用自己的目录,请替换本文档中所有的 /root/nfs_root/
mkdir /root/nfs_rootsystemctl enable rpcbind
systemctl enable nfs-serversystemctl start rpcbind
systemctl start nfs-server
exportfs -r
2.4.检查配置是否生效
exportfs
# 输出结果如下所示
/root/nfs_root <world>
exportfs 选项参数
-a:输出/etc/exports中设置的所有目录-r:重新读取/etc/exports文件中的设置,并且立即生效,而不需要重新启动NFS服务。-u:停止输出某一目录-v:在输出目录时,将目录显示在屏幕上。
- 修改vi /etc/exports后,不用重启服务,直接使用命令输出共享目录
exportfs -rv- 停止输出所有共享目录
exportfs -auv
3.在客户端测试NFS
3.1.执行以下命令安装 nfs 客户端所需的软件包(所有客户端节点)
yum install -y nfs-utils
3.2.执行以下命令检查 nfs 服务器端是否有设置共享目录
# showmount -e $(nfs服务器的IP)
showmount -e 192.168.33.106
输出结果:

showmount 参数选项 nfs服务器名称或地址
-a:显示指定的nfs服务器的所有客户端主机及其所连接的目录-d:显示指定的nfs服务器中已经被客户端连接的所有共享目录-e:显示指定的nfs服务器上所有输出的共享目录
- 查看所有输出的共享目录
showmount -e- 显示所有被挂载的所有输出目录
showmount -d
4.在Kuboard中创建 NFS 存储类
4.1.设置存储类
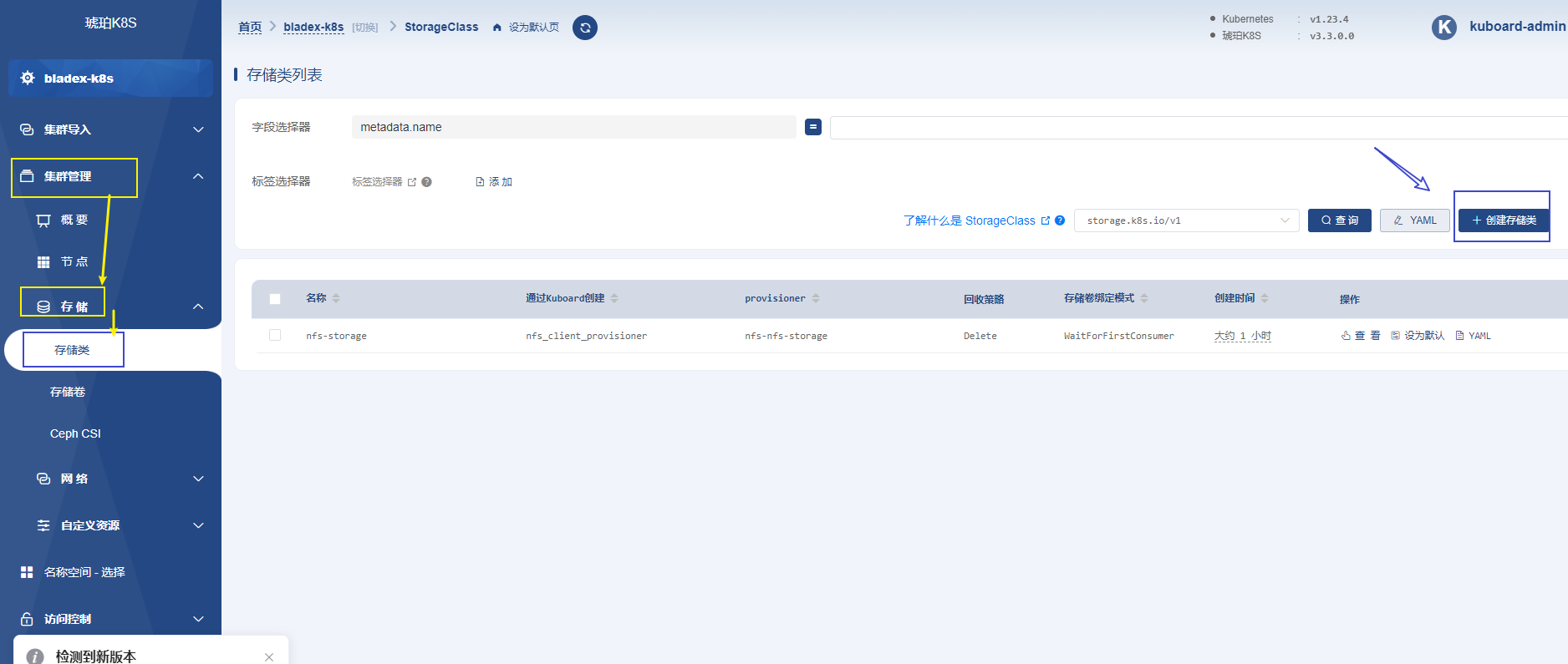
打开
Kuboard的集群概览页面,点击 创建存储类 按钮,如下图所示
