本文主要是介绍MySQL实战45讲课后问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、第一章
如果表T中没有字段k,而你执行了这个语句 select *fromTwhere k=1, 那肯定是会报“不存在这个列”的错误: “Unknown column ‘k’ in ‘where clause’”。你觉得这个错误是在我们上面提到的哪个阶段报出来的呢?
解答:是在分析器阶段,分析器阶段会对要执行的sql进行词法分析和语法分析,mysql会识别出sql语句里面的每个字符串分别是什么,代表什么,所以是在分析器阶段。
2、第二章
我说到定期全量备份的周期“取决于系统重要性,有的是一天一备,有的是一周一备”。那么在什么场景下,一天一备会比一周一备更有优势呢?或者说,它影响了这个数据库系统的哪个指标?
解答:一天一备跟一周一备对比,好处是"最长恢复时间更短",在一天一备的模式里,最坏情况下需要应用一天的binlog。比如,你每天0点做一次全量备份,而要恢复出一个到昨天晚上23点的备份。一周一备最坏情况就要应用一周的binlog了。
3、第三章
如何避免长事务对业务的影响?
解答:如何避免长事物要从应用端和数据库端两个方面来说:
首先,从应用开发端来看:
- 确认是否使用了set autocommit=0。这个确认工作可以在测试环境中开展,把MySQL的
general_log开起来,然后随便跑一个业务逻辑,通过general_log的日志来确认。一般框架
如果会设置这个值,也就会提供参数来控制行为,你的目标就是把它改成1。 - 确认是否有不必要的只读事务。有些框架会习惯不管什么语句先用begin/commit框起来。我
见过有些是业务并没有这个需要,但是也把好几个select语句放到了事务中。这种只读事务
可以去掉。 - 业务连接数据库的时候,根据业务本身的预估,通过SETMAX_EXECUTION_TIME命令,
来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。(为什么会意外?在后
续的文章中会提到这类案例)
其次,从数据库端来看:
- 监控 information_schema.Innodb_trx表,设置长事务阈值,超过就报警/或者kill;
- Percona的pt-kill这个工具不错,推荐使用;
- 在业务功能测试阶段要求输出所有的general_log,分析日志行为提前发现问题;
- 如果使用的是MySQL 5.6或者更新版本,把innodb_undo_tablespaces设置成2(或更大的
值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。
4、第四章
对于上面例子中的InnoDB表T,如果你要重建索引 k,你的两个SQL语句可以这么写:
alter table T drop index k;
alter table T add index(k);
如果你要重建主键索引,也可以这么写:
alter table T drop primary key;
alter table T add primary key(id);
我的问题是,对于上面这两个重建索引的作法,说出你的理解。如果有不合适的,为什么,更好的方法是什么?
解答:重建索引k的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。这两个语句,你可以用这个语句代替 : alter table Tengine=InnoDB。
5、第五章
DBA小吕在入职新公司的时候,就发现自己接手维护的库里面,有这么一个表,表结构定义类似这样的:
CREATE TABLE `geek` (`a` int(11) NOT NULL,`b` int(11) NOT NULL,`c` int(11) NOT NULL,`d` int(11) NOT NULL,PRIMARY KEY (`a`,`b`),KEY `c` (`c`),KEY `ca` (`c`,`a`),KEY `cb` (`c`,`b`)
) ENGINE=InnoDB;
公司的同事告诉他说,由于历史原因,这个表需要a、b做联合主键,这个小吕理解了。但是,学过本章内容的小吕又纳闷了,既然主键包含了a、b这两个字段,那意味着单独在字段c上创建一个索引,就已经包含了三个字段了呀,为什么要创建“ca”“cb”这两个索引?
同事告诉他,是因为他们的业务里面有这样的两种语句:
select * from geek where c=N order by a limit 1;
select * from geek where c=N order by b limit 1;
这位同事的解释对吗,为了这两个查询模式,这两个索引是否都是必须的?为什么呢?
解答:ca可以去掉,cb需要保留,因为ca的索引组织跟c的索引组织是一样的(因为在二级索引中,附带的主键是有序)
6、第六章
当备库用–single-transaction做逻辑备份的时候,如果从主库的binlog传来一个DDL语句会怎么样?
