本文主要是介绍Flink SQL窗口表值函数(Window TVF)聚合实现原理浅析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方蓝色字体,选择“设为星标”
回复"面试"获取更多惊喜
八股文教给我,你们专心刷题和面试

Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。
引子
表值函数(table-valued function, TVF),顾名思义就是指返回值是一张表的函数,在Oracle、SQL Server等数据库中屡见不鲜。
而在Flink的上一个稳定版本1.13中,社区通过FLIP-145提出了窗口表值函数(window TVF)的实现,用于替代旧版的窗口分组(grouped window)语法。
举个栗子,在1.13之前,我们需要写如下的Flink SQL语句来做10秒的滚动窗口聚合:
SELECT TUMBLE_START(procTime, INTERVAL '10' SECONDS) AS window_start,merchandiseId,COUNT(1) AS sellCount
FROM rtdw_dwd.kafka_order_done_log
GROUP BY TUMBLE(procTime, INTERVAL '10' SECONDS),merchandiseId;在1.13版本中,则可以改写成如下的形式:
SELECT window_start,window_end,merchandiseId,COUNT(1) AS sellCount
FROM TABLE( TUMBLE(TABLE rtdw_dwd.kafka_order_done_log, DESCRIPTOR(procTime), INTERVAL '10' SECONDS) )
GROUP BY window_start,window_end,merchandiseId;根据设计文档的描述,窗口表值函数的思想来自2019年的SIGMOD论文<>,而表值函数属于SQL 2016标准的一部分。
Calcite从1.25版本起也开始提供对滚动窗口和滑动窗口TVF的支持。
除了标准化、易于实现之外,窗口TVF还支持旧版语法所不具备的一些特性,如Local-Global聚合优化、Distinct解热点优化、Top-N支持、GROUPING SETS语法等。
接下来本文简单探究一下基于窗口TVF的聚合逻辑,以及对累积窗口TVF做一点简单的改进。
SQL定义
窗口TVF函数的类图如下所示。
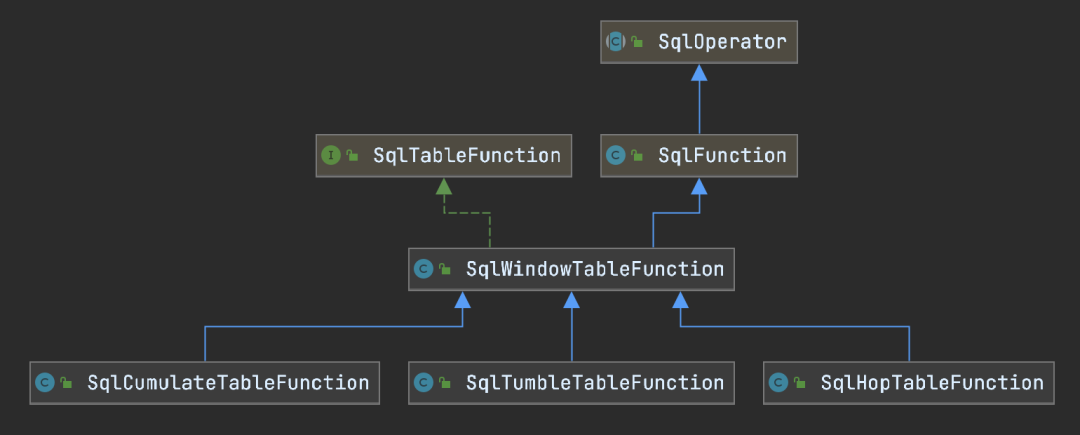
Flink SQL在Calcite原生的SqlWindowTableFunction的基础上加了指示窗口时间的三列,即window_start、window_end和window_time。
SqlWindowTableFunction及其各个实现类的主要工作是校验TVF的操作数是否合法(通过内部抽象类AbstractOperandMetadata和对应的子类OperandMetadataImpl)。这一部分不再赘述,在下文改进累积窗口TVF的代码中会涉及到。
物理计划
目前窗口TVF不能单独使用,需要配合窗口聚合或Top-N一起使用。以上文中的聚合为例,观察其执行计划如下。
EXPLAIN
SELECT window_start,window_end,merchandiseId,COUNT(1) AS sellCount
FROM TABLE( TUMBLE(TABLE rtdw_dwd.kafka_order_done_log, DESCRIPTOR(procTime), INTERVAL '10' SECONDS) )
GROUP BY window_start,window_end,merchandiseId;== Abstract Syntax Tree ==
LogicalAggregate(group=[{0, 1, 2}], sellCount=[COUNT()])
