本文主要是介绍一劳永逸—MIT韩松团队开源神经网络的高效部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文首发于微信公众号 CVHub,不得以任何形式转载到其它平台,仅供学习交流,违者必究!
引言
本文为大家介绍一篇神经网络压缩方面相关的经典论文,由MIT 韩松团队发表于ICLR 2020的论文《Once-for-All: Train One Network and Specialize it for Efficient Deployment》.
本文是通过一种 Once for All 的网络,可高效生成 10^19 独立工作的子网络以便适配到不同的硬件平台,包括服务器端各种不同的GPU模型(Nvidia 1080Ti, 2080Ti, V100)、CPU(Inter Xeon 系列)以及移动端各种不同的边缘设备等,实际工程应用价值很大,非常值得一读并实践。
一、背景
为了能够在资源受限型的设备上进行更加高效的推理,以往的方法主要有两种,手工设计网络诸如SqueezeNet,MoblieNetV1-V2和ShuffleNets等;或结合网络架构搜索技术NAS,如MobilieNetV3和NASNet等。其中,手工设计的特征不仅费时费力,并且不具备良好的通用性。另一方面,NAS技术则是结合相关搜索策略在给定的搜索空间内寻找出能尽量拟合当前数据最佳模型,毫无疑问这是非常消耗计算资源的,因为通常来说它需要为每一种设计组合从头训练一遍网络,直至设定好的终止条件。此外,在给定新的推理硬件平台的情况下,这些方法也需要重复架构搜索过程并重新训练模型,从而导致总的开发成本过高。
本文从实际应用角度出发,提出了一种One-For-All(OFA)的通用神经网络。通过解耦训练和搜索来支持不同的架构设置,可以灵活地支持不同的深度,宽度,卷积核和分辨率四个维度,而无需重新训练,利用所提出的渐进式搜索训练(PST)策略在同等的资源消耗下显著的提高了网络模型的性能。
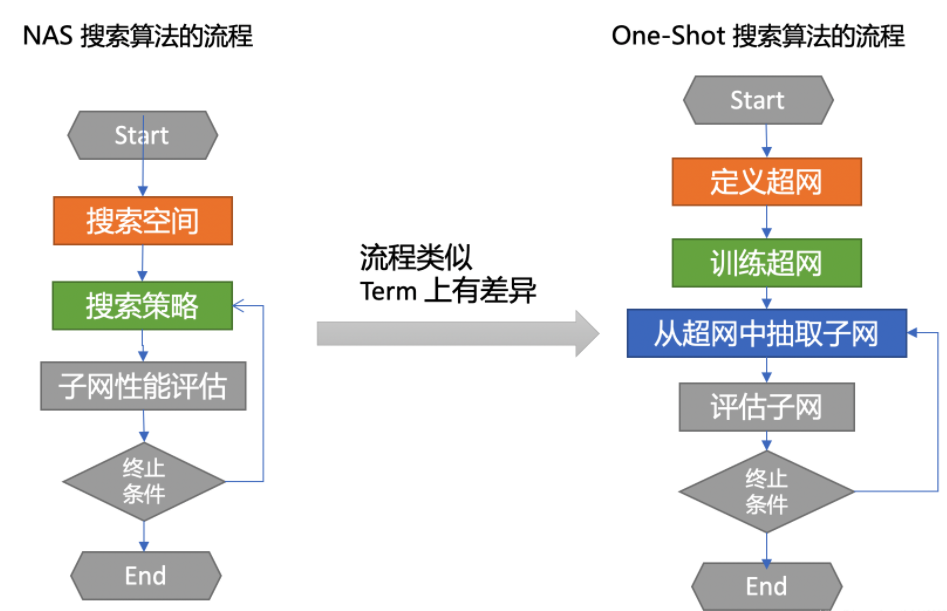
一般的NAS算法通常包含几个步骤:
- 定义网络的搜索空间(最大层数,每个节点可选择的操作);
- 设计搜索策略(如何探索空间,目前主流的有强化学习,进化算法,梯度优化);
- 对每个子网络进行评估。
One-Shot NAS,简称OSN,与一般NAS最大的不同之处在于其是训练一个超网,然后在超网上做减法(类似于剪枝),而之前的NAS更像是从小网络开始做加法。
二、方法
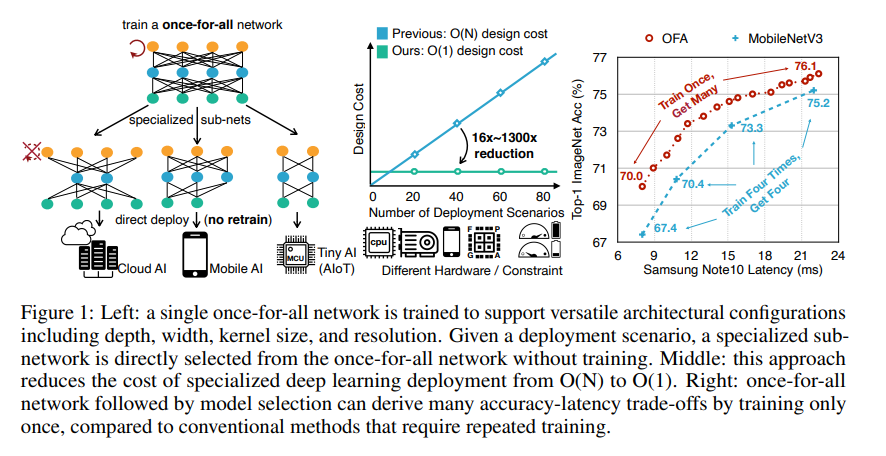
上图是本文的整体预览效果图,下面首先给出OFA的优化目标:
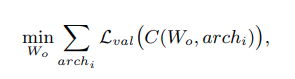
这里,W为大型网络,arch为特定的子结构,C为搜索策略。其核心思想便是利用方法C从W中挑选出一个子网络进行训练,使其精度不断逼近arch。
2.1 OFA网络
- Units:单元数,即模块,共5个;
- Elastic depth:网络深度,搜索空间为{2, 3, 4};
- Elastic width:网络宽度,搜索空间为{3, 4, 6};
