本文主要是介绍【大数据实训】python石油大数据可视化(八),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2014到2020年石油加工产品产量数据处理分析
一、任务描述
石油是工业的命脉。
一直到2020年,我国原油产量基本处于平稳的状态,大部分原油来自国外进口;中国原油加工产量在华东、东北地区占比较大,华南地区相对较少。原油的加工企业对原油的加工有很大的影响,中国石油营业收入及净利润也十分可观。
本课题的目标是用python编程,抓取有关网站的数据,并将获取数据保存到csv文件和excel文件中,然后使用python对数据进行清洗及处理,利用python可视化,结合数据处理与分析,获得数据的统计分析结果。

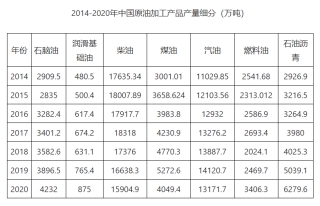
图1 2014-2020年中国原油加工产量信息
**二、**数据获取与清洗
1、数据描述
数据来源:2020年中国原油加工产业现状分析、2019年中国原油加工量产量及格局分析(当前网络上暂无2020年数据,故爬取了2019年数据)
数据获取:2014-2020年中国原油产量统计、中国各地区原油加工比例。
2、使用工具
python是一种功能丰富的语言,它拥有一个强大的基本类库和数量众多的第三方扩展。本次报告,使用到的库有:
1)requests库
2)BeautifulSoup4库
3)csv库
4)pandas库
3、数据获取步骤
第一步:从网页上获取HTML内容。
第二步:分析网页内容并提取有用数据
第三步:将获得的数据写入Excel文件。
4、程序代码
- 获取数据代码如下
文件夹名称:报告
文件名称: 石油加工产品产量分析
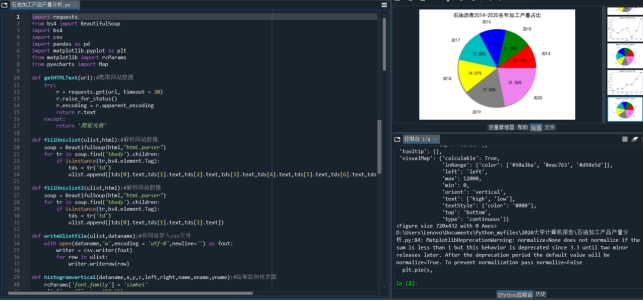
图2 爬虫程序及运行结果
- 将获得各省原油加工产量以及各种油产量放入csv文件中,使用的函数代码如下:
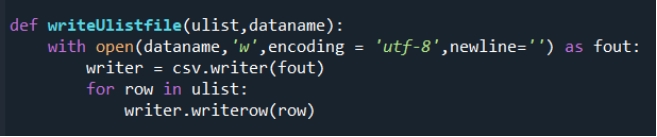
图3 存储函数
5 数据清洗后保存到Excel和csv文件,使用的函数、Excel文件截图,存储位置如图4、5、6、7所示:
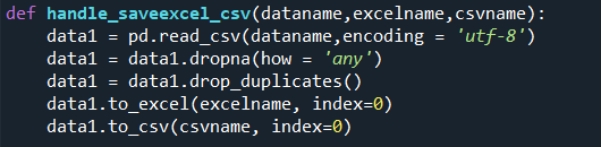

图4 数据清洗并存储函数
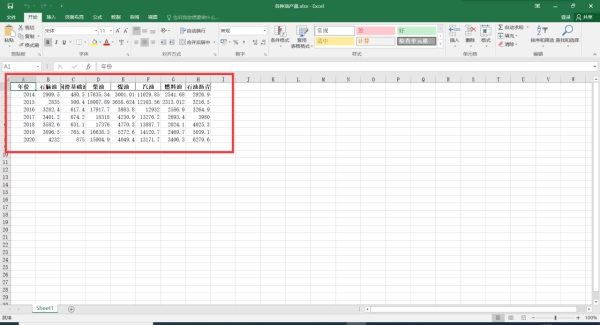
图5 各种油的产量的excel文件截图
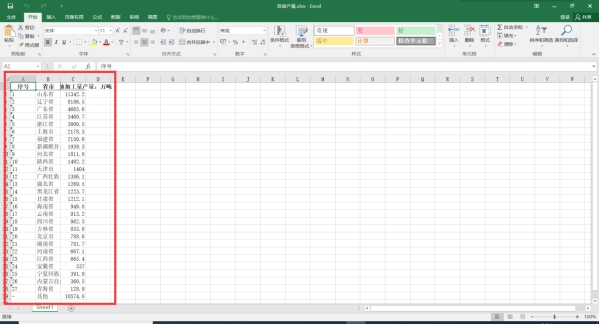
图6 各省油产量的excel文件截图
图7 存储位置截图