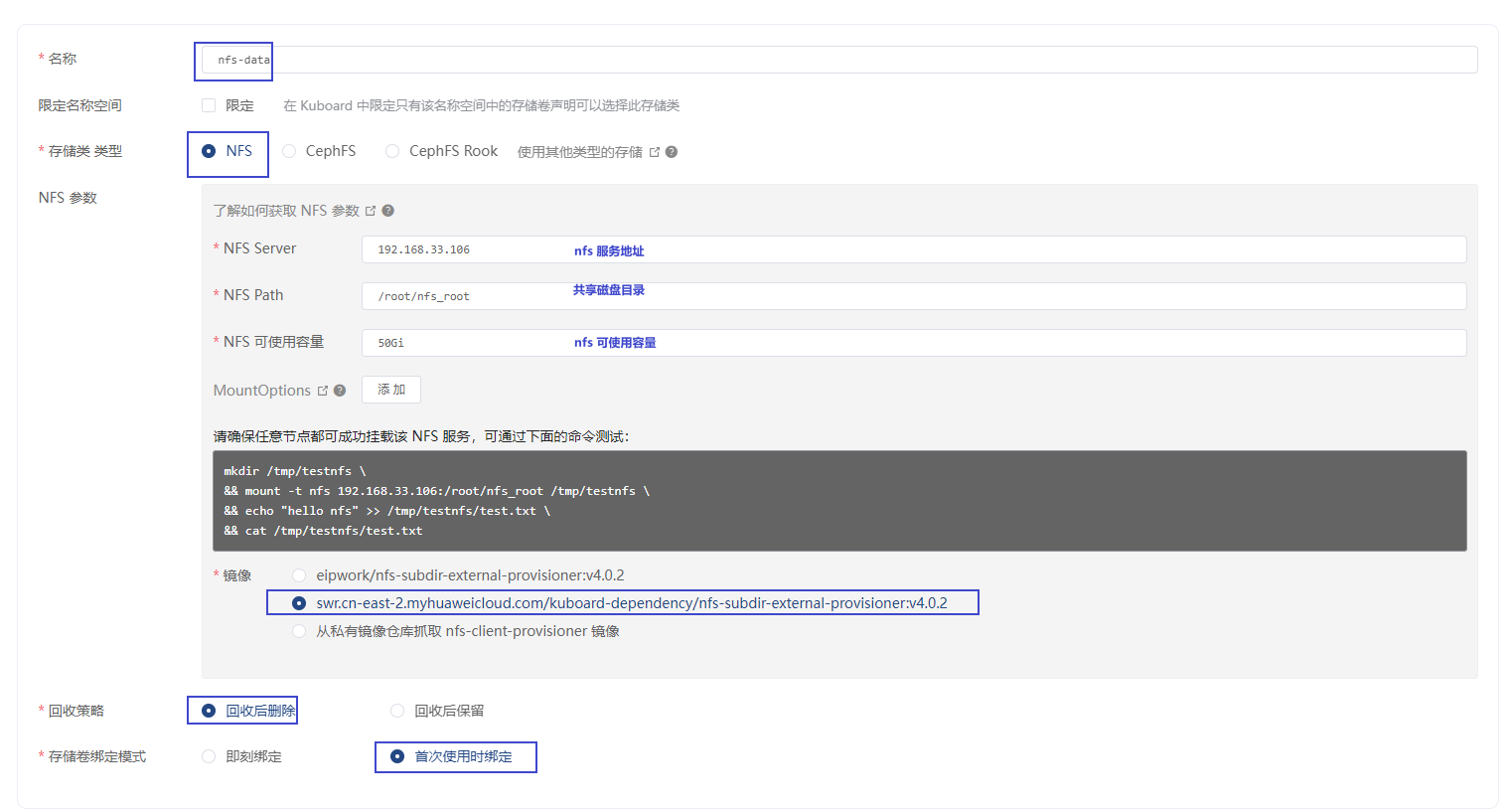
4.2.填写表单输入表单
名称nfs-storage 请自定义名称- NFS Server 172.17.216.82 请使用您自己的NFS服务的IP地址
- NFS Path /root/nfs_root 请使用您自己的NFS服务所共享的路径
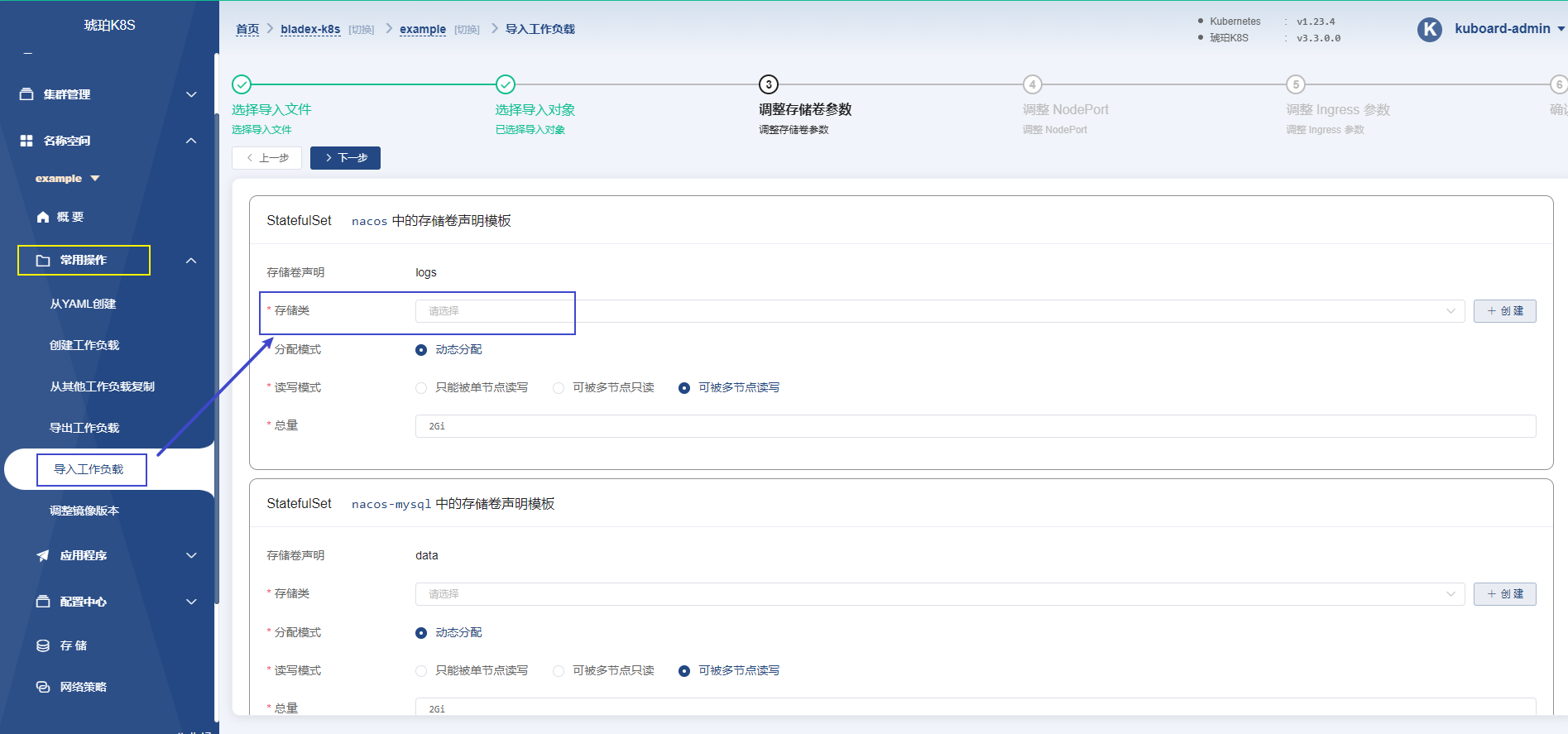
4.1.在场景中使用存储类
此时您可以在自己的场景中使用刚创建的存储类。Kuboard上,有以下几个地方可以用到NFS存储> > 类:
- 导入
example微服务- 安装监控套件
下一章节,使用kuboard不是开源项目 blade-cloud
这篇关于【K8s】3# 使用kuboard管理K8s集群(NFS存储安装)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








