本文主要是介绍pytorch实现DCP暗通道先验去雾算法及其onnx导出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pytorch实现DCP暗通道先验去雾算法及其onnx导出
- 简介
- 实现
- ONNX导出
- 导出
- 测试
简介
最近在做图像去雾,于是在Pytorch上复现了一下dcp算法。暗通道先验去雾算法是大神何恺明2009年发表在CVPR上的一篇论文,还获得了当年的CVPR最佳论文。

实现
具体原理就不阐述了,网上的解析多的是,这里直接把用pytorch复现的代码贴出来:
import torchdef dcp(img, omega=0.75):h, w = img.shape[2:]imsz = h * w# 要查找的是暗通道中前0.1%的值numpx = torch.clamp_min(imsz // 1000, 1)# 找到暗通道的索引,弄成[batch, 3, numpx],因为要匹配三个通道,所以需要expanddark = torch.min(img, dim=1, keepdim=True)[0]indices = torch.topk(dark.view(-1, imsz), k=numpx, dim=1)[1].view(-1, 1, numpx).expand(-1, 3, -1)# 用上述索引匹配原图中的3个通道,并求其平均值a = (torch.gather(img.view(-1, 3, imsz), 2, indices).sum(2) / numpx).view(-1, 3, 1, 1)# 代公式算txtx = 1 - omega * torch.min(img / a.view(-1, 3, 1, 1), dim=1, keepdim=True)[0]# 代公式算jxreturn (img - a) / torch.clamp_min(tx, 0.1) + a
函数有两个参数:
- img:经归一化后的(N,C,H,W)布局的图像
- omega:DCP算法的一个参数ω,数值越大效果越强
如果想在模型训练时引入dcp算法,可以用nn.Module封装一下:
class DCP(torch.nn.Module):def __init__(self, omega):self._omega = omegadef forward(self, x):return dcp(x, self._omega)
ONNX导出
导出
既然能封装成Module,那么就顺便试了一下导出ONNX。
导出onnx需要安装onnx和onnxsim:
pip install onnx onnxsim
导出代码如下:
import torch
import onnx
from onnxsim import simplify def dcp(img, omega=0.75):h, w = img.shape[2:]imsz = h * w# 要查找的是暗通道中前0.1%的值numpx = torch.clamp_min(imsz // 1000, 1)# 找到暗通道的索引,弄成[batch, 3, numpx],因为要匹配三个通道,所以需要expanddark = torch.min(img, dim=1, keepdim=True)[0]indices = torch.topk(dark.view(-1, imsz), k=numpx, dim=1)[1].view(-1, 1, numpx).expand(-1, 3, -1)# 用上述索引匹配原图中的3个通道,并求其平均值a = (torch.gather(img.view(-1, 3, imsz), 2, indices).sum(2) / numpx).view(-1, 3, 1, 1)# 代公式算txtx = 1 - omega * torch.min(img / a.view(-1, 3, 1, 1), dim=1, keepdim=True)[0]# 代公式算jxreturn (img - a) / torch.clamp_min(tx, 0.1) + aclass DCPExport(torch.nn.Module):def forward(self, x, omega):return dcp(x, omega)def export(output='dcp.onnx'):torch.onnx.export(DCPExport(), (torch.randn(1, 