本文主要是介绍非结构化用户标签︱如何花式解析一条收货地址(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据中台类产品必须用户画像,目前大多数用户画像都是结构化数据,其实还有非常多有意思的兴趣标签,可以从文本、图片、视频中获取,接下来这类兴趣标签也会越来越多的被计算与获得。
本系列,也从此出发,先来看一下,一则收货地址的几个字,可能就有非常多的内容值得解析:
上海市浦东新区银城中路上海中心大厦501室,张三,155111122331 geopy地理解析
pip install geopy
geopy 是一款免费开源的库,在单个包中为许多不同地理编码服务提供了实现,从而避免了直接对接不同地理编码服务的 API,简化了代码的逻辑。
具体可参考:3100 Star!集成多种地理信息编码服务的神器
可以获取地理位置具体信息、经纬度等
>>> from geopy.geocoders import Nominatim
>>> geolocator = Nominatim(user_agent="test_geo")
>>> location = geolocator.reverse("31.23564615, 121.5012662299473")
>>> print(location.address)
上海中心大厦, 501, 银城中路, 浦东新区, 200010, 中国
>>> print((location.latitude, location.longitude))
(31.23564615, 121.5012662299473)
>>> print(location.raw)
{'place_id': 130257928, 'licence': 'Data © OpenStreetMap contributors, ODbL 1.0. https://osm.org/copyright', 'osm_type': 'way', 'osm_id': 165792123, 'lat': '31.23564615', 'lon': '121.5012662299473', 'display_name': '上海中心大厦, 501, 银城中路, 浦东新区, 200010, 中国', 'address': {'tourism': '上海中心大厦', 'house_number': '501', 'road': '银城中路', 'city': '浦东新区', 'postcode': '200010', 'country': '中国', 'country_code': 'cn'}, 'boundingbox': ['31.235266', '31.2360377', '121.5007425', '121.5017465']}2 手机归属地
参考github地址为: https://github.com/ls0f/phone
安装: pip install phone
示例:
from phone import Phone
p = Phone()
p.find(15511112233)结果包括:手机归属地省份、归属地城市、营业厅类型、区域编码
{'phone': '15511112233','province': '河北','city': '石家庄','zip_code': '50000','area_code': '0311','phone_type': '联通'}3 名字判断性别
参考:https://github.com/observerss/ngender
当然,通过名字,判定性别有点牵强;不过够花式~
pip install ngender
>>> import ngender
>>> ngender.guess('张三')('male', 0.7722227984648896)4 智能地址识别
这边有蛮多开源项目都在做,这边简单推荐几个:
•百度AI -智能地址识别,博客介绍:百度AI -智能地址识别 接口使用[1]•dongrixinyu/JioNLP[2]•PyUnit/pyunit-address[3]•fighting41love/cocoNLP[4]•yihenglu/chinese-address-segment[5]
百度地址解析的效果:
ad = address_detection()
text = "上海市浦东新区纳贤路701号百度上海研发中心 F4A000 张三"
text = '北京市朝阳区富康路姚家园3号楼5单元3305室马云15000000000邮编038300'
ad.address(text)输出:
{'log_id': 1309384850054053888,'town': '张江镇','city': '上海市','county_code': '310115','county': '浦东新区','city_code': '310100','phonenum': '','province_code': '310000','town_code': '310115125','province': '上海市','person': '张三','detail': '纳贤路701号百度上海研发中心F4A000','text': '上海市浦东新区纳贤路701号百度上海研发中心 F4A000 张三'}dongrixinyu/JioNLP
parse_location:给定一个(地址)字符串,识别其中的省、市、县三级地名,指定参数town_village(bool), 可获取乡镇、村、社区两级详细地名,指定参数change2new(bool)可自动将旧地址转换为新地址。
这个开源项目的优势是:字符串中缺少省市信息,可依据词典做自动补全,如上例1中,根据“武侯区” 补全 “四川、成都”。
# 例 1
>>> import jionlp as jio
>>> text = '武侯区红牌楼街道19号红星大厦9楼2号'
>>> res = jio.parse_location(text, town_village=True)
>>> print(res)# {'province': '四川省',
# 'city': '成都市',
# 'county': '武侯区',
# 'town': '红牌楼街道',
# 'village': None,
# 'detail': '红牌楼街道19号红星大厦9楼2号',
# 'full_location': '四川省成都市武侯区红牌楼街19号红星大厦9楼2号',
# 'orig_location': '武侯区红牌楼街19号红星大厦9楼2号'}PyUnit/pyunit-address
该库比较好的就是人工干预的设置比较多,应该是经得起实操的.