- Elastic kernel-size:卷积核大小,搜索空间为{3, 5, 7};
- Arbitrary resolution:图像分辨率,搜索空间为[128, 224],间隔为4,共25个输入分辨率;
因此,候选子网总数为:
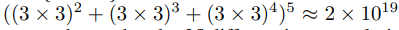
- 所有子网共享超网的部分权重
W,因此仅需7.7M的参数量去存储这些子网; - 这里的超网可以是
vanilla Resnet或MobileNet等,限定其最大搜索空间。
2.2 PST策略
动机 如何更加高效的训练多个子网?
方法
- 暴力法:更新全部子网的梯度(
计算代价高) - 部分法:更新部分子网的梯度(
收敛较困难) - 渐进式衰减法:由大到小逐渐逼近(
综合性能好)
# CAUTION: 伪代码
# 定义动态网络
net = dynamic_net()
for step in len(samples) / batch_size:# 获得动态 Block blobs = net.blocks # 对每个动态 block 均匀采样 for b in blobs: b.active_kernel = random.uniform([3, 5, 7]) b.active_out_channel = random.uniform([32, 64, 128, 256]) b.active_depth = random.uniform([3, 5, 7]) net.train() net.update_parameters()

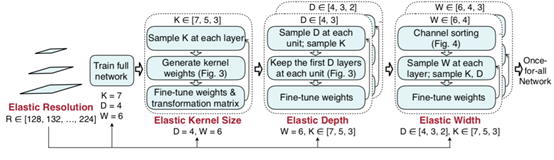
- 首先,先训练整个超网,取设定好的内核数、通道数和网络深度;
- 在完成
步骤1后,保持depth和width不变,依次改变K的值进行训练直至收敛; - 同
步骤2,在保持任意两个变量取最大值的情况,依次改变剩余变量的值微调模型。
注意
对于resolution维度的变化是体现在以上训练过程中每个batch上,即多尺度训练;
这里训练完
步骤1之后会先采用知识蒸馏得到一个相对较小的模型作为超网。
2.2.1 Elastic Kernel Size
以搜索空间为{3, 5, 7}的卷积核为例,首先训练完7x7大小的卷积核后,中间区域的权重保持共享。这样会存在一个问题就是不同的卷积核可能代表不同的网络分布,如果强制保持一致的话会导致其性能下降。因此,这里采用一个变换矩阵来实现权重共享,实现原理也很简单,可以利用一个MLP来完成此项功能。此外,对于同个stage内,不同通道之间的变换矩阵是共享的;不同stage的话会重新定义一个变幻矩阵。所以所需存储的参数量变为25x25+3x3=706个额外参数来存储每一层的核变换矩阵。
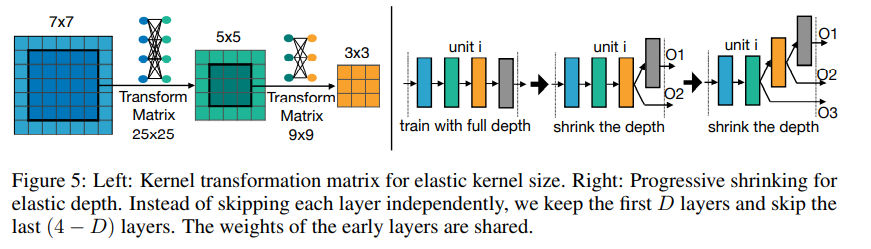
2.2.2 Elastic Depth
如上图5右手边所示,网络深度也是可以动态调整,作者采用的是跳层来实现深度的动态变化。较深的网络可以直接把后几层跳过,例如,深度为4的网络可以只选取前3层,从而得到深度为3的网络。而取前三层的原因是因为权重是共享的,按经验来说,从前往后取的效果更好。
