本文主要是介绍详解 Jeecg-boot 框架如何配置 elasticsearch,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、下载安装 Elasticsearch
1、 地址:https://www.elastic.co/cn/downloads/elasticsearch
2、下载完成后,解压缩,进入config目录更改配置文件
3、 修改配置完成后,前往bin目录启动el
4、访问:localhost:9200 测试
二、配置 Jeecg-boot 框架
1、导入jeecg项目后,打开application-dev.yml配置文件,设置为如下
2、配置完成后启动 JeecgSystemApplication
一、下载安装 Elasticsearch
1、 地址:https://www.elastic.co/cn/downloads/elasticsearch
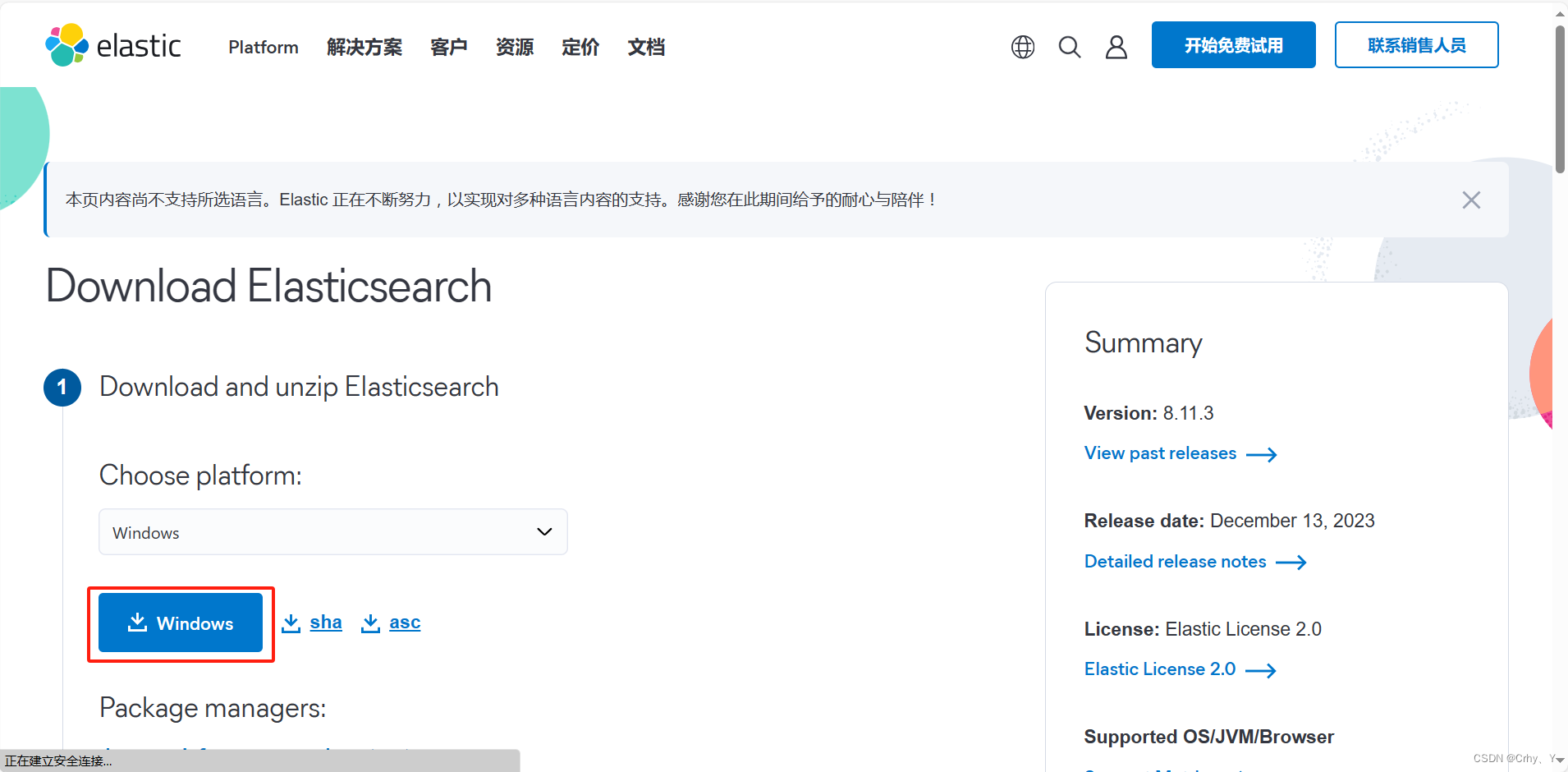
2、下载完成后,解压缩,进入config目录更改配置文件

