本文主要是介绍Recorder+人脸识别︱国内人脸识别技术趋势与识别难点、技术实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一些经验记录:
经过我的实践证明,不管人脸库多大,都不要用svm或者knn去分类,相似度搜索是保证准确率的前提(某weixin群大佬如是说)
一、人脸识别技术基本认识
1、文献综述与基本认识
本节来源于:人脸检测与深度学习
关于人脸检测算法的文献 总结:
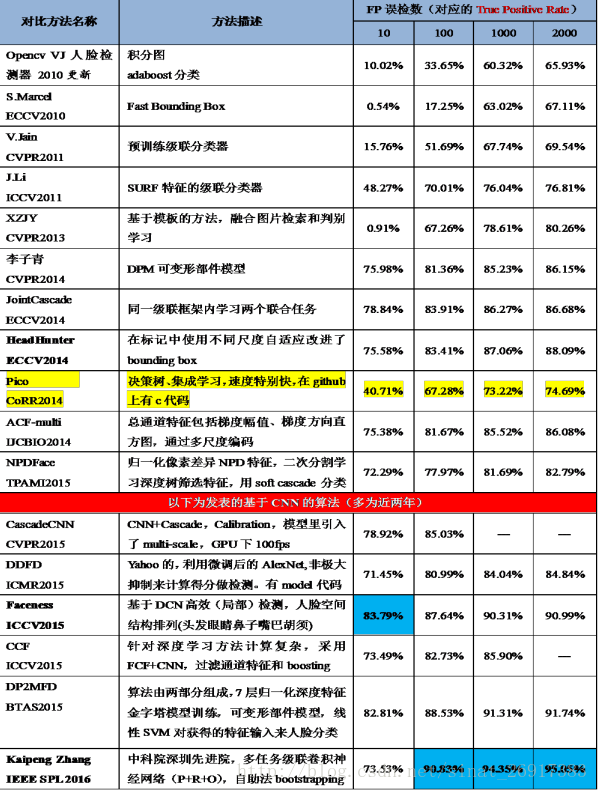
商用算法总结:
列举出共十七项商用算法,百度IDL提出DenseBox第三版(加粗蓝色)是性能最优算法。表中有十项是基于深度学习方法的人脸检测算法(加底纹),这些算法普遍比传统算法提高了十几个百分点,在误检数限制为10的情况下(基本没有误检),准确率仍能达到75%-80%,甚至有88.43%之高。在上述两表中提到的文献算法和商用算法只是为了说明深度学习方法的优势,然而相比于人脸比对评测集中许多公司刷到的99.00%+来说,FDDB人脸检测评测集还远未达到顶点(目前最高97.31%),虽然只有仅仅两个百分点左右的差距,如果用比较相似的额外数据作训练集,完全能够刷出更高的分数,但是对于算法研究和实际应用却是极难突破的,因为实际遇到的情况远比FDDB测试集上的复杂多变,随着深度学习和机器视觉技术的发展,我们可以用更好的策略、更优的特征学习、更深的网络将非约束情况下的人脸检测性能逐步提高。
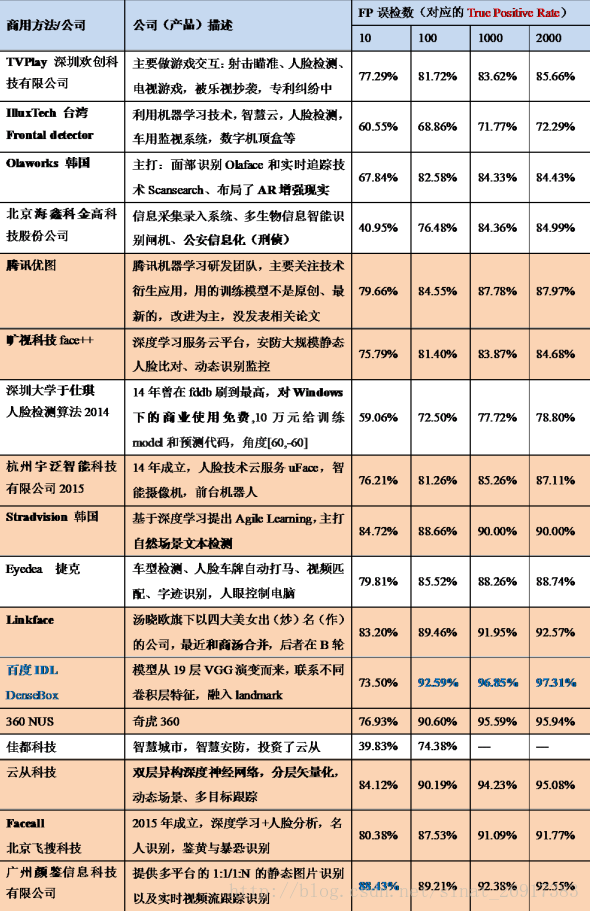
专利情况
.