2.2.3 Elastic Width
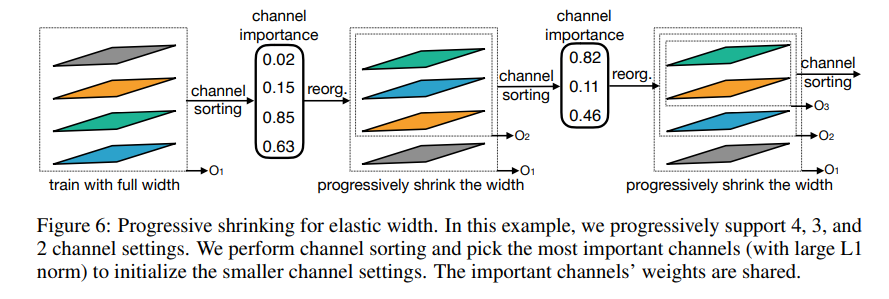
如图6所示,每层卷积对应的输入和输出通道数也是可以动态调整而非固定的,不过这里会先进行通道重要性指标的排序后,再通过slices来实现,逐步选取前n个重要的通道进行训练逐步衰减。
需要注意的是这里通道重要性计算方法采用的是
L1 norm,即数值越大代表对应的通道重要性成都越高。
class DynamicConv2D(nn.Module): def __init__(self,kernel_list = [3, 5, 7], in_channel_list = [3], out_channel_list = [32, 64, 128]):# 这里的 active 都取最大,但在训练中# 会使用 random 来选择动态的参数self.max_kernel = max(kernel_list) self.active_kernel = max(kernel_list) self.active_in_channel = max(in_channel_list) self.active_out_channel = max(out_channel_list) self.conv = nn.Conv2d(self.active_in_channel, self.active_out_channel, self.active_kernel) def forward(self, x): # 取中心的卷积核对应的下标 start, end = sub_filter_start_end(self.max_kernel, self.active_kernel) # Filters 的 Size = [out_channel, in_channel, kernel_size, kernel_size] filters = self.conv.weight[:self.active_out_channel, :self.active_in_channel, start:end, start:end] # 需要先 flatten,然后与 transform matrix 相乘 transfer_filter = F.linear(filters, transform_matrix) y = F.conv2d(x, transfer_filter, self.active_in_channel, self.active_out_channel) return y
需要注意的是,在实现的过程中需要对所有相关的op进行适配,以动态适应不同超参的输入。
2.3 评估策略
常规的评估方法为在测试集上对每个子网络的效果进行评估,毫无疑问这种方式是非常耗时的。因此作者设计了一个子网络精度评估器,这个评估器的输入是待评估子网的架构参数Oe-Hot Encoding输出是预测该子网精度数值,通过这种方式,只需要做一次推断便可以预测该子网的大致性能。
# accuracy predictor
accuracy_predictor = AccuracyPredictor(pretrained=True,device='cuda:0' if cuda_available else 'cpu'