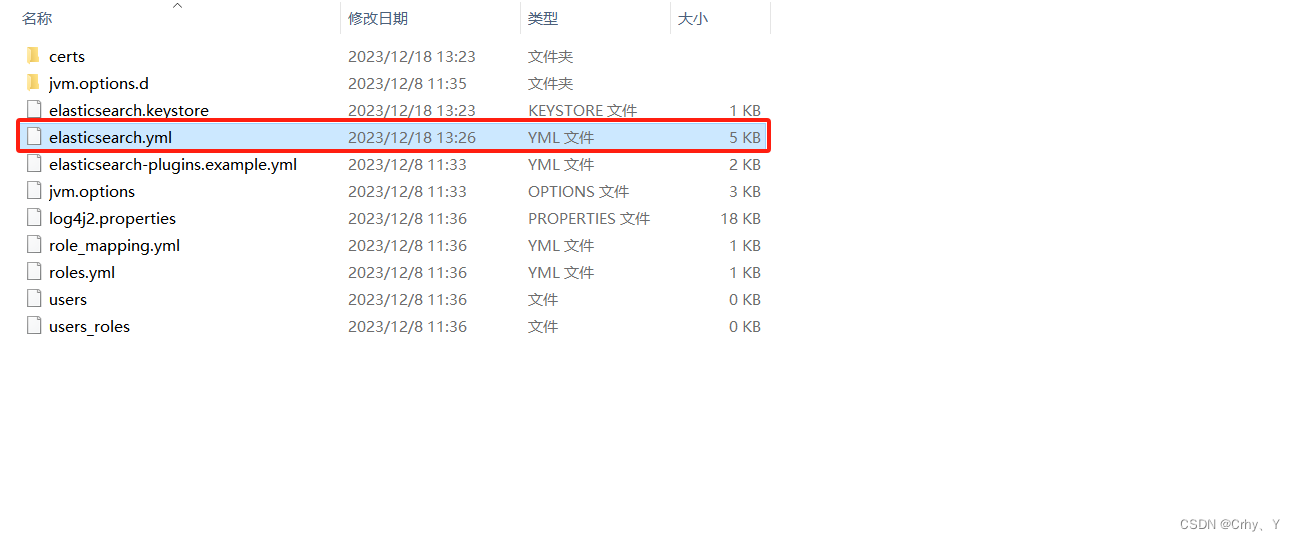
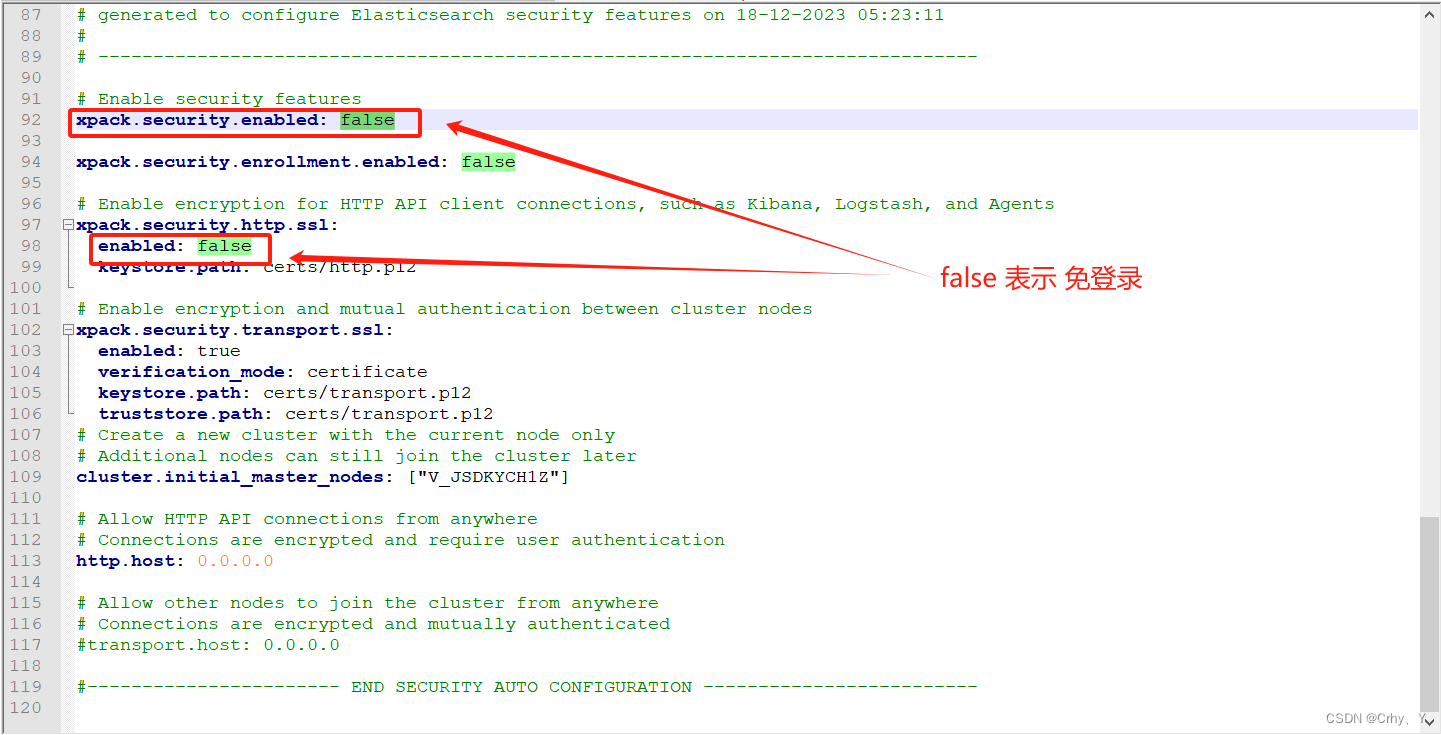
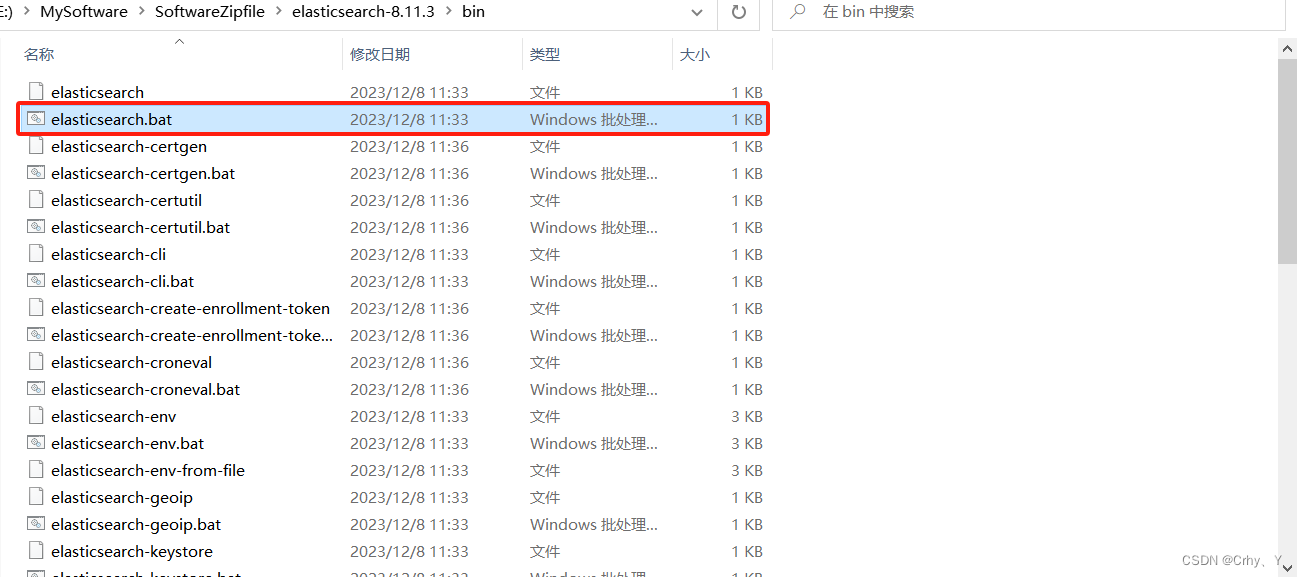
3、 修改配置完成后,前往bin目录启动el

4、访问:localhost:9200 测试

二、配置 Jeecg-boot 框架
1、导入jeecg项目后,打开application-dev.yml配置文件,设置为如下

2、配置完成后启动 JeecgSystemApplication

有以上输出说明配置成功
这篇关于详解 Jeecg-boot 框架如何配置 elasticsearch的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