+- LogicalProject(window_start=[$48], window_end=[$49], merchandiseId=[$10])+- LogicalTableFunctionScan(invocation=[TUMBLE($47, DESCRIPTOR($47), 10000:INTERVAL SECOND)], rowType=[RecordType(BIGINT ts, /* ...... */, TIMESTAMP_LTZ(3) *PROCTIME* procTime, TIMESTAMP(3) window_start, TIMESTAMP(3) window_end, TIMESTAMP_LTZ(3) *PROCTIME* window_time)])+- LogicalProject(ts=[$0], /* ...... */, procTime=[PROCTIME()])+- LogicalTableScan(table=[[hive, rtdw_dwd, kafka_order_done_log]])== Optimized Physical Plan ==
Calc(select=[window_start, window_end, merchandiseId, sellCount])
+- WindowAggregate(groupBy=[merchandiseId], window=[TUMBLE(time_col=[procTime], size=[10 s])], select=[merchandiseId, COUNT(*) AS sellCount, start('w$) AS window_start, end('w$) AS window_end])+- Exchange(distribution=[hash[merchandiseId]])+- Calc(select=[merchandiseId, PROCTIME() AS procTime])+- TableSourceScan(table=[[hive, rtdw_dwd, kafka_order_done_log]], fields=[ts, /* ...... */])== Optimized Execution Plan ==
Calc(select=[window_start, window_end, merchandiseId, sellCount])
+- WindowAggregate(groupBy=[merchandiseId], window=[TUMBLE(time_col=[procTime], size=[10 s])], select=[merchandiseId, COUNT(*) AS sellCount, start('w$) AS window_start, end('w$) AS window_end])+- Exchange(distribution=[hash[merchandiseId]])+- Calc(select=[merchandiseId, PROCTIME() AS procTime])+- TableSourceScan(table=[[hive, rtdw_dwd, kafka_order_done_log]], fields=[ts, /* ...... */])在Flink SQL规则集中,与如上查询相关的规则按顺序依次是:
ConverterRule:StreamPhysicalWindowTableFunctionRule
该规则将调用窗口TVF的逻辑节点(即调用SqlWindowTableFunction的LogicalTableFunctionScan节点)转化为物理节点(StreamPhysicalWindowTableFunction)。
ConverterRule:StreamPhysicalWindowAggregateRule
该规则将含有window_start、window_end字段的逻辑聚合节点FlinkLogicalAggregate转化为物理的窗口聚合节点StreamPhysicalWindowAggregate以及其上的投影StreamPhysicalCalc。在有其他分组字段的情况下,还会根据FlinkRelDistribution#hash生成StreamPhysicalExchange节点。
RelOptRule:PullUpWindowTableFunctionIntoWindowAggregateRule
顾名思义,该规则将上面两个规则产生的RelNode进行整理,消除代表窗口TVF的物理节点,并将它的语义上拉至聚合节点中,形成最终的物理计划。
然后,StreamPhysicalWindowAggregate节点翻译成StreamExecWindowAggregate节点,进入执行阶段。
切片化窗口与执行