def all_test():string_ = '我家在红花岗,你家在贵州贵阳花溪区,他家在贵州省遵义市花溪区'finds = find_address(address, string_)for find in finds:print()print('地址', find)print('补全地址', supplement_address(address, find))print('纠错地址', correct_address(address, find))print('--------------------------')# 地址 红花岗
# 补全地址 ['贵州省-遵义市-红花岗区']
# 纠错地址 贵州省-遵义市-红花岗区
# --------------------------
#
# 地址 贵州贵阳花溪区
# 补全地址 ['贵州省-贵阳市-花溪区']
# 纠错地址 贵州省-贵阳市-花溪区
# --------------------------
#
# 地址 贵州省遵义市花溪区 注:这个地址是错误的
# 补全地址 [] 注:错误的地址无法补全
# 纠错地址 贵州省-贵阳市-花溪区 注:错误的地址被纠正为对的地址
# --------------------------[fighting41love/cocoNLP]
# 抽取地址信息
>>> locations = ex.extract_locations(text)
>>> print(locations)
['陕西省安康市汉滨区', '安康市汉滨区', '汉滨区'][yihenglu/chinese-address-segment] 深度学习做算法,IDCNN膨胀卷积网络或者BILSTM 地址元素识别可以抽取地址中不同的地址元素,同时也可以作为其它项目任务的基础。
{'string': '江苏省南京市六合区雄州街道雄州南路333号冠城大通南郡25幢1单元502室', 'entities': [{'word': '江苏省', 'start': 0, 'end': 3, 'type': 'XZQHS'}, {'word': '南京市', 'start': 3, 'end': 6, 'type': 'XZQHCS'}, {'word': '六合区', 'start': 6, 'end': 9, 'type': 'XZQHQX'}, {'word': '雄州街道', 'start': 9, 'end': 13, 'type': 'JD1'}, {'word': '雄州南路', 'start': 13, 'end': 17, 'type': 'JD2'}, {'word': '333号', 'start': 17, 'end': 21, 'type': 'MP1'}, {'word': '冠城大通南郡', 'start': 21, 'end': 27, 'type': 'MP2'}, {'word': '25幢', 'start': 27, 'end': 30, 'type': 'MP3'}, {'word': '1单元', 'start': 30, 'end': 33, 'type': 'DYS1'}, {'word': '502室', 'start': 33, 'end': 37, 'type': 'DYS2'}]}5 POI解析 -> 商圈价值 / 房价
高德/百度地图,能够直观反映地址的质量的有:房价 + 商圈消费水平
5.1 关于地图API的理解
理解一下地理编码 / 逆地理编码 / 关键词搜索 / 周边搜索,这几个分别实现的关系:
•地理编码:给一长串地址文本,解析出省市区 + 经纬度(精度高)•逆地理编码:给一个经纬度,解析出附近的POI信息•关键词搜索:给一个关键词,解析出省市区 + 经纬度(精度低,不过比较常用)•周边搜索:给一个关键词,解析附近的POI信息,与关键词搜索配套
5.2 一些基于POI的标签
其次可以产出一些基于POI标签的值:
- 美食标签(附近餐厅)
- 化妆品集中度(是否有较多的化妆品)
- 购买指数(商城比较多)
- 生活便利指数(超市数量)需要很多数据然后进行筛选
5.3 房价
透过房价,解析地址价值,这里笔者自己写的一个项目的实践步骤为:
(1)高德地图定位经纬度
首先通过高德地图,定位该收货地址的经纬度,这里其实我们直接"信任"了高德地图,认为它具备鉴定该收货地址是否合理的功能. 从实践角度来看,可以尽量多的将省市区与小区信息都给到高德地图,如果高德地图不认识,会返回最高level可认识的范围
比如,我们给入地址上海市xxxxxxxxx小区,肯定错误,那么高德会定位到上海, 从而我们可以根据,高德地图返回的level来判定,地图能不能认识细粒度. 比如,某个地址返回粒度为市那么该地址文本质量较差,定位到街道该地址文本质量较高.