3, 255, 255, dtype=torch.float32), torch.tensor(0.75, dtype=torch.float32)), 'dcp.onnx', input_names=['fog_image', 'omega'], output_names=['clear_image'], dynamic_axes={'fog_image': {0: 'batch', 2: 'height', 3: 'width'},'clear_image': {0: 'batch', 2: 'height', 3: 'width'},})onnx_model = onnx.load(output) model_simp, check = simplify(onnx_model) assert check, "简化模型失败" onnx.save(model_simp, output) if __name__ == '__main__':export()
导出结果如下:
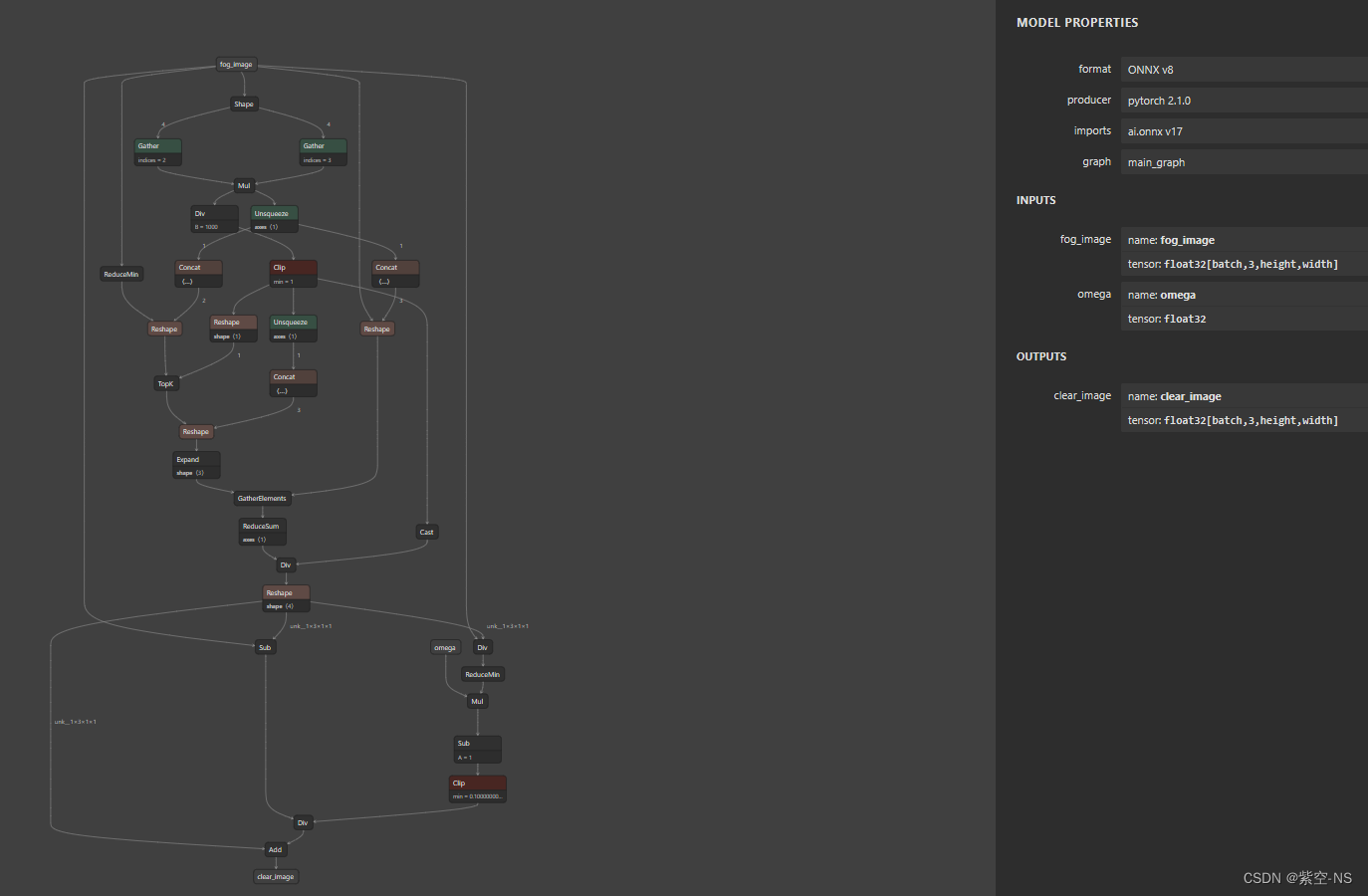
导出后的onnx输入输出如下:
- 输入:
- fog_image[float32]:形状为NCHW,且归一化的有雾图像,其中通道数C必须为3
- omega[float32]:dcp的参数,类型为浮点数
- 输出:
- clear_image[float32]:形状为NCHW,且归一化的无雾图像,其中通道数C为3
下载链接:https://pan.baidu.com/s/1A1jSJQBFCGTeM8vbHOrysQ?pwd=tl6p
测试
用cv2和pil都可以:
import numpy as np
import cv2
from PIL import Image
from onnxruntime import InferenceSessionmodel = InferenceSession('dcp.onnx')# CV2读图
image = cv2.imread('dehaze/dehaze/input/images/indoor1.jpg')
# 这里说明一下,因为dcp对所有通道进行同等变换,所以不用bgr和rgb互转了,出来的结果都是一样的
# x = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
x = np.transpose(image, (2, 0, 1))[None].astype(np.float32) / 255.
res = model.run(['clear_image'], {'fog_image': x, 'omega': np.array(0.75, dtype=np.float32)})[0][0]
res = np.transpose(res, (1, 2, 0))
res = np.clip(res*255+0.5, 0, 255).astype(np.uint8)
# res = cv2.cvtColor(res, cv2.COLOR_RGB2BGR)
cv2.imwrite('onnx-cv.png', np.concatenate((image, res), 1))# PIL读图
image = Image.open('dehaze/dehaze/input/images/indoor1.jpg')
x = np.transpose(image, (2, 0, 1))[None].astype(np.float32) / 255.
res = model.run(None, {'fog_image': x, 'omega': np.array(0.75, dtype=np.float32)})[0][0]
res = np.transpose(res, (1, 2, 0))
res = np.clip(res*255+0.5, 0, 255).astype(np.uint8)
Image.fromarray(np.concatenate((image, res), 1)).save('onnx-pil.png')
效果:

这篇关于pytorch实现DCP暗通道先验去雾算法及其onnx导出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