以前我们提过粒度太碎的滑动窗口会使得状态和Timer膨胀,比较危险,应该用滚动窗口+在线存储+读时聚合的方法代替。
社区在设计窗口TVF聚合时显然考虑到了这点,提出了切片化窗口(sliced window)的概念,并以此为基础设计了一套与DataStream API Windowing不同的窗口机制。
如下图的累积窗口所示,每两条纵向虚线之间的部分就是一个切片(slice)。
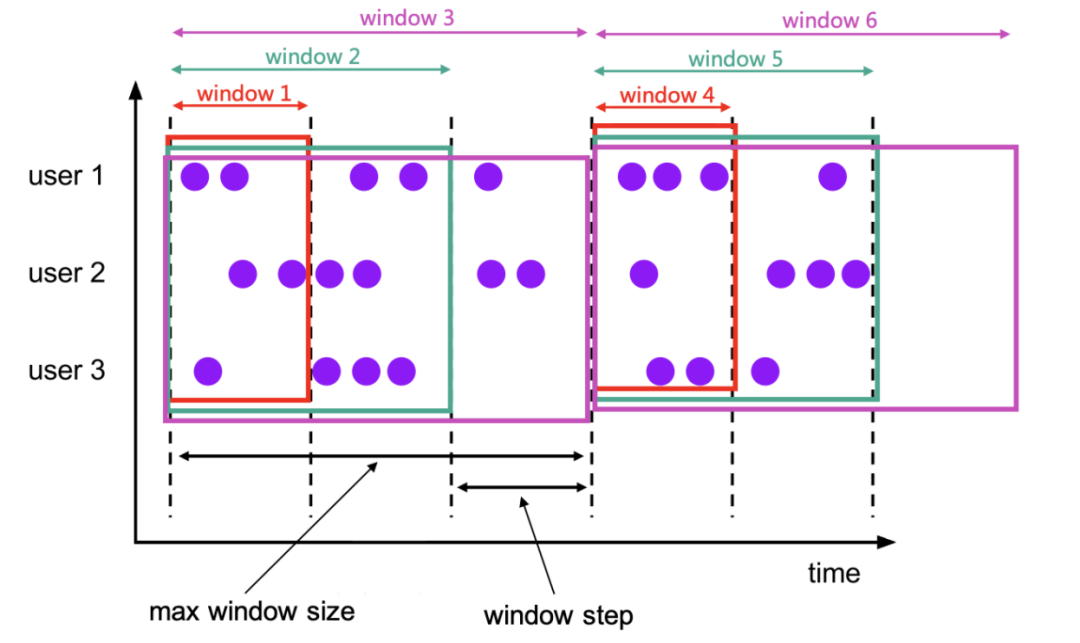
切片的本质就是将滑动/累积窗口化为滚动窗口,并尽可能地复用中间计算结果,降低状态压力。
自然地,前文所述的Local-Global聚合优化、Distinct解热点优化就都可以无缝应用了。
那么,切片是如何分配的呢?答案是通过SliceAssigner体系,其类图如下。
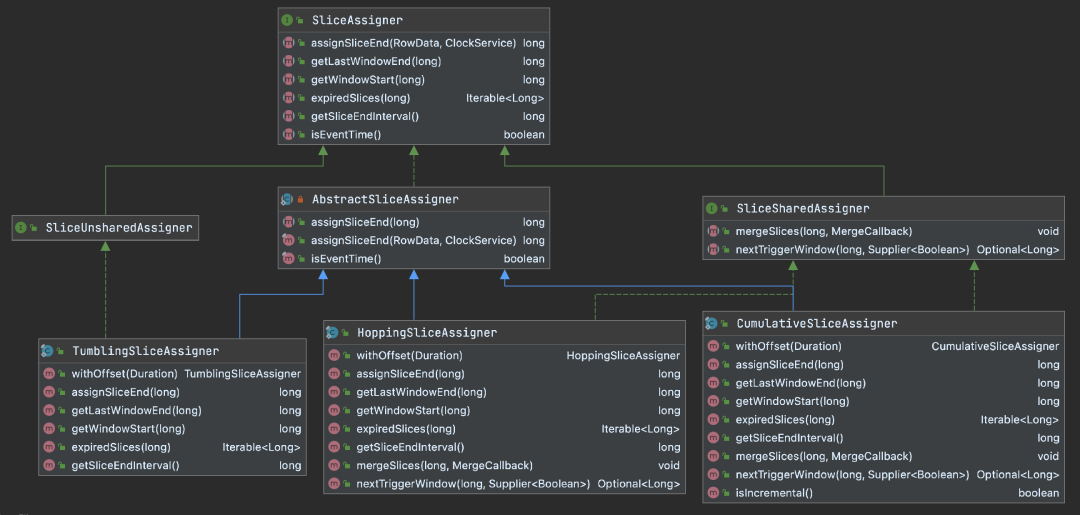
注意CumulativeSliceAssigner多了一个isIncremental()方法,这是下文所做优化的一步可见,对于滚动窗口而言,一个窗口就是一个切片;而对滑动/累积窗口而言,一个窗口可能包含多个切片,一个切片也可能位于多个窗口中。
所以共享切片的窗口要特别注意切片的过期与合并。
以负责累积窗口的CumulativeSliceAssigner为例,对应的逻辑如下。
@Override
public Iterable<Long> expiredSlices(long windowEnd) {long windowStart = getWindowStart(windowEnd);long firstSliceEnd = windowStart + step;long lastSliceEnd = windowStart + maxSize;if (windowEnd == firstSliceEnd) {// we share state in the first slice, skip cleanup for the first slicereuseExpiredList.clear();} else if (windowEnd == lastSliceEnd) {// when this is the last slice,// we need to cleanup the shared state (i.e. first slice) and the current slicereuseExpiredList.reset(windowEnd, firstSliceEnd);} else {// clean up current slicereuseExpiredList.reset(windowEnd);}return reuseExpiredList;
}@Override
public void mergeSlices(long sliceEnd, MergeCallback callback) throws Exception {long windowStart = getWindowStart(sliceEnd);long firstSliceEnd = windowStart + step;if (sliceEnd == firstSliceEnd) {// if this is the first slice, there is nothing to mergereuseToBeMergedList.clear();} else {// otherwise, merge the current slice state into the first slice statereuseToBeMergedList.reset(sliceEnd);}callback.merge(firstSliceEnd, reuseToBeMergedList);
}可见,累积窗口的中间结果会被合并到第一个切片中。窗口未结束时,除了第一个切片之外的其他切片触发后都会过期。
实际处理切片化窗口的算子名为SlicingWindowOperator,它实际上是SlicingWindowProcessor的简单封装。SlicingWindowProcessor的体系如下。
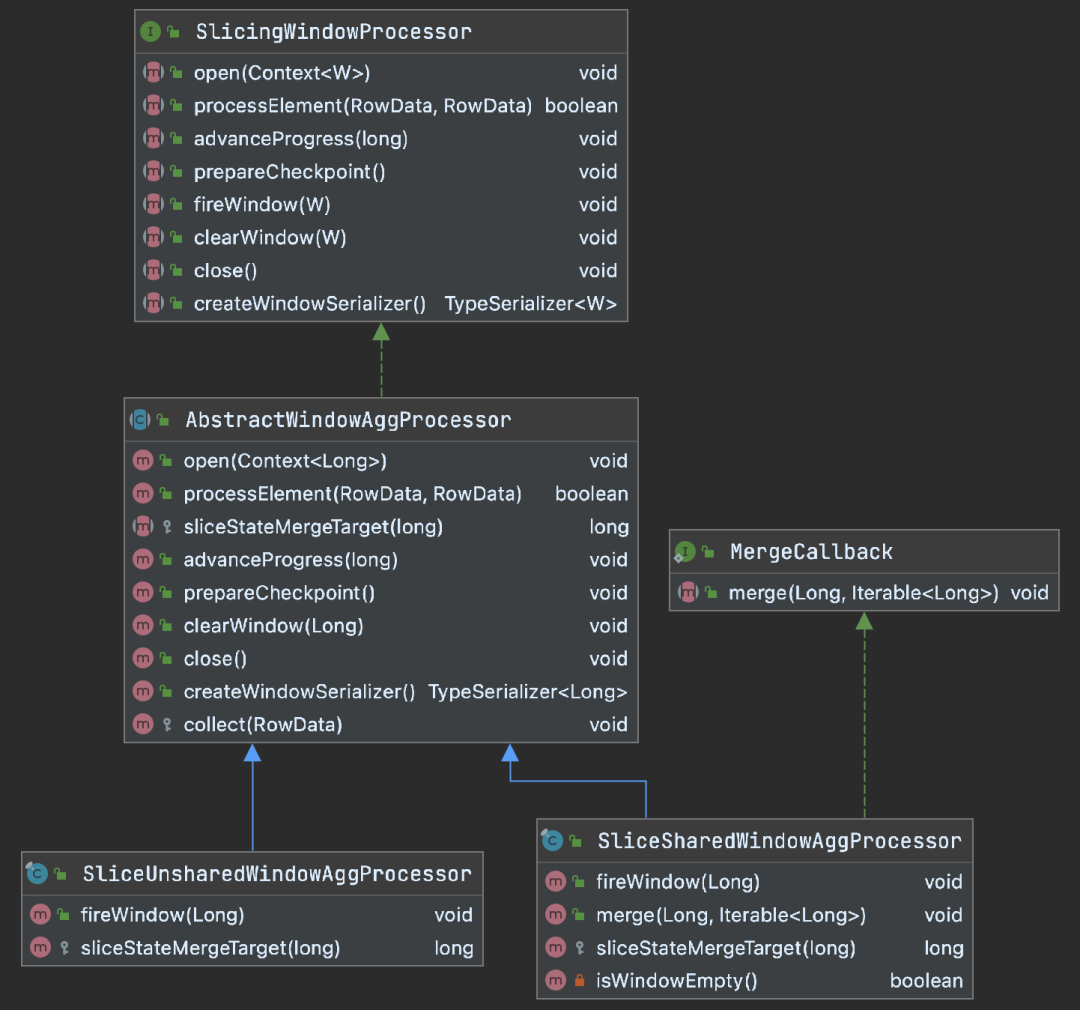
SlicingWindowProcessor的三个重要组成部分分别是:
WindowBuffer:在托管内存区域分配的窗口数据缓存,避免在窗口未实际触发时高频访问状态;