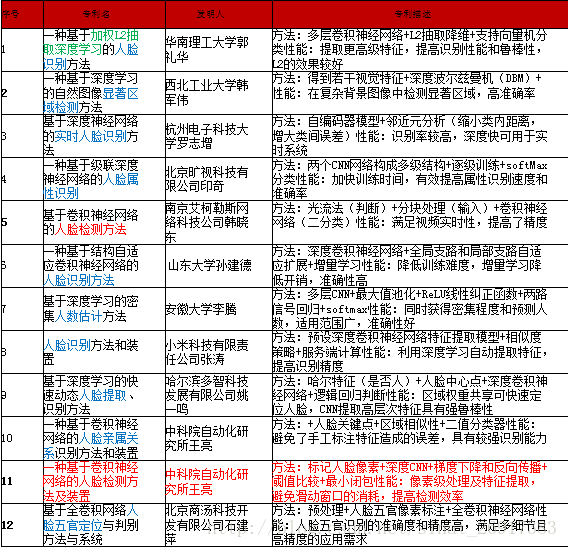
2、人脸检测过程
要实现这个过程,我们需要完成下面几个关键技术的分析:
(1)人脸检测:检测到图像中的人脸区域,快速定位。
(2)人脸识别:识别人的身份。
(3)人脸跟踪:定位并跟踪视频中的人脸。
(4)姿态估计:得到人脸方向和眼睛注视位置。
(5)表情识别:识别人的面部表情。
检测人脸相对应的参数有:检测参数:年龄,胡须,表情,性别,眼镜,人种
参考了 赵丽红《人脸检测方法综述》
来源于:如何定位图像中的人脸位置?
.
二、人脸识别难点与传统方法介绍
极市平台:人脸检测与识别的趋势和分析
1、人脸识别出现的问题
Ø 图像质量
人脸识别系统的主要要求是期望高质量的人脸图像,而质量好的图像则在期望条件下被采集。图像质量对于提取图像特征很重要,因此,即使是最好的识别算法也会受图像质量下降的影响;
Ø 照明问题
同一张脸因照明变化而出现不同,照明可以彻底改变物体的外观;
Ø 姿势变化
从正面获取,姿势变化会产生许多照片,姿态变化难以准确识别人脸;
Ø 面部形状/纹理随着时间推移的变化
有可能随着时间的推移,脸的形状和纹理可能会发生变化;
Ø 相机与人脸的距离
如果图像是从远处拍摄的,有时从较长的距离捕获的人脸将会遭遇质量低劣和噪音的影响;
Ø 遮挡
用户脸部可能会遮挡,被其他人或物体(如眼镜等)遮挡,在这种情况下很难识别这些采集的脸。
人脸尺度多变、数量冗大、姿势多样包括俯拍人脸、戴帽子口罩等的遮挡、表情夸张、化妆伪装、光照条件恶劣、分辨率低甚至连肉眼都较难区分等

2、人脸检测传统方法介绍:
- 1、基于Adaboost人脸检测
Adaboost人脸检测算法,是基于积分图、级联检测器和Adaboost算法的方法,该方法能够检测出正面人脸且检测速度快。其核心思想是自动从多个弱分类器的空间中挑选出若干个分类器,构成一个分类能力很强的强分类器。
缺点:而在复杂背景中,AdaBoost人脸检测算法容易受到复杂环境的影响,导致检测结果并不稳定,极易将类似人脸区域误检为人脸,误检率较高。
- 2、基于特征的方法(引用“Summary of face detection based on video”)
基于特征的方法实质就是利用人脸的等先验知识导出的规则进行人脸检测。
① 边缘和形状特征:人脸及人脸器官具有典型的边缘和形状特征,如人脸轮廓、眼睑轮廓、虹膜轮廓、嘴唇轮廓等都可以近似为常见的几何单元;
② 纹理特征:人脸具有特定的纹理特征,纹理是在图上表现为灰度或颜色分布的某种规律性,这种规律性在不同类别的纹理中有其不同特点;
③ 颜色特征:人脸的皮肤颜色是人脸表面最为显著的特征之一,目前主要有RGB,HSV,YCbCr,YIQ,HIS等彩色空间模型被用来表示人脸的肤色,从而进行基于颜色信息的人脸检测方法的研究。
- 3、 基于模板的方法
基于模板匹配的方法的思路就是通过计算人脸模板和待检测图像之间的相关性来实现人脸检测功能的
- 4、基于统计理论的方法