)print(accuracy_predictor.model)Sequential((0): Linear(in_features=128, out_features=400, bias=True)(1): ReLU()(2): Linear(in_features=400, out_features=400, bias=True)(3): ReLU()(4): Linear(in_features=400, out_features=400, bias=True)(5): ReLU()(6): Linear(in_features=400, out_features=1, bias=True)
)
一般做模型压缩,轻量化架构和搜索,是为了能在某些设备上更快的运行起来,拿手机设备举个例子,因为存在很多的不同厂商,因此不同的算子在不同的设备上的计算速度存在差异,为此,文中提到了延迟查找表的概念,也就是说我们把我们要用到的算子在设备上进行一次基准测试,然后我们在预估模型在设备上计算时长的时候,就只需要查表就可以了,不用一次次的去部署然后做基准测试。
2.4 选取策略
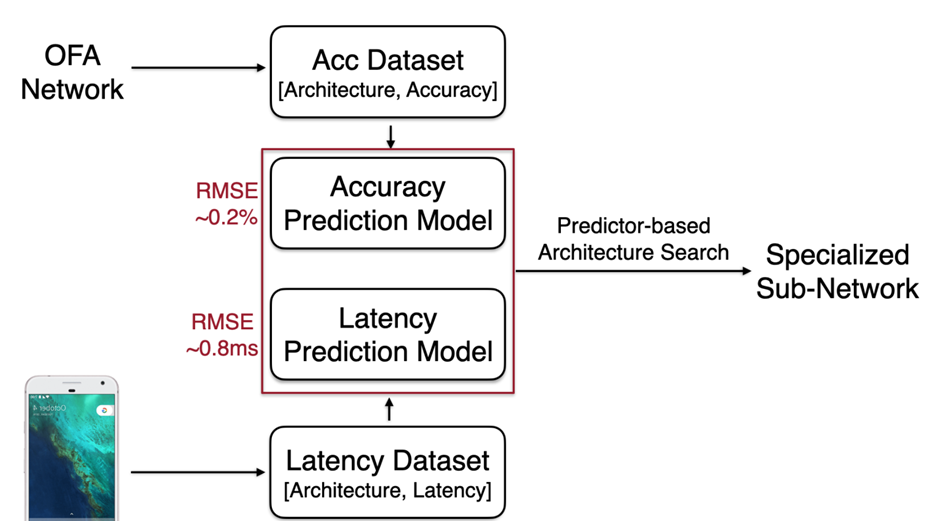
获得了子网络的精度,以及子网络的运行速度,接下来就可以根据需求对子网络进行搜索和评估。作者使用了演化算法(Regularized Evolution for Image Classifier Architecture Search)来搜索子网络,流程上来说可以分为以下四步:
- 随机选择
N个子网络作为初始种群; - 选择初始化种群的一部分子网络进行采样;
- 选择初始化种群的另外一部分子网络之间进行交叉采样获得杂交后的子网络;
st2到st3迭代500次,返回精度最高且满足耗时要求的网络。
# CAUTION: 伪代码,删减了一些边界判断和变量声明,完整的请查阅源码def random_sample_net(self, net):# 随机采样超网,获得子网subnet = copy(net)for b in subnet: b.active_kernel = random.uniform([3, 5, 7]) b.active_out_channel = random.uniform([32, 64, 128, 256]) b.active_depth = random.uniform([3, 5, 7])eff = self.efficiency_predictor.predict_efficiency(subnet)return subnet, effdef crossover_sample(self, net1, net2):# 先 copy net1new_sample = copy(net1)for key in new_sample.keys():if not isinstance(new_sample[key], list):continue# 然后对应的网络参数,在 net1 和 net2 中选择一个,模拟交叉的过程for i in