WindowValueState:窗口的状态,其schema为[key, window_end, accumulator]。窗口结束时间作为窗口状态的命名空间(namespace);
NamespaceAggsHandleFunction:通过代码生成器AggsHandlerCodeGenerator生成的聚合函数体。注意它并不是一个AggregateFunction,但是大致遵循其规范。
每当一条数据到来时,调用AbstractWindowAggProcessor#processElement()方法,比较容易理解了。
@Override
public boolean processElement(RowData key, RowData element) throws Exception {long sliceEnd = sliceAssigner.assignSliceEnd(element, clockService);if (!isEventTime) {// always register processing time for every element when processing time modewindowTimerService.registerProcessingTimeWindowTimer(sliceEnd);}if (isEventTime && isWindowFired(sliceEnd, currentProgress, shiftTimeZone)) {// the assigned slice has been triggered, which means current element is late,// but maybe not need to droplong lastWindowEnd = sliceAssigner.getLastWindowEnd(sliceEnd);if (isWindowFired(lastWindowEnd, currentProgress, shiftTimeZone)) {// the last window has been triggered, so the element can be dropped nowreturn true;} else {windowBuffer.addElement(key, sliceStateMergeTarget(sliceEnd), element);// we need to register a timer for the next unfired window,// because this may the first time we see elements under the keylong unfiredFirstWindow = sliceEnd;while (isWindowFired(unfiredFirstWindow, currentProgress, shiftTimeZone)) {unfiredFirstWindow += windowInterval;}windowTimerService.registerEventTimeWindowTimer(unfiredFirstWindow);return false;}} else {// the assigned slice hasn't been triggered, accumulate into the assigned slicewindowBuffer.addElement(key, sliceEnd, element);return false;}
}而当切片需要被合并时,先从WindowValueState中取出已有的状态,再遍历切片,并调用NamespaceAggsHandleFunction#merge()方法进行合并,最后更新状态。
@Override