基于统计理论的方法是指利用统计分析与机器学习的方法分别寻找人脸与非人脸样本特征,利用这些特征构建分类,使用分类进行人脸检测。它主要包括神经网络方法,支持向量机方法和隐马尔可夫模型方法。基于统计理论的方法是通过样本学习而不是根据人们的直观印象得到的表象规律,因此可以减小由于人眼观测不完整和不精确带来的错误而不得不扩大检测的范围,但是这种方法需要大量的统计特性,样本训练费时费力。
以上也都是通过快速阅读得到的一些结论,大部分都是直接引用文章作者的语句。其中在这些方法中,都有很多改进,比如PCA+Adaboost,HMM等。
- 5、神经网络
现在流行了DL架构,打破了人类的极限,又将检测,识别,跟踪等技术上升到另一个高度。
模型有:RCNN、RINN、PCA & ANN、Evolutionary Optimization of Neural Networks、Multilayer Perceptron (MLP)
可参考论文:《Recent Advances in Face Detection》
.
延伸一:Facebook的DeepFace
DeepFace是FAIR开发的一套人脸识别系统,主要应用卷积神经网络来提取人脸特征完成识别。现在Facebook用户每天上传的图片数量达到了8亿张,拥有大量的数据供机器训练与学习。
此外,Yann LeCun还提到了一项FAIR开发的,用于检测、分割、识别单张图像中每个物体的技术,比如在一盘菜里检测、分割、并识别出西兰花来、又或是在一堆羊群里分割出每只羊,其核心流程为以下三步
- 1、使用DeepMask这个新型框架对物体进行检测与分割,生成初始对象掩膜(Mask,相当于一个覆盖区域);
- 2、使用SharpMask模型优化这些对象掩膜;
- 3、使用MutiPathNet卷积网络识别每个掩膜所框定的物体。
MutiPathNet中使用了一种新型的对象实例分割(Instance Segmentation)框架:Mask R-CNN。它是Faster R-CNN的扩展形式,能够有效地检测图像中的目标,同时还能为每个实例生成一个高质量的分割掩膜(Segmentation Mask)。
.
延伸二:用Dlib 人脸识别实践
参考:40行代码的人脸识别实践
人脸检测解决的问题是确定一张图上有木有人脸,而人脸识别解决的问题是这个脸是谁的。可以说人脸检测是是人识别的前期工作。今天我们要做的是人脸识别。
Dlib里面有人脸检测器,有训练好的人脸关键点检测器,也有训练好的人脸识别模型。今天我们主要目的是实现,而不是深究原理。
girl-face-rec.py是我们的python脚本。shape_predictor_68_face_landmarks.dat是已经训练好的人脸关键点检测器。dlib_face_recognition_resnet_model_v1.dat是训练好的ResNet人脸识别模型。ResNet是何凯明在微软的时候提出的深度残差网络,获得了 ImageNet 2015 冠军,通过让网络对残差进行学习,在深度和精度上做到了比CNN 更加强大。
.
