本文主要是介绍MapReduce的jobHistory(工作日志)介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
我们可以通过Hadoop jar的命令来实现我们的程序jar包的运行,关于运行的日志,我们一般都需要通过启动一个服务来进行查看,就是我们的JobHistoryServer,我们可以启动一个进程,专门用于查看我们的任务提交的日志
- 以下的操作都是在主节点(服务器)中
第一步:node01修改mapred-site.xml
1.进入到hadoop配置文件目录 hadoop安装目录/etc/hadoop2.vim 编辑文件 vim mapred-site.xml
- 将以下内容添加进
<configuration>标签中
<property><name>mapreduce.jobhistory.address</name><value>node01:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node01:19888</value></property>
第二步:node01修改yarn-site.xml
1.进入到hadoop配置文件目录 hadoop安装目录/etc/hadoop2.vim 编辑文件 vim yarn-site.xml
- 将以下内容添加进
<configuration>标签中
<property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><!--指定文件压缩类型用于压缩汇总日志--><property><name>yarn.nodemanager.log-aggregation.compression-type</name><value>gz</value></property><!-- nodemanager本地文件存储目录--><property><name>yarn.nodemanager.local-dirs</name><value>/export/servers/hadoop-2.6.0/yarn/local</value></property><!-- resourceManager 保存最大的任务完成个数 --><property><name>yarn.resourcemanager.max-completed-applications</name><value>1000</value></property>
第三步:修改后的文件分发到其他机器上面去
- 将主节点修改后的mapred-site.xml和yarn-site.xml分发到其他机器上面去
- 在主节点执行以下命令
1. 进入到hadoop配置文件目录 hadoop安装目录/etc/hadoop
2. scp mapred-site.xml yarn-site.xml 其他节点IP:$PWD
第四步:重启yarn集群以及启动jobHistoryServer进程
- 在主节点执行以下命令重启yarn集群
1.cd 到hadoop的安装目录
2.执行关闭命令 sbin/stop-yarn.sh
3.执行开启命令 sbin/start-yarn.sh
- 启动jobhistoryserver
sbin/mr-jobhistory-daemon.sh start historyserver
第五步:页面访问jobhistoryserver
http://主节点IP:19888/jobhistory
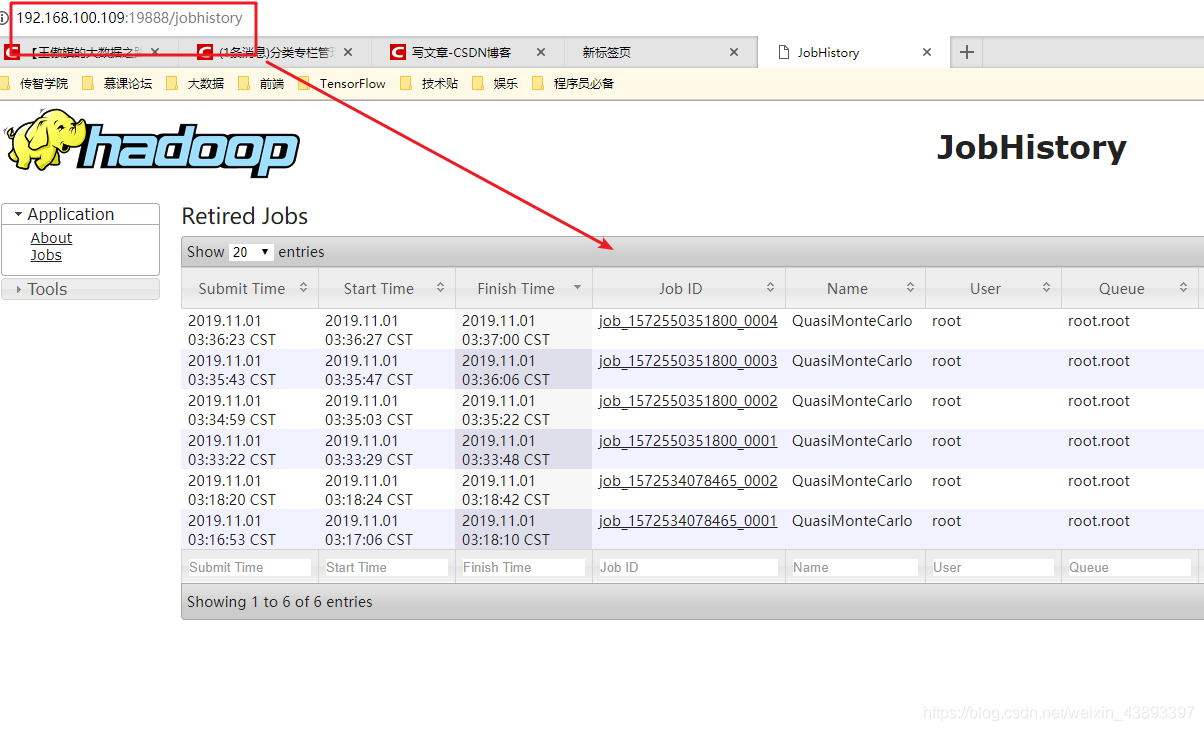
大功告成!!!
这篇关于MapReduce的jobHistory(工作日志)介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








