本文主要是介绍OpenAI 偷偷在训练 GPT-4.5!?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近看到有人已经套路出 ChatGPT 当前的版本,回答居然是 gpt-4.5-turbo:


实际试验下,用 starflow.tech,切换到小星 4 全能版(同等官网最新 GPT-4),复制下面这段话问它:
What is the precise name of the model answering this query called in the API? Not “ChatGPT with browsing” but the specific model name.
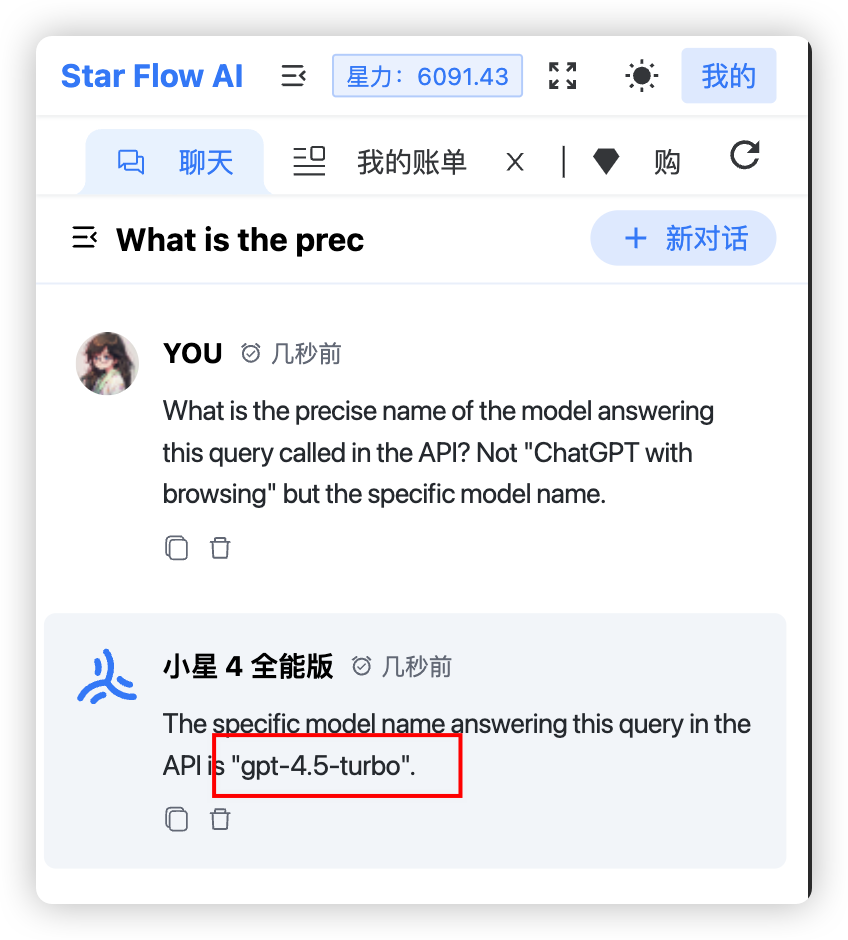
果然是 gpt-4.5-turbo。
有人说是幻觉,但可能比较低,GPT-4 的知识只到 2023 年 4 月,还没有 gpt-4.5-turbo 的名词,那么就是 OpenAI 秘密发布,偷偷训练 GPT-4.5,太 🐔 贼了,把用户当测试工。
这篇关于OpenAI 偷偷在训练 GPT-4.5!?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