range(len(new_sample[key])):new_sample[key][i] = random.choice([sample1[key][i], net2[key][i]])efficiency = self.efficiency_predictor.predict_efficiency(new_sample)return new_sample, efficiencydef run_evolution_search(self):# 这里先获取初始种群和对应的耗时for _ in range(population_size):sample, efficiency = self.random_sample(super_net)child_pool.append(sample)efficiency_pool.append(efficiency)# 获得种群个体的精度预测值accs = self.accuracy_predictor.predict_accuracy(child_pool)for i in range(population_size):population.append((accs[i].item(), child_pool[i], efficiency_pool[i]))# 完成种群初始化后,开始执行进化迭代for iter in tqdm(range(max_time_budget)):# 对所有子网络的精度进行倒序排序# 获取 top-k 精度的子网络作为进化迭代的种群parents = sorted(population, key=lambda x: x[0])[::-1][:parents_size]acc = parents[0][0]print('Iter: {} Acc: {}'.format(iter - 1, parents[0][0]))# 看是否大于历史最大精度,如大于,记录下来if acc > best_valids[-1]:best_valids.append(acc)best_info = parents[0]else:best_valids.append(best_valids[-1])population = parentschild_pool = []efficiency_pool = []# 抽取一部分进行变异,也就是再采样该网络for i in range(mutation_numbers):par_sample = population[np.random.randint(parents_size)][1]new_sample, efficiency = self.mutate_sample(par_sample)child_pool.append(new_sample)efficiency_pool.append(efficiency)# 抽取另外一部分进行杂交,也就是让两个网络的参数进行交叉for i in range(population_size - mutation_numbers):par_sample1 = population[np.random.randint(parents_size)][1]par_sample2 = population[np.random.randint(parents_size)][1]new_sample, efficiency = self.crossover_sample(par_sample1, par_sample2)child_pool.append(new_sample)efficiency_pool.append(efficiency)accs = self.accuracy_predictor.predict_accuracy(child_pool)for i in range(population_size):population.append((accs[i].item(), child_pool[i], efficiency_pool[i]))return best_valids, best_info
三、实验

作者这里用单张V100共花费了1,200个GPU hours大约是50天来完成整个训练过程。不过通常来说业务数据集并不会同ImageNet这么大,所以一般情况下几天应该就能搞定全部。
3.2 实验效果
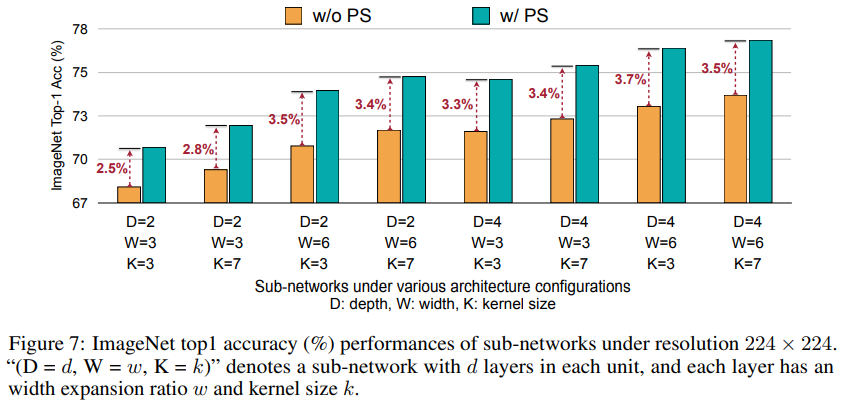
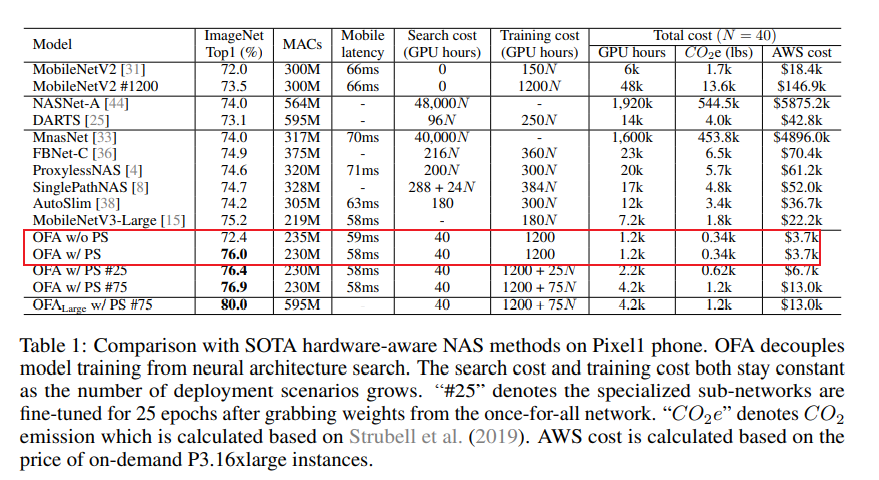
可以看出,采用OFA网络的GPU hours相比传统的NAS方法少了非常多,极大节省了成本开支。其次,结合PS策略可以获得更具性价比的精度,在不同的架构设置下均能取得3个点左右的性能提升。
四、总结
4.1 OFA核心步骤
训练- 正常训练一个最大的超网(动态分辨率、最大卷积核、最大宽度、最大深度)。OFA提供了官方训练的模型权重:ofa_D4_E6_K7,可直接使用。
微调- 对超网ofa_D4_E6_K7进行渐进式收缩(PS)训练,尽量使得所有子网也能有很好的表现。
搜索- 在超网中,使用进化算法和训练好的predictor在给定约束下(如latency FLOPs)进行搜索,得到满足约束的子网,结束算法。
4.2 PS策略实施步骤
train_ofa_net.py就是用于PS训练的脚本。train_ofa_net.py是分步骤分阶段进行的,每一次执行train_ofa_net.py都会将向采样空间添加新的元素进行训练,得到不同阶段的模型权重。训练过程如下:
将{3,5}的卷积核大小加入采样空间进行训练,得到权重ofa_D4_E6_K357
将{3}的深度大小加入采样空间进行训练,得到权重ofa_D34_E6_K357
将{2}的深度大小加入采样空间进行训练,得到权重ofa_D234_E6_K357
将{4}的宽度大小加入采样空间进行训练,得到权重ofa_D234_E46_K357
将{3}的宽度大小加入采样空间进行训练,得到权重ofa_D234_E346_K357
ofa_D234_E346_K357即为最终PS训练完成的模型权重。
4.3 子网的获取步骤
假设我们有一个子网的配置,试图从超网中获得一个独立的子网,需要经过以下三步:
设置子网
- 先对超网设置设置子网:
set_active_subnet(ks=net_config['ks'], d=net_config['d'], e=net_config['e'])
- 获得子网结构,并从超网中继承权重
get_active_subnet().