对这个整个模块来看,定位到县级,其实也是可以接受,毕竟一个县的房价,总比跨县城的要合理.
(2)匹配房价数据库确定房价
对于自建的房价数据库,需要做一些预处理,简单的数据清洗自不必说;还需要补齐每个小区的经纬度,已经小区周边的POI的内容
匹配房价也有两种方式去进行定位:
•精准版(poi_match),通过高德地图识别出来的经纬度,通过经纬度回查房价数据库,进行精准定位,遴选3km之内的•模糊版(resident_match),如果高德识别不了,那就通过文本关键词匹配的方式,匹配小区名称;如果小区名称还不可识别,那只能退而求其次计算整个县城的均价
5.4 房价影响因素比较
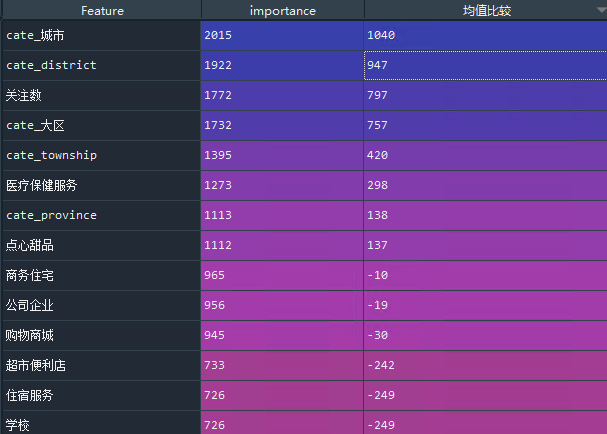
笔者对房价数据库的数据进行简单的解析,做了一个非常、非常简单的解析,y(房价) ~ x(上述POI个数,城市类型等),模型为LGB
特征重要性来看,不同城市(地理位置类的标签)的影响较大,在poi信息中,医疗保健服务的POI对房价的影响较大,竟然不是学校??不过由于这个是全国的房价实情,所以可能会跟认知存在一定的偏差。
另外,某平台的关注数,确实与房价的关系密切。
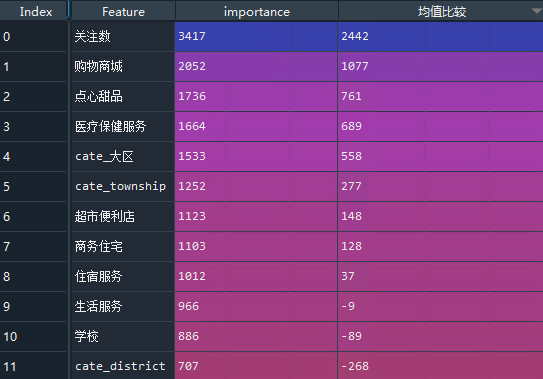
把数据集限定在上海,POI价值比较明显的有购物商城,点心甜品类。
6 地址人流量
哈哈哈... 想多了,怎么可能有...
References
[1] 智能地址识别 接口使用[2] dongrixinyu/JioNLP:[3] PyUnit/pyunit-address: https://github.com/PyUnit/pyunit-address[4] fighting41love/cocoNLP: https://github.com/fighting41love/cocoNLP[5] yihenglu/chinese-address-segment: https://github.com/yihenglu/chinese-address-segment
这篇关于非结构化用户标签︱如何花式解析一条收货地址(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