延伸三:用opencv检测人脸Cascade
参考:用10行代码自己写个人脸识别程序
github界面:https://github.com/CloudsDocker/pyFacialRecognition
Classifer
在机器深度学习领域,针对识别不同物体都有不同的classifier,比如有的classifier来识别洗车,还有识别飞机的classifier,有classifier来识别照片中的笑容,眼睛等等。而我们这个例子是需要去做人脸识别,因此需要一个面部识别的classifier。
物体识别的原理
一般来说,比如想要机器学习着去识别“人脸”,就会使用大量的样本图片来事先培训,这些图片分为两大类,positive和negative的,也就是分为包“含有人脸”的图片和“不包含人脸”的图片,这样当使用程序去一张一张的分析这些图片,然后分析判断并对这些图片“分类” (classify),即合格的图片与不合格的图片,这也就其为什么叫做 classifier , 这样学习过程中积累的"知识",比如一些判断时的到底临界值多少才能判断是positive还是negative什么的,都会存储在一个个XML文件中,这样使用这些前人经验(这里我们使用了 哈尔 分类器)来对新的图片进行‘专家判断’分析,是否是人脸或者不是人脸。
Cascade
这里的 Cascade是 层级分类器 的意思。为什么要 分层 呢?刚才提到在进行机器分析照片时,其实是对整个图片从上到下,从左到右,一个像素一个像素的分析,这些分析又会涉及很多的 特征分析 ,比如对于人脸分析就包含识别眼睛,嘴巴等等,一般为了提高分析的准确度都需要有成千上万个特征,这样对于每个像素要进行成千上万的分析,对于整个图片都是百万甚至千万像素,这样总体的计算量会是个天文数字。但是,科学家很聪明,就想到分级的理念,即把这些特征分层,这样分层次去验证图片,如果前面层次的特征没有通过,对于这个图片就不用判断后面的特征了。这有点像是系统架构中的 FF (Fail Fast),这样就提高了处理的速度与效率。
import cv2,sys
faceClassifier=cv2.CascadeClassifier('haarcascade_frontalface_default.xml') # the HAAR cascade file, which contains the machine learned data for face detection
objImage=cv2.imread(sys.argv[1]) # use cv2 to load image file
cvtImage=cv2.cvtColor(objImage,cv2.COLOR_BGR2GRAY) # convert the image to gray scale
foundFaces=faceClassifier.detectMultiScale(cvtImage,scaleFactor=1.3,minNeighbors=9,minSize=(50,50),flags = cv2.cv.CV_HAAR_SCALE_IMAGE) # to detect faces
print(" There are {} faces in the input image".format(len(foundFaces)))
for (x,y,w,h) in foundFaces:# to iterate each faces foundedcv2.rectangle(objImage,(x,y),(x+w,y+h),(0,0,255),2)
cv2.imshow("Facial Recognition Result, click anykey of keyboard to exit", objImage) #show the image
cv2.waitKey(0)
延伸四:自编码器进行人脸数据降维
参考实验楼实验:自编码器进行人脸数据降维
虽然目前深度学习取得了非常不错的成果,但是由于网络结构复杂,训练非常耗时。而且目前要进行深度学习的分类训练需要大量的带标记数据,对这些数据进行标记是非常耗时耗人力的。因此我们可用无监督学习利用无标记数据提取特征,并且利用无标记数据基于无监督学习对数据进行降维后,结合有标记数据基于有监督学习进行分类训练,实现人脸识别,图像分类等任务。
神经网络由两部分组成,第一部分为自编码器训练完毕后的编码部分,第二部分为有监督训练单层网络,在基于无监督学习的自编码器实现中我们已经详细地介绍过自编码器的原理,这里我们将运用其作为对人脸进行数据降维,再结合有监督学习结合有标记数据进行分类训练。
自编码器结构:

.
