本文主要是介绍【03】GeoScene创建海图或者电子航道图数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 配置Nautical属性
1.1 管理长名称
长名称(LNAM)是一个必要的对象标识符,是生产机构(AGEN)、要素识别号码(FIDN)和要素识别子项(FIDS)组件的串联。这三个子组件用于数据库中创建的每一个要素,以唯一地识别导出产品中的每个要素。
注:
在创建要素之前,必须设置用户名、机构和FIDS字段。还必须有一个S-57或S-100地理数据库。
步骤:
- 启动GeoScene Pro。
- 从 "视图 "标签,打开 "目录 "和 "内容 "窗格。
- 从目录窗格中,展开地理数据库,将EditingProperties表添加到内容窗格中。
- 右键单击EditingProperties表。
- 单击打开。
出现EditingProperties表。
注:
默认情况下,该表的第一行包含一个DEFAULT条目。
- 点击你想编辑的要素的机构下拉箭头,选择机构名称,例如:选择CN。

这个字段的值不能为空。
- 点击FIDS单元格,键入一个数字值或接受默认值。
- 提示:
- 每个用户名可以有一个唯一的FIDS值,但该字段值不能为空。FIDS的取值范围必须在1到65534之间。
- 按Tab键,然后按Enter键,在出现的新行中输入一个用户名,以添加更多的用户名。
- 提示:
- 重复此步骤以添加更多的用户名。
- 单击 "编辑 "选项卡。
- 单击保存。
1.2 设置编绘比例尺
设置一个适当的编绘比例尺对生产工作流程很重要。在多比例生产环境中工作时,你需要建立比例,以便正确管理新创建的要素。你可以使用S-57编辑组中海事标签上的编绘比例尺工具来完成这个工作。该设置会自动为每个插入的要素填充PLTS_COMP_SCALE属性。该工具允许你审查和动态改变新创建数据的编辑比例尺。
默认的编辑比例尺是1;在编绘比例尺组合框中可以选择其他比例值。你也可以为没有出现在列表中的编辑比例尺输入一个值。你提供的值会保存在活动项目中,并在你创建项目时持续存在。
注:
建议你在添加功能前确认你的编辑比例尺。你可以查看组合框中的值,以确认它是正确的。
警告:
不要使用负值或非数字字符。
步骤:
- 启动GeoScene Pro。
- 打开一个新的或现有的项目。
- 如有必要,在 "内容 "窗格中添加海事数据。
- 出现海事标签。
- 在海事标签上,在S-57编辑组中,点击编绘比例尺下拉箭头。

- 在编绘比例的组合框中选择一个值。
提示:
你也可以在编辑比例组合框中输入一个自定义值。
2 坐标系设置
数据显示单位在地图视图属性对话框中常规页可以进行设置。

3 创建新的要素
- 启动GeoScene Pro,启用编辑下的“创建”。
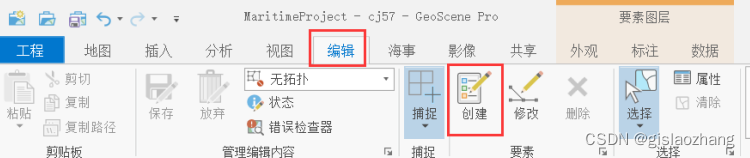
- 选择合适的要素模板
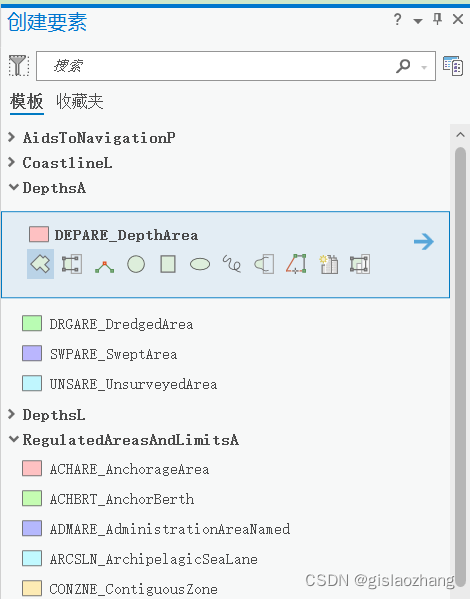
- 根据模板创建要素,点击“属性”选项给新创建的物标赋予相应的属性信息。

- 编辑完后保存编辑即可。

说明:在geoscene版本中,添加了创建物标的S-58主动质检,也就是你在创建物标的时候,Nautical框架会主动按照S-58质检的要求进行约束,如下图。

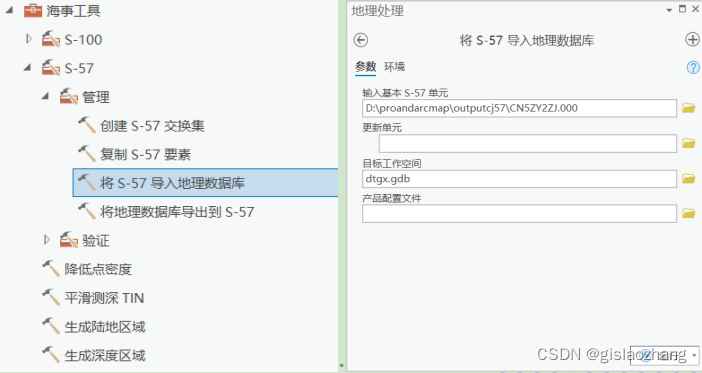
4 Load数据到NIS库
在进行ENC制图时,对于已经有的ENC数据如何利用,可以将历史的ENC数据导入到GDB中,或者NIS库中。具体的操作方式如下图:
- 在目录窗格中,创建一个文件数据库

说明:然后导入对应的模型的schema,可以是NIS也可以是ENC等等。
- 通过海事工具箱中的“将s-57导入地理数据库”工具导入现有的ENC数据(.000文件);
这篇关于【03】GeoScene创建海图或者电子航道图数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