public void merge(@Nullable Long mergeResult, Iterable<Long> toBeMerged) throws Exception {// get base accumulatorfinal RowData acc;if (mergeResult == null) {// null means the merged is not on state, create a new accacc = aggregator.createAccumulators();} else {RowData stateAcc = windowState.value(mergeResult);if (stateAcc == null) {acc = aggregator.createAccumulators();} else {acc = stateAcc;}}// set base accumulatoraggregator.setAccumulators(mergeResult, acc);// merge slice accumulatorsfor (Long slice : toBeMerged) {RowData sliceAcc = windowState.value(slice);if (sliceAcc != null) {aggregator.merge(slice, sliceAcc);}}// set merged acc into state if the merged acc is on stateif (mergeResult != null) {windowState.update(mergeResult, aggregator.getAccumulators());}
}看官若要观察codegen出来的聚合函数的代码,可在log4j.properties文件中加上:
logger.codegen.name = org.apache.flink.table.runtime.generated
logger.codegen.level = DEBUG一点改进
有很多天级聚合+秒级触发的Flink作业,在DataStream API时代多由ContinuousProcessingTimeTrigger实现,1.13版本之前的SQL则需要添加table.exec.emit.early-fire系列参数。
正式采用1.13版本后,累积窗口(cumulate window)完美契合此类需求。
但是,有些作业的key规模比较大,在一天的晚些时候会频繁向下游Redis刷入大量数据,造成不必要的压力。
因此,笔者对累积窗口TVF做了略有侵入的小改动,通过一个布尔参数INCREMENTAL可控制只输出切片之间发生变化的聚合结果。
操作很简单:
修改SqlCumulateTableFunction函数的签名,以及配套的窗口参数类CumulativeWindowSpec等;
修改SliceSharedWindowAggProcess#fireWindow()方法,如下。
@Override
public void fireWindow(Long windowEnd) throws Exception {sliceSharedAssigner.mergeSlices(windowEnd, this);// we have set accumulator in the merge() methodRowData aggResult = aggregator.getValue(windowEnd);if (!isWindowEmpty()) {if (sliceSharedAssigner instanceof CumulativeSliceAssigner&& ((CumulativeSliceAssigner) sliceSharedAssigner).isIncremental()) {RowData stateValue = windowState.value(windowEnd);if (stateValue == null || !stateValue.equals(aggResult)) {collect(aggResult);}} else {collect(aggResult);}}// we should register next window timer here,// because slices are shared, maybe no elements arrived for the next slices// ......
}当然,此方案会带来访问状态的overhead,后续会做极限压测以观察性能,并做适当修改。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
这篇关于Flink SQL窗口表值函数(Window TVF)聚合实现原理浅析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