延伸五:利用opencv的CascadeClassifier
7行Python的人脸识别
import cv2face_patterns = cv2.CascadeClassifier('/usr/local/opt/opencv3/share/OpenCV/haarcascades/haarcascade_frontalface_default.xml')sample_image = cv2.imread('/Users/abel/201612.jpg')faces = face_patterns.detectMultiScale(sample_image,scaleFactor=1.1,minNeighbors=5,minSize=(100, 100))for (x, y, w, h) in faces:cv2.rectangle(sample_image, (x, y), (x+w, y+h), (0, 255, 0), 2)cv2.imwrite('/Users/abel/201612_detected.png', sample_image);
- 第1行 引入 OpenCV
开源是伟大的,使我们视野更开阔,而且不用重复造轮子。这里没有用PIL,再结合特定算法,而是直接使用了OpenCV(http://opencv.org)。OpenCV是一个基于BSD许可发行的跨平台计算机视觉库,可以运行在Linux、Windows和Mac OS操作系统上,轻量而且高效,用C/C++编写,同时提供了Python、Ruby、MATLAB等接口,实现了图像处理和计算机视觉方面的很多通用算法。
- 第2行 加载分类器 cv2.CascadeClassifier
CascadeClassifier是Opencv中做人脸检测时候的一个级联分类器,该类中封装的是目标检测机制即滑动窗口机制+级联分类器的方式。数据结构包括Data和FeatureEvaluator两个主要部分。Data中存储的是从训练获得的xml文件中载入的分类器数据;而FeatureEvaluator中是关于特征的载入、存储和计算。这里采用的训练文件是OpenCV中默认提供的haarcascadefrontalfacedefault.xml。至于Haar,LBP的具体原理,可以参考opencv的相关文档,简单地,可以理解为人脸的特征数据。
- 第3行 加载目标图片 imread
人脸识别系统一般分为:人脸图像采集、人脸图像预处理、人脸图像特征提取以及匹配与识别。 简化起见,之间读入图片,这是一张去年中生代北京闭门会的集体照。
- 第4行 多尺度检测 detectMultiScale
调用 CascadeClassifier 中的调detectMultiScale函数进行多尺度检测,多尺度检测中会调用单尺度的方法detectSingleScale。 参数说明:
scaleFactor 是 图像的缩放因子
minNeighbors 为每一个级联矩形应该保留的邻近个数,可以理解为一个人周边有几个人脸
minSize 是检测窗口的大小
这些参数都是可以针对图片进行调整的,处理结果返回一个人脸的矩形对象列表。
- 第5行 和 第6行 为每个人脸画一个框
循环读取人脸的矩形对象列表,获得人脸矩形的坐标和宽高, 然后在原图片中画出该矩形框,调用的是OpenCV的rectangle 方法,其中矩形框的颜色等是可调整的。
- 第7行 保存检测后的结果
万事具备了,调用imwrite,将检测后的结果保存到指定的位置。
.
延伸六:高效处理框架(人脸检测识别/关键帧/图片搜索等)
Scanner: Efficient Video Analysis at Scale
github地址:https://github.com/scanner-research/scanner
视频中人脸识别、高效,而且开源
.
延伸七:人脸识别 + 手机推送,从此不再害怕老板背后偷袭!
BossComing 项目地址:fendouai/BossComing
技术介绍
人脸识别技术
face_recognition
The world's simplest facial recognition api for Python and the command line
ageitgey/face_recognition
手机推送技术
jpush-api-python-client
JPush's officially supported Python client library for accessing JPush APIs.
jpush/jpush-api-python-client
依赖安装
pip install face_recognition
pip install jpush

python bosscoming.py
体验人脸识别部分命令:
python bosswatching.py
打开电脑上摄像头,开始捕捉画面。然后调整角度,对准需要观察的位置。
.