(默认存储到与py文件同目录的位置)
三**、**数据处理和分析
1、数据可视化工具
python是一种功能丰富的语言,它拥有一个强大的基本类库和数量众多的第三方扩展。报告中使用Matplotlib库以及pyecharts库的Map库实现了数据可视化。
2、先用python 对2014-2020年各种油产量以及2019年各省油产量数据进行可视化处理,所用的函数代码以及柱状图如图8、9所示。
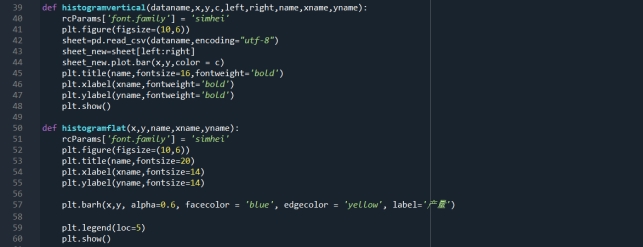


图8 使用函数代码截图
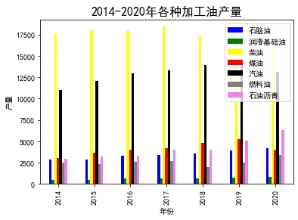
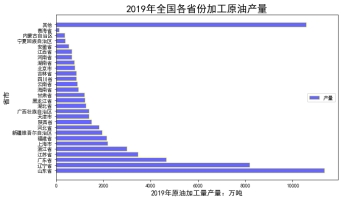
图9 各种油加工产量以及各省份加工原油产量
3、统计各种加工油产量以及各省市油产量数据,可视化后,画出折线图、饼状图如图10所示使用的代码如图11所示:
注明:代码本将七种油逐年产量数据均画出饼状图、折线图,因图数量过多,不全予以展示。
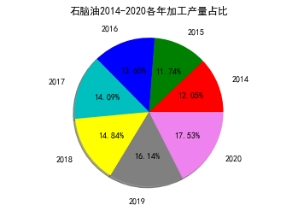
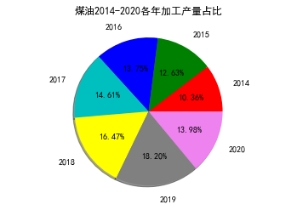
图10 各种油加工产量以及各省份加工原油产量
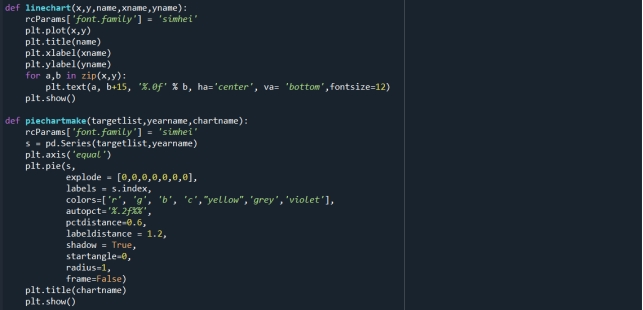
 图11 使用的函数代码
图11 使用的函数代码
4、特别地,我们安装pyecharts库将2019年各省油的产量在整个中国地图中呈现出来,观看时只需要将鼠标移到对应的省份,这样观看更加直观和方便。(其中山西、重庆、贵州、西藏、台湾暂无数据)代码及成果如下,结果如图
四**、**关键问题及对策
1、*爬取时的问题*
问题描述:找到要爬取的网站,找到网站上目标表格。于是参考了第二次大作业所用的爬取数据的代码,但是出现了爬取数据不完整的问题:
图13 用爬虫抓取数据
解决方法:
通过查询网上资料,我发现了问题主要出在fillUnivlist函数中,把tds增加到可以容纳整个列表后问题就可以解决,并且将string改为text以加强函数的稳定性,如图14 :
图14
2**、** 实际编写代码时遇到代码过长问题
问题描述:在我编写到输出折线图和饼状图的代码时,由于要输出的图过多,导致代码过长,输出一张图至少需要10行,加上在绘制饼状图时要计算出百分数,计算一系列百分数最少需要5行,那么七个系列至少需要180行含有大量重复的绘图代码,这极易导致错误出现,于是我将绘图代码编成函数,使用函数输出,然而这样还会存在以下重复代码:
依然存在大量重复代码,但是通过观察发现里面依然存在重复部分,此时我突然想起来“+”还可以链接字符串,于是我立刻拿出了课本,通过查阅课本发现的确可以,于是通过改写就有下列代码:

之后根据同样可以将重复部分改编成函数重复调用的方法,我经过压缩,将成品代码压缩到193行,其中函数部分有157行,主体部分有36行,如果将中间用于分割的空行删除,则可以进一步压缩,压缩过的代码不但整洁,还可以迅速发现并改正错误的、需要改正的地方。
五、数据处理与分析结果分析
综合以上分析,自2014-2020年各种油产量数据可以看出:
(1)各种加工油产量中柴油稳居第一,润滑基础油产量最低,表明我国在柴油方面需求较大,汽油相对较少,润滑基础油需求不高。
(2)七种加工油产量中柴油产量在2014年到2017年发展平稳,从2017年到2020年逐年下降;石脑油、润滑基础油、石油沥青的产量逐年上升;汽油在2014到2019年产量逐年上升,但在2020年突然下降,可能受到了疫情的影响;燃料油近些年来产量上下浮动较大,但在2018年到2020年产量一直上升,推测下一年产量还会上升;总体来看,未来除柴油和汽油外,其他油下一年产量可能还会升高,柴油和汽油在经历疫情影响后可能会积极恢复,再次实现增长。
(3)2019年中国原油加工产量65198.1万吨,其中:位于第一的是山东省,原油加工量产量11342.2万吨;第二的是辽宁省,原油加工量产量8186.5万吨;广东省进入第三,原油加工量产量4665.6万吨;其中值得注意的是在其他地区加工的原油占大多数,产量达到10574.8万吨,这些产量有可能来自暂无数据的山西、重庆、贵州、台湾,还有可能是从国外进口的成品油。
(4)最近一年,2020年中国原油加工产量为67440.8万吨,同比增长3.4%,表明虽然我国经历了新冠疫情的影响,但是我国在疫情得到控制后积极恢复,原油加工产量不降反增,原油加工产业受到疫情影响不大。
(5)原油加工产品中,2020年中国石脑油产量为4232万吨,同比增长8.6%;中国润滑基础油产量为875万吨,同比增长14.3%;中国柴油产量为15904.9万吨,同比下降4.4%;中国煤油产量为4049.4万吨,同比下降23.2%;中国汽油产量为13171.7万吨,同比下降6.7%;中国燃料油产量为3406.3万吨,同比增长37.9%;中国石油沥青产量为6279.6万吨,同比增长24.6%;总体来看我国原油加工产业正不断发展。
六、程序代码
略
七**、**学习总结与反思
略
这篇关于【大数据实训】python石油大数据可视化(八)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