假设这个DDL是针对表t1的, 这里我把备份过程中几个关键的语句列出来:
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* other tables */
Q3:SAVEPOINT sp;
/* 时刻 1 */
Q4:show create table `t1`;
/* 时刻 2 */
Q5:SELECT * FROM `t1`;
/* 时刻 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* 时刻 4 */
/* other tables */
在备份开始的时候,为了确保RR(可重复读)隔离级别,再设置一次RR隔离级别(Q1);
启动事务,这里用 WITH CONSISTENTSNAPSHOT确保这个语句执行完就可以得到一个一致性视图(Q2);
设置一个保存点,这个很重要(Q3);
showcreate 是为了拿到表结构(Q4),然后正式导数据 (Q5),回滚到SAVEPOINTsp,在这里的作用是释放 t1的MDL锁 。
DDL从主库传过来的时间按照效果不同,我打了四个时刻。题目设定为小表,我们假定到达后,如果开始执行,则很快能够执行完成。
参考答案如下:
- 如果在Q4语句执行之前到达,现象:没有影响,备份拿到的是DDL后的表结构。
- 如果在“时刻 2”到达,则表结构被改过,Q5执行的时候,报 Table definition has changed,
please retry transaction,现象:mysqldump终止; - 如果在“时刻2”和“时刻3”之间到达,mysqldump占着t1的MDL读锁,binlog被阻塞,现象:
主从延迟,直到Q6执行完成。 - 从“时刻4”开始,mysqldump释放了MDL读锁,现象:没有影响,备份拿到的是DDL前的表
结构。
7、第七章
怎么删除表的前10000行,有以下三种方法可以做到:
- 第一种,直接执行delete fromTlimit 10000;
- 第二种,在一个连接中循环执行20次 delete fromTlimit 500;
- 第三种,在20个连接中同时执行delete fromTlimit 500。
比较多的留言都选择了第二种方式,即:在一个连接中循环执行20次 delete fromTlimit 500。
确实是这样的,第二种方式是相对较好的。
第一种方式(即:直接执行delete fromTlimit 10000)里面,单个语句占用时间长,锁的时间也比较长;而且大事务还会导致主从延迟。
第三种方式(即:在20个连接中同时执行delete fromTlimit 500),会人为造成锁冲突。
8、第八章
我用下面的表结构和初始化语句作为试验环境,事务隔离级别是可重复读。现在,我要把所有“字段c和id值相等的行”的c值清零,但是却发现了一个“诡异”的、改不掉的情况。请你构造出这种情况,并说明其原理。
mysql> CREATE TABLE `t` (`id` int(11) NOT NULL,`c` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, c) values(1,1),(2,2),(3,3),(4,4);
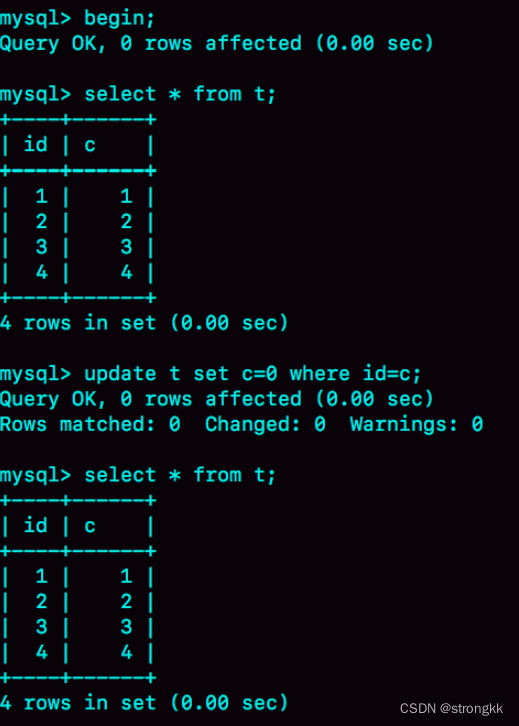
复现出来以后,请你再思考一下,在实际的业务开发中有没有可能碰到这种情况?你的应用代码会不会掉进这个“坑”里,你又是怎么解决的呢?
上期的问题是:如何构造一个“数据无法修改”的场景。评论区里已经有不少同学给出了正确答案,这里我再描述一下。

这篇关于MySQL实战45讲课后问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