延伸八:微动作模式(MAP)表达学习
来源文章《深层网络面部表情的特征学习》
面部动作编码(FACS)理论的关键成分是一个观察到的表情可以被分解成若干个局部外观的变化。为了学习高层表情具体特征,应该先编码这些后续使用的局部变化。考虑到AU的局部性,我们从所有的训练表情图像中密集采样大量的小块(即MAP原型),去共同表达由面部表情引起的所有局部变化。
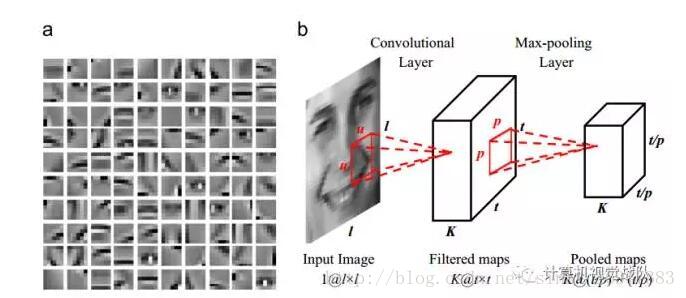
提出了自动学习:
(1)可提供信息的局部外观变化;
(2)优化方法去结合局部变化;
(3)最后表情识别的高层表达。
所提出的AUDN由三个连续的模块组成,主要为微动作模式(MAP)表达学习、感受野构造和group-wise子网络学习。实验最后选择在CK+、MNI和SFEW三个表情数据库进行,学习的特征通过采用线性分类器,在所有数据库中都到达了优异的结果且验证了AUDN的有效性。
.
延伸九:深度卷积网络迁移学习的脸部表情识别
基本数据库:
主要根据四个面部表情数据库(CK+,JAFFE,KDEF和Pain expressionsform PICS)建立了一个面部表情数据库含有七个基本情绪状态和2062个不平衡样本。
模型connets
深度ConvNets由四个卷积层和最大池化层去特征提取,全连接的高层特征层和Softmax输出层预测识别类,具体如图1所示。
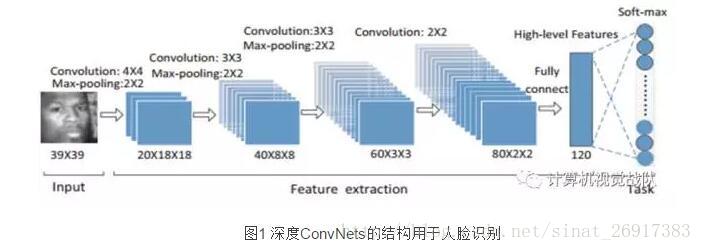
每一层的特征数量在减少,最后将高层特征层固定在120个特征,其可表达丰富的人脸信息。最后一个Softmax输出层全连接的高层特征预测1580个识别类。
.
延伸十:基于mtcnn和facenet的实时人脸检测与识别系统开发
来源知乎
文章的主要内容为:
- 2,采用opencv2实现从摄像头读取视频帧;
- 3,对读取的视频帧采用mtcnn方法,检测人脸;
- 4,采用预训练的facenet对检测的人脸进行embedding,embedding成128维度的特征;
- 5,对人脸embedding特征采用knn进行分类,实现人脸识别;
- 6,结果与改进;
其中截取感兴趣的一部分:
facenet embedding
Facenet是谷歌研发的人脸识别系统,该系统是基于百万级人脸数据训练的深度卷积神经网络,可以将人脸图像embedding(映射)成128维度的特征向量。以该向量为特征,采用knn或者svm等机器学习方法实现人脸识别。
对人脸进行embedding后,得到128维度的特征向量 。
其中faceNet的github(with Tensorflow r1.0):https://github.com/davidsandberg/facenet
这篇关于Recorder+人脸识别︱国内人脸识别技术趋势与识别难点、技术实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