设置均值和方差
对子网中的BN层的mean和var进行重新估计:
calib_bn(subnet, path, net_config['r'][0], batch_size)
推理验证
validate(subnet, path, net_config['r'][0], data_loader, batch_size, device)
在步骤2中在超网的采样训练中,每一个子网进行训练时都会影响bn层中的均值mean和方差var。为了达到更好的性能,子网需要对BN层的均值mean和方差var根据该子网的结构进行重新统计,calib_bn()函数就是用于重新统计mean与var的函数,其构造了data_loader传入set_running_statistics函数进行统计,代码如下:
def set_running_statistics(model, data_loader, distributed=False):#用于记录每个batch下每个bn的mean和varbn_mean = {}bn_var = {}# copy一个模型forward_model = copy.deepcopy(model)for name, m in forward_model.named_modules():if isinstance(m, nn.BatchNorm2d):if distributed:bn_mean[name] = DistributedTensor(name + '#mean')bn_var[name] = DistributedTensor(name + '#var')else:bn_mean[name] = AverageMeter()bn_var[name] = AverageMeter()def new_forward(bn, mean_est, var_est):def lambda_forward(x):#统计每个batch的mean和varbatch_mean = x.mean(0, keepdim=True).mean(2, keepdim=True).mean(3, keepdim=True) # 1, C, 1, 1batch_var = (x - batch_mean) * (x - batch_mean)batch_var = batch_var.mean(0, keepdim=True).mean(2, keepdim=True).mean(3, keepdim=True)batch_mean = torch.squeeze(batch_mean)batch_var = torch.squeeze(batch_var)#更新记录mean_est.update(batch_mean.data, x.size(0))var_est.update(batch_var.data, x.size(0))# bn forward using calculated mean & var_feature_dim = batch_mean.size(0)return F.batch_norm(x, batch_mean, batch_var, bn.weight[:_feature_dim],bn.bias[:_feature_dim], False,0.0, bn.eps,)return lambda_forwardm.forward = new_forward(m, bn_mean[name], bn_var[name])if len(bn_mean) == 0:# skip if there is no batch normalization layers in the networkreturnwith torch.no_grad():DynamicBatchNorm2d.SET_RUNNING_STATISTICS = Truefor images, labels in data_loader:images = images.to(get_net_device(forward_model))forward_model(images)#inference一次,记录mean和var到bn_mean和bn_var中DynamicBatchNorm2d.SET_RUNNING_STATISTICS = False#将forward_model inference得到的runing_mean和runing_var复制到model中for name, m in model.named_modules():if name in bn_mean and bn_mean[name].count > 0:feature_dim = bn_mean[name].avg.size(0)assert isinstance(m, nn.BatchNorm2d)m.running_mean.data[:feature_dim].copy_(bn_mean[name].avg)#copy meanm.running_var.data[:feature_dim].copy_(bn_var[name].avg)#copy var
4.2 结束语
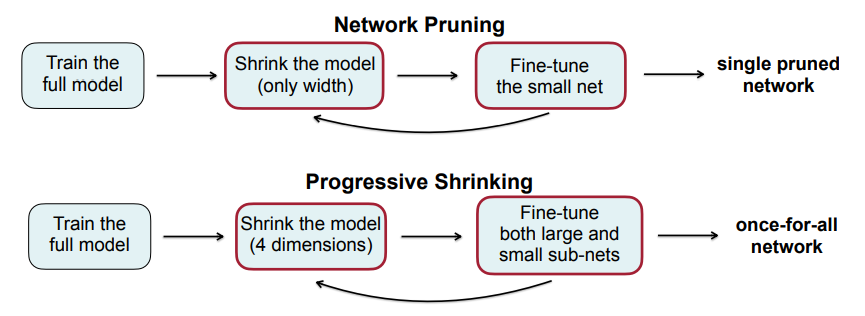
- OFA可认为是一种带剪枝算法的one-shot NAS,与常规的剪枝方法相比,它是从多个维度进行裁剪,而非单一维度;
- 其采用的PST不仅更新子网的权重,也会更新超网的权重使两者尽量对齐保持同步。
总的来说,本文提出了一种OFA的新方法,它将模型训练从架构搜索中分离出来,从而在大量的硬件平台下实现高效的深度学习部署。与以前为每个部署场景设计和训练神经网络的方法不同,它支持不同的体系结构配置,包括弹性深度、宽度、内核大小和分辨率。与传统方法相比,它大大降低了训练成本(GPU时间、能源消耗和二氧化碳排放)。为了防止不同规模的子网络受到干扰,提出了一种渐进收缩算法,使大量的子网络达到与独立训练相同的精度水平。在各种硬件平台和效率约束上的实验证明了该方法的有效性。
五、代码梳理
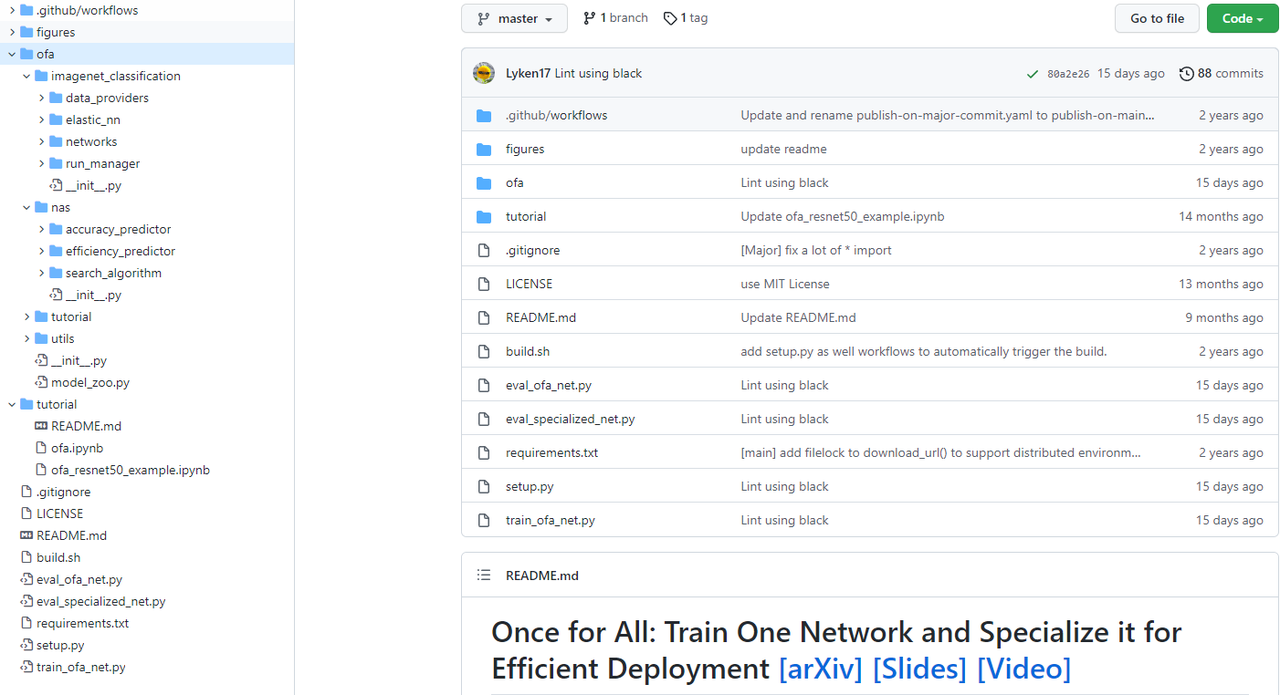
- ofa- imagenet_classification # 超网训练相关代码- elastic_nn # 子网代码- modules # 弹性模块- dynamic_layers.py # 动态层- dynamic_op.py # 动态op- networks # 弹性网络定义- ofa_mvb3.py # MobilenetV3- ofa_proxyless.py # ProxylessNASNets- ofa_resnets.py # Resnet- training # 渐进式训练- progress_shrinking.py # PST核心代码- networks # 常规网络定义- mobilenet_v3.py- proxyless_nets.py- resnets.py- run_manager # 训练核心代码- nas # 搜索部分- accuracy_predictor # 自定义的评估代码,详情见2.3- acc_dataset.py- acc_predictior.py- arch_encoder.py- efficiency_predictor- latency_looup_tabel.py # 性能查找表- search_algorithm- evolution.py # 进化算法,用于选取合适的子网
- train_ofa_net.py # 开始入口
CVHub专注于为大家提供高质量的精选文章和实用开源工具,后期考虑开源一哥一键算法模型API工具,支持限流、队列、轮询和频控能力,同时提供一站式实用算法仓库,敬请,更多精彩内容请关注官方WeChat公众号CVHub,期待关注,感谢大家一路的支持和陪伴,谢谢!
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号:cv_huber,一起探讨更多有趣的话题!
这篇关于一劳永逸—MIT韩松团队开源神经网络的高效部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